



SpringCloud分布式微服务总结
SpringCloud笔记
SpringCloud:
是一个分布式微服务架构的一站式解决方案,多种微服务架构落地技术的集合体,俗称叫微服务全家桶
就像KFC全家桶,你要用什么,加进去就行,它会给你自动协调,最后使用就行
构建微服务模块
1. 建module:在父工程右键新建模块,创建子模块
2. 改POM:如果子模块没有标识版本,就自动引用父模块的
3. 写yml
4. 主启动
5. 业务类
笔记中一些概念:
服务:指我们服务提供商的服务
客户端:指我们用户访问的客户端
服务器:有可能是Eureka服务器等,注意区分与服务的区别
新学的注解(cloud启用+激活):
普通注解:
@Slfj4:类注解 开启日志记录,不用使用LoggerFactory来获取logger了,可以直接调用log.info...等方法
@EnableDiscoveryClient:启动类注解 使用这个注解,可以启动服务发现功能,用于让服务器发现此微服务,不加的话自己的服务将无法被发现
配套DiscoveryClient类使用
服务注册发现中心:
Eureka:
@EnableEurekaServer:启动类注解 使用这个注解,在Eureka服务器中开启Eureka服务,就不用配置业务类了(其实也是因为我们没有业务)
@EnableEurekaClient:启动类注解 启动Eureka,用于连接服务器并注册
@LoadBalanced:属性注解 在RestTemplate上使用,适用于开启多服务集群之后,访问路径是服务名之后,如果不开启会直接报500错误,因为我们不知道要找哪个主机给我们处理,开启之后Eureka会轮流使用注册的服务(这是配合Ribbon使用的)
服务调用中心:
Ribbon:
@RibbonClient:启动类注解 里面有name:参数是服务注册中心的服务名字符串,标识我们需要哪个服务被更改均衡设置,configuration:参数是一个类,标识以什么方法去启用负载均衡
OpenFeign:
@EnableFeignClients:启动类注解 开启Feign的支持
配套@FeignClient使用
@FeignClient:Feign接口类定义,用于与服务注册中心的服务挂钩,接口类里面定义的方法是服务与客户端相同的,该注解有value属性,标识该类与哪一个服务绑定
同时还有fallback属性,这个和服务降级有关
服务降级熔断中心:
Hystrix:
@EnableHystrix:启动类注解 开启对Hystrix的支持
@HystrixCommand:类注解 定义在需要使用服务降级的方法上,用于标识这个方法时需要使用服务降级的,里面有fallback属性,用于标识使用哪个方法来进行服务降级。除此之外还有@HystrixProperties方法,标识使用什么标准来进行事务降级
@HystrixProperties:注解内注解 定义在@HystrixCommand内,配置Hystrix的属性
@DefaultProperties:类注解 里面有defaultFallback属性,用于表示默认在这个类中用什么方法进行服务降级,解决了代码膨胀的问题
@EnableHystrixDashboard:启动类注解 表示开启Hystrix的可视化面板监控
路由网关:
Gateway:
没有新学的注解
配置中心:
Config:
@EnableConfigServer:启动类注解 表示该模组为配置服务中心
@RefreshScope:类注解 在controller层上注解表示这个类用于开启手动刷新配置功能
消息总线中心:
没有新学的注解
消息驱动中心:
Stream:
@EnableBinding:类注解 用于在这个类中启用消息驱动,并指定这个类是发送消息的类还是接收消息的。如果是发送消息,使用Source.class;如果是接收消息,使用Sink.class
@StreamListener:方法注解 用于指定该方法是一个管道接收器,用于监听并接收消息
Spring Cloud Alibaba:
Nacos服务注册配置中心:
@LoadBalanced:属性注解 由于Nacos集成了Ribbon,所以需要使用这个注解来做负载均衡
Sentinel服务降级熔断中心:
@SentinelResource:用于指定该类需要与Sentinel面板绑定,然后操作其中的方法。里面有blockHandler,用于指定违规处理器;还有fallback,用于指定降级方法
新学到的方法:
通用方法:
Springboot-Actuator依赖:引入了Actuator依赖,可以帮助我们查看MVC网址和JavaBean依赖UML图
服务发现:
DiscoveryClient类:DiscoveryClient是一个服务发现的客户端,我们可以部署在服务器上,当用户想看我们上传至Eureka服务器的方法中都有什么东西的时候,可以把它注入到Controller里面
