Socket与系统调用深度分析
系统调用
系统调用的过程
系统调用的过程如下:
- 用户程序
- C库(API):INT 0x80
- system_call
- 系统调用服务例程
- 内核程序
说明:
- 我们常说的用户 API 其实就是系统提供的 C 库;
- 系统调用是通过软中断指令 INT 0x80 实现的,而这条 INT 0x80 指令就被封装在 C 库的函数中。
- INT 0x80 这条指令的执行会让系统跳转到一个预设的内核空间地址,它指向系统调用处理程序,即 system_call 函数
下图为系统调用具体的流程。
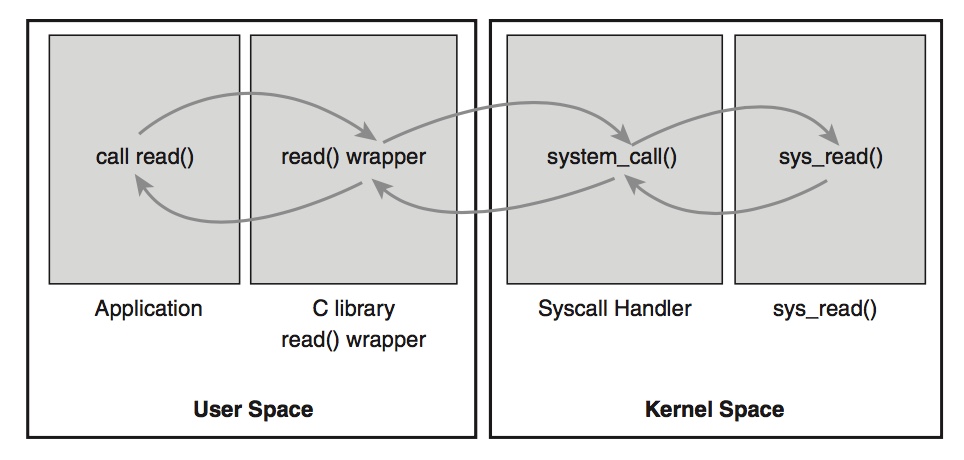
值得一提的是:系统调用处理程序 system_call 并不是系统调用服务例程。
系统调用服务例程是对一个具体的系统调用的内核实现函数,而系统调用处理程序是在执行系统调用服务例程之前的一个引导过程,是针对 INT 0x80 这条指令,面向所有的系统调用的。
简单来讲,执行任何系统调用,都是先通过调用 C 库中的函数,这个函数里面就会有软中断 INT 0x80 语句,然后转到执行系统调用处理程序 system_call,system_call 再根据具体的系统调用号转到执行具体的系统调用服务例程。
那么,system_call 函数是怎么找到具体的系统调用服务例程的呢?
答案是:通过系统调用号查找系统调用表 sys_call_table。
软中断指令 INT 0x80 执行时,系统调用号会被放入 eax 寄存器中,system_call 函数可以读取 eax 寄存器获取,然后将其乘以 4,生成偏移地址,然后以 sys_call_table 为基址,基址加上偏移地址,就可以得到具体的系统调用服务例程的地址了!
然后就可以根据这个地址找到对应的系统调用服务例程了。
系统调用可以被进程抢占、进入阻塞状态
其原因在于:
系统调用通过软中断 INT 0x80 陷入内核,跳转到系统调用处理程序 system_call 函数,然后执行相应的服务例程。但是由于是代表用户进程,所以这个执行过程并不属于中断上下文,而是进程上下文。
因此,系统调用执行过程中,可以访问用户进程的许多信息,可以被其他进程抢占,可以休眠。
当系统调用完成后,把控制权交回到发起调用的用户进程前,内核会有一次调度。如果发现有优先级更高的进程或当前进程的时间片用完,那么会选择优先级更高的进程或重新选择进程执行。
示例分析
了解系统调用的过程之后,我们举个例子来分析用户态是如何陷入到内核态的。
由于本次实验的目的是调研socket相关的系统调用,因此我们以一个bind绑定事件作为例子。
#include <sys/socket.h>
#include <sys/un.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#define MY_SOCK_PATH "/somepath"
#define LISTEN_BACKLOG 50
#define handle_error(msg) \
do { perror(msg); exit(EXIT_FAILURE); } while (0)
int main(int argc, char *argv[])
{
int sfd, cfd;
struct sockaddr_un my_addr, peer_addr;
socklen_t peer_addr_size;
sfd = socket(AF_UNIX, SOCK_STREAM, 0);
if (sfd == -1)
handle_error("socket");
memset(&my_addr, 0, sizeof(struct sockaddr_un));
/* Clear structure */
my_addr.sun_family = AF_UNIX;
strncpy(my_addr.sun_path, MY_SOCK_PATH,
sizeof(my_addr.sun_path) - 1);
if (bind(sfd, (struct sockaddr *) &my_addr,
sizeof(struct sockaddr_un)) == -1)
handle_error("bind");
if (listen(sfd, LISTEN_BACKLOG) == -1)
handle_error("listen");
在用户态我们调用了
bind函数,它声明在<sys/socket.h>。
/* Give the socket FD the local address ADDR (which is LEN bytes long). */
extern int bind (int __fd, __CONST_SOCKADDR_ARG __addr, socklen_t __len)
__THROW;
我们之前提到过,用户态进程只需要调用库函数即可,而不用管这个函数是如何实现的。
linux中这些具体函数的实现则由glibc统一提供。它定义在glibc-2.23/sysdeps/unix/sysv/linux/bind.c
int __bind (int fd, __CONST_SOCKADDR_ARG addr, socklen_t len)
{
#ifdef __ASSUME_BIND_SYSCALL
return INLINE_SYSCALL (bind, 3, fd, addr.__sockaddr__, len);
#else
return SOCKETCALL (bind, fd, addr.__sockaddr__, len, 0, 0, 0);
#endif
}
weak_alias (__bind, bind)
在syscall之前需要先将参数传入寄存器。
之前,如我们之前分析的一样:使用0x80中断去陷入内核,并将返回值存放到eax寄存器中,通常0表示成功。
syscall的name为
__NR_##name,在本例中即为__NR_bind。
其定义在/usr/include/asm/unistd_64.h中。
#define __NR_bind 49
#define __NR_listen 50
#define __NR_getsockname 51
这样,用户态和内核态通过系统调用号(49)来确定本次系统调用是哪个功能。
Socket系统调用分析
Socket系统调用主要完成socket的创建,必要字段的初始化,关联传输控制块,绑定文件等任务,完成返回socket绑定的文件描述符。
socket的调用关系如下:
/**
* sys_socket
