Linux常用命令及场景
Linux常用命令查询
*$为可选命令
命令行快捷键
ctrl + a 移动光标至字符头
ctrl + e 移动光标至字符尾
ctrl + l 清屏
通用
终端管控tty
# 查看当前终端信息
$ tty
# 关闭当前终端
$ pkill -9 -t tty4
# 进程详情,tty列可以知道在哪个终端正在运行哪个CMD
$ ps -ax
# 关闭终端密码输入模式,回显展示内容
$ stty echo
系统管理员sudo
$ sudo command
文件管理
局域网传送文件python&wget
# 目标主机局域网IP
$ ifconfig
# 目标主机上开启传输端口(注意切换到要传输文件目录路径下)
$ python -m http.server 8888
# 操作主机上下载文件
$ wget -c "ip:port/path/to/file"
复制文件内容pbcopy <
$ pbcopy < file
展示文件ll&du
# 显示文件详情信息(非文件夹),~/.bash_profile添加LL命令:alias ll='ls -alhF'
$ ll file
# 显示各文件(文件夹)大小(磁盘空间)
$ du -sh *
排序sort
# 按文件名排序
$ ll -l | awk '{print $9}' | sort -k1.1nr
# sort -k1.1 小数点前面的1表示按第一列排序,后面的1表示从文件名的第一个字符开始排序
# sort -n 按照数值大小排序
# sort -r 反向排序
创建文件touch
$ touch fileName.txt
解压缩tar
# 解压以gzip压缩的文件到指定目录下
$ tar -zxvf pkg.tar.gz -C /path
# 以gzip压缩指定目录下的指定文件
$ tar -zcvf pkg.tar.gz /path/file.txt
其他文件格式的解压缩:https://blog.csdn.net/kingschan/article/details/19033637
分页展示|more
# 空白键(space)往下一页显示,按 b 键就会往回(back)一页显示
$ command |more
# 每页显示n行
$ command |more -n
# 从第n行开始展示
$ command |more +n
常用文件查看操作
$ tail -n 100 filename #查看前100行
$ tail -f #tai
$ head -n 100 filename #查看后100行
$ wc -c filename #查看文件里有多少字节
$ wc -l filename #查看文件里有多少行
$ cat filename | grep "xxxx" -C 50 #显示上下50行
文件操作sed
$ sed -n ‘5,10p’ filename #查看文件的第5行到第10行
$ sed -n "m,np" a.txt > b.txt #将a.txt的m到n行复制到b.txt中
$ sed "s/xx/oo/g" a.txt #将a.txt中的xx替换为oo,并打印在屏幕
$ sed -i "s/xx/oo/g" a.txt #原文件中查找替换
$ sed -i "s/11/22/g;s/33/44/g;s/55/66/g" a.txt #批量替换
$ sed -i "/^\s*$/d" a.txt #删除空行(d代表删除)
$ find /etc -type f -name "*.conf" | xargs sed -i 's/old_value/new_value/g' #批量修改配置文件
文件对比diff
$ diff [命令行参数] file1 file2
a 将所有文件当做文本文件来处理
b 忽略空格造成的不同
B 忽略空行造成的不同
q 只报告什么地方不同,不报告具体的不同信息
H 利用试探法加速对大文件的搜索
i 忽略大小写的变化
l 用pr对输出进行分页
r 在比较目录时比较所有的子目录
s 两个文件相同时才报告
v 在标准输出上输出版本信息并退出
搜索grep
$ grep "str" filename #习惯搜索的字符串加上双引号
# grep "$a" file #引用变量a,查找变量a的值
# grep '$a' file #查找“$a”字符串
$ grep -r "str" * #在当前目录及其子目录下搜索,-r和*配合使用
$ grep -i "str" filename #不区分大小写
$ grep -n "str" filename #显示行数
$ grep -c "str" filename #统计出现的次数
$ grep -v "str" filename #显示不匹配的行
$ grep -e "reg" filename #正则匹配
$ grep "[0-9]* ERROR" #正则匹配实例
$ cat mirageDB.list | grep -o "[0-9]*[.][0-9]*[.][0-9]*[.][0-9]*" #只打印匹配的部分

重复行uniq
#去掉相邻重复的数据行
$ cat data1.txt | uniq
#去掉所有重复的数据行
$ cat data1.txt | sort | uniq
#统计重复行
