

后缀自动机概念的温习
觉得对于一个数据结构充分的学会使用,一定要对它的构成部分和定义概念有很充分很全面的了解.
所以我觉得的一种温习的最好方式就是:明晰概念->分析运用这样的层次.
概念的明晰确实是十分有用的,它既是理解他人算法的必要前提,也是你在看到题目后可以有创新想法的重要基础.
下面这篇文章主要是写给笔者自己看的...所以逻辑有点混乱是因为写的顺序不是这样一路下去的...233
1.状态集合
每个状态中存储的是一些right集合相同的字符串.初始态的right集合视为{1,2,3...n} [但是例如"aaa"中,"a"的right虽然也是{1,2,3}但是不与初始态重合,这个例子的parent树中初始态只有一个叶子节点].
right相同的字符串的话,就不要觉得它们之间是没有联系的,它们应该是连续的是相互重叠的.
比如说"abcdefdef中": "abcdef","bcdef","cdef" 就是放在一个right集合中的.
状态中出现了一个属性mx,表示的是这个right集合中线段的最长长度.
回顾构造sam的过程,mx的赋值是在实边的基础上赋值的.比如当末尾元素加入的时候mx[np]=mx[p]+1,因为当实边连接的时候表示前一个集合的某些位置可以往后向x的方向拓展一步,那么所有能拓展的子串中选最长的+1就是新的right集合中最长的子串了,而由于我们是沿着parent往上走,所以parent的前进相当于删去一个首字母得到原先串的一个后缀,所以最底下的串是最长的,所以也可以想象得到新增加的这个节点中的子串一定满足上面说的性质连续的.
如果两个状态u,v,v--x-->u 且 mx[u]=mx[v]+1,则说明u中最长的串可以直接由v的最长串得来.v是所有能通过x到u的串中最长的,其它的串是它的后缀,且不被其他任何串包含.
2.状态之间的联系
1.实边:
如果在一个串的后面加上字符,那么right集合一定发生了改变.
实边连接表示一个right集合的出现,这个right集合应该是前一个right集合中的部分位置往后+1得到的新right集合
例如"abcdeabcdf"中R("abcd")={4,6}--e-->R("abcde")={5}
--f-->R("abcdf")={7}
所以说如果有实边相连说明在串中的某个位置可以接着往后走这个元素到达新的一个状态.
图像感受就是现在线段上你有很多个小点[表示当前状态的right集合]然后你可以在某些位置后面找到一个元素走一步,变成新的一些小点.
2.parent边:
每个状态中存下的是一段连续的串,其中最短的那个串去掉首字母就不在这个状态中了.那么就是到了parent节点中.parent(x)就是right集合包含x的所有中最小的集合.
所以parent链往下相当于trans反过来的一个过程:首先你有一个线段上的小点,然后某些位置上你可以往前找到某一个字符,然后满足这个条件的某些小点就构成了parent挂下的right集合.
比如下图中的边就表示的往前加入的一个字符。当然我们可以发现,加了字符之后能出现新right集合的条件就是你得有几种加法,比如"cd"可以加"b"或者"d";"bcd"可以加"a"或者"d"。
这个的正确性比较显然...如果每个地方都只能加一样的...当然新串的right集合和自己这个相同咯...
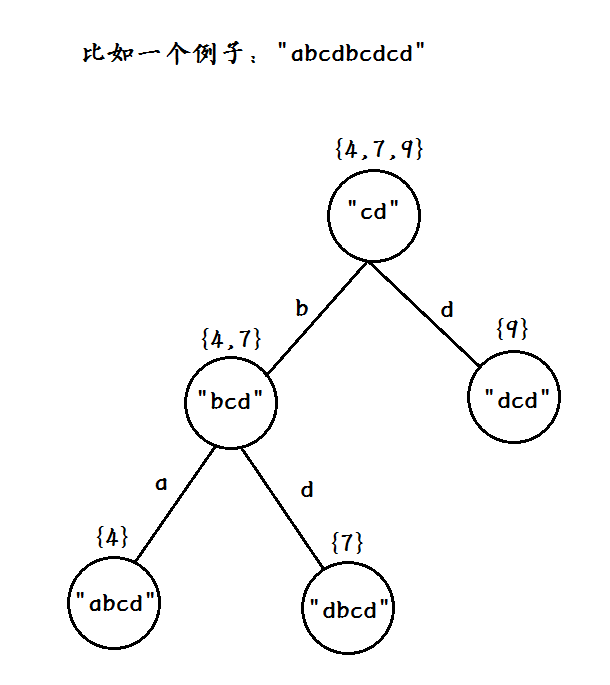
而反过来沿着parent链往上又是集合合并的过程。唔,这个的正确性你可以感受一下上面那个逆过程,想必是能理解的。
当然我们在这里就发现了trans和parent的区别。
1.trans是在原来串的基础上往后加字符,parent是往前加。所以一个是right集合中选一部分出来+1作为新的right,一个是直接从right集合中选一部分出来。
2.trans是只要后面能加值就一定能产生新的状态,parent是必须要有至少两条不同的才能产生新的right集合。
3.状态之间的路径:
1.实边构成的路径
从初始态沿着实边到达某个状态的若干条路径即这个状态中所有的串.若某个状态指的是终止态,那么这是原串的一条后缀.