* |-->sock_create
* | |-->__sock_create
* | |-->inet_create
* |-->sock_map_fd
*/
sock_map_fd
该函数的主要功能在于:负责分配文件,并实现与socket的绑定。
/* 套接口与文件描述符绑定 */
static int sock_map_fd(struct socket *sock, int flags)
{
struct file *newfile;
/* 获取未使用的文件描述符 */
int fd = get_unused_fd_flags(flags);
if (unlikely(fd < 0))
return fd;
/* 分配socket文件 */
newfile = sock_alloc_file(sock, flags, NULL);
if (likely(!IS_ERR(newfile))) {
/* fd和文件进行绑定 */
fd_install(fd, newfile);
return fd;
}
/* 释放fd */
put_unused_fd(fd);
return PTR_ERR(newfile);
}
sock_create
其主要功能为:负责创建socket,并进行必要的初始化工作。
int sock_create(int family, int type, int protocol, struct socket **res)
{
return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0);
}
之后,sock_create调用__socket_create函数来进行必要的检查项,并创建和初始化socket。
在__socket_create函数中,调用对应协议族的pf->create函数来创建传输控制块,并且与socket进行关联。
/* 创建socket */
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
int err;
struct socket *sock;
const struct net_proto_family *pf;
/*
* Check protocol is in range
*/
/* 检查协议族 */
if (family < 0 || family >= NPROTO)
return -EAFNOSUPPORT;
/* 检查类型 */
if (type < 0 || type >= SOCK_MAX)
return -EINVAL;
/* Compatibility.
This uglymoron is moved from INET layer to here to avoid
deadlock in module load.
*/
/* ipv4协议族的packet已经废除,检测到,则替换成packet协议族 */
if (family == PF_INET && type == SOCK_PACKET) {
pr_info_once("%s uses obsolete (PF_INET,SOCK_PACKET)\n",
current->comm);
family = PF_PACKET;
}
/* 安全模块检查套接口 */
err = security_socket_create(family, type, protocol, kern);
if (err)
return err;
/*
* Allocate the socket and allow the family to set things up. if
* the protocol is 0, the family is instructed to select an appropriate
* default.
*/
/* 分配socket,内部和inode已经绑定 */
sock = sock_alloc();
if (!sock) {
net_warn_ratelimited("socket: no more sockets\n");
return -ENFILE; /* Not exactly a match, but its the
closest posix thing */
}
/* 设定类型 */
sock->type = type;
#ifdef CONFIG_MODULES
/* Attempt to load a protocol module if the find failed.
*
* 12/09/1996 Marcin: But! this makes REALLY only sense, if the user
* requested real, full-featured networking support upon configuration.
* Otherwise module support will break!
*/
if (rcu_access_pointer(net_families[family]) == NULL)
request_module("net-pf-%d", family);
#endif
rcu_read_lock();
/* 找到协议族 */
pf = rcu_dereference(net_families[family]);
err = -EAFNOSUPPORT;
if (!pf)
goto out_release;
/*
* We will call the ->create function, that possibly is in a loadable
* module, so we have to bump that loadable module refcnt first.
*/
/* 增加模块的引用计数 */
if (!try_module_get(pf->owner))
goto out_release;
/* Now protected by module ref count */
rcu_read_unlock();
/* 调用协议族的创建函数 */
err = pf->create(net, sock, protocol, kern);
if (err < 0)
goto out_module_put;
/*
* Now to bump the refcnt of the [loadable] module that owns this
* socket at sock_release time we decrement its refcnt.