$ cat data1.txt | sort | uniq -c
查找文件find
$ find / -name "*jdk*" #根目录下查找文件名中有jdk的文件
$ find . -name "*.in" #从当前目录开始查找所有扩展名为 .in 的文本文件
$ sudo find / -type f -size +500000k -exec ls -lh {} \; | awk '{ print $9 ": " $5 }' #查找>500M大文件
查找环境变量中的文件which
$ which -a jdk
清除文件内容echo
$ echo "" > statistic.log
创建软硬链接ln
https://www.zhihu.com/question/420367183/answer/2924040658
https://zhuanlan.zhihu.com/p/455508513
$ ln -s src_file slink_file
$ ln src_file hardlink_file
复制文件cp
# 复制源文件(夹)到目标文件(夹)
$ cp -r src_file(dir) target_file(dir)
# 更新文件(夹)
$ cp -u src target
# 创建软链接
$ cp -s src target
# 创建硬链接
$ cp -l src target
# 复制文件,只有源文件比目标文件的修改时间新时,才复制文件
$ cp -u -v src target
下载内容wget
# 默认下载当前目录
$ wget url
# 指定路径和文件名,注意大写O
# wget -O /home/ym/demo.tar url
创建文件夹mkdir
# 按路径依次创建文件夹
$ mkdir -p /tmp/usr/local
查询历史执行命令history
$ history
包管理
yum(Redhat/Centos/Fedora)
# 基于rpm包管理,从指定的服务器自动下载rpm包并且安装,自动处理依赖性关系,一次安装所有依赖的软件包
# 安装rpm包的命令是“rpm -参数”
# 安装
$ yum install pkgName
# 更新源
$ yum update pkgName
$ yum upgrade pkgName
# 显示所有已经安装和可以安装的程序包
$ yum list
$ yum list pkgName
# 显示安装包信息
$ yum info pkgName
$ yum remove pkgName
$ yum search pkgName
换源:https://blog.csdn.net/sinat_33384251/article/details/91404617
apt-get(Debian/Ubuntu)
# 基于deb包管理,自动从互联网的软件仓库中搜索、安装、升级、卸载软件或操作系统
# 安装deb包的命令是“dpkg -参数”
# 移除的同时清除配置
$ apt-get purge pkgName
# 下载软件包的源码
$ apt-get source pkgName
# 列出已安装的所有软件包
$ dpkg -l
$ apt-cache search pkgName
$ apt-cache show pkgName
换源:https://www.cnblogs.com/bigcola/p/13378638.html
brew(MacOS)
下载homebrew:https://www.cnblogs.com/bigcola/p/13378638.html
tar(SourceCodePkg)
tar、rpm、deb:
https://blog.csdn.net/liu865033503/article/details/86014773
https://blog.csdn.net/bandaoyu/article/details/83312230
$ tar -zxvf pkg.tar.gz -C /path
$ cd /path/pkg
# 指定软件安装目录
*$ ./configure -prefix=/path
# 编译
$ make
# 安装
$ make install
# 删除安装时产生的临时文件
$ make clean
# 卸载
*$ make uninstall
Shell
分屏tmux
$ sudo yum install tmux
step1:开启tmux
$ tmux
step2:开启左右分屏(注意MacBook上是control键)
$ ctrl+b -> %(shift+5)
step3:分屏切换
$ ctrl+b -> ↑↓←→(四个键)
step4:翻屏
$ ctrl+b -> [(左中括号)-> pageUp/paDn
step5:退出tmux
$ ctrl+b -> d
# 查询开启的分屏进程
$ tmux -ls
# 关闭所有sessions
$ tmux kill-server
# 关闭指定session
$ tmux kill-session -t targetSession
脚本编写
数组:https://www.runoob.com/linux/linux-shell-array.html
### 聚类统计文本
#!/bin/bash
echo "start!"
