
本篇文章主要用用于爬虫的学习,以及资料的整理防止过一段时间忘了,不知道怎么写了,特此写一篇博客记录一下。
文章目录
Python 爬虫学习
一、爬虫使用的库:
爬虫的第一步就是先把所有的数据从服务器上获取,然后在从本地解析,如果数据无法从下载到本地,那么你就候面的技术都是空谈。
很多初学者学爬虫都是用urllib库和requests库。具体有什么区别,最直观的区别就是requests库比urllib库使用的更简介一点,深层次的区别我就不填清楚了,我用到那种地步呢。
1、requests:
requests的函数方法:
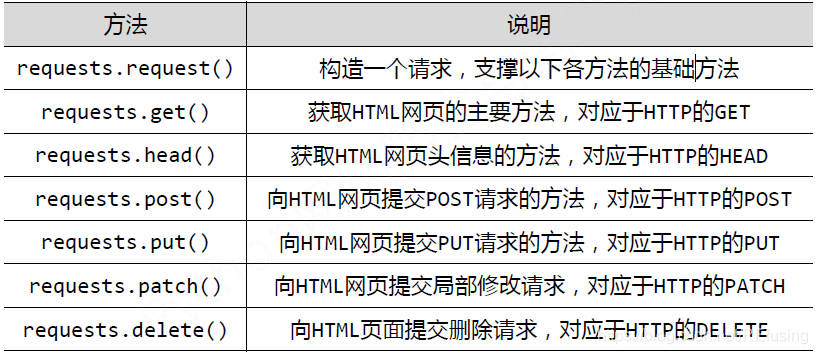
图片来自:python-爬虫-requests的基本方法函数
2、urllib库
urllib是python自带的请求库,各种功能相比较之下也是比较完备的,urllib库包含了一下四个模块:
| 模块 | 功能 |
|---|---|
| urllib.request | 请求模块 |
| urllib.error | 异常处理模块 |
| urllib.parse | url解析模块 |
| urllib.robotparse | robots.txt解析模块 |
2.1 urllib.request模块
代码来自:
response = urllib.request.urlopen('http://www.baidu.com')#发出请求
print(response.status) #打印状态码信息 其方法和response.getcode() 一样 都是打印当前response的状态码
print(response.getheaders()) #打印出响应的头部信息,内容有服务器类型,时间、文本内容、连接状态等等
print(response.getheader('Server')) #这种拿到响应头的方式需要加上参数,指定你想要获取的头部中那一条数据
print(response.geturl()) #获取响应的url
print(response.read())#使用read()方法得到响应体内容,这时是一个字节流bytes,看到明文还需要decode为charset格式
2.2urllib.parse模块
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True):该函数用于解析 URL 字符串。程序返回一个 ParseResult 对象,可以获取解析出来的数据。
urllib.parse.urlunparse(parts):该函数是上一个函数的反向操作,用于将解析结果反向拼接成 URL 地址。
urllib.parse.parse_qs(qs, keep_blank_values=False, strict_parsing=False, encoding='utf-8', errors='replace'):该该函数用于解析查询字符串(application/x-www-form-urlencoded 类型的数据),并以 dict 形式返回解析结果。
urllib.parse.parse_qsl(qs, keep_blank_values=False, strict_parsing=False, encoding='utf-8', errors='replace'):该函数用于解析查询字符串(application/x-www-form-urlencoded 类型的数据),并以列表形式返回解析结果。
urllib.parse.urlencode(query, doseq=False, safe='', encoding=None, errors=None, quote_via=quote_plus):将字典形式或列表形式的请求参数恢复成请求字符串。该函数相当于 parse_qs()、parse_qsl() 的逆函数。
urllib.parse.urljoin(base, url, allow_fragments=True):该函数用于将一个 base_URL 和另一个资源 URL 连接成代表绝对地址的 URL。
二、爬虫解析的库
爬虫解析库的作用就是解析从服务器上获取的网页,然后解析你需要的信息。解析网页我只用过三种库方式, 正则表达式, BeautifulSoup, xpath 。
正则是系统的 xpath和bs4是属于第三方库BeautifulSoup 和 xpath 都是用来解析html数据的。相比之下,xpath的速度会快一点正则使用元字符xpath和bs4将获取的源码转化成一个对象正则无层级结构,只有先后顺序。
1、性能对比
lxml 和正则表达式模块都是C语言编写的,而BeautifulSoup则是纯Python 编写的。下表总结了每种抓取方法的优缺点。
| 选择器 | 性能 | 使用难度 | 安装难度 |
|---|---|---|---|
| 正则表达式 | 快 | 困难 | 简单(内置模块) |
| BeautifulSoup | 慢 | 简单 | 简单(纯Python) |
| lxml | 快 | 简单 | 相对困难 |
图表参考博客:Python网络爬虫四大选择器(正则表达式、BS4、Xpath、CSS)总结
2、学习博客
如果你想要系统的学习这三个库的具体使用方法,可以参考一下博客。
正则表达式:re用法讲解
BeautifulSoup:BeautifulSoup用法讲解
xpath:xpath用法讲解
三、具体实例
1、百度贴吧
1.1要爬取网页的链接在这里,打开网址如图下图:
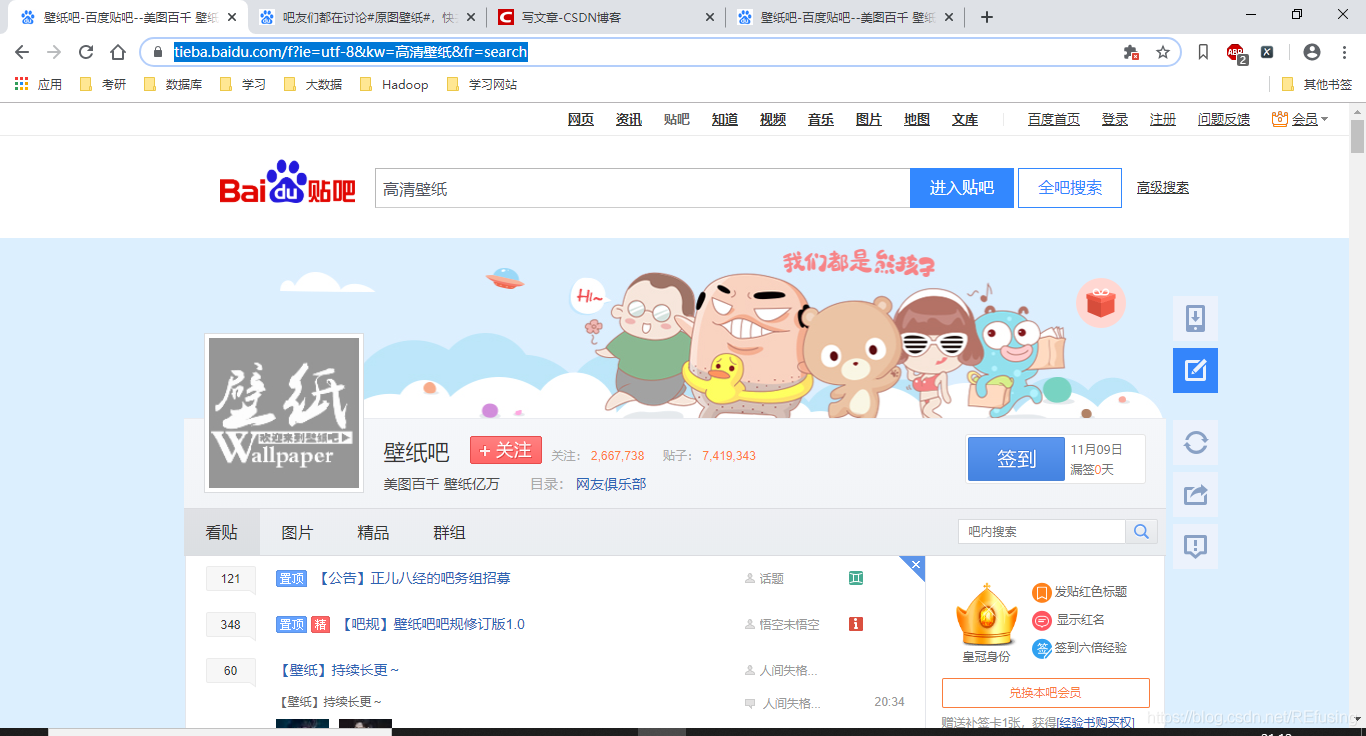
然后你发现链接是:
https://tieba.baidu.com/f?ie=utf-8&kw=%E9%AB%98%E6%B8%85%E5%A3%81%E7%BA%B8&fr=search
但是这个链接是没有规律的,所以就需要我们去转换一下,翻到最底下,如图:

你点2之后把网页的网址记录一下,在次翻到最后,点击1记录网址。然后两个网址记录一下,进行对比。
1.https://tieba.baidu.com/f?kw=%E5%A3%81%E7%BA%B8&ie=utf-8&pn=0
2.https://tieba.baidu.com/f?kw=%E5%A3%81%E7%BA%B8&ie=utf-8&pn=50
你会发现前面的都一样,只是最后的数字不一样,通过这个规律我们可以知道多个网页的网址了。
1.2 获取单个网页
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
}
#模拟浏览器