*/
if (!try_module_get(sock->ops->owner))
goto out_module_busy;
/*
* Now that we're done with the ->create function, the [loadable]
* module can have its refcnt decremented
*/
module_put(pf->owner);
err = security_socket_post_create(sock, family, type, protocol, kern);
if (err)
goto out_sock_release;
*res = sock;
return 0;
out_module_busy:
err = -EAFNOSUPPORT;
out_module_put:
sock->ops = NULL;
module_put(pf->owner);
out_sock_release:
sock_release(sock);
return err;
out_release:
rcu_read_unlock();
goto out_sock_release;
}
EXPORT_SYMBOL(__sock_create);
对于PF_INET协议族来讲,上述的pf->create函数将调用inet_create函数。
熟悉设备驱动的同学应该都知道这些操作被定义在file_operations结构中。
static const struct net_proto_family inet_family_ops = {
.family = PF_INET,
.create = inet_create,
.owner = THIS_MODULE,
};
最后,在inet_create函数中完成创建传输控制块,并且将socket与传输控制块进行关联。至于该函数代码这里不再展开分析。
实验代码分析
在上一次实验中,我们已经将老师提供的客户端以及服务器端的程序集成到了MenuOS中,可以在qemu虚拟机中使用replyhi和hello两个命令。
但是对于这两个程序的内部实现还没有深入分析,这里我们通过阅读代码来找出这两个程序在执行时所使用到的Socket API。
服务器端
首先,分析一下服务器端的代码。
在我们使用
replyhi命令时,会执行main.c文件中的StartReplyhi函数。
MenuConfig("replyhi", "Reply hi TCP Service", StartReplyhi);
继续阅读
StartReplyhi函数的代码。可以发现,在满足连接条件的判断语句中,程序继续调用了Replyhi函数。
int StartReplyhi(int argc, char *argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid < 0)
{
/* error occurred */
fprintf(stderr, "Fork Failed!");
exit(-1);
}
else if (pid == 0)
{
/* child process */
Replyhi();
printf("Reply hi TCP Service Started!\n");
}
else
{
/* parent process */
printf("Please input hello...\n");
}
}
查看
Replyhi函数的实现。在函数中总共调用了六个方法,从字面意思来看,不难推测出它们的具体含义分别是:初始化服务、启动服务、接收消息、发送消息、停止服务以及关闭服务。
这些方法都在头文件
syswrapper.h中定义。下面将对这些方法逐一展开分析。
int Replyhi()
{
char szBuf[MAX_BUF_LEN] = "\0";
char szReplyMsg[MAX_BUF_LEN] = "hi\0";
InitializeService();
while (1)
{
ServiceStart();
RecvMsg(szBuf);
SendMsg(szReplyMsg);
ServiceStop();
}
ShutdownService();
return 0;
}
InitializeService方法
#define InitializeService() \
PrepareSocket(IP_ADDR,PORT); \
InitServer();
可以看到,在头文件中使用宏定义的方式将其具体实现私有化。
根据第一部分的socket创建过程分析,我们可以很自然地理解