任意两个状态之间的路径表示的是一个匹配的过程.还是回到图形上去.一开始你有一条线段上的若干个点,然后你沿着你需要匹配的链,从这些点中选出你需要的点并将位置+1,然后再下一步再选出一些点,再+1...以此下去直到最后你到达的那个状态.其中就是不断选择满足条件的right向后延伸的过程.也相当于一个匹配的过程.
2.parent构成的链
parent构成的链是向上的不断的去掉首字母的过程,其祖先都是它的一个后缀.parent树上不是向上的边构成的路径意义不是很大.但是两个点的lca表示它们的最长公共后缀.
大概反思了一下所有的概念,然后就可以分析一些SAM处理的过程:
1.构造:
构造是在串"S"所构成的SAM的基础上往后拓展一位c得到的SAM.由于SAM需要识别所有的子串,其中不包括c的子串已经得到,需要识别所有包括c的子串,也就是后缀.
首先需要构造一个新的终止态np.因为终止态的最长串自然是整个串,所以mx[np]=mx[p]+1,然后因为是识别后缀,就应该是在原来的后缀基础上向后拓展c.找到所有后缀的方法很简单,首先找到了包括所有后缀的"S",然后沿着parent链往上就是一个不断取后缀的过程.
对于一些原本没有连出c边的后缀,也就是它们在线段上的小点中没有一个位置能向后拓展一步c,现在它们在末尾可以拓展了,所以a[x][c]=np.
对于某些后面原本连出c边的后缀"A",它们在线段上的小点中有某些位置往后走一步c,这样的话还要看是不是有包含了这个后缀而又不是原串后缀的串"B",如果有,那么这个后缀往后走一步c到达的状态的最长串就不是"Ac"而是"Bc",那么"Ac"的right集合会变化,但是"Bc"到"Ac"的这一段的right集合却不会变化.所以需要将这个状态分成两个部分,新的部分的right集合需要加入新的一个点.即fa[np]=nq,这个新的状态的最长长度就是"A"长度+1,即mx[nq]=mx[p]+1;同时也要包含以前的right集合,即fa[q]=nq.再看一下接着往上去的话,因为构成的是一棵parent树,"A"所在的状态相当于一个分叉点,再往上就不会分叉了.所以上面的right都会增加新的那个节点,即fa[nq]=fa[q].既然产生了新的,可能还会有别的后缀也扩展到"A"所扩展的状态去,所以需要把所有fa[x][c]==q的全部改成nq.当然如果满足了mx[q]==mx[p]+1就没有这么麻烦了,只需要给这个right集合扩充就行.fa[np]=q.然后整个过程就完成了.
所以如果说读者您看过我之前有一篇入门的后缀自动机的话,可以发现那张解释构造的图其实有一点小问题.希望你理解之后可以自己发现.
2.寻找最长公共子串:
首先给第一个串建立sam,然后让别的串在这个自动机上走.
思考这个走的过程.现在我们在x状态,然后可以往后看是否具有一个当前字符的转移,如果有,就相当于把所有当前状态中可以转移的小点都往前走了一步.如果没有,那么就无法找到这么多匹配的,但是要利用已经匹配的信息,所以我们可以退回到当前串的后缀去看,然后把已经匹配的长度变成mx[S],相当于我们舍弃了这个状态到上一个状态的前面的部分,然后再去尝试往x的方向走.当然如果找了所有的,甚至到了初始态都没有x出边,那么就说明没有匹配,已匹配长度设置为0,指针指向初始态.
当我们处于某个状态的时候,其实并不能判断我们匹配的是这个状态中的哪一个串,但是我们却知道我们匹配到了原串的哪几个位置.也就是知道下一个可以往哪个方向走.如果要知道匹配了多长则需要记录一个变量,但是如果是发现此处不能向后拓展后的沿着parent往回跳,那么就一定可以匹配到parent中的最长的那个串.
寻找多个串的公共子串的时候,可以记录一下每个节点在每个位置匹配到的长度,然后对于所有的串在该位置上取一个最小值就是所有串公共的部分了.但是有要注意的地方就是如果你匹配到了某一个状态,那么它的parent中的所有的值其实你也可以匹配到,所以需要拓扑排序处理一下,把每个匹配到的值往上回溯更新,防止出现疏漏.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号