
20242421 实验四《Python程序设计》综合实践报告
20242421 2024-2025-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 2424
姓名: 张骜阳
学号:20242421
实验教师:王志强
实验日期:2025年5月26日
必修/选修: 选修课
1.实验课题
作为电影爱好者,我常通过豆瓣电影榜单发现优质影片,因此尝试通过python爬虫技术采集豆瓣电影top250的信息。
2.实验内容
(1)配置环境:


似乎想让我升级但是我不想升级。
(2)爬取目标:
电影排名:榜单中的序号(1-250)
电影名称:中文标题
评分:豆瓣评分(10分制)
评价人数:参与评分用户数
导演:导演姓名
主演:主要演员
上映年份:电影首映年份
简介:一句话点评
3. 实验过程
(1)爬虫框架:Requests + BeautifulSoup
(2)工作流程:
A.模拟浏览器发送HTTP请求
B.解析HTML页面内容
C.定位并提取目标字段
D.数据清洗与存储
E.分页循环处理所有页面
F.反爬策略:随机延迟、异常处理
(3)代码:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import random
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.9'
}
movies = []
for start in range(0, 250, 25):
url = f'https://movie.douban.com/top250?start={start}'
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
items = soup.find_all('div', class_='item')
for item in items:
rank = item.find('em').text
title = item.find('span', class_='title').text
rating = item.find('span', class_='rating_num').text
rating_num = item.find('div', class_='star').find_all('span')[-1].text.replace('人评价', '')
quote_tag = item.find('span', class_='inq')
quote = quote_tag.text if quote_tag else "无"
movies.append({
'排名': rank,
'标题': title,
'评分': rating,
'评价人数': rating_num,
'简介': quote
})
delay = random.uniform(1, 3)
print(f'已爬取第{start // 25 + 1}页,等待{delay:.1f}秒...')
time.sleep(delay)
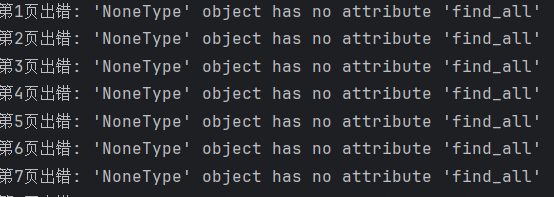
except Exception as e:
print(f"第{start // 25 + 1}页出错: {e}")
pd.DataFrame(movies).to_csv('douban_top250.csv', index=False, encoding='utf-8-sig')
print("数据已保存至 douban_top250.csv")
4. 实验结果
(1)发现并不能运行。。。
(2)修改代码:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import random
from fake_useragent import UserAgent
ua = UserAgent()
headers = {
'User-Agent': ua.random,
'Accept-Language': 'zh-CN,zh;q=0.9',
'Referer': 'https://movie.douban.com/'
}
movies = []
def scrape_douban_top250():
for start in range(0, 250, 25):
page_num = start // 25 + 1
url = f'https://movie.douban.com/top250?start={start}'
try:
response = requests.get(url,
headers=headers,
timeout=(3.05, 10),
proxies={'http': 'http://proxy.example.com:8080'},
allow_redirects=False)
if response.status_code != 200:
print(f"第{page_num}页:请求失败,状态码 {response.status_code}")
continue
soup = BeautifulSoup(response.text, 'html.parser')
if not soup:
print(f"第{page_num}页:HTML解析失败")
continue
items = soup.select('div.item')
if not items:
print(f"第{page_num}页:未找到电影条目,可能页面结构变化")
with open(f'error_page_{page_num}.html', 'w', encoding='utf-8') as f:
f.write(response.text)
continue
for item in items:
try:
movie_data = {
'排名': safe_extract(item, 'em'),
'标题': safe_extract(item, 'span.title'),
'评分': safe_extract(item, 'span.rating_num', default='0.0'),
'评价人数': safe_extract(item, 'div.star span:last-child',
processor=lambda x: x.replace('人评价', ''),
default='0'),
'导演': extract_director(item),
'年份': extract_year(item),
'简介': safe_extract(item, 'span.inq', default='无')
}
movies.append(movie_data)
except Exception as e:
print(f"第{page_num}页电影条目解析异常:{str(e)}")
continue
print(f"第{page_num}页爬取完成,共{len(items)}部电影")
time.sleep(random.uniform(2, 5))
except requests.exceptions.RequestException as e:
print(f"第{page_num}页网络请求异常:{str(e)}")
continue
except Exception as e:
print(f"第{page_num}页发生未知错误:{str(e)}")
continue
def safe_extract(parent, selector, default='N/A', processor=None):
element = parent.select_one(selector)
if not element or not element.text.strip():
return default
result = element.text.strip()
return processor(result) if processor else result
def extract_director(item):
try:
info_text = item.select_one('.bd p').text.strip()
if '导演:' in info_text:
return info_text.split('导演:')[1].split('\n')[0].strip().split(' ')[0]
except:
pass
return '未知'
def extract_year(item):
try:
year_text = item.select_one('.bd p').text.strip().split('\n')[-1].strip()
return year_text[:4] if year_text and year_text[0].isdigit() else '未知'
except:
return '未知'
if __name__ == '__main__':
scrape_douban_top250()
if movies:
df = pd.DataFrame(movies)
df.to_csv('douban_top250_secure.csv', index=False, encoding='utf-8-sig')
print(f"数据已保存,共{len(movies)}条记录")
else:
print("未获取到有效数据")
(3)于是安装了新的模块:

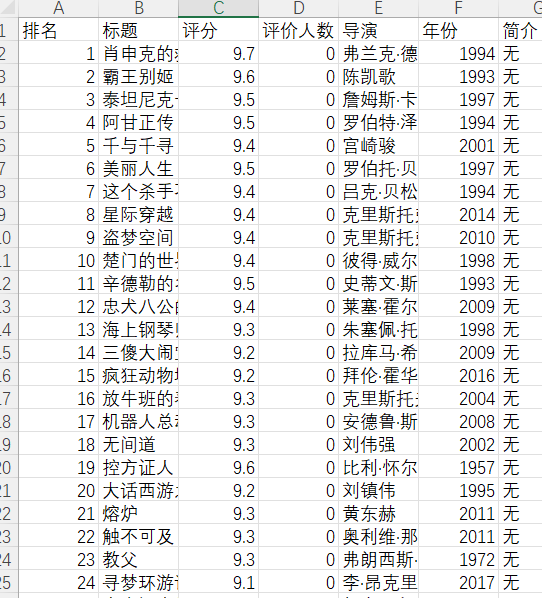
(4)然后终于爬成功了啊啊啊啊啊啊啊啊啊类目了

(5).csv文件
5.思想体悟
这学期抢python课,本来是听学长学姐说python课很好很值得抢,结果第一节抢了python之后发现其他的课都没了呃呃呃。于是就这学期我就体验了一次只有一节晚课的究极轻松学期,但是其实python的学习也并不轻松就是了,本实验报告写得我心绞痛。我本来以为python会比C语言简单很多(虽然确实是这样),但是每次上完课就忘记了当堂课的内容,很多时候上了一节课,下周已经忘记了上节课讲了什么,然后要看了ppt才能回忆起来。还有一些抽象的内容我很多没有实践,导致学了之后就放在一旁了。
经历了较为艰难的一学期学习,我还是逐渐明白了我应该怎样学习一门语言:不能只在课上听,也不整理笔记也不实践,而是应该多多实操,多试试上课教的方法下课自己多琢磨琢磨,不然只能纸上谈兵,实操时溃不成军。
最后夸夸王志强老师,强哥本身很幽默风趣,上课也是很有意思,希望这种老师来教我所有科目啊啊啊。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号