使用方法:
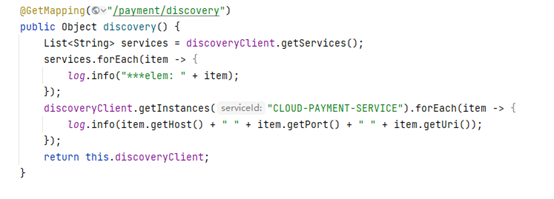
负载均衡:
RestTemplate类:RestTemplate是Spring开发的一个发送请求的工具,可以发送http请求给一个特定的url
使用方法:在配置类中添加RestTemplate并交给IOC管理,在需要的地方自动注入,然后使用里面的方法发送请求
方法详解:
get和post的区别:一个是读,一个是写,Restful风格
forObject:返回的是一个JSON字符串,封装了基本信息等
forEntity:返回的是一个ResponseEntity对象,封装了响应的头部信息、响应码、基本信息等信息
示例module:
用户订单81端口 ==》 服务器对接用户端口8001
服务器:按照上面的步骤建立module
引入POM依赖:根据业务需求引入,例如连接数据库的数据源、热部署、web&test依赖等
写yml:设置数据源以及端口等
主启动:写@SpringBootApplication
业务类:由底层写起
1.建立数据库,看看自己业务需求什么数据库
2.编写实体类文件,例如数据库操作的实体类或者数据模型等
3.编写dao层文件,即一个mapper映射接口
4.编写mapper操作,即mapper.xml
5.编写service规范接口类,然后使用serviceImpl进行实现
6.编写controller文件,提供url给SpringMVC,对应编写方法,实现url对应的Handler
客户端:按照上面的步骤建立module
引入POM依赖:根据业务需求引入,由于客户只需要访问地址,对接到服务端即可,那就只需要引入web等依赖,像数据源那些就不用了
写yml:设置端口
主启动:写@SpringBootApplication
业务类:观察客户端需要如何操作,因为只需要访问网址,所以我们使用了 RestTemplate 来在controller发送请求,并且还得有实体类和数据模型
1.编写数据模型和实体类
2.编写配置类,创建RestTemplate实例并交给IOC管理
3.在controller层编写Handler,把使用restTemplate发送请求,里面有getForObject等方法可以发送请求的
重构优化:在上面我们可以发现,因为客户端和服务器有很多冗余的东西,例如实体类和数据模型这些大家都能用到的类,所以我们要进行优化
新建module,根据业务需求引入热部署、lombok等(其中有一个hutool暂时未学)
因为是公用api,在其中我们并不需要怎么写入配置类,所以省略掉yml编写
然后编写所需要用的实体类以及数据模型,最后使用mvn:install来安装
*在需要引用该公用api的POM文件的dependency引入我们自己创建的公用api
服务注册发现中心:
eureka:
服务治理:有很多调用者和服务,我们需要一个服务管理机制来管理各项服务
服务注册:
Eureka Server:提供服务注册服务,用于把微服务节点注册进去,并储存起来,用于统一管理
Eureka Client:提供服务中心访问服务,它是一个Java用户端,用于简化对Server的交互,同时向各个组件发送心跳,确认他们还在线,如果不在线,就会把他们从注册中心删除
Eureka的单机调用:
Eureka服务器:就是和以上差不多的操作
创建模块
修改POM文件,引入springcloud的netfilx中的eureka服务器依赖
配置application.yml文件,在yml的eureka配置项中可以配置客户端与服务器交互地址
编写主启动类,因为我们只是一个管理的服务器,可以使用注解:@EnableEurekaServer 来启动Eureka服务器
因为只是一个服务中心,所以我们不需要编写业务类,但是如果有需要还是可以加上业务类的
Eureka客户端:五大操作
修改POM文件,引入springcloud的netfilx中的eureka客户端依赖
配置application.yml文件,在yml的eureka配置项中可以配置客户端与服务器交互地址,是以键值对的方式添加
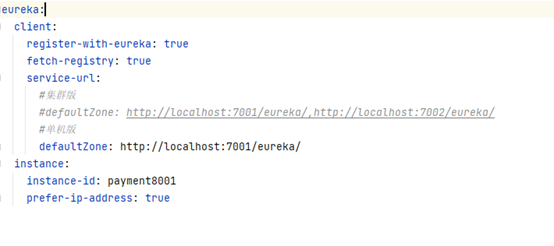
编写主启动类,使用注解:@EnableEurekaClient 来连接Eureka服务器
业务类本来就有,不用特殊修改
注意:要修改客户端服务名的话,使用 spring.application.name=xxx 来配置
Eureka集群:
实现高可用:互相注册,相互守望
服务器:在service-url配置里面声明其他的Eureka服务器地址,而不像单机一样声明自己 *注意:hostname不能一样,不然会当成同一个服务
客户端:在service-url配置里面声明全部服务器地址,这样就可以连接其他所有服务器
服务器7001:

服务器7002:

Eureka服务器中的服务集群+负载均衡:
除了Eureka集群之外,我们注册的服务也可以实现集群
在多个服务注册进入Eureka后,因为他们的端口号不同,但是注册进去的是同一个服务名,所以Eureka可以随意调用一个 服务名+访问路径+参数 来操作这个方法
Eureka集成了Ribbon,在引入EurekaClient的时候就顺带引入了Ribbon
*注意:之前我们用户访问的是一个 路径+访问路径,现在使用了服务集群的话,就要用 服务名+访问路径 来操作了,还注意需要开启RestTemplate的负载均衡功能@LoadBalanced
Eureka的Actuator的完善:
当我们不想在Eureka的界面中显示主机名称的话,我们可以在yml中配置instance.instance-id,这个可以限制Eureka的中让他显示自己的 服务名称+端口
当我们指向Eureka界面中服务的访问地址时,默认是不会显示服务的IP地址,我们可以通过配置yml中的instance.prefer-ip-address来显示我们要访问的服务的IP地址
Eureka的服务发现:
我们在部署微服务的时候,可以通过在Controller中注入DiscoveryClient实例,并调用其中的方法来告诉用户,我们的微服务里面有什么东西
同时也要开启@EnableDiscoveryClient在启动类上,不然Eureka的服务发现将发现不了我们当前微服务(但可以发现其他的)
Eureka的自我保护机制:
当它开启的时候,如果某个时刻某一个微服务不可用了,Eureka也不会立刻清除,依然会对该微服务的信息进行保存
宁愿保存错误的服务信息,也不会盲目的注销任何可能健康的服务实例(AP)
如何禁止:
可以通过配置server.self-preservation来开启或关闭
配置lease-renewal-interval-in-seconds来设置多久发送一次心跳包
配置lease-expiration-duration-in-seconds来设置断开多久后注销服务
Zookeeper:
启动Zookeeper,然后五大步:
改POM:添加springcloud的zookeeper依赖坐标
写yml:配置cloud.zookeeper.connect-string,修改为zookeeper服务器地址

因为我们是注册进去,就像前文注册Eureka一样,我们可以通过在服务器中使用 ls/services/xxx 来查看有哪些服务注册进来了
Zookeeper的节点临时节点还是持久节点:这是临时节点,不像Eureka有保护机制,如果感受不到微服务端,就会及时删除
只要完成上面几步,就可以把微服务注册进Zookeeper
Consul:
安装Consul:在http://www.consul.io可以下载,解压后只有一个exe文件,需要使用命令行consul agent -dev来启动
服务注册:五大步
建模块:新创建一个8006的模块
改POM:引入Consul依赖
写yml:在yml的spring.cloud中可以配置Consul,其中host和port为我们连接的服务器地址,discovery中的service-name就是自己要注册的服务名(和Eureka不同的是,是在其中传入spring.application-name参数来控制服务名称)
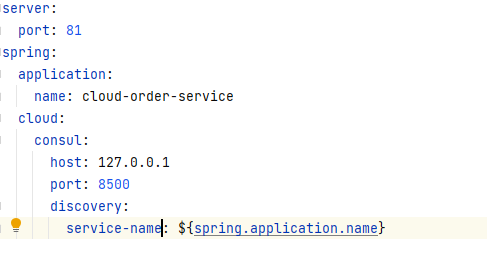
主启动:在主启动类记得加上@DiscoveryClient来告诉服务器我们有这个服务
业务类:在此可以定义我们的真正的业务
当启动后,会根据配置文件自动连接去Consul服务器,可以通过 服务器的IP地址:8500 访问Consul的UI界面
三大注册中心的异同:
CAP角度:
C ==》Consistency 一致性
A ==》Available 可用性
P ==》Partition tolerance 分区容错性
Eureka:AP角度
Zookeeper和Consul:CP角度
服务注册发现中心的总结:
我感觉三个服务注册发现中心都差不多,但是Eureka和Consul都有Web界面支持,更友好一点,然后基本步骤都是引入依赖、配置服务注册中心的地址、
然后启动Discovery来告诉中心我们有这个一个服务,三个都大同小异。Eureka还需要配置一下Server端和Client端,这个是麻烦一点的
服务调用中心:
Ribbon:
Ribbon介绍:这是一套客户端,负责负载均衡,可以实现随机或轮询等模式访问微服务
Ribbon与Nginx的区别:
Ribbon是本地的负载均衡,而Nginx是服务器的负载均衡。就是说Ribbon会请求注册发现中心,让负载中心发送服务消息,发现服务信息后,本地远程连接调用;而Nginx是使用了在服务器来分配实现负载均衡
Ribbon的使用:
开启Ribbon:
1.注入RestTemplate类:
RestTemplate是Spring开发的一个发送请求的工具,可以发送http请求给一个特定的url,请求调用其中的Handler返回消息,详见上面的通用方法
2.在注入的RestTemplate开启@LoadBalanced注解
负载均衡规则替换:
1.自定义规则不能放在@ComponentScan能扫描到的范围内,不然就会被所有Ribbon客户端共享,达不到特殊定制的目的
2.在扫不到的地方添加package:MyRule并在里面实现IRule接口实现类
3.添加一个配置类,注入一个IRule接口的实现类,供客户端处理
4.在需要被更改的controller类或者启动类上加入@RibbonClient注解,并配置其中的name和configuration属性
负载均衡轮询规则原理:取模
使用 对服务的第x次请求 % 该服务集群里共有多少台 来获取需要真正被调用的机器位置下标,每次服务重启之后都会把请求数设置为1
OpenFeign:
它是一个声明式的WebService客户端,也是用于客户端。它旨在是简化Java Http客户端的开发
OpenFeign与Ribbon的对比:
在Ribbon中,每一个需要负载均衡的类中都要注入RestTemplate,很不方便,但OpenFeign就解决了这个问题,可以直接面向接口编程
OpenFeign与Feign的对比:
Feign封装了Ribbon,而OpenFeign在Feign的基础上添加了对SpringMVC的支持,支持对@RequestMapping等注解的使用
使用方法:编写一个接口并在接口添加注解@FeignClient
1.在微服务调用的接口中添加@FeignClient,里面有一个value属性,用于标识它与什么服务相对应
2.定义Feign接口类的方法和服务的方法一致
3.在Feign接口类的方法中添加Mapping路径参数,参数要和服务商一致,并且如果我们使用了@PathVariable的话,一定要加上一个value="xxx"来标识这个属性该如何匹配URL的参数
4.在客户端定义Controller并注入Feign接口,调用其中的方法,和上面一样,@PathVariable也要加上value:原理就是我们调用本地Feign接口的方法,Feign会自动的使用Mapping参数去服务注册中心寻找目标服务并调用里面的方法
OpenFeign的超时控制:
*注意:如果报connect timeout的话可以重启,而且对应微服务集群里面每一个微服务都要做同样的超时处理
OpenFeign默认超时等待一秒钟,超过后报错read timeout
配置yml:由于OpenFeign底层是封装了Ribbon的,那么可以使用ribbon来配置超时时间(没有提示的):ribbon.ReadTimeOut和ribbon.ConnectTimeOut
OperFeign的日志打印:
OpenFeign的日志级别:
NONE:默认,不显示任何日志
BASIC:仅记录请求方法、URL、响应状态码等信息
HEADERS:除了BASIC的信息以外,还有请求头的信息
FULL:全部信息
OpenFeign开启日志打印:
1.注入日志Bean:配置类中注入Logger.level这个JavaBean
2.在yml中配置日志监视目录,像Springboot一样的格式
服务调用中心的总结:
对于服务调用中心,在我看来都是要在客户端以服务名的形式绑定服务提供商的服务,而且我们不能写死服务路径,要把服务名绑定在服务路劲上。对于OpenFeign,我们首先要
改POM,改yml来设定超时时间(也可以不设)。主启动类要启动Feign,而且要创建一个与服务提供商一样的service接口类,通过@FeignClient注解标识它要访问服务商的什么服务名,并要写清楚我们要访问这个
服务名的什么路径。最后编写controller调用service的方法就可以了
服务降级熔断中心:
Hystrix:
服务降级:
Hystrix使用方法:(使用+激活)(五大步)
引入POM:引入Hystrix的依赖坐标
由于我们在客户端使用了OpenFeign,所以在yml中配置feign.hystrix=enable,配置当我们使用feign的时候配合hystrix使用

