
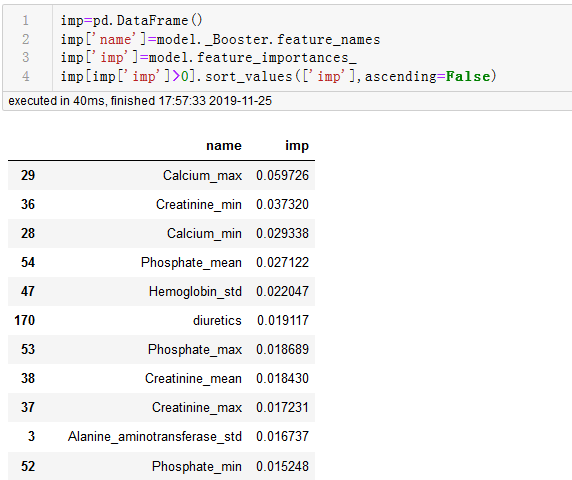
原生xgboost中如何输出feature_importance
网上教程基本都是清一色的使用sklearn版本,此时的XGBClassifier有自带属性feature_importances_,而特征名称可以通过model._Booster.feature_names获取,但是对应原生版本,也就是通过DMatrix构造,通过model.train训练的模型,如何获取feature_importance?而且,二者获取的feature_importance又有何不同?
1.通过阅读官方文档https://xgboost.readthedocs.io/en/latest/python/python_api.html,发现sklearn版本初始化时会指定一个默认参数

显而易见,最后获取的feature_importances_就是gain得到的

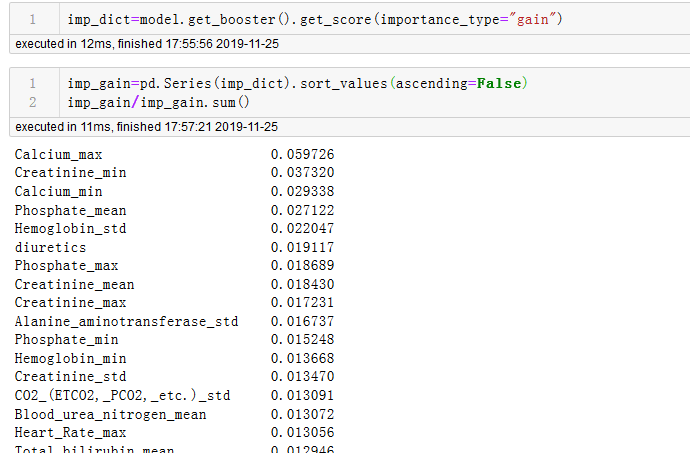
2.而原生版本初始化时没有importance_type参数,真正获取feature_importance时通过model.get_score(importance_type="gain")获取,(另外一个方法get_fscore()就是get_score(importance_type="weight"),二者实现一样。)
注意这里默认参数是"weight",就是指每个特征被用于分割的使用次数。如果对标skelearn版本需要指定“gain”,这里gain是指平均增益,另外,skelearn版本返回的importance是0-1形式,而原生版本返回的是很大的小数形式,对标的话可以通过除以总和得到,结果如图
3.至于什么时候用weight,什么时候用gain,其实各有说法。实际上,判断特征重要性共有三个维度,而在实际中,三个选项中的每个选项的功能重要性排序都非常不同
1. 权重。在所有树中一个特征被用来分裂数据的次数。
2. 覆盖。在所有树中一个特征被用来分裂数据的次数,并且有多少数据点通过这个分裂点。
3. 增益。使用特征分裂时平均训练损失的减少量
是什么使得衡量特征重要性的度量好或者坏?
如何比较一种特征归因方法与另一种特征归因方法并不容易。我们可以度量每种方法的最终用户性能,例如数据清理、偏差检测等。但这些只是对特征归因方法好坏的间接测量。在这里,我们将定义两个属性,我们认为任何好的特征归因方法应该遵循:
1. 一致性。每当我们更改模型以使其更依赖于某个特征时,该特征的归因重要性不应该降低。
2. 准确性。所有特征重要性的总和应该等于模型的总重要性。(例如,如果重要性由R²值测量,那么每个特征的属性应该与完整模型的R²相等)
如果一致性不成立,那么我们不能比较任意两个模型之间的归因重要性,因为具有较高分配归因特征,并不意味着模型实际上更多地依赖于该特征。
如果精度未能保持,那么我们不知道每个特征的属性如何组合以表示整个模型的输出。我们不能在方法完成后对归因进行规范化,因为这可能会破坏方法的一致性
这里推荐使用shap,可以全面的判断特征重要性,而且对xgboost和lightgbm都有集成,可视化也相当不错。详细可看https://github.com/slundberg/shap
附:lightgbm和xgboost类似,https://lightgbm.readthedocs.io/en/latest/pythonapi/lightgbm.Booster.html?highlight=importance#lightgbm.Booster.feature_importance


 浙公网安备 33010602011771号
浙公网安备 33010602011771号