PrepareSocket函数就是用于创建服务器端socket:在定义了serveraddr中的协议族、端口、IP地址信息后,通过socket这一系统调用完成服务器端socket的创建,并返回文件描述符信息。
InitServer函数则是调用bind和PrepareSocket函数中得到的文件描述符完成绑定,绑定成功后,服务器进入监听状态,即等待客户端的连接,通过调用listen来实现监听。
#define PrepareSocket(addr,port) \
int sockfd = -1; \
struct sockaddr_in serveraddr; \
struct sockaddr_in clientaddr; \
socklen_t addr_len = sizeof(struct sockaddr); \
serveraddr.sin_family = AF_INET; \
serveraddr.sin_port = htons(port); \
serveraddr.sin_addr.s_addr = inet_addr(addr); \
memset(&serveraddr.sin_zero, 0, 8); \
sockfd = socket(PF_INET,SOCK_STREAM,0);
#define InitServer() \
int ret = bind( sockfd, \
(struct sockaddr *)&serveraddr, \
sizeof(struct sockaddr)); \
if(ret == -1) \
{ \
fprintf(stderr,"Bind Error,%s:%d\n", \
__FILE__,__LINE__); \
close(sockfd); \
return -1; \
} \
listen(sockfd,MAX_CONNECT_QUEUE);
因此,在初始化服务中我们所使用到的Socket API共有三个,分别为:socket,bind,listen。
ServiceStart方法
在调用初始化服务方法之后,我们完成了服务器端socket的创建、绑定以及监听。
因此,在该方法的实现中,我们所实现的是接收客户端所发出的连接请求,通过调用
accept来实现,可以看到该函数的参数中clientaddr则标明服务器与哪个客户端进行连接。
#define ServiceStart() \
int newfd = accept( sockfd, \
(struct sockaddr *)&clientaddr, \
&addr_len); \
if(newfd == -1) \
{ \
fprintf(stderr,"Accept Error,%s:%d\n", \
__FILE__,__LINE__); \
}
因此,在启动服务中我们所使用到的Socket API只有一个:accept。
RecvMsg与SendMsg方法
与客户端经历三次握手建立TCP连接之后,就可以与客户端进行消息的发送与接收。
代码的实现与之前类似,其过程就不再赘述。不过,需要注意的是在这两个方法中,都包含
newfd这个参数,此参数是客户端与服务器建立连接时所获得的返回值,也就是说这个值标识了这条TCP连接,确认了消息发送、接收的双方。
#define RecvMsg(buf) \
ret = recv(newfd,buf,MAX_BUF_LEN,0); \
if(ret > 0) \
{ \
printf("recv \"%s\" from %s:%d\n", \
buf, \
(char*)inet_ntoa(clientaddr.sin_addr), \
ntohs(clientaddr.sin_port)); \
}
#define SendMsg(buf) \
ret = send(newfd,buf,strlen(buf),0); \
if(ret > 0) \
{ \
printf("send \"hi\" to %s:%d\n", \
(char*)inet_ntoa(clientaddr.sin_addr), \
ntohs(clientaddr.sin_port)); \
}
因此,在消息接收与发送中我们所使用到的Socket API共有两个:recv,send。
ServiceStop与ShutdownService方法
这两个方法都用于终止连接,因此在代码中所调用的API也都是
close。
#define ShutdownService() \
close(sockfd);
#define ServiceStop() \
close(newfd);
因此,在停止和关闭服务中我们所使用到的Socket API为:close。
客户端
同样的,在我们使用