启动类中加入@EnableHystrix
编写用于降级处理的方法,注意:它的参数必须和服务的参数一致
在需要被降级的方法上加入@HystrixCommand注解,用于开启Hystrix服务降级服务,里面有fallbackMethod属性,用于指定使用哪一个方法降级,还有@HystrixProperties属性,配置Hystrix的属性
当配置好之后,存在两个问题:
一是每个方法都要写一个降级方法吗?这样会造成代码膨胀
二是每个方法都和业务逻辑绑定在一个类中,这样会造成代码混乱
解决方法:
代码膨胀:
可以通过使用@DefaultProperties注解来标识现在当前类用什么方法进行默认的服务降级,在里面配置defaultFallback方法

代码混乱:
可以重写一个方法同样实现Service接口,然后在需要被服务降级的接口上加上@FeignClient注解(如果是客户端的话本来就有@FeignClient了),设置里面的fallback属性,用于指定哪个类来做服务降级
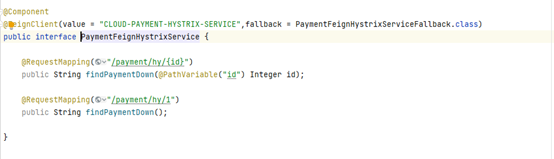
在实际开发中,一般可以使用重写接口的方法进行服务降级
服务熔断:
当开发中如果遇到请求次数过多或者发生什么异常的不得不关闭服务器以处理的时候,就会触发服务熔断机制,类似于家里的保险丝,如果电流过大就会熔断
服务熔断涉及到断路器的三个重要参数:快照时间窗、请求总数阀值、错误百分比阀值
服务熔断的使用及原理:
在@HystirxProperties中加入有关于断路器的属性配置,比如最基本的开启断路器、时间窗口期、请求次数以及成功率等
当没有触发熔断的时候,CircuitBreaker是关闭的,当到达限定次数,就从关闭转为开启,经过窗口期后试着去发一次请求,这时是半开状态,如果可以发送了,就恢复到关闭状态
对于服务降级只需要修改@HystrixProperties,由于是降级之后才能触发熔断,所以还是要配置上fallbackMethod
服务限流:
Alibaba的Sentinel才说
Hystrix Dashborad可视化:
五大步:
引入POM:网飞的Hystrix Dashboard依赖
yml配置端口和放行的路径,通过 hystrix.dashboard.proxy-stream-allow-list="*" 配置
主启动类加上@EnableHystrixDashboard
无需写业务类,因为这是监控,没有处理业务的需要
*注意:每一个需要被监控的服务都需要加上Actuator的依赖坐标,并且在主启动类要加上自己被监控的路径
@Bean
public ServletRegistrationBean getServlet() {
HystrixMetricsStreamServlet streamServlet = new HystrixMetricsStreamServlet();
ServletRegistrationBean registrationBean = new ServletRegistrationBean(streamServlet);
registrationBean.setLoadOnStartup(1);
registrationBean.addUrlMappings("/hystrix.stream");
registrationBean.setName("HystrixMetricsStreamServlet");
return registrationBean;
}
访问 路径+端口/hystrix 即可进入Hystrix可视化监控界面,在里面输入需要监控的路径即可监控
*注意:如果出现连接不上,可以在yml添加
hystrix:
dashboard:
proxy-stream-allow-list: "*"
服务降级熔断中心的总结:
服务降级就是将我们请求时长过久或者出现异常的方法进行一个兜底处理,当发生的时候会自动跳转到处理方法进行调用,并返回给用户。
在配置上要记得方法之间的参数类型要匹配,使用+触发 机制
服务熔断就是触发降级的次数过多了,就会触发到服务熔断机制,直接拒绝服务,直接跳去降级方法,经过一段窗口期后会自动尝试恢复正常工作
路由网关:
Gateway:
*特别注意:springboot的版本必须是与springcloud的版本相适配,最好springboot是版本集x.y.z的最后一个版本
代替了Zuul1.0,基于WebFlux开发,基于过滤链提供一种简单有效的统一的API路由管理方式,Gateway集成了Netty,它挡在其他微服务前面,为其他微服务提供分配
三大概念:
路由:构建网关的基本模块,就像我们寻找IP地址一样,符合下一跳才能往那边走
断言:开发人员可以匹配HTTP请求的所有内容,如果请求和断言匹配才能进行路由
过滤:就像SpringMVC过滤器一样,可以在断言后的请求传进来之后对它进行一些修改
使用:
写POM:引入gateway坐标依赖 *注意:gateway不能和web依赖共存
写yml:注册Eureka服务,修改端口和应用名
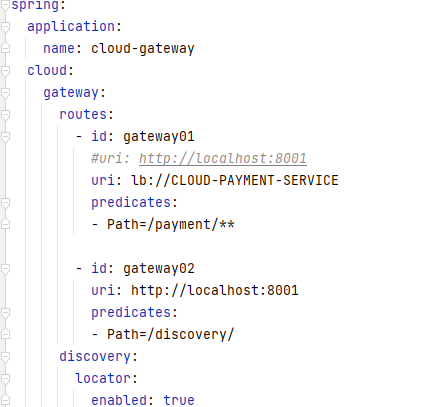
除此之外,还需要在cloud.gateway里面配置对应的 id、uri和断言,uri使用微服务名的话就开启动态路由
主启动:配置@SpringBootApplication和@EnableEurekaClient
访问 http://IP地址:网关端口/寻找路径 就可以调用其他端口的方法
动态路由:
由于在上面我们的uri是写死了,对于服务集群十分的不方便,所以我们需要配置 动态路由+负载均衡
修改uri为:lb://服务名 其中lb为Gateway自带的负载均衡uri,配置了这个就可以直接使用负载均衡
还需要修改discovery.locator.enable=true,这样配置的话就可以访问 http://localhost:8001/服务名/路径 来寻找服务,替换我们的 http://localhost:8001/路径 来寻找服务
predicates断言:
- After:从什么时候开始才能访问这个服务 时间串可以通过ZonedDataTime获取时间
- Before:从什么时候之前才能访问这个服务
- Between:以上两个的结合
- Cookie:必须携带什么cookie,有两个参数,一个是cookie名,一个是正则表达式
- Header:必须携带什么样的头部信息,有两个参数,一个是属性名,一个是正则表达式
- Path:匹配路径
- Method:必须是什么请求方法访问才能访问
Gateway过滤器:
修改yml中的filter的方法:可以修改已经放进来的HTTP请求中的东西
自定义过滤器:
实现GlobalFilter,Ordered接口,并重写里面的方法:getOrder方法是指加载过滤器的优先级,越小越高;filter方法是指过滤的方法,返回chain.filter,里面参数是exchange,类似ServletHttpRequest
如果判断失败的话,可以不让他访问指定的资源

