


1.大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
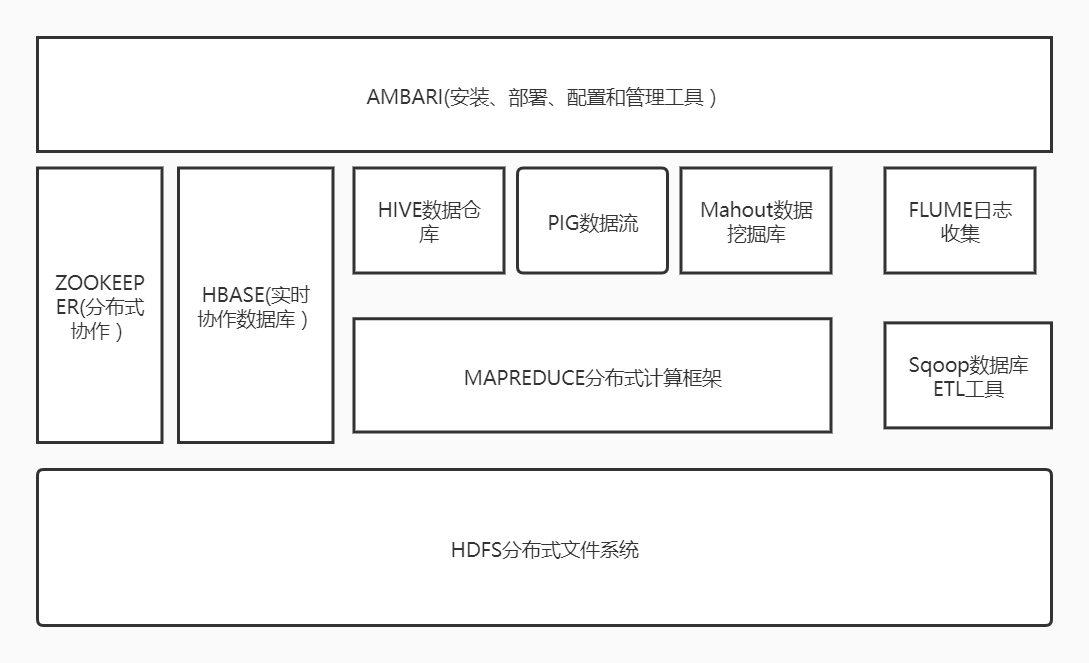
(1)Hadoop分布式文件系统
源自于Google的GFS论文,发表于2003年10月,HDFS是GFS克隆版。
HDFS是整个hadoop体系的基础,负责数据的存储与管理。HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。它提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群不同物理机器上。
client:切分文件,访问HDFS时,首先与NameNode交互,获取目标文件的位置信息,然后与DataNode交互,读写数据
NameNode:master节点,每个HDFS集群只有一个,管理HDFS的名称空间和数据块映射信息,配置相关副本信息,处理客户端请求。
DataNode:slave节点,存储实际数据,并汇报状态信息给NameNode,默认一个文件会备份3份在不同的DataNode中,实现高可靠性和容错性。
Secondary NameNode:辅助NameNode,实现高可靠性,定期合并fsimage和fsedits,推送给NameNode;紧急情况下辅助和恢复NameNode,但其并非NameNode的热备份。
(2)① MapReduce
MapReduce 是一种分布式并行编程模型,用于大规模数据集(大于1TB)的并行运算,它将复杂的、运行于大规模集群上的并行计算过程高度抽象到两个函数:Map和Reduce。
MapReduce极大方便了分布式编程工作,编程人员在不会分布式并行编程的情况下,也可以很容易将自己的程序运行在分布式系统上,完成海量数据集的计算。
②并行计算流程
在MapReduce中,一个存储在分布式文件系统中的大规模数据集,会被切分成许多独立的小数据块,这些小数据块可以被多个Map任务并行处理。MapReduce框架会为每个Map任务输入一个数据子集,Map任务生成的结果会继续作为Reduce任务的输入,最终由Reduce任务输出最后结果,并写入分布式文件系统。
③涉及理念:计算向数据靠拢
MapReduce 设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,因为移动数据需要大量的网络传输开销,尤其是在大规模数据环境下,这种开销尤为惊人,所以,移动计算要比移动数据更加经济。本着这个理念,在一个集群中,只要有可能,MapReduce框架就会将Map程序就近地在 HDFS 数据所在的节点运行,即将计算节点和存储节点放在一起运行,从而减少了节点间的数据移动开销。
(3) hive(基于hadoop的数据仓库)
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。
hive定于了一种类似sql的查询语言(hql)将sql转化为mapreduce任务在hadoop上执行。
(4)HBase
HBase 是针对谷歌 BigTable 的开源实现,是一个高可靠、高性能、面向列、可伸缩的分布式数据库,主要用来存储非结构化和半结构化的松散数据。
HBase可以支持超大规模数据存储,它可以通过水平扩展的方式,利用廉价计算机集群处理由超过10亿行元素和数百万列元素组成的数据表
HBase利用MapReduce来处理HBase中的海量数据,实现高性能计算;利用 Zookeeper 作为协同服务,实现稳定服务和失败恢复;使用HDFS作为高可靠的底层存储,利用廉价集群提供海量数据存储能力,当然,HBase也可以在单机模式下使用,直接使用本地文件系统而不用 HDFS 作为底层数据存储方式,不过,为了提高数据可靠性和系统的健壮性,发挥HBase处理大量数据等功能,一般都使用HDFS作为HBase的底层数据存储方式。此外,为了方便在HBase上进行数据处理,Sqoop为HBase提供了高效、便捷的RDBMS数据导入功能,Pig和Hive为HBase提供了高层语言支持。
(5)zookeeper(分布式协作服务)