hello命令时,程序会调用Hello函数。
MenuConfig("hello", "Hello TCP Client", Hello);
在Hello函数中,我们又见到了消息发送和接收这两个方法的“身影”。
int Hello(int argc, char *argv[])
{
char szBuf[MAX_BUF_LEN] = "\0";
char szMsg[MAX_BUF_LEN] = "hello\0";
OpenRemoteService();
SendMsg(szMsg);
RecvMsg(szBuf);
CloseRemoteService();
return 0;
}
其调用的方法内部实现与服务器端类似,这里我们给出结论:
客户端所使用到的Socket API有:socket, connect,send,recv,close。
跟踪socket相关系统调用的内核处理函数
系统调用初始化
系统调用初始化的过程:
- 在32位系统中:
start_kernel -> trap_init -> idt_setup_traps -> 0x80- 在64位系统中:
start_kernel -> trap_init -> cpu_init -> syscall_init
为了验证这个初始化过程是否正确,我们使用上一次实验使用过的gdb进行调试。
由于我们上次实验构建的是32位的MenuOS系统,因此我们在start_kernel, trap_init以及 idt_setup_traps这三个函数打上断点来完成验证。
命令
sudo qemu -kernel ../linux-5.0.1/arch/x86/boot/bzImage -initrd ../rootfs.img -append nokaslr -s -S #启动
# 新建终端
gdb #进入gdb命令行
file ../LinuxKernel/linux-5.0.1/vmlinux #在gdb界面中targe remote之前加载符号表
target remote:1234 # 建立gdb和gdbserver之间的连接
break start_kernel # 设置断点1
break trap_init # 设置断点2
break idt_setup_traps # 设置断点3

接着,我们可以使用continue命令让qemu虚拟机继续运行起来。

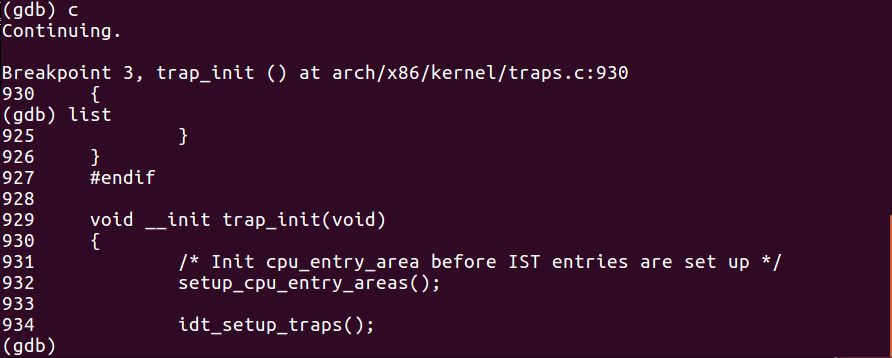

为避免出现断点捕捉顺序与断点设置顺序相关的情况发生,这里我故意将后两个函数的断点设置顺序调换了一下。
而结果如我们之前分析的一样,我们捕获到了三个断点,并且这三个断点的捕捉顺序正是系统调用初始化过程所经历的顺序。
socket相关的系统调用
通过查阅32位的系统调用表,我们发现与socket相关的系统调用分为以下两种:
sys_socketcall
socket api对应的单独系统调用
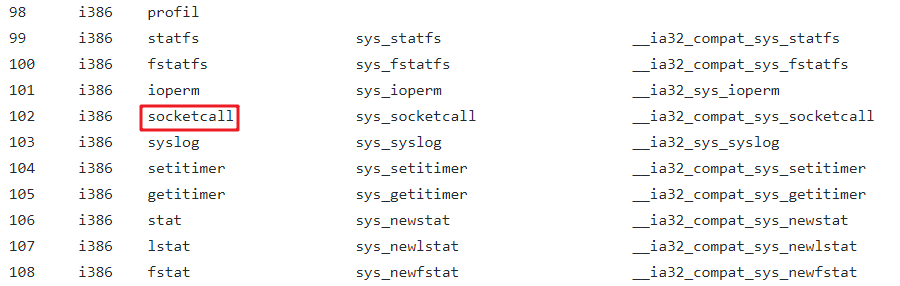

通过查阅资料我们发现:
sys_socketcall()是内核中为 socket 设置的总入口 ,也就是说,在调用socket其他相关的API时都需要先调用sys_socketcall()。
而在前一章中的实验代码分析中,我们对于已经集成到MenuOS中replyhi和hello命令所对应的客户端、服务器端程序进行了分析,并且已经得出结论,即这两个命令在执行时所使用到的Socket API。分别为:
服务器端:socket,bind,listen,accept,recv,send,close
客户端:socket,connect,send,recv,close
理清楚了socket相关的系统调用之后,下面我们同样通过gdb调试的方法来验证我们的分析是否正确。
命令
break sys_socketcall # 设置断点
continue
经过调试,我们捕捉到了该断点,并通过list命令找到了sys_socketcall系统调用所对应的内核处理函数SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args)。
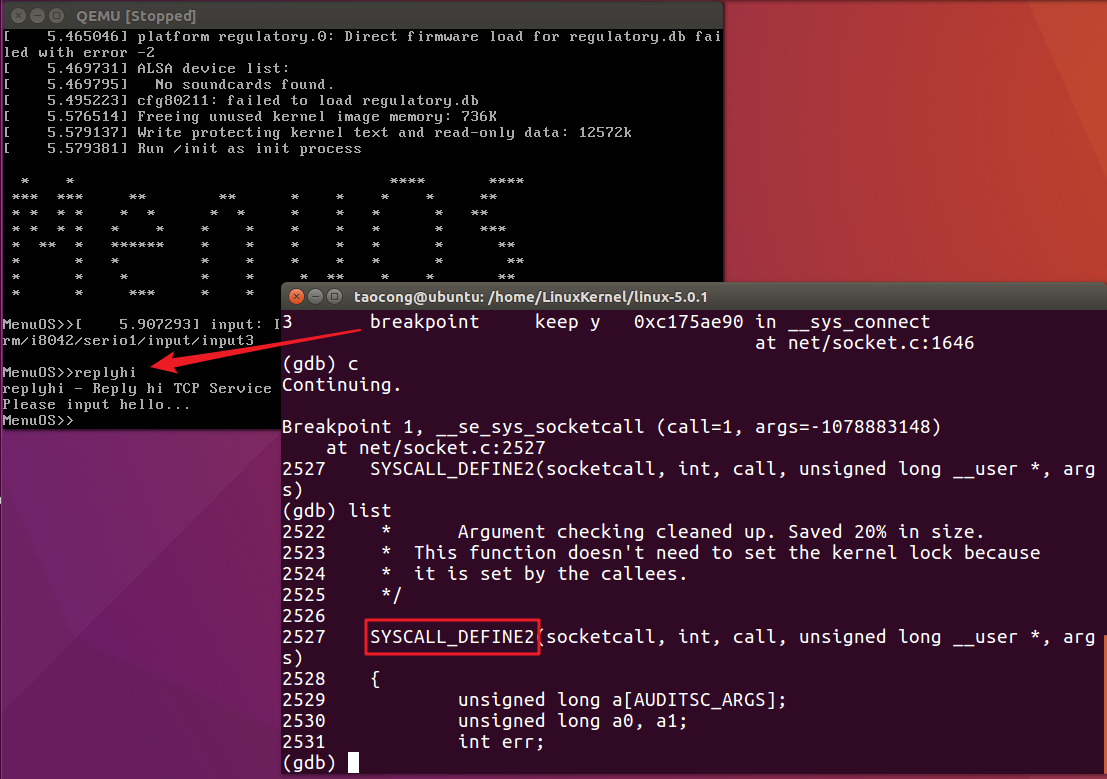
那么,下面简要的分析以下这个内核处理函数。
/*
* System call vectors.
*
* Argument checking cleaned up. Saved 20% in size.
* This function doesn't need to set the kernel lock because
* it is set by the callees.