url = "https://tieba.baidu.com/f?kw=%E5%A3%81%E7%BA%B8&ie=utf-8&pn=0"
# 网址
response = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(response)
#发送请求
html = res.read().decode()
#获取网页
网页获取之后开始分析网页,按F12查看网页代码,如图:
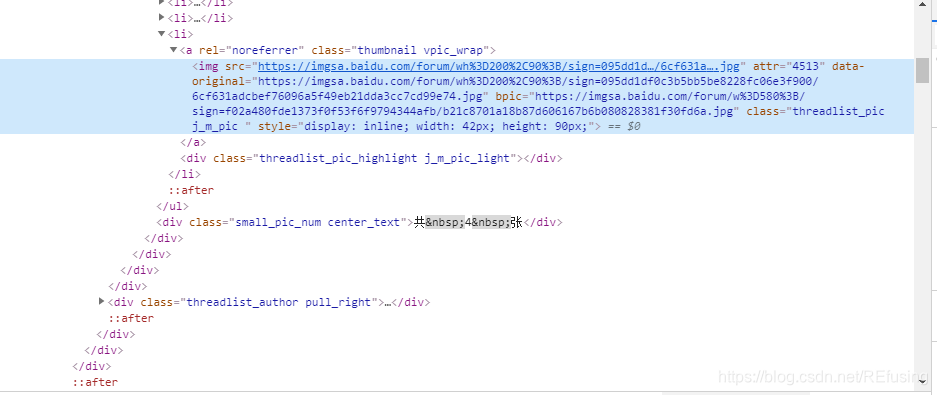
你会发现网址存在的位置没有规律,网址存在的方式不是在同一标签之下排列,所以就需要使用正则表达式提取链接。你会发现所有的图片信息都在下面文本中:
<img src="https://imgsa.baidu.com/forum/wh%3D200%2C90%3B/sign=095dd1df0c3b5bb5be8228fc06e3f900/6cf631adcbef76096a5f49eb21dda3cc7cd99e74.jpg" attr="4513" data-original="https://imgsa.baidu.com/forum/wh%3D200%2C90%3B/sign=095dd1df0c3b5bb5be8228fc06e3f900/6cf631adcbef76096a5f49eb21dda3cc7cd99e74.jpg" bpic="https://imgsa.baidu.com/forum/w%3D580%3B/sign=f02a480fde1373f0f53f6f9794344afb/b21c8701a18b87d606167b6b080828381f30fd6a.jpg" class="threadlist_pic j_m_pic " style="display: inline; width: 42px; height: 90px;">
然后打开链接后发现bpic是张清楚的大图,所以就获取下面的链接如下:
lst = re.findall(r'''bpic="(.*.jpg)"''', html)
按道理说结果应该是正确的,可你会发现多了一些动西,多的是什么呢?多了一些其他的链接以及没有用的东西,经过仔细的思考,发现正则表达式默认的是贪婪匹配也就是匹配最长的一个,所以就需要修改一下。只需要把.变成.?就可以了。
lst = re.findall(r'''bpic="(.*?.jpg)"''', html)
1.3链接获取了你就可以下载图片了,下载图片有一个非常好用的函数urllib.request.urlretrieve(url, name)只需要传网址和图片的名字就可以了,由于这个图片是用户上传的所以不存在名字,所以你就可以随便命名了。然后把获取单个页面封装成一个函数,方便使用。
def load_pic(url):
global num
if lock.acquire():
try:
response = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(response)
html = res.read().decode()
lst = re.findall(r'''bpic="(.*?.jpg)"''', html)#解析
for i in range(0, len(lst)):
num = num + 1
print("第%d个图片正在下载"%num)
id = "D:ipp/" + str(num) + ".jpg"
img = lst[i]
urllib.request.urlretrieve(img, id)#下载图片
lock.release()
except:#防止有的链接不好使,直接跳过
pass
1.4 因为前面已经分析好如何不同页面的网址了,所以只需要把后面的数字和基础的网址拼接一下就可以了。如果你想要加块下载的速度你可以使用多线程,能够快很多,我下载三页图片,用线程的是170秒,不用线程的是224秒,由于我是用数字来作为图片的名字,为了防止冲突,我使用了锁服务。
完整代码:
#爬取贴吧
import urllib.request
import urllib.parse
import re
import threading
import os
import time
burl = "https://tieba.baidu.com/f?kw=%E5%A3%81%E7%BA%B8&ie=utf-8&pn="
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
}
lock = threading.Lock()
num = 0
start = time.clock()
if not os.path.isdir("D:ipp"):
os.mkdir("D:ipp")
def load_pic(url):
global num
if lock.acquire():
try:
response = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(response)
html = res.read().decode()
lst = re.findall(r'''bpic="(.*?.jpg)"''', html)
for i in range(0, len(lst)):
num = num + 1
print("第%d个图片正在下载"%num)
id = "D:ipp/" + str(num) + ".jpg"
img = lst[i]
urllib.request.urlretrieve(img, id)
lock.release()
except:
pass
# page = input("请输入下载的页数")
# page = int(page)
page = 3
for i in range(0, page):
url = burl + str(i * 50)
t = threading.Thread(target=load_pic, args=(url,))
t.setDaemon(True)
t.start()
t.join()
end = time.clock()
print("时间为%d"%(end-start,))
结果如图:

如果你还还行爬取一些高清的图片,那么你可以看看下面的博客:
Python爬取unsplash
2、爬取快代理
这篇爬取的内容是获取代理IP,我们在爬取网站的时候如何肆无忌惮的爬取网页,电脑的IP就会容易被封了,这么一来你就爬取不了你要爬取的网址了,所以获取代理IP也是爬虫中不可或缺的一部分。我之前爬取豆瓣的时候就是因为爬的太快了,当时IP给封了,无奈!