a=(
"str1"
"str2"
)
b=(
"str3"
"str4"
)
i = 0
for str in ${b[*]}
do
echo ${a[$i]},$str
cat statistic.log | grep ${a[$i]} | grep -c $str
done
if [-e filename] # 文件存在
文件路径

Shell通配符(匹配文件名)
常用于find、ls、cp 、mv
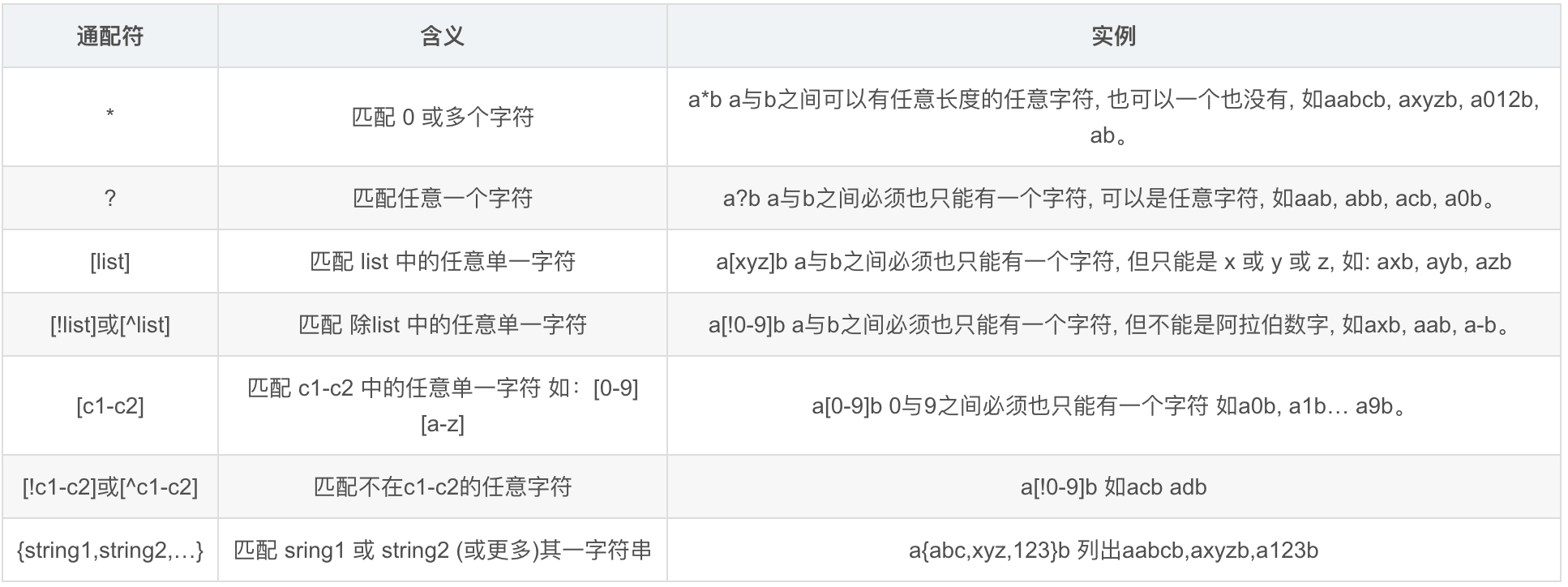
Shell正则(匹配字符串)
常用于vi,grep,awk,sed
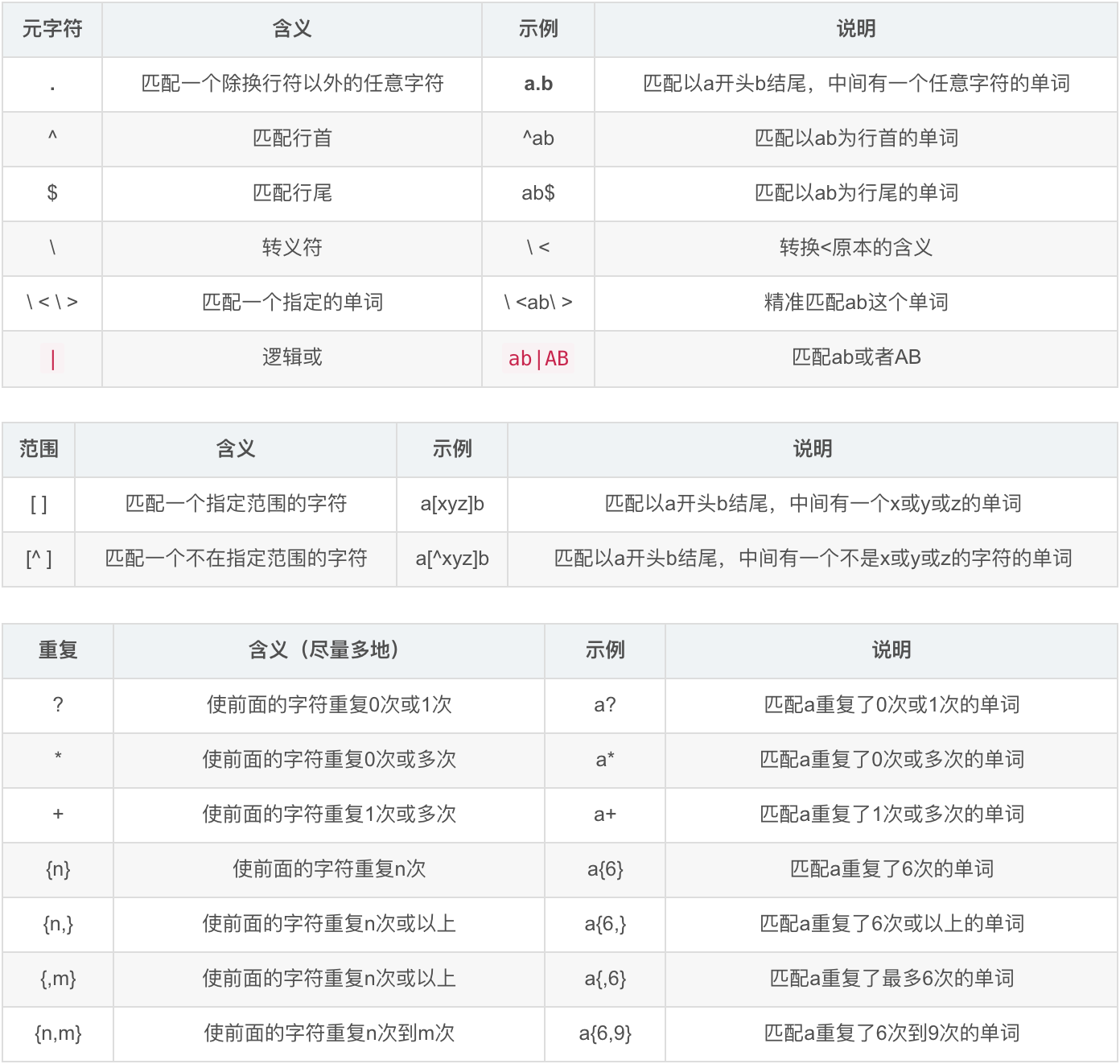
后台执行命令&
# 后面的命令在该行命令执行完成并返回前就能得到执行,不加为阻塞式执行
$ command &
后台执行命令nohup
https://www.cnblogs.com/yourenbo/p/18067565
# 命令会在后台运行train.sh,同时将标准错误重定向到标准输出,然后再将标准输出写入到log.out文件中
$ nohup train.sh > log.out 2>&1 &
连接多个命令&&
$ make && make install #前一个命令执行成功(返回true),执行后一个命令
执行文件命令source&.&./xx.sh&sh
https://www.maixj.net/ict/linux-source-18000
$ sh -c 'command string' #sudo sh -c 'command string'可以让command string所有命令都有sudo权限
输出到文件>
追加到文件>>
查看命令参数详情man
$ man top
查看磁盘空间df
$ df -h
查看当前系统信息uname
$ uname -a
查看当前目录绝对路径pwd
$ pwd
传递命令参数|xargs
为什么有xargs: http://www.ruanyifeng.com/blog/2019/08/xargs-tutorial.html
使用:http://linux.51yip.com/search/xargs