服务网关中心的总结:
通过网关中心,我们可以把原有用于开放微服务的端口关闭,转由网管中心动态转发至各个微服务接口。配置上来说需要注意yml配置中的id、uri和断言三部分的配置,这三部分负责匹配与路由转发,其他的yml配置基本上和其他中心大同小异
配置中心:
Config:
公有配置放在配置中心,私有配置放在各个微服务处
服务端:
为各个连接的到服务器的客户端提供公用的配置方法,为所有环境提供一个中心化的外部配置,也可以动态刷新各个微服务配置
配置与设置:
先把自己的配置文件放在github,有test、dev、prod环境配置文件
使用配置服务中心:
建module:新建配置中心模块
写POM:引入spring-cloud-config-server依赖坐标
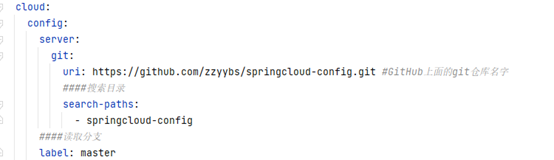
写yml:需要添加
config.server.git.url=github的url 表示github仓库的地址
config.server.git.search-path=- springcloud-config 表示搜索的路径
config.label=master 设置分支
主启动:加入@EnableConfigServer
这里我们直接连接教程的github地址
配置读取规则:
/{label}/{application}-{profile}.yml 我觉得这个最好用
/{application}-{profile}.yml
/{application}/{profile}/{label}
/{name}-{profiles}.yml
/{label}-{name}-{profiles}.yml
其中name为服务中心的服务名称
客户端:
去访问服务器用于寻找github的配置文件
写POM:引入spring-cloud-config-client依赖坐标
写yml:要使用bootstrap.yml这个配置文件,bootstrap.yml要比application.yml的优先级更高,但和application.yml共享一个环境,它适用于读取外部配置,而application.yml适合于读取自己的配置
主启动:无需特殊配置
业务类:编写具体业务
当启动的时候,服务器会给我们加载bootstrap.yml文件,用于读取外部的配置,同时把自身的yml数据加载进环境,合起来就是我们该模块环境的总体配置
存在问题(每次修改后重启问题):
当我们修改github的文件时,服务器会立刻做出响应,修改获取到的yml内容,但是客户端已经成功加载了,并不会自动重新获取,每次重启不现实
解决方法:
使用actuator依赖进行监控
暴露自己的监控端点
然后在Controller层加入@RefreshScope注解
运维人员使用POST请求发送refresh命令到客户端的/actuator/refresh,即可完成刷新

消息总线中心:
Bus:
Bus支持两种消息代理:RabbitMQ和Kafka
两种设计思想:
一是发送给一个服务中心,让服务中心通知各个客户端(推荐)
二是发送给一个客户端,让这个客户端去通知其他客户端(破坏了客户端的职责单一性)
处理一次请求多处修改的服务器与客户端配置:
POM引入
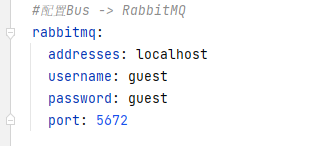
yml添加RabbitMQ的配置项目 服务器还需要配置自己暴露的监控端点 bus-refresh
*注意15672是web可视化访问端口,但是真正RabbitMQ访问的端口是5672
开启服务,在cmd可以使用curl指令来执行POST请求的发送,服务器会发送刷新请求给刷新服务器,服务器再把刷新执行发给各个客户端
定点通知:
修改请求url:http://localhost:配置中心的端口号/actuator/bus-refresh/{destination}
destination中填入 服务名:端口号
这样就只更新特定服务
消息驱动中心:
Stream:
解决了前中后端消息中间件不同的问题,可以使用流来发送,一种不再关注MQ细节,但是可以在各种MQ中切换的技术 现在只支持RabbitMQ和Kafka,就像一个翻译器一边输入一边输出,但是可以解决适配问题
编码API:
Middleware:中间件
Binder:绑定器,用于绑定输入输出者,连接两方
常用注解:
@Input:标注输入通道,消息会由此输入
@Output:标注输出通道,消息会由此输出
@StreamListener:消息监听器,用于监听是否有消息进入中间件
@EnableBinder:把队列和exchange绑定在一起
服务器配置:
改POM:引入stream-rabbit依赖坐标
改yml:在spring.cloud.binders写入绑定器的属性
binders:
绑定器名:
type:rabbit ==》 绑定器类型
environment:
spring:
以下是rabbit信息
bindings: 这是实现队列和交换机的绑定
通道名称:
destination:这个表示要使用的Exchange名字
content-type:表示传输的消息类型
binder:上面的绑定器名

编写服务器输出接口及其实现类:实现类中需要加上@EnableBinding注解,发送方参数填写为Source.class,表示定义消息的推送管道。里面还需要定义MessageChannel对象实例,就是一个消息队列,用于发送消息,里面有send方法是用来发送消息的
编写Controller类自动注入接口
调用就可以了
客户端配置:
改POM和yml:与上面一致
业务类:实现类中需要加上@EnableBinding注解,接收方参数填写为Sink.class,在需要处理消息的方法上使用@StreamListener注解,里面参数是Sink.INPUT,用于监听发送去RabbitMQ的消息,可以使用Message对象去接收
SpringCloud Alibaba:
出现原因:很多springcloud的支持都进入了维护模式,导致我们自己很被动,需要提供新组件来使用
Nacos:代替Eureka做服务注册中心,代替Config做服务配置中心
服务注册中心:使用Nacos的话可以下载了使用/bin/startup.cmd进行启动,由此通过http://localhost:8848/nacos访问到Nacos中心
服务端:
新建模组
写POM:引入spring-cloud-starter-alibaba-nacos-discovery依赖,开启对Nacos服务注册中心的支持
改yml:修改应用名称,修改discover-server-addr,设置为Nacos中心的地址,并暴露 * 端点
主启动:除了标准启动类以外,还需要加上@EnableDiscoveryClient,用于被Nacos服务器发现
业务类:定义具体业务
通过web网页可以控制注册到Nacos的服务