*/
SYSCALL_DEFINE2(socketcall, int, call, unsigned long __user *, args)
{
unsigned long a[AUDITSC_ARGS];
unsigned long a0, a1;
int err;
unsigned int len;
if (call < 1 || call > SYS_SENDMMSG)
return -EINVAL;
call = array_index_nospec(call, SYS_SENDMMSG + 1);
len = nargs[call];
if (len > sizeof(a))
return -EINVAL;
/* copy_from_user should be SMP safe. */
if (copy_from_user(a, args, len))
return -EFAULT;
err = audit_socketcall(nargs[call] / sizeof(unsigned long), a);
if (err)
return err;
a0 = a[0];
a1 = a[1];
switch (call) {
case SYS_SOCKET:
err = __sys_socket(a0, a1, a[2]);
break;
case SYS_BIND:
err = __sys_bind(a0, (struct sockaddr __user *)a1, a[2]);
break;
case SYS_CONNECT:
err = __sys_connect(a0, (struct sockaddr __user *)a1, a[2]);
break;
case SYS_LISTEN:
err = __sys_listen(a0, a1);
break;
case SYS_ACCEPT:
err = __sys_accept4(a0, (struct sockaddr __user *)a1,
(int __user *)a[2], 0);
break;
case SYS_GETSOCKNAME:
err =
__sys_getsockname(a0, (struct sockaddr __user *)a1,
(int __user *)a[2]);
break;
case SYS_GETPEERNAME:
err =
__sys_getpeername(a0, (struct sockaddr __user *)a1,
(int __user *)a[2]);
break;
case SYS_SOCKETPAIR:
err = __sys_socketpair(a0, a1, a[2], (int __user *)a[3]);
break;
case SYS_SEND:
err = __sys_sendto(a0, (void __user *)a1, a[2], a[3],
NULL, 0);
break;
case SYS_SENDTO:
err = __sys_sendto(a0, (void __user *)a1, a[2], a[3],
(struct sockaddr __user *)a[4], a[5]);
break;
case SYS_RECV:
err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3],
NULL, NULL);
break;
case SYS_RECVFROM:
err = __sys_recvfrom(a0, (void __user *)a1, a[2], a[3],
(struct sockaddr __user *)a[4],
(int __user *)a[5]);
break;
case SYS_SHUTDOWN:
err = __sys_shutdown(a0, a1);
break;
case SYS_SETSOCKOPT:
err = __sys_setsockopt(a0, a1, a[2], (char __user *)a[3],
a[4]);
break;
case SYS_GETSOCKOPT:
err =
__sys_getsockopt(a0, a1, a[2], (char __user *)a[3],
(int __user *)a[4]);
break;
case SYS_SENDMSG:
err = __sys_sendmsg(a0, (struct user_msghdr __user *)a1,
a[2], true);
break;
case SYS_SENDMMSG:
err = __sys_sendmmsg(a0, (struct mmsghdr __user *)a1, a[2],
a[3], true);
break;
case SYS_RECVMSG:
err = __sys_recvmsg(a0, (struct user_msghdr __user *)a1,
a[2], true);
break;
case SYS_RECVMMSG:
if (IS_ENABLED(CONFIG_64BIT) || !IS_ENABLED(CONFIG_64BIT_TIME))
err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1,
a[2], a[3],
(struct __kernel_timespec __user *)a[4],
NULL);
else
err = __sys_recvmmsg(a0, (struct mmsghdr __user *)a1,
a[2], a[3], NULL,
(struct old_timespec32 __user *)a[4]);
break;
case SYS_ACCEPT4:
err = __sys_accept4(a0, (struct sockaddr __user *)a1,
(int __user *)a[2], a[3]);
break;
default:
err = -EINVAL;
break;
}
return err;
}
其核心代码在于switch...case中,可以看到在函数执行时它会按照参数call的值去调用不同的内核处理程序,如__sys_socket,__sys_bind等。至于call的值,SYS_SOCKET对应值为1,下面的case条件所对应的call值则以此递增。
这样,我们就很容易理解为什么说sys_socketcall()是内核中为 socket 设置的总入口。
接着,我们将Socket API所对应的各个内核处理函数打上断点。
命令
break __sys_socket
break __sys_bind
break __sys_listen
break __sys_connect
break __sys_accept4
break __sys_recvmsg
break __sys_sendmsg
break __sys_recvfrom
break __sys_sendto
break __sys_shutdown

然后,使用continue命令来康康我们是否能够捕获到这些断点。