$ ls |grep .php |xargs -i mv {} {}.bak #将当前目录下php文件,改名字
环境变量export/env/echo
$ env #显示所有的环境变量
$ export HELLO="Hello!" #导入环境变量
$ echo $HOME #查看环境变量HOME
常用
网络相关
抓包tcpflow(流数据)
$ sudo yum install tcpflow
# 跟踪当前机器上的流量,keyInfo可以是某个接口名
$ sudo tcpflow -cp | grep keyInfo
# 监听eth0端口上的流量
*$ sudo tcpflow -cp -i eth0
抓包tcpdump(包数据)
# 查询网卡
$ ifconfig -a
# 监听网卡eth0流量(指定端口、指定协议、展示详细报文)
$ sudo tcpdump -n -i eth0 [port 80] [tcp and udp] [-vv]
# 监听ip/hostname相关流量
$ sudo tcpdump -n -i eth0 [host 119.176.28.151/www.baidu.com]
# 指定数据流方向(src源端dst目的端)
$ sudo tcpdump -n -i eth0 src 33.7.126.147 and dst 33.10.147.254
# 写入文件,下载后可在wireshark分析
$ sudo tcpdump -n -i eth0 -w file.cap
获取网络数据curl
# url为下载文件时进行内容展示,-v展示完整http通信过程
$ curl -v "url" | more
# 指定ip和port访问
$ curl "url" -x "11.11.11.11:80"
# --resolve HOST:PORT:ADDRESS 将 HOST:PORT 强制解析到 ADDRESS, 用于https域名指定访问ip和port访问
$ curl --resolve www.baidu.com:443:103.15.99.85 "url"
# 自动跳转,如www.sina.com会自动跳转到 www.sina.com.cn
$ curl -L www.sina.com