客户端:
新建模组
写POM:引入Nacos坐标依赖
改yml:修改应用名,端口号,而且要配置nacos的连接设置
主启动:和上面一致
业务类:由于Nacos自带Ribbon负载均衡功能,需要搭配RestTemplate使用,所以需要新建RestTemplate并添加@LoadBalanced注解。在业务类中可以使用 服务名:端口/路径 的方式访问

各种服务中心的对比:
Nacos可以切换CP和AP,使用 curl -X PUT '$NACOS_SERVER:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=**' **表示是切换的模式
服务配置中心:可以直接把文件放到Nacos服务器,不用放去github了
引入spring-cloud-starter-alibaba-nacos-config依赖
改yml:添加spring的config配置,配置服务器地址和文件拓展名
主启动:如上
业务类:定义具体的业务,如果是要拉去配置,还要加上手动刷新的注解@RefreshScope,但是Nacos做了改进,可以自动刷新了,也不用使用Bus去发送刷新请求了


拉取的DataId配置文件格式规范:三个属性都可以在自己的yml中配置的
${spring.application.name}-${spring.profile.active}.${file.extension}
即 应用名-环境.后缀
在Nacos里面使用了三个空间来对配置进行分组,分别是Namespace、Group和DataId,就类似于Java里面的package、类名、方法名一样
Namespace用于切换部署环境,不同Namespace是实现隔离的,比如三个环境:test、dev、prod
Group可以把不同的微服务但是是同一个开发环境下的东西放在一起
DataId用于区分不同的微服务
如何分组:
DataId配置方案:指定spring的profile和配置文件的DataId来使不同环境下读取不同的配置
例如 默认空间+默认分组+***-dev/prod.yaml
Group配置方案:在yml中的nacos.config由group属性,可以特殊指定某个组
Namespace配置方案:在yml里同样有nacos.config可以配置namespace,特殊指定 某个命名空间ID
******重点******
Nacos集群:
避免单点故障,实现高可用
由于官网推荐Nacos集群的环境是Linux,所以安装Linux的Nacos,并且需要反向代理,所以我们还需要一个Nginx,一个持久化用的mysql
集群配置步骤:
1.配置集群内持久化方案,配置mysql的properties
2.在conf里面配置集群方案,使用cluster.properties.example作为模板,制作cluster.properties,并在里面配置集群的地址

3.修改sh脚本,让它能接受-p参数,即在里面加入-p参数的判断,并以此作为开启指定nacos服务器的sh脚本
4.配置Nginx,让它作为负载均衡处理器,编辑Nginx的conf文件,修改Nginx的监听端口,由此监听端口转发去其他端口,并配置location参数,使Nginx知道要转发去哪里
5.在我们需要注册进Nacos的服务中,修改yml文件,转发前往Nginx,再让Nginx转发出去给集群的Nacos,转发到谁就是谁

Nacos持久化方案:
像一些需要持久化储存的Nacos配置等,需要使用一个持久化的储存方案,默认Nacos自带derby,可以切换成其他大的数据库,但目前只支持mysql
在/conf/里面有一个sql的文件,在mysql导入后,在conf里面的application.propeties修改关于数据库的相关配置,即可把储存方式从一开始的derby修改成mysql
Sentinel:代替Hystrix实现熔断和限流,并且提供了Web界面让我们进行更加精细的操作
使用是需要安装Sentinel Dashboard,用于对于Sentinel的精细化操作:可以使用 --server.port=xxxx 进行默认端口的修改
使用方法:
需要额外引入:
1.sentinel的依赖坐标
2.nacos的数据库操作依赖(因为我们使用了外部储存)
3.nacos服务注册
yml配置:需要配置nacos和sentinel的地址,并且暴露端点
Sentinel采用懒加载的策略,当启动的时候dashboard不会给你加载消息,只有你访问了页面之后Sentinel才会给你加载方法的相关信息
当访问需要被sentinel检测的页面后,sentinel dashboard会加载相关信息,提供各种服务
簇点链路:
有哪些路径,是供用户访问的
流控规则:
基本介绍:定义流量控制的模式及规则
资源名:唯一名称,默认为请求路径
针对来源:可以对某个调用者限制流量,填写调用者的微服务名称,默认为default
阈值:
QPS:每秒钟请求的次数
线程数:调用该API的线程数
如果达到阈值了,就会进行限流
是否集群:是否是集群模式
流控模式:
直接:当到达阈值之后,直接限流
关联:当关联的资源到达阈值时,限流自己
链路:记录链路上的流量,如果达到阈值就限流
流控效果:
快速失败:直接拒绝
Warm Up,根据冷加载因子的指,经过预热时长,才达到阈值
均匀:均匀通过流量
流控模式:
在Sentinel的Web管理界面中添加流控规则:
QPS:阈值表示每秒能请求的次数
线程数:阈值表示同一时间内能同时处理请求的线程数
关联:资源A、B,当资源A访问到达阈值之后,就会限流绑定的资源B
应用场景:比如我支付接口访问到达阈值后,就限流下订单接口
Warm Up:当请求流量一瞬间拉高的时候,系统很可能被压垮,预热就是用来解决这个问题
类似于慢开始,阈值一开始为 设定的阈值/3 ,慢慢拉升到设定的阈值,而不是流量一下子就爆满打垮系统,动态改变阈值
需要配置预热时长
均匀:所有请求都排队,均匀通过,请求超时的话就重试
降级熔断规则:
配置:
RT:平均响应时间,类似于Hystrix的执行超时时间,如果处理一个请求的时间 超过这个时间 且 在这段时间内请求的次数大于 设定的请求数 就进行服务降级
异常比例数:QPS大于等于5的且在窗口时间内正常执行与抛出异常的比例达到一定值的时候,触发服务降级
异常数:当窗口时间(必须大于60s)内异常数大于某个阈值的时候,触发服务降级
热点规则:
把在一段时间内最频繁访问的资源进行流量限制,仅支持检测窗口时间的QPS
配置:
在Sentinel的Web管理界面中配置监控的参数索引和请求次数与时间等数据,当超过阈值之后,会服务降级并返回Error Page和异常信息
这对用户来说十分不友好,所以我们使用了@SentinelResource注解,用于自定义降级方法
高级配置:
如果我们参数为特定值的时候,就可以自己特别的为它设立一个阈值:比如 我设定id的阈值是10QPS,但是有一个账号id=5是特殊的,他的阈值可以达到200QPS,这样就可以通过高级配置设置
系统配置:
Load:自适应配置,仅对Linux或Unix生效,以系统load来自判断,当到达条件就限流
CPU:当CPU占用率到达多少就限流
......
从@HystrixCommand到@SentinelResource:
@SentinelResource:其实它表示的是在Sentinel面板里面的唯一标识,和Sentinel中的资源名绑定。
里面有很多属性,例如:
blockHandler:违规处理器等。它只能用来处理违规操作,不能在发生Java异常的时候返回自定义异常页面
fallback:异常降级处理器,可以处理Java异常