可以发现在初始化的过程中我们共捕获到6次断点,分别是三次sys_socketcall()和三次__sys_socket。
都是三次,有这么巧合吗?另外,我们可以发现捕获顺序的规律总是先sys_socketcall()后捕获__sys_socket。
其实,我们之前已经提到过:sys_socketcall()是内核为socket设置的总入口,我们需要先进入到这个总入口,然后根据call值来进入不同的分支去调用对应的内核处理函数,这也就是为什么我们捕获断点时有上面的规律。
通过qemu虚拟机中的提示信息,该初始化的过程其实主要完成的是对网卡的配置与启动。
继续。

在又一次捕获到sys_socketcall()且此时call值为1时,我们发现gdb调试界面停止,
这时,按照之前服务器端代码分析的思路,我们需要在MenuOS系统输入replyhi命令来创建socket。
在输入命令之后,gdb调试继续。并且再次捕获断点时可以看到我们捕获到了__sys_socket,即调用了该内核处理函数完成了我们服务器端socket的创建。
继续捕获断点:
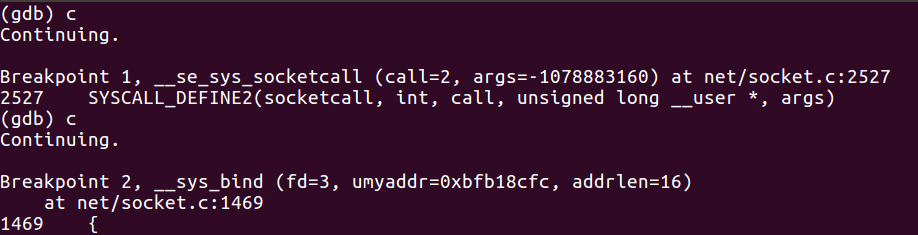
与之前分析的一样,需要先进入sys_socketcall()这个总入口;
然后通过我们之前在源代码分析中看到的switch结构,根据call=2的信息,可以知道它进入了case SYS_BIND这个分支;
继续使用continue命令可以看到,我们捕获到了__sys_bind这个断点,即确实按照分支的语句调用了所对应的内核处理函数,在这里,我们所调用的是socket的绑定函数。
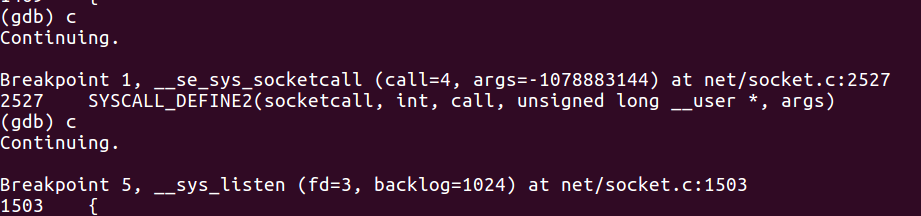
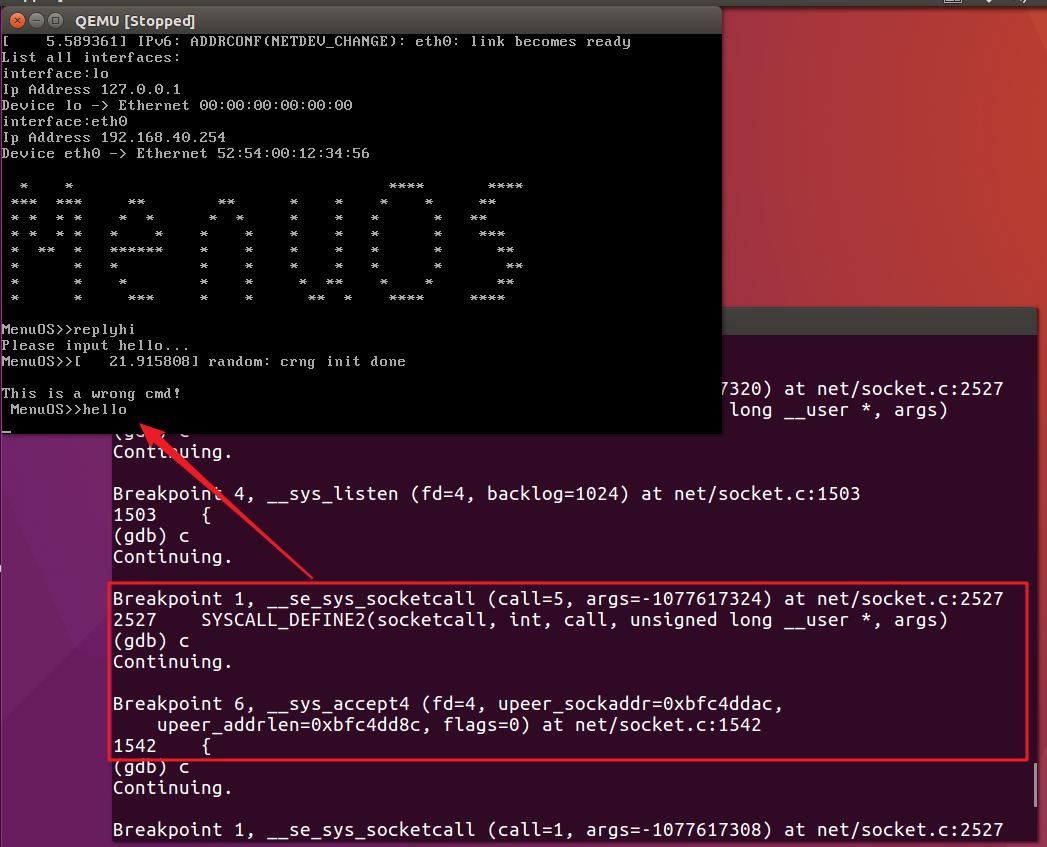
这一次,我们捕获到__sys_accept4,按照服务器端代码的思路,我们知道此时服务器准备好接收客户端的请求。
在qemu虚拟机中输入hello命令,来创建客户端socket。
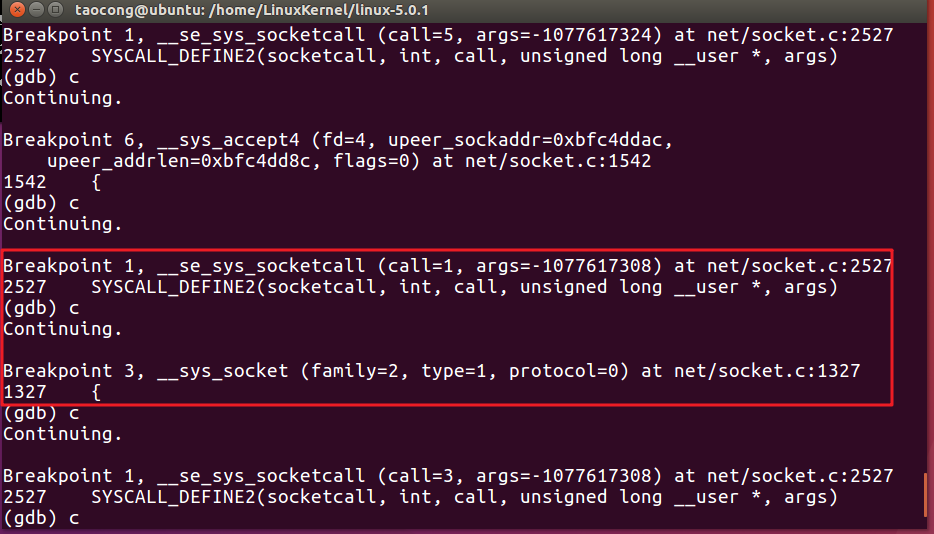
没错,在经历sys_socketcall()总入口之后我们再一次使用__sys_socket完成了客户端socket的创建。
同理,我们捕获到__sys_connect断点,该内核处理函数完成了客户端与服务器端的连接。
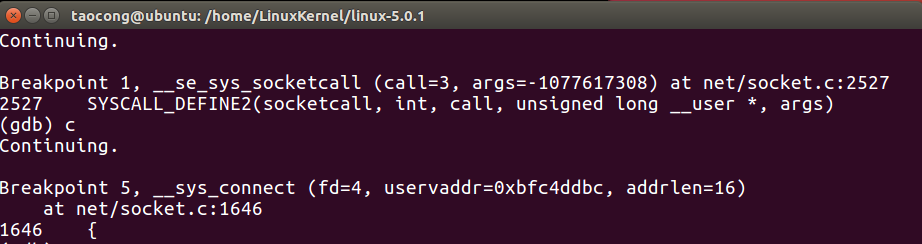
接着,我们会捕捉到收发消息相关的一系列系统调用,而与此同时,在qemu虚拟机中,我们也能够看到服务器与客户端交互的情况。
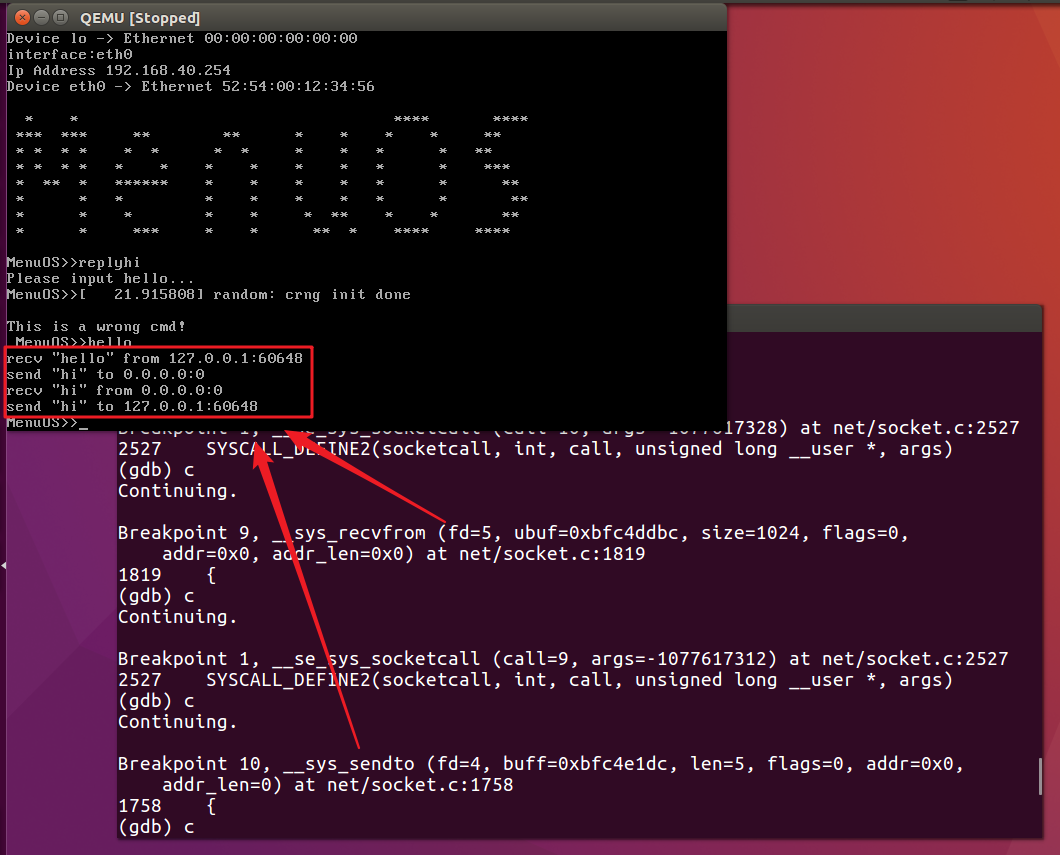
之后捕获断点我们又会重新创建一个客户端socket。
其原因在于Replyhi的实现中使用到了while循环,即服务器端不会主动关闭服务,而是不断等待新的客户端连接,然后与其进行交互。实现的是一个简单的多线程功能。
好的,以上就是socket系统调用追踪的全部内容了。
经历上述的追踪过程,我们发现系统调用的使用顺序与我们之前所分析的replyhi以及hello命令的执行过程一致!
如果您觉得这篇文章对你有所帮助,不妨给我点个关注/推荐吧。
参考链接
系统调用从用户态通过库函数进入内核的过程
socket系统调用和关键数据结构
Socket系统调用
SOCKET用户接口与系统调用关系
linux-5.0.1内核源码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号