2.1首先搜索快代理网址——在这结果如图:
然后你会看到最上面有一个免费代理,点击一下。如图:
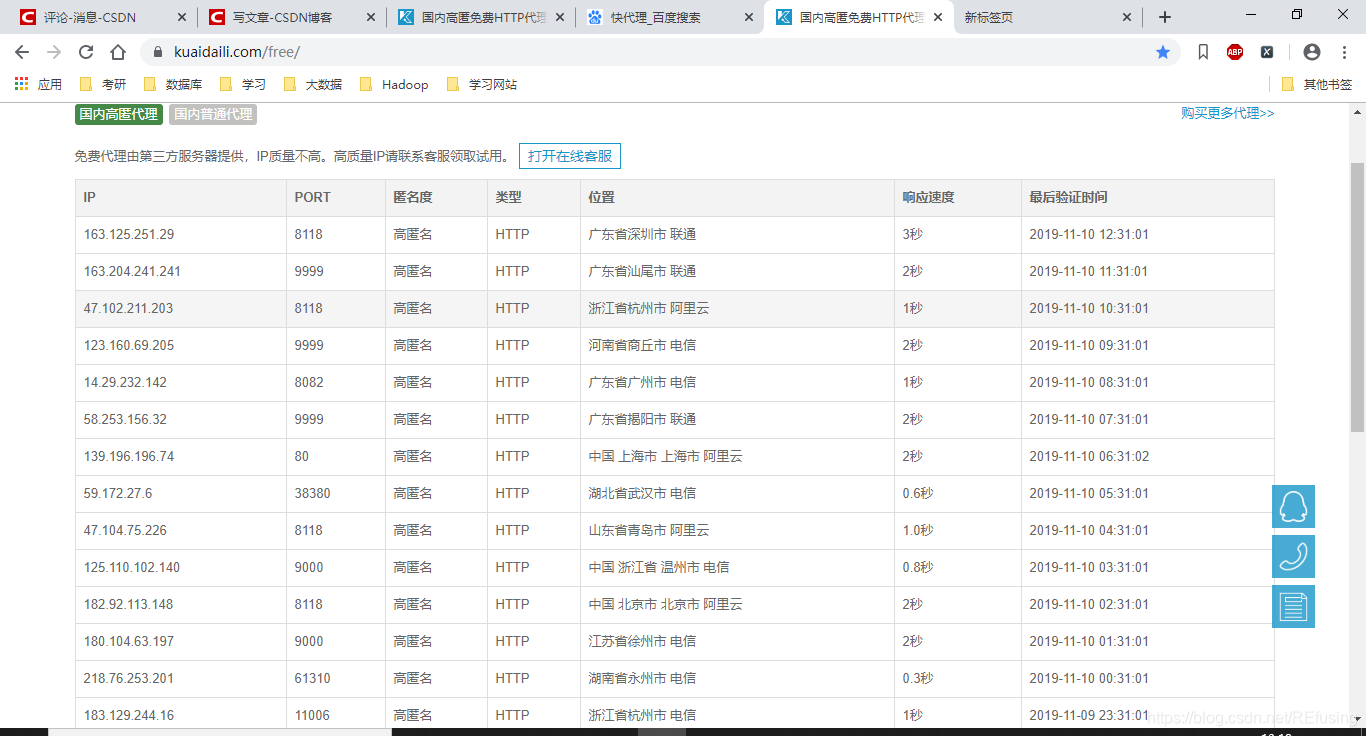
看到了一堆IP和对应的端口号。这个就是我们要的页面,我们的目的就是吧获取页面中IP和端口号,存储在text文件中,存储的格式为下图:
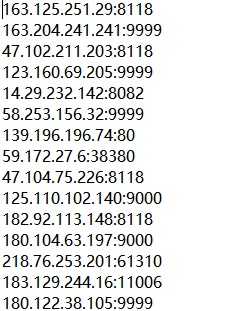
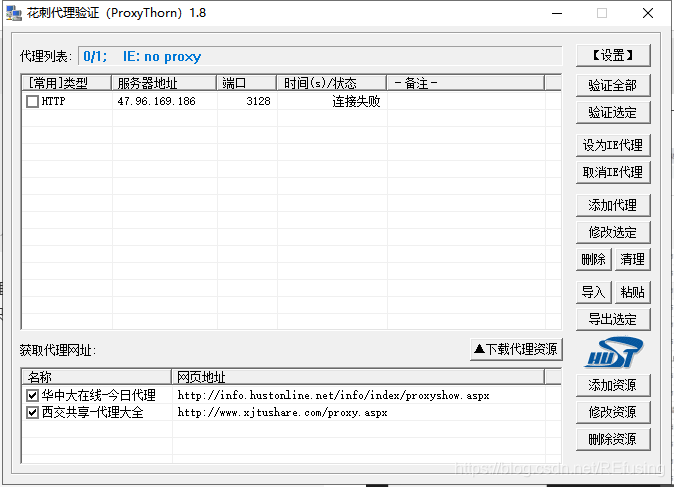
为什么这么存储?因为我们有软件可以测试代理IP好使,这个软件是花刺代理,可以测试IP是否好使,但是导入文件的格式给限定了,只能是上面的那个样式。如图花刺代理:
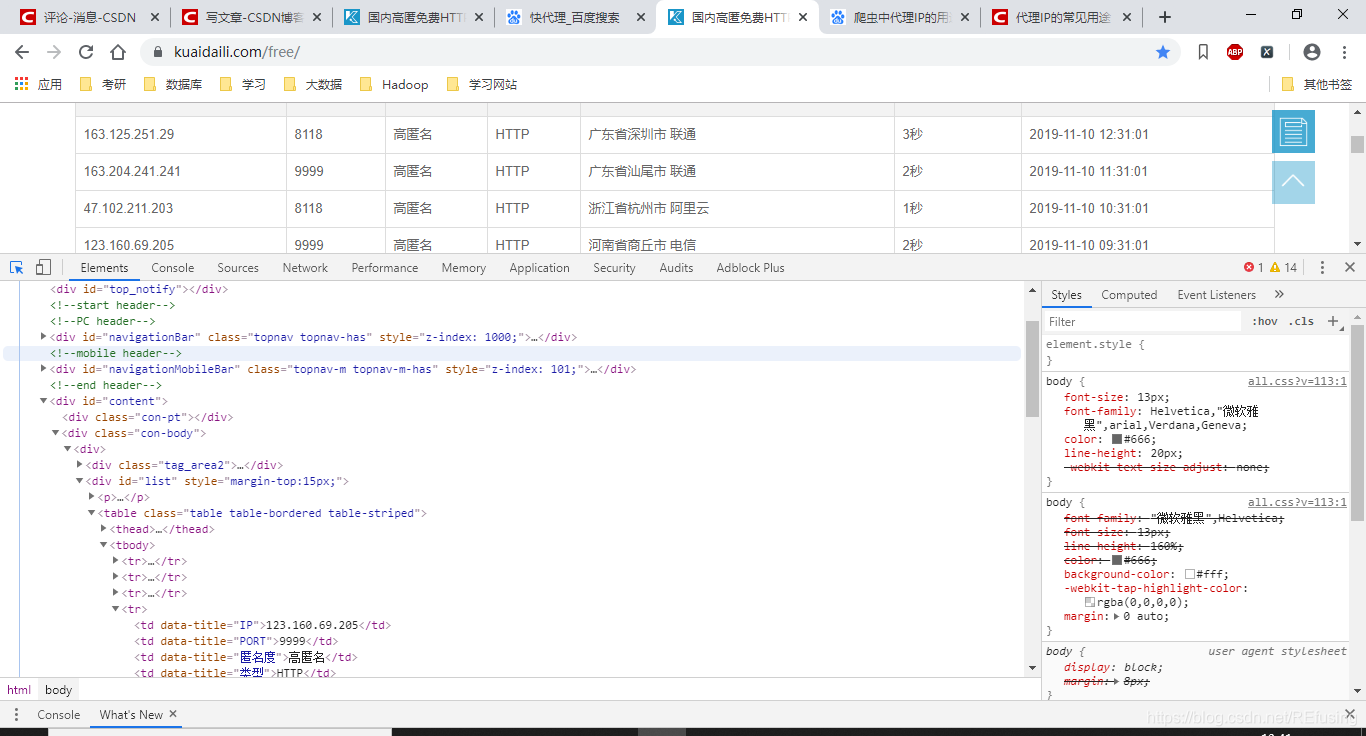
2.2我们开始分析页面,同样的按F12查看网页代码。如图:
然后再按Ctrl + Shift +C,就会产生下面的效果:
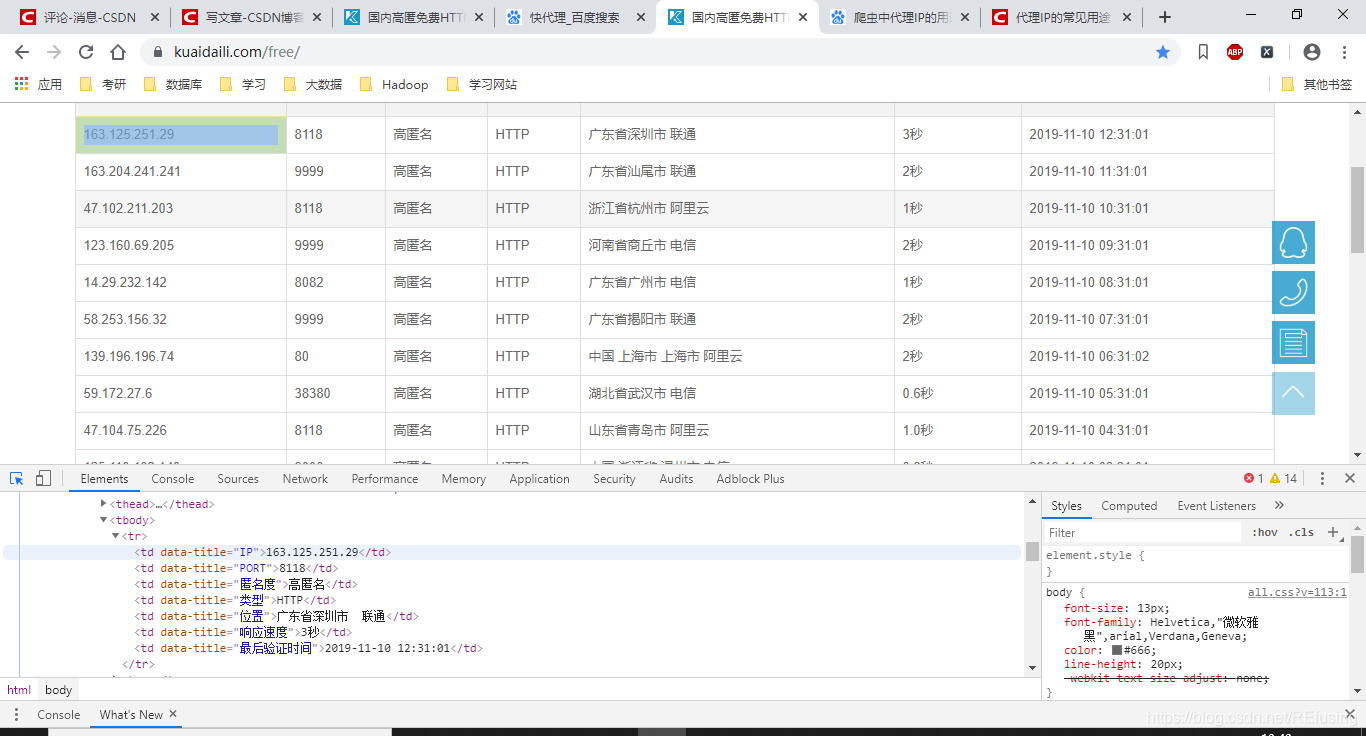
随便点击一个IP,然后右键确定一下,就能看到IP具体存在那个标签里面。点击代码中含有IP的那个标签,再点击右键,出现Copy,Copy xpath如图:
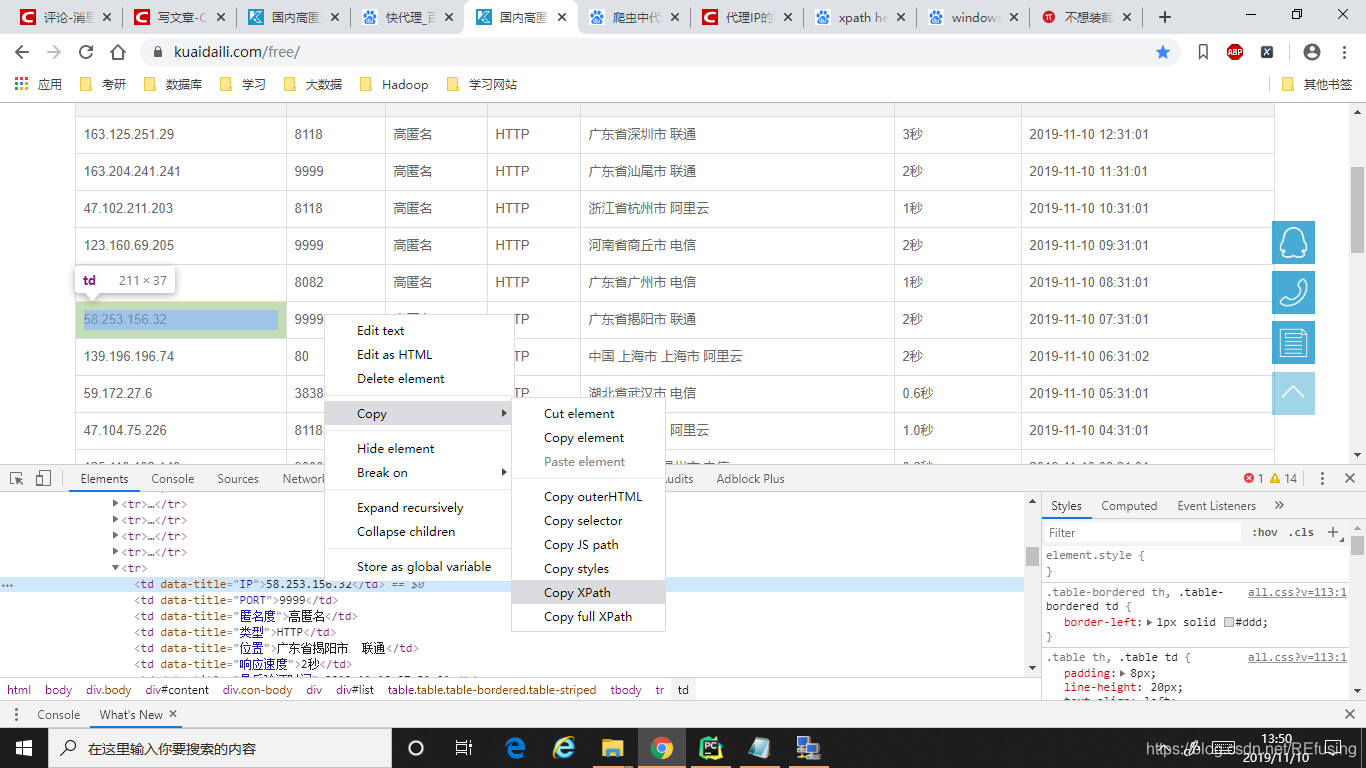
此时你就获取了IP 的xpath也就是IP存储的路径,但是不一定好使,你需要去用一个软件去验证,这软件就是xpath helper他能帮助你验证xpath路径。
路径:
//*[@id="list"]/table/tbody/tr[6]/td[1]/text()