自定义规则处理:
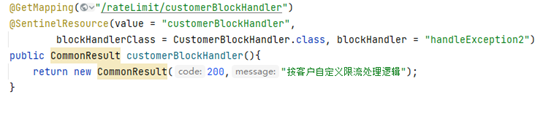
编写违规方法并在需要降级的方法上指定@SentinelResource,使用blockHandler来指定违规处理器,违规方法的参数要和降级方法一致(和Hystrix一样都是要一致),而且还要加上BlockException参数

@SentinelResource详解:
为什么要用@SentinelResource:
这个注解可以指定我们违规操作降级方法和异常降级方法,当流量违规之后会跳入违规处理器返回对应界面给用户,当Java发生运行时异常时也会跳入相关的异常降级处理器来进行处理
属性:
blockHandlerClass + blockHandler:
blockHandlerClass表示是使用哪一个类作为违规处理类,而blockHandler表示是用哪一个方法来进行违规降级
blockHandlerClass不填写的话默认是本类,里面的方法必须都是静态方法,否则Sentinel会找不到这个方法
违规处理方法的参数必须要有BlockException,否则会无效
fallback:定义异常处理类方法,用于处理RuntimeException,并进行相应的业务处理
exceptionToIngore:忽略的异常,当运行的时候抛出里面异常的时候将忽略掉
blockHandler和fallback一起使用:如果是还没限流,就就进入fallback方法处理降级;如果是限流了,就进入blockHandler方法处理限流
配合Ribbon的话,是使用RestTemplate进行负载均衡
但是也可以配合OpenFeign,使用@EnableFeignClients和@FeignClient注解来进行负载均衡以及异常的降级处理
Sentinel规则持久化:
当重启服务的时候,刷新Sentinel Dashboard,就会把之前设置的限流规则全部清空,所以我们要设置Sentinel规则持久化
需要在需要持久化的模块上:
1.引入Sentinel-Datasource-Nacos依赖包,用于把Sentinel的流控规则传入Nacos

2.在yml中配置
datasource:
ds1:
nacos:
server-addr: localhost:8848 //Nacos服务器
dataId: cloudalibaba-sentinel-service //要找哪个dataId
groupId: DEFAULT_GROUP //要找哪个分组
data-type: json //要找什么数据类型
rule-type: flow //是什么规则
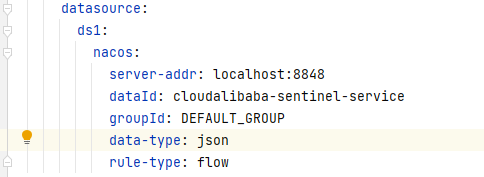
3.在Nacos上传JSON配置,匹配规则和上面一样
4.完成持久化
Seata分布式事务处理:跨JVM、跨数据库实例
分布式:单机单库 -> 单机多库 -> 多机多库(专库专连)
一次业务调用多个库的时候,就会引出分布式事务数据一致性问题
一ID,三组件:
ID:全局唯一一个XID
TC:一个全局事务的协调器,用于协调整个TC业务
TM:事务管理器,全局事务中,单个事务的处理边界,用于提交给TC,并让TC跳转到下一步
RM:资源管理器,用于控制资源与数据库的连接


 浙公网安备 33010602011771号
浙公网安备 33010602011771号