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
(6)Sqoop
Sqoop是SQL-to-Hadoop的缩写,主要用来在Hadoop和关系数据库之间交换数据,可以改进数据的互操作性。
通过Sqoop,可以方便地将数据从MySQL、Oracle、PostgreSQL等关系数据库中导入Hadoop(比如导入到HDFS、HBase或Hive中),或者将数据从Hadoop导出到关系数据库,使得传统关系数据库和Hadoop之间的数据迁移变得非常方便。
(7)pig(基于hadoop的数据流系统)
定义了一种数据流语言-pig latin,将脚本转换为mapreduce任务在hadoop上执行。
通常用于离线分析。
(8)mahout(数据挖掘算法库)
mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。mahout现在已经包含了聚类,分类,推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法是,mahout还包含了数据的输入/输出工具,与其他存储系统(如数据库,mongoDB或Cassandra)集成等数据挖掘支持架构。
(9)flume(日志收集工具)
cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。他将数据从产生,传输,处理并写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在flume中定制数据发送方,从而支持收集各种不同协议数据。
(10)资源管理器的简单介绍(YARN和mesos)
随着互联网的高速发展,基于数据 密集型应用 的计算框架不断出现,从支持离线处理的mapreduce,到支持在线处理的storm,从迭代式计算框架到 流式处理框架s4,...,在大部分互联网公司中,这几种框架可能都会采用,比如对于搜索引擎公司,可能的技术方法如下:网页建索引采用mapreduce框架,自然语言处理/数据挖掘采用spark,对性能要求到的数据挖掘算法用mpi等。公司一般将所有的这些框架部署到一个公共的集群中,让它们共享集群的资源,并对资源进行统一使用,这样便诞生了资源统一管理与调度平台,典型的代表是mesos和yarn。
2.对比Hadoop与Spark的优缺点。
Spark 是在借鉴了 MapReduce 之上发展而来的,继承了其分布式并行计算的优点并改进了 MapReduce 明显的缺陷,(spark 与 hadoop 的差异)具体如下:
首先,Spark 把中间数据放到内存中,迭代运算效率高。MapReduce 中计算结果需要落地,保存到磁盘上,这样势必会影响整体速度,而 Spark 支持 DAG 图的分布式并行计算的编程框架,减少了迭代过程中数据的落地,提高了处理效率。(延迟加载)
其次,Spark 容错性高。Spark 引进了弹性分布式数据集 RDD (Resilient DistributedDataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即允许基于数据衍生过程)对它们进行重建。另外在RDD 计算时可以通过 CheckPoint 来实现容错。
最后,Spark 更加通用。mapreduce 只提供了 Map 和 Reduce 两种操作,Spark 提供的数据集操作类型有很多,大致分为:Transformations 和 Actions 两大类。Transformations包括 Map、Filter、FlatMap、Sample、GroupByKey、ReduceByKey、Union、Join、Cogroup、MapValues、Sort 等多种操作类型,同时还提供 Count, Actions 包括 Collect、Reduce、Lookup 和 Save 等操作
3.如何实现Hadoop与Spark的统一部署?
由于Hadoop、Spark等,都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号