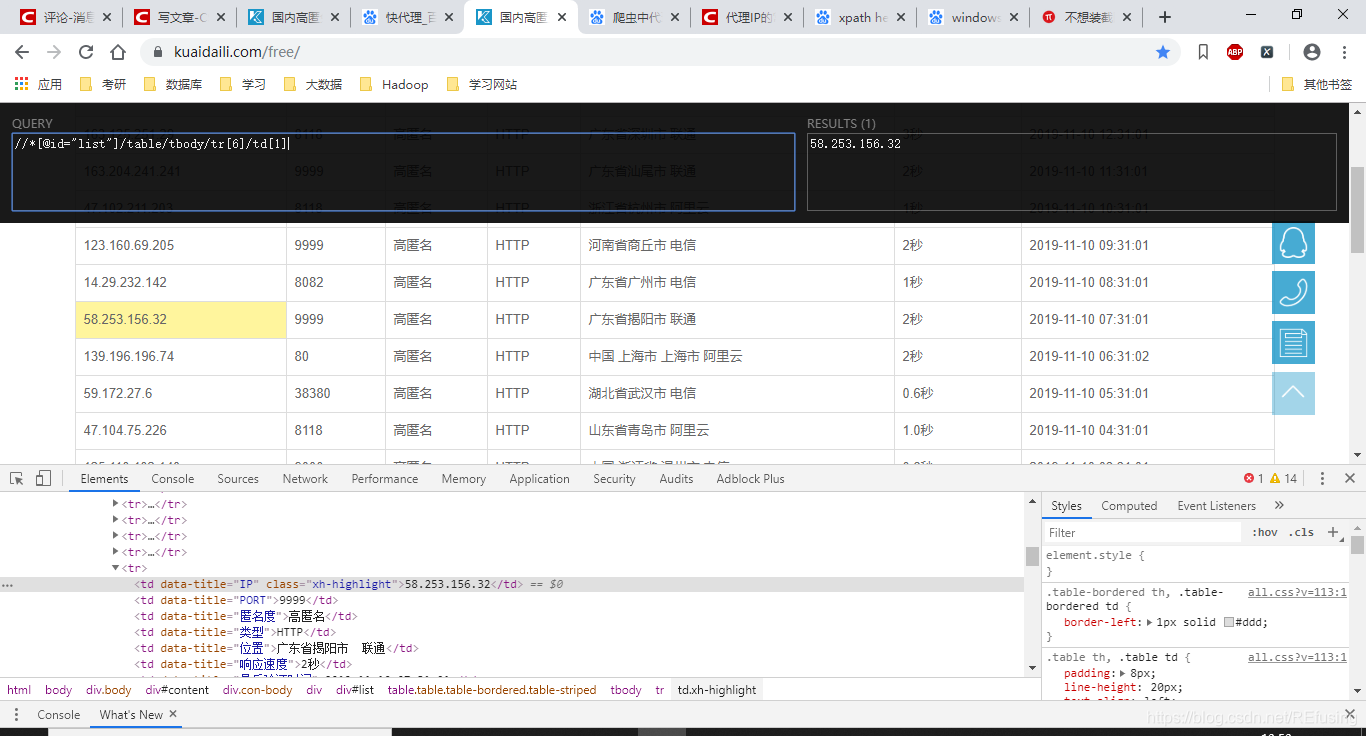
发现结果是正确的但是在使用的时候你获取的应该是纯文本信息,所以需要在候面加一个/text()这个么的就好使了,在爬取的时候就只保留文本信息。
但是结果只有一条IP怎么办呢?我们就只需要删除一点东西就可以了,如图:
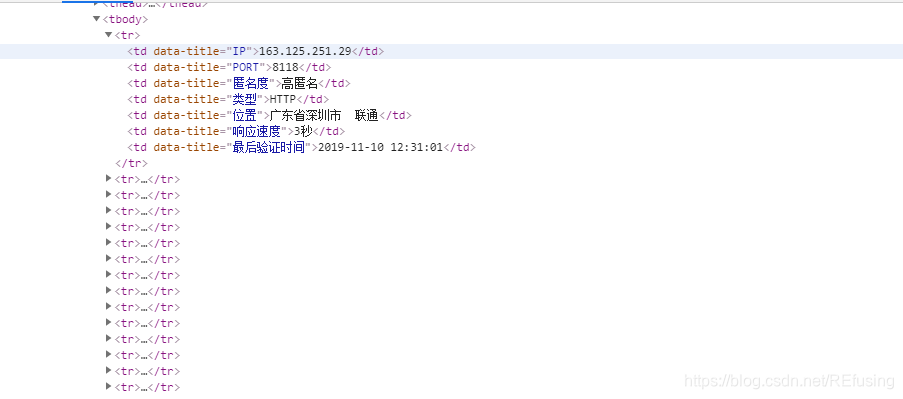
你会发现所有的信息都存储在tbody标签中的中tr标签中,每一个tr标签中存储的使用IP的详细的各种信息。我们只需要把//[@id=“list”]/table/tbody/tr[6]/td[1]/text()
中红色的删去,因为带有数组表示只选取tr标签中的第六个标签,去掉的话就会获取到tr标签中的所有标签。如图:

这么IP就处理完了,但是端口号还没有处理处理,这个过程和上面的过程极其相似,我们只需要把//[@id=“list”]/table/tbody/tr/td[1]/text()中标红的改成2就可以了。如图:

这个给网页我们已经分析完了,那么就开始我们的爬取工作吧。
2.3获取网页的过程和百贴吧的过程基本一致,但是由于该网页的编码问题需要转换一下,增加几个句子,依旧把封装成函数了。又到分析页面的时候,和分析百度贴吧页面网址的方法是一致的。获取的网址如下
https://www.kuaidaili.com/free/inha/1/
https://www.kuaidaili.com/free/inha/2/
很容易看出规律,稍微拼接一下就可以了,总代码如下:
#爬取ip
import urllib.request
from bs4 import BeautifulSoup
from io import BytesIO
from lxml import etree
import gzip
import threading
import os
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
}
base_url = "https://www.kuaidaili.com/free/inha/"
if not os.path.isdir("D:/ip_get"):
os.mkdir("D:/ip_get")
def load_ip(num):# 数字是页面的序号
url = base_url + str(num) + "/" #网址的拼接
requests = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(requests)
html = response.read()
##下面的三个句子是进行编码的修改
buff = BytesIO(html)
f = gzip.GzipFile(fileobj=buff)
ans = f.read().decode('utf-8')
tree = etree.HTML(ans)#构造要解析的对象
res1 = tree.xpath("""//*[@id="list"]/table/tbody/tr/td[1]/text()""")#解析IP 的路径
res2 = tree.xpath("""//*[@id="list"]/table/tbody/tr/td[2]/text()""")#解析port的路径
print("第%d个正在下载中"%num)
try:
with open("D:/ip_get/" + str(num) + ".txt", 'w')as f:#保存
for i in range(0, len(res1)):
f.write(res1[i] + ":" + res2[i] + "\n")
except:
pass
for i in range(1, 3134):
t = threading.Thread(target=load_ip, args=(i,))
t.setDaemon(True)
t.start()
t.join()
结果如图:
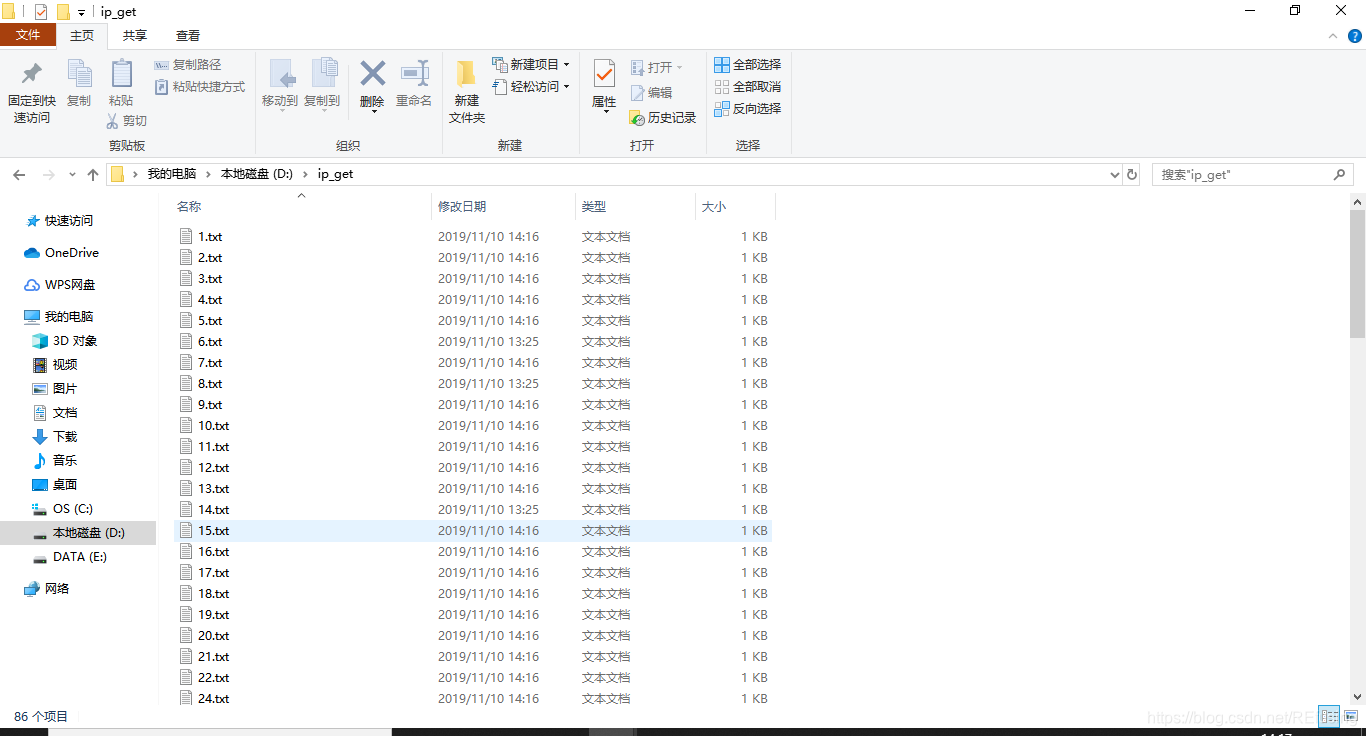
3、爬取百度翻译
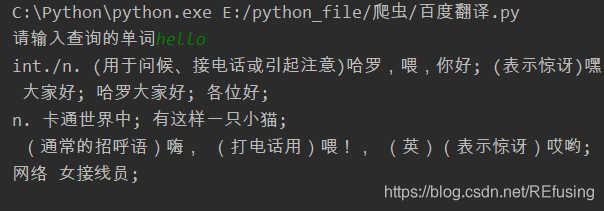
这篇博客是获取百度翻译软翻译你输入的单个英文单词的意思,不能翻译整个句子的意思。
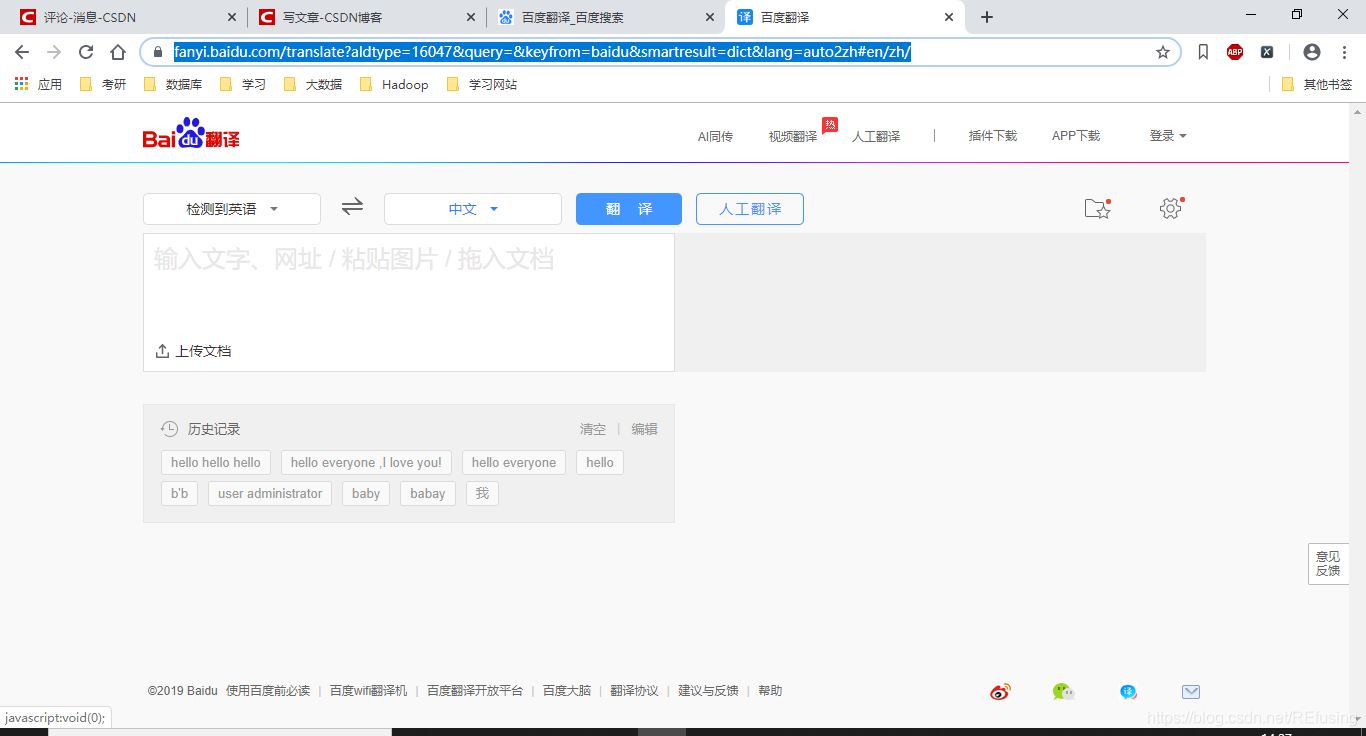
3.1当仁不让的就是打开网址——这 , 如图:
我们先输入几个英文字母试试,如图:
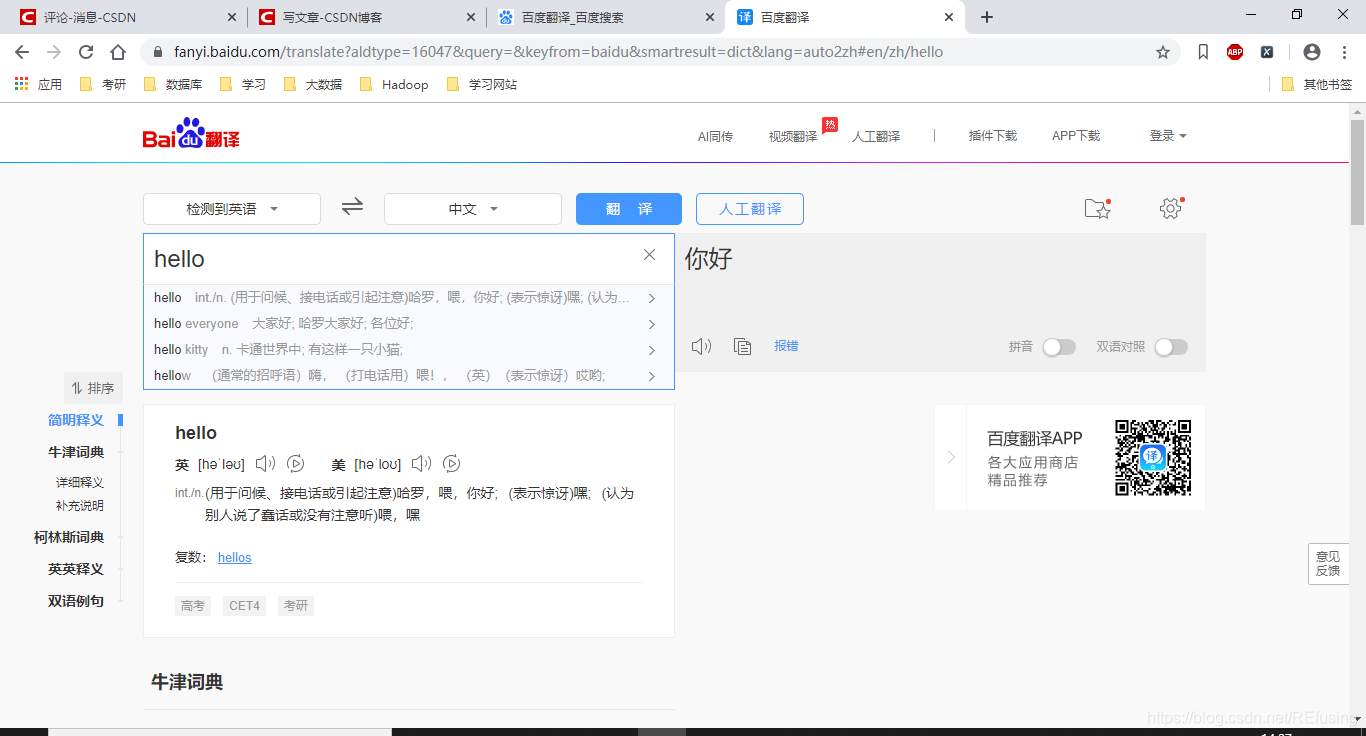
发现他的网址并没有改变,这说明什么,在你输入hello的时候那个获取内容,而网址没有发生该变这个说明这个网址,主体是HMTL的形式,但是他的核心内容是JavaScript,所以这个请求的方法就跟之前的不一样了。那这么我们怎么搞呢?
莫方,有办法,同样的是按F12 键,如图:
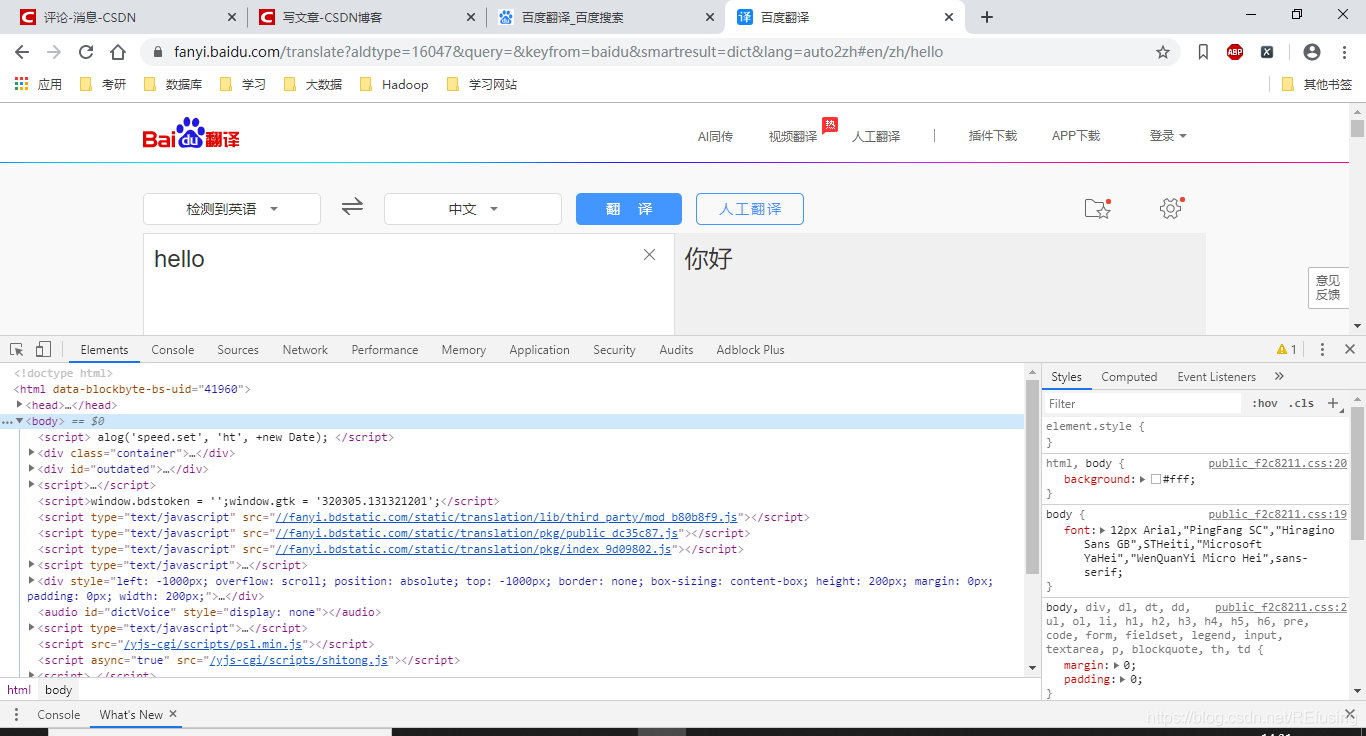
然后从Elements切换到Network,如图:
你试着输入一个单词试试,发现什么了?
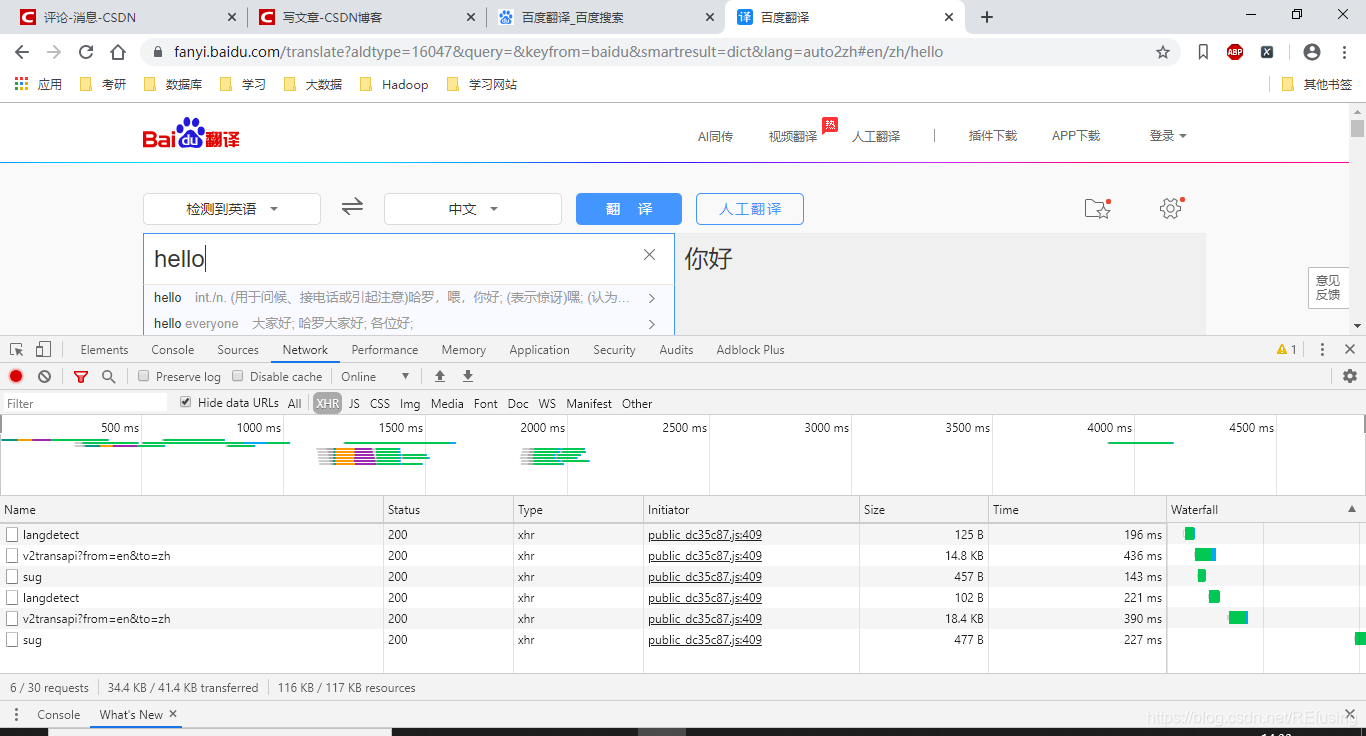
是不是页面多了一点东西,我们点击一下sug:
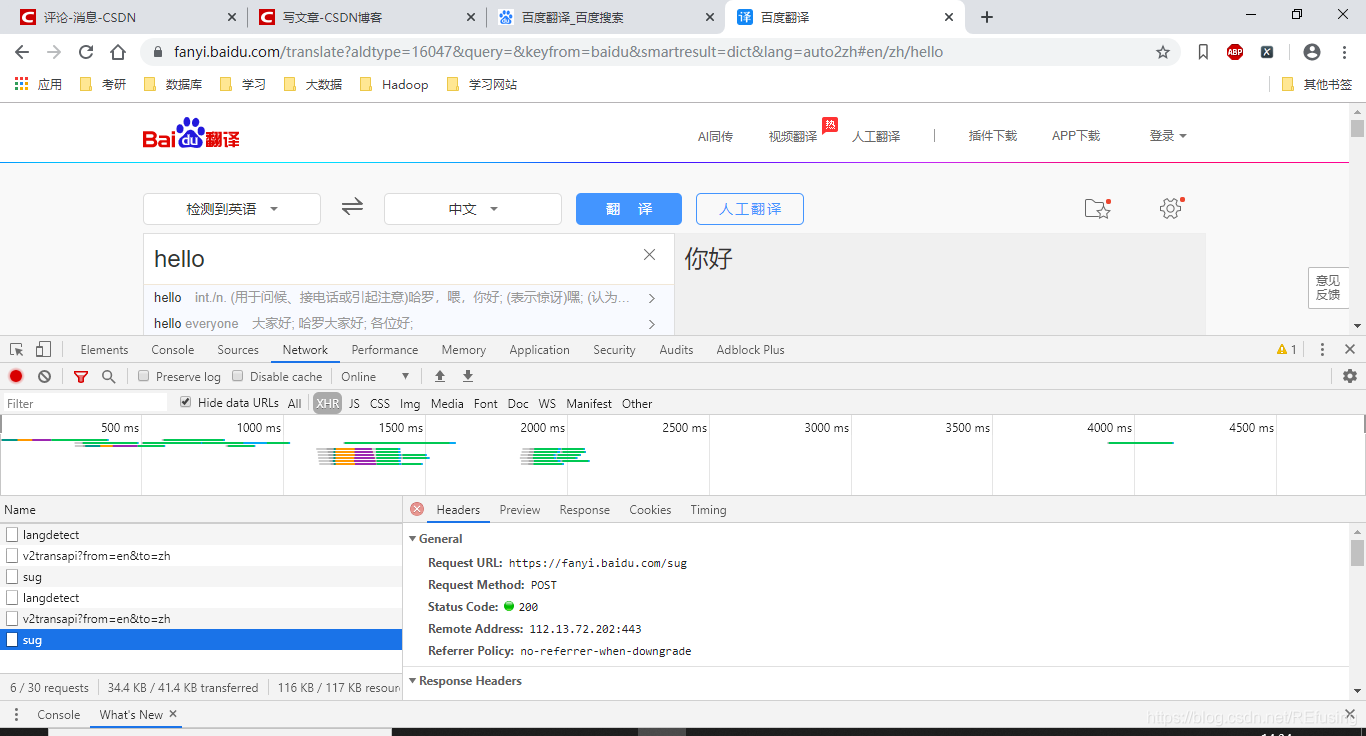
主要获取翻译内容的是这个链接:
https://fanyi.baidu.com/sug
然后传参的是这个字典类型

3.2该获取的信息都已经明确了开始写代码吧!链接如下:
url = 'https://fanyi.baidu.com/sug?'
链接字典类型:
value = input("请输入查询的单词")
data = {
'kw':value
}
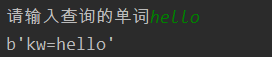
data_form = urllib.parse.urlencode(data).encode()
print(data_form)
结果为:
获取数据:
requests = urllib.request.Request(url = url, headers = headers)
response = urllib.request.urlopen(requests, data = data_form)#json 传参数
text = response.read().decode()
结果:

JavaScrip使用的数据类型是字典,所以我们要转换数据类型为字典数据类型。
这个转换使用的库为json库----python的JSON库
js = json.loads(text)
结果:

通过上面的图,我们发现翻译的数据存储在js[‘data’]里面的字典中的’v’的映射中。
data = js['data']
for i in data:
print(i['v'])
完整代码:
#百度翻译
import urllib.request
import urllib.parse
import json
url = 'https://fanyi.baidu.com/sug?'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
}
value = input("请输入查询的单词")
data = {
'kw':value
}
data_form = urllib.parse.urlencode(data).encode()
print(data_form)
requests = urllib.request.Request(url = url, headers = headers)
response = urllib.request.urlopen(requests, data = data_form)#json 穿参数
text = response.read().decode()
js = json.loads(text)
data = js['data']
for i in data:
print(i['v'])
结果:
3.豆瓣电影top250
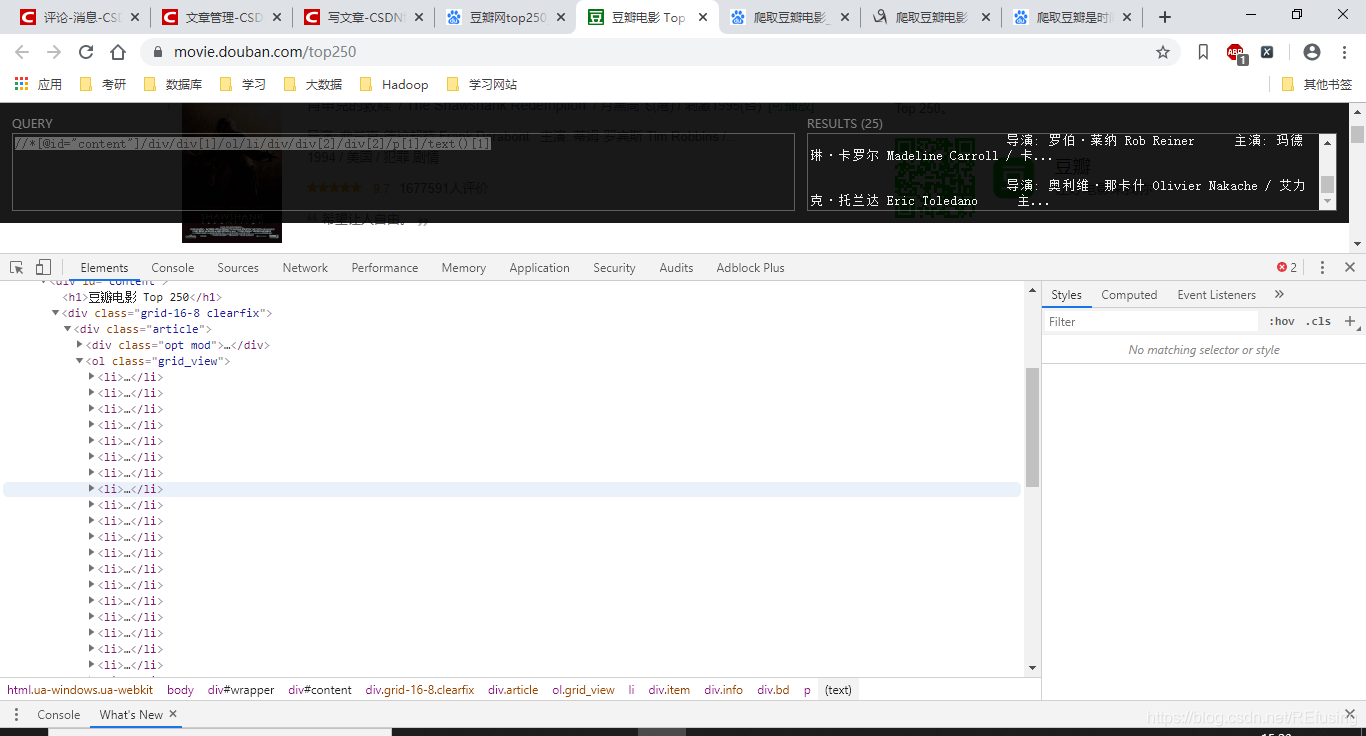
找到网址—豆瓣电影 Top 250,分析网页,方法和之前类似,我么需要找找的信息是”电影名, 导演,主演, 类型",通过xpath获取路径。
路径:
//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[2]/p[1]/text()[1]
结果:

你会发现所有的信息都存储在li标签中只需要把li[1]的[1]去掉就可以,如图:
编写代码:
import urllib.request
from lxml import etree
import json
## 获取页面
url = "https://movie.douban.com/top250"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
}
response = urllib.request.Request(url = url, headers = headers)
res = urllib.request.urlopen(response)
html = res.read().decode()
## 解析网页
tree = etree.HTML(html)
name = tree.xpath("""//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[1]""")
print(name)
运行结果

页面分析代码:
import urllib.request
from lxml import etree
import re
## 获取页面
url = "https://movie.douban.com/top250"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
}
try:
response = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(response)
html = res.read().decode()
## 解析网页
tree = etree.HTML(html)
name = tree.xpath("""//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[1]""")
kind = tree.xpath("""//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[2]""")
name = [x.strip() for x in name]
print(name)
for i in name:
director = re.findall(r"导演: ([\u4e00-\u9fa5]+.[\u4e00-\u9fa5]+)", i)
actor = re.findall(r"主演: ([\u4e00-\u9fa5]+.?[\u4e00-\u9fa5]+)", i)
print(director[0], actor[0])
print(director)
except:
pass
结果:

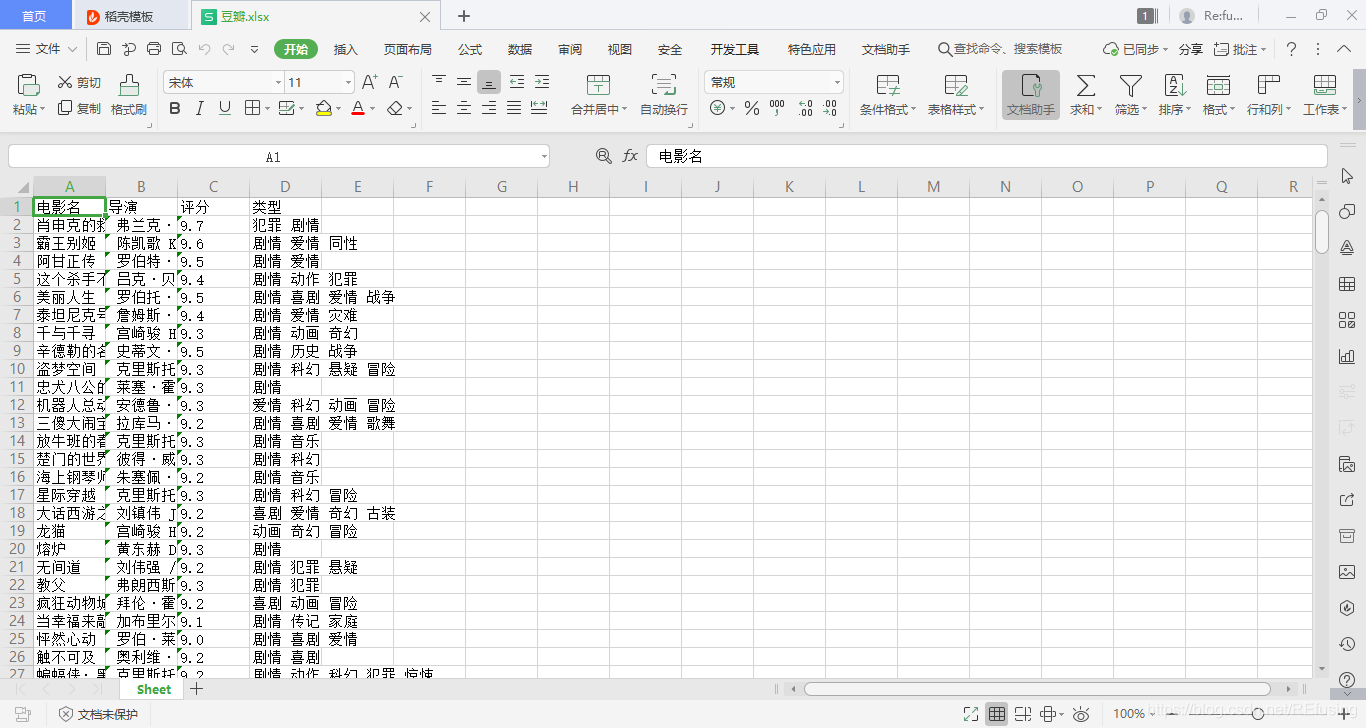
最终代码:
import urllib.request
from lxml import etree
import re
from openpyxl import workbook # 写入Excel表所用
from openpyxl import load_workbook
import threading
## 获取页面
url = "https://movie.douban.com/top250"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"
}
def add(movie, dir, rate, kind):
print(len(movie), len(dir), len(rate), len(kind))
for i in range(0, len(movie)):
ws.append([movie[i], dir[i], rate[i], kind[i]])
def load(url):
try:
lock.acquire()
response = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(response)
html = res.read().decode()
## 解析网页
tree = etree.HTML(html)
movie = tree.xpath("""//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()""")
name = tree.xpath("""//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[1]""")
kind = tree.xpath("""//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[2]""")
## 去掉空格之类的东西
mark = tree.xpath("""//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()""")
name = [x.strip() for x in name]
kind = [x.strip() for x in kind]
director = []
catalog = []
## 电影类型处理
for i in kind:
catalog.append(i.split("\xa0")[-1])
## 导演, 演员处
for i in name:
director.append(i.split(":")[1].split("\xa0\xa0\xa0")[0])
except:
pass
add(movie, director, mark, catalog)
lock.release()
if __name__ == '__main__':
base = "https://movie.douban.com/top250?start="
lock = threading.Lock()
wb = workbook.Workbook() # 创建Excel对象
ws = wb.active
ws.append(['电影名', '导演', '评分', '类型'])
for i in range(0, 10):
url_res = base+str(i*25)
t = threading.Thread(target=load, args=(url_res,))
t.setDaemon(True)
t.start()
t.join()
wb.save("D:豆瓣.xlsx")
结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号