
爬虫大作业
1.选一个自己感兴趣的主题。
2.用python 编写爬虫程序,从网络上爬取相关主题的数据。
3.对爬了的数据进行文本分析,生成词云。
4.对文本分析结果进行解释说明。
5.写一篇完整的博客,描述上述实现过程、遇到的问题及解决办法、数据分析思想及结论。
6.最后提交爬取的全部数据、爬虫及数据分析源代码。
这里爬取了虎扑步行街的贴子,包括帖子标题,作者,时间,帖子链接,帖子内容和评论
import requests from bs4 import BeautifulSoup import os def get_soup(url): req = requests.get(url) req.encoding = 'utf-8' soup = BeautifulSoup(req.text, 'html.parser') return soup def selectClass(fa,cls1,cls2): return fa.select(cls1)[0].select(cls2) def delchar(word): ch1 = '\\' ch2 = ':/*?' for c in word: if(c==ch1): word = word.replace(ch1,'') elif(c in ch2): word = word.replace(c, '') return word def get_pagelist(element): for i in element: if (len(i.select('.titlelink')) > 0): post = dict() post_list = list() a = selectClass(i,'.titlelink','.truetit') post['title'] = delchar(a[0].text) post['title_url'] = hupu_url + a[0].attrs['href'] a = selectClass(i,'.author','.aulink') post['author'] = a[0].text post['author_url'] = a[0].attrs['href'] a = selectClass(i,'.author','a') post['time'] = a[1].text post['count'] = i.select('.ansour')[0].text.split('\xa0') post_list.append(post) page_list.extend(post_list) return page_list def createfile(filename,title): if not os.path.exists(filename): os.makedirs(filename) newfile = filename+'/'+title +'/' if not os.path.exists(newfile): os.makedirs(newfile) return newfile def getcontent(page_list): for onelist in page_list: com = dict() com_list = list() soup = get_soup(onelist['title_url']) content = soup.select('.quote-content')[0].text comment = soup.find('table', {"class": 'case'}) if(comment.select('td')!=''): td = comment.select('td') if (len(td) > 0): comments = td[0].text com['content'] = content com['comment'] = comments com_list.append(com) allcom_list.extend(com_list) # if(i==3): # break # else: # i=i+1 return allcom_list # if (int(onelist['count'][0]) > 100 and int(onelist['count'][2]) > 5000): hupu_url = 'https://bbs.hupu.com' soup = get_soup(hupu_url+'/bxj') li = soup.select('li') page_list = list() page_list = get_pagelist(li) allcom_list = list() allcom_list = getcontent(page_list) location = str() i=0 for onelist in page_list: # if(int(onelist['count'][0])>500 and int(onelist['count'][2])>1000): location = createfile('NEWS',str(i)) # soup = get_soup(onelist['title_url']) # comment = soup.find_all('table',{"class":'case'}) # td = comment.select('td')[0] # if(len(td)>0): # comments = td[0].text # # # content = soup.select('.quote-content')[0].text # for i in soup.select('.quote-content')[0].find_all(attrs={'data-original': True}): # print(i) # print(soup.select('.quote-content')[0].find_all(attrs={'data-original': True})) # print(img.attrs['data-original']) # for img in soup.select('.quote-content')[0].select('img'): # print (img.find_all(attrs={'data-original': True})) # if(img.attrs['data-original']!=''): # print(img.attrs['data-original']) # else: # print(img.attrs['src']) # print(img) filename = location+'/information'+'.txt' print(onelist['title']) with open(filename,'w',encoding='utf-8') as file: file.write('帖子标题:'+onelist['title']+'\n') file.write('帖子链接:' + onelist['title_url']+'\n') file.write('帖子作者:' + onelist['author']+'\n') file.write('作者链接:' + onelist['author_url']+'\n') file.write('创建时间:' + onelist['time']+'\n') file.write('浏览/评论:' + ''.join(onelist['count'])+'\n') i = i + 1 print('**------------information------------done') for com in allcom_list: filename = location+'/content'+'.txt' with open(filename,'w',encoding='utf-8') as file: file.write(com['content']) file.write('\n\n') file.write(com['comment'])
结果截图
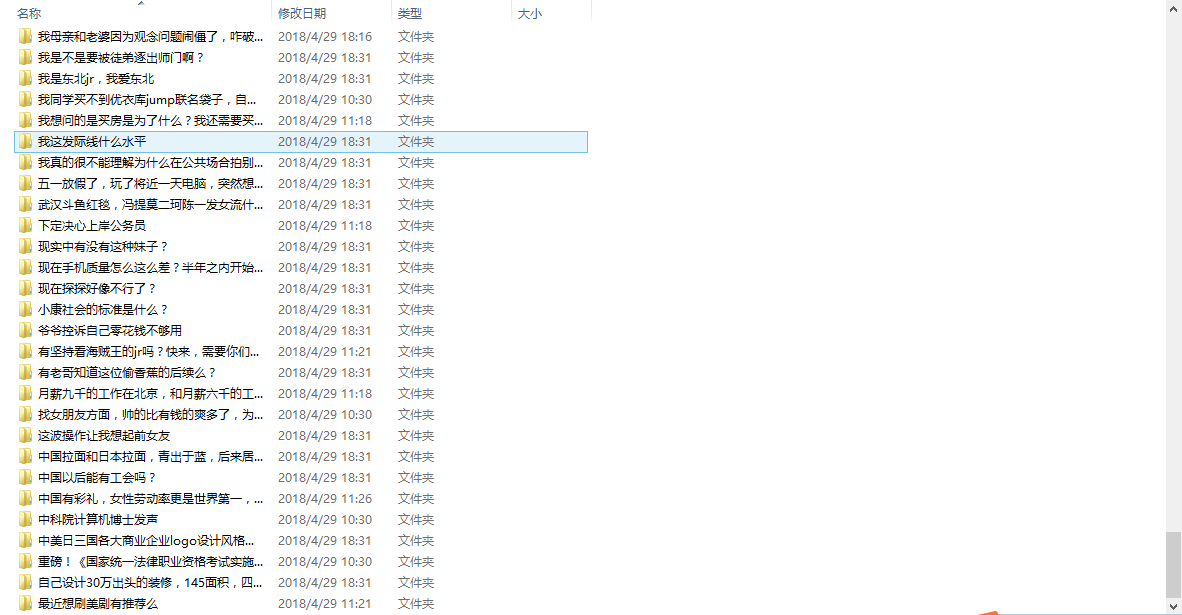
这里使用了帖子的标题作为文件夹的名字,就出现了问题是,有些标题使用了一些不能用来命名文件夹的特殊字符,会造成文件夹创建不成功而出错。解决方法尝试过使用字符串的操作去掉敏感字符,然而特殊字符并不能全部列举出来,就此放弃,使用自定义的命名文件夹,如下图
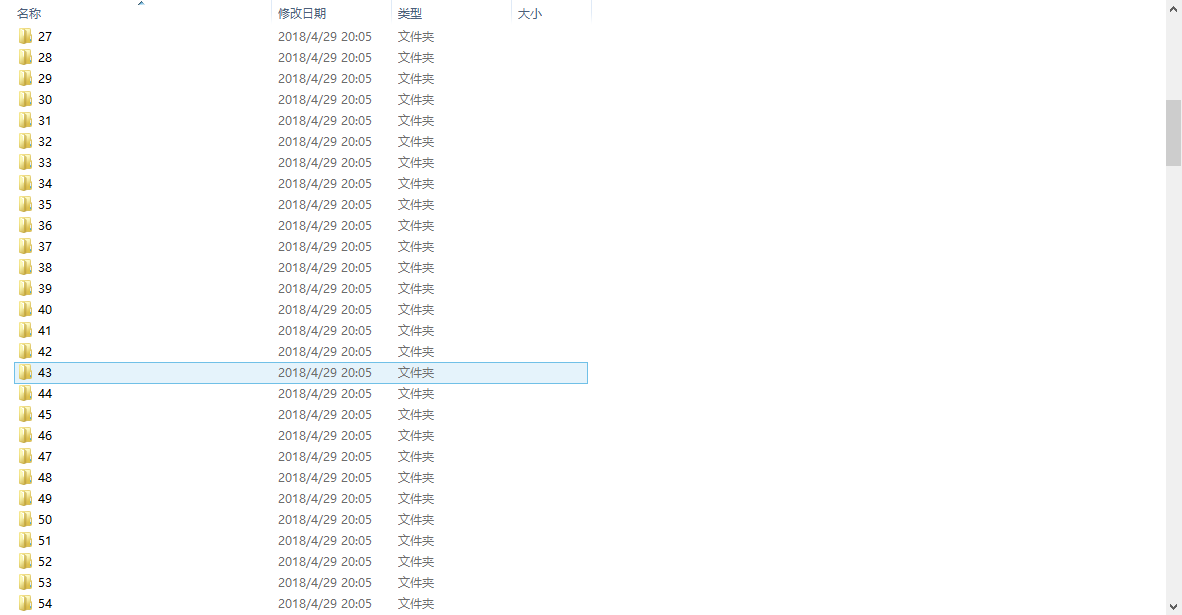
文件夹里有帖子相关信息和相关内容

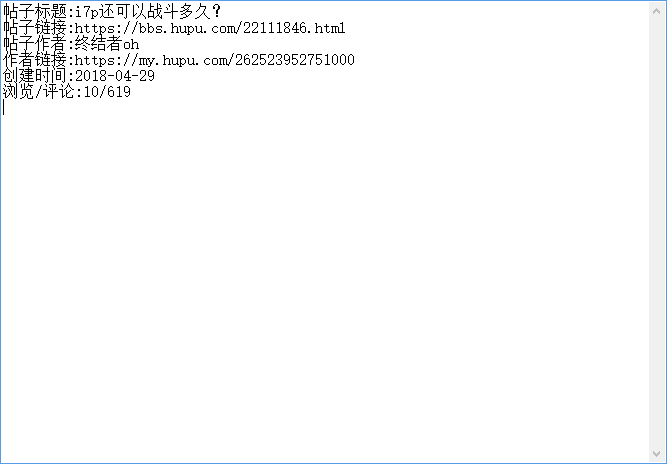
帖子的内容可能涉及图片,本来爬图片是很容易的,不过好像遇到了img有一个这样的属性 。百度好像并没有我想要的答案,就.....
。百度好像并没有我想要的答案,就.....
帖子很多,受到网络、硬件的限制没有全部爬下,可以对点击数和评论数进行筛选多人关注的帖子进行爬取
if (int(onelist['count'][0]) > 100 and int(onelist['count'][2]) > 5000):
也可以排序热度最高的前十个帖子来看看,或许有惊喜呢?
有的网站可能需要登录才能访问相关资源,可以参考
https://zhuanlan.zhihu.com/p/26102000
把所有帖子内容生成词云


 浙公网安备 33010602011771号
浙公网安备 33010602011771号