第一次个人编程作业
|这个作业属于哪个课程|信安1912-软件工程|
| ---- | ---- | ---- |
|这个作业要求在哪里|个人项目作业|
|这个作业的目标|论文查重:熟悉个人开发流程 PSP表格使用 软件的性能优化方式 异常处理|
正文
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 5 | 5 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 625 | 505 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 100 |
| · Design Spec | · 生成设计文档 | 5 | 15 |
| · Design Review | · 设计复审 | 5 | 5 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 5 |
| · Design | · 具体设计 | 120 | 30 |
| · Coding | · 具体编码 | 240 | 200 |
| · Code Review | · 代码复审 | 60 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 120 |
| Reporting | 报告 | 105 | 145 |
| · Test Repor | · 测试报告 | 30 | 50 |
| · Size Measurement | · 计算工作量 | 15 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 90 |
| · 合计 | 735 | 655 |
实现思路
其实这个博客是我一边写代码一边在草稿里写的,因此可以看到不同版本的进度
开头就决定了采用python编写,毕竟众所周知python中有很多非常好用的库可以进行文字处理啊图像处理的工作,然后去查了一些资料了解到了文本处理中比较特别常用的一些文本处理库。
二话不说先pip install了,技术可以晚点学库一定要先装了总之开心就好
其实不仅仅查到了自己目前在使用的技术,还有别的常见的一些关于文本处理的技术也花了一部分时间去学习,直接导致了PSP表中Analysis(包括学习新技术)的部分远远超出了预期。
相关技术
-
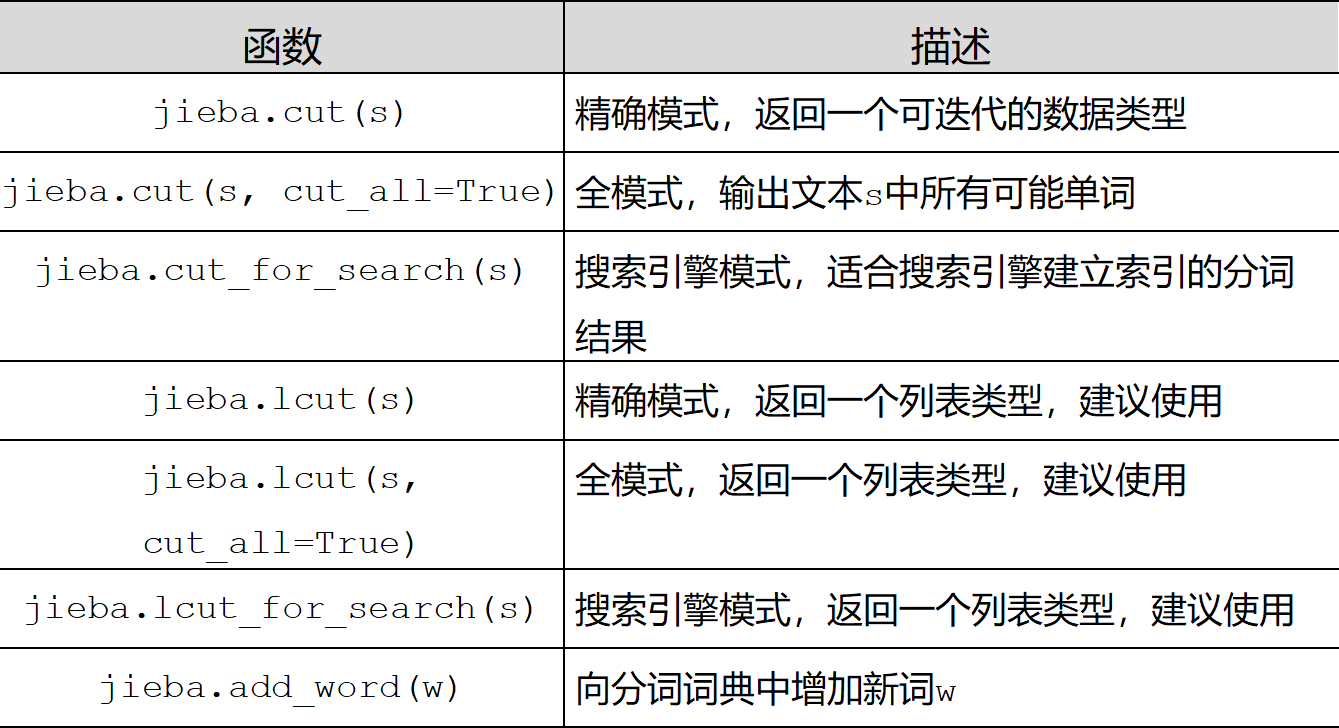
jieba
jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式、全模式和搜索引擎模式,下面是三种模式的特点。
精确模式:试图将语句最精确的切分,不存在冗余数据,适合做文本分析
全模式:将语句中所有可能是词的词语都切分出来,速度很快,但是存在冗余数据
搜索引擎模式:在精确模式的基础上,对长词再次进行切分
-
余弦相似度
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。从而两个向量之间的角度的余弦值确定两个向量是否大致指向相同的方向。两个向量有相同的指向时,余弦相似度的值为1;两个向量夹角为90°时,余弦相似度的值为0;两个向量指向完全相反的方向时,余弦相似度的值为-1。这结果是与向量的长度无关的,仅仅与向量的指向方向相关。余弦相似度通常用于正空间,因此给出的值为-1到1之间。
注意这上下界对任何维度的向量空间中都适用,而且余弦相似性最常用于高维正空间。例如在信息检索中,每个词项被赋予不同的维度,而一个维度由一个向量表示,其各个维度上的值对应于该词项在文档中出现的频率。余弦相似度因此可以给出两篇文档在其主题方面的相似度。
另外,它通常用于文本挖掘中的文件比较。此外,在数据挖掘领域中,会用到它来度量集群内部的凝聚力。