# get请求携带多个header
$ curl -H "Referer: xxx.com" -H "Cookie: xxxxx" "url"
# post请求(-X大写), form方式
$ curl -X POST -d "param1=value1¶m2=value2" "url"
# post请求(-X大写),json方式
$ curl -H "Content-type: application/json" -X POST -d '{"phone":"13521389587","password":"test"}' "url"
https://blog.csdn.net/z69183787/article/details/124880735
@GetMapping("/example1")
public void example1(Float money, String product){}
$ curl "http://localhost:8888/example1?money=123&product=洗洁精"
@GetMapping("/example2")
public void example2(String[] keywords){}
$ curl " http://localhost:8888/example2?keywords=123 ,456"
@GetMapping("/example3")
public void example3(SubTestDTO subTest){}
public class SubTestDTO { private String content; private String remark;}
$ curl "http://localhost:8888/example3?content=测试内容&remark=11"
参考:https://www.cnblogs.com/guixiaoming/p/8507268.html
域名解析dig
$ dig www.isc.org
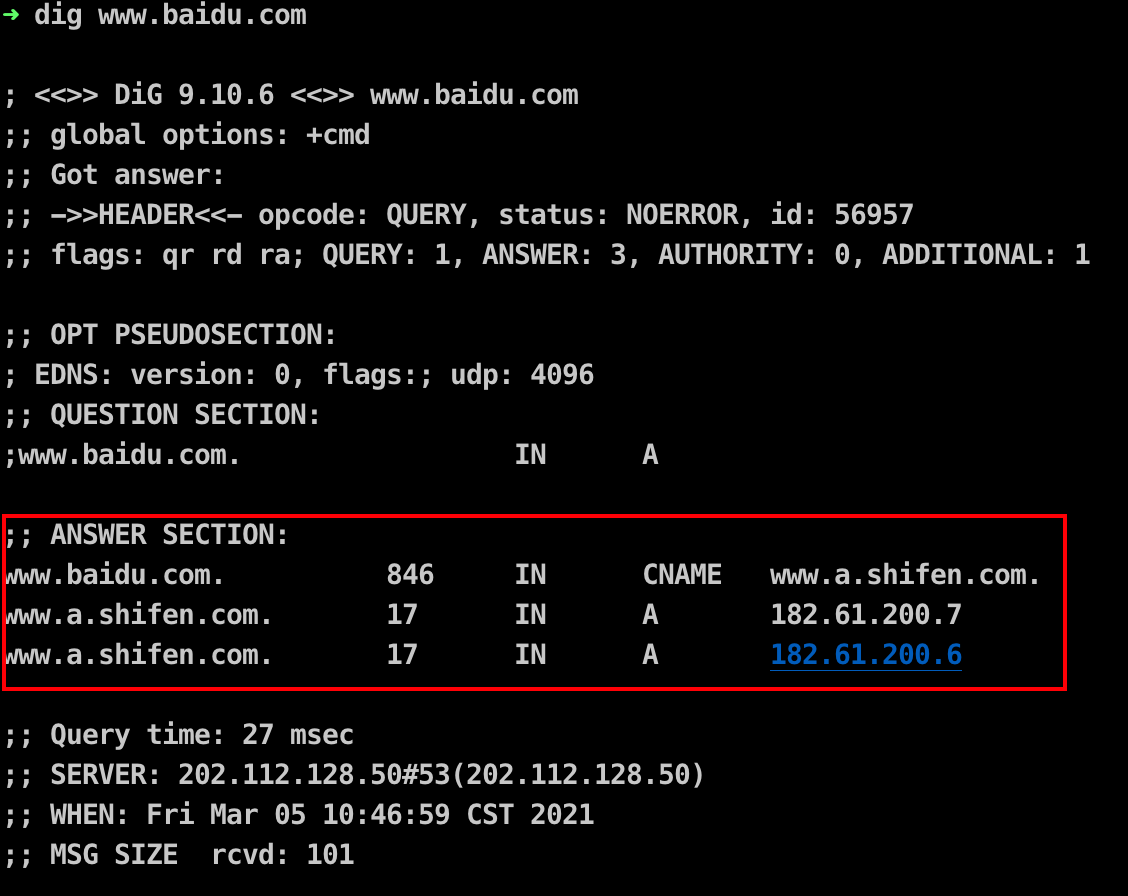
参考:https://www.jb51.net/article/154701.htm
远端登入telnet
$ telnet 127.0.0.1 12201