-
gensim
Gensim(generate similarity)是一个简单高效的自然语言处理Python库,用于抽取文档的语义主题(semantic topics)。Gensim的输入是原始的、无结构的数字文本(纯文本),内置的算法包括Word2Vec,FastText,潜在语义分析(Latent Semantic Analysis,LSA),潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)等,通过计算训练语料中的统计共现模式自动发现文档的语义结构。这些算法都是非监督的,这意味着不需要人工输入——仅仅需要一组纯文本语料。一旦发现这些统计模式后,任何纯文本(句子、短语、单词)就能采用语义表示简洁地表达。
查了但是没用上的其他相关技术
- 海明距离
和余弦距离类似,计算特征向量之间的距离。 - simhash
其主要思想是降维,将高维的特征向量映射成低维的特征向量,通过两个向量的Hamming Distance来确定文章是否重复或者高度近似。 - 机器学习
倒是以前了解过这个,最开始的时候也思考过这个方向,没想到真的看到有同学写了还蛮震撼的。
模块接口的设计
要实现的功能
- 文章预处理
- 分词
- 整理字典,得到向量
- 计算距离
- 读写文件
- 异常处理
设计上其实最开始是想着尽量上面几个功能分开来进行,结果因为其实基本都是靠调用现有的库就解决了,导致了部分的功能合并。
具体实现
此项以最终版本(第五版)讲解
- get_file_contents
传入路径,获得文本。 - filter
过滤器+分词。
def filter(string):
result_text = []
pattern = re.compile(u"[^a-zA-Z0-9\u4e00-\u9fa5]") #定义正则表达式匹配模式
data = pattern.sub("",string) # 只保留英文a-zA-z、数字0-9和中文\u4e00-\u9fa5的结果。 去除标点符号
result_text = [i for i in jieba.cut(data, cut_all=False) if i != ''] #分词
return result_text
- calc_similarity
传入过滤数据,生成向量并计算结果。
#传入过滤数据
def calc_similarity(text1, text2):
texts = [text1, text2]
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))
test_corpus_1 = dictionary.doc2bow(text1)
cosine_sim = similarity[test_corpus_1][1]
return cosine_sim
- main_test
字面意义,调用其他函数得出结果并进行四舍五入。

独到之处
我觉得我的异常处理写的比较清晰。
我博客写的也很用心。
性能分析
工具介绍
- time
Python time time() 返回当前时间的时间戳(1970纪元后经过的浮点秒数)。 - profile
其中输出每列的具体解释如下:
ncalls:表示函数调用的次数;
tottime:表示指定函数的总的运行时间,除掉函数中调用子函数的运行时间;
percall:(第一个 percall)等于 tottime/ncalls;
cumtime:表示该函数及其所有子函数的调用运行的时间,即函数开始调用到返回的时间;
percall:(第二个 percall)即函数运行一次的平均时间,等于 cumtime/ncalls;
filename:lineno(function):每个函数调用的具体信息;
如果需要将输出以日志的形式保存,只需要在调用的时候加入另外一个参数。如 profile.run(“profileTest()”,”testprof”)。 - coverage
coverage是一种用于统计Python代码覆盖率的工具,通过它可以检测测试代码对被测代码的覆盖率如何。可以高亮显示代码中哪些语句未被执行,哪些执行了,方便单测。并且,coverage支持分支覆盖率统计,可以生成HTML/XML报告。
具体分析状况及改进
以下部分是在第三版的情况下写的
因为在第二版的情况下我不满意余弦相似度的精确度,但兜兜转转没什么区别。(指看到了舍友的结果)
第三版的运行时间:

第三版但采用第二版方式计算余弦相似度的运行时间:

可以看到快了很多,两个版本主要差距在于生成向量的部分。
事实上两个版本代码主要的差距在于构造向量的部分第二版更多的使用了调用的库,果然比自己写的快,因此部分回退到第二版,但保留其它优化。
至此快进到第四版:
- 总体运行时间