参考:https://www.runoob.com/linux/linux-comm-telnet.html
远端登录&文件传输ssh/scp
$ ssh tianhong@10.130.147.226
$ scp username@ip:/path/filename /localPath # 下载服务器文件到本地
$ scp /localPath/file username@ip:/path/ # 上传文件到服务器
查看ip
# 查询本机公网IP
$ curl ipinfo.io
# 查询指定IP信息
$ curl ipinfo.io/103.208.15.138
$ ifconfig | grep "inet " | grep -v 127.0.0.1
查看主机名hostname
$ hostname
修改host文件
$ sudo vi /etc/hosts
查看端口占用lsof
$ lsof -i:port
网络连接netstat
# 查看网络连接
$ netstat -anp [grep port] [grep pid]
# TCP连接池中各个连接的状态及数量
$ netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
实时监控watch
# 每秒监控一次显存详情
$ watch -n 1 nvidia-smi
进程详情
ps
$ ps aux | grep keyInfo
# 利用管道快捷kill掉进程
$ ps -aux | grep "python" | grep -v grep | cut -c 9-15 | xargs kill -9
# elf查看进程状态和父进程 https://blog.csdn.net/Dontla/article/details/120928551
$ ps -elf

R(运行)//进程正在运行或在运行队列中等待。
S(中断)//进程处于休眠中,当某个条件形成后或者接收到信号时,则脱离该状态。
D(不可中断)//无法中断的休眠状态,进程不响应系统异步信号,即便用kill命令也不能将其中断。(通常IO进程)
Z(僵死)//进程已经终止,但进程描述符依然存在, 直到父进程调用wait4()系统函数后将进程释放。
T(停止)//进程收到停止信号后停止运行,停止或被追踪。
< //优先级高的进程
N //优先级较低的进程
L //有些页被锁进内存
s //进程的领导者(在它之下有子进程)
l //多线程,克隆线程(使用 CLONE_THREAD, 类似 NPTL pthreads)
+ //位于后台的进程组;
top
$ top
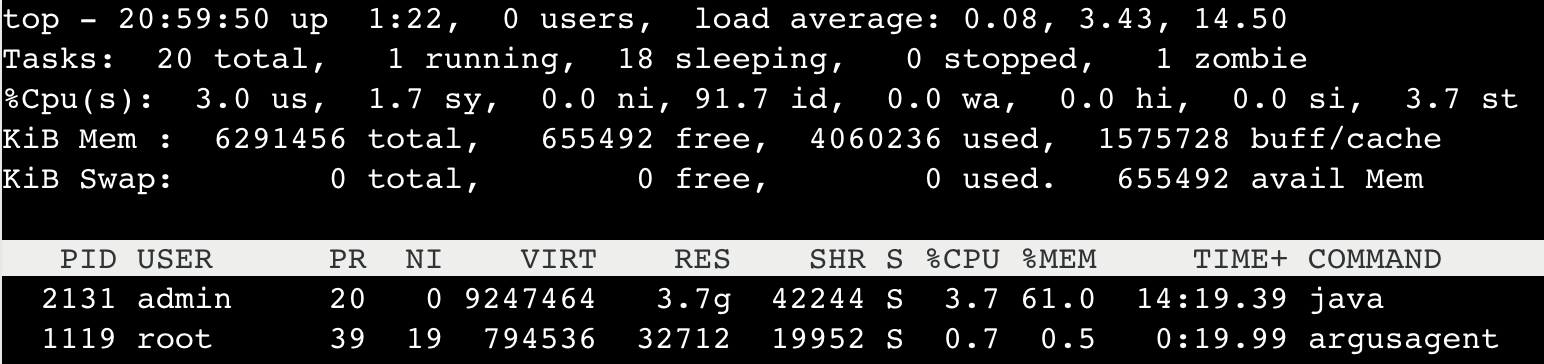

跟踪进程的系统调用strace
$ strace -o output.txt -T -tt -e trace=all -p 28979 # 跟踪28979进程的所有系统调用(-e trace=all),并统计系统调用的花费时间,以及开始时间(并以可视化的时分秒格式显示),最后将记录结果存在output.txt文件里面
$ strace -f -e execve myserver # 只关注execve,-f选项告诉strace同时跟踪fork和vfork出来的进程,myserver是要启动和调试的程序

进程内线程详情
top -Hp pid
$ top -Hp pid #-H是thread model,-p指定进程pid,具体机器环境可用man top查看参数
各线程运行时间
$ ps -eLo pid,lwp,pcpu | grep pid
线程堆栈快照pstack
$ pstack pid
pstack原理:https://nanxiao.me/linux-pstack/
pstack+gdb调试死锁:https://www.cnblogs.com/gqtcgq/p/7530384.html
JDK工具
javap分析class文件
javap -verbose TestClass
JDK工具: https://zhuanlan.zhihu.com/p/63102801
性能分析工具:VisualVM(推荐)、jprofiler
VisualVM:https://blog.csdn.net/qq_35246620/article/details/106817964 (jdk的bin目录下自带)
IDEA也有VisualVM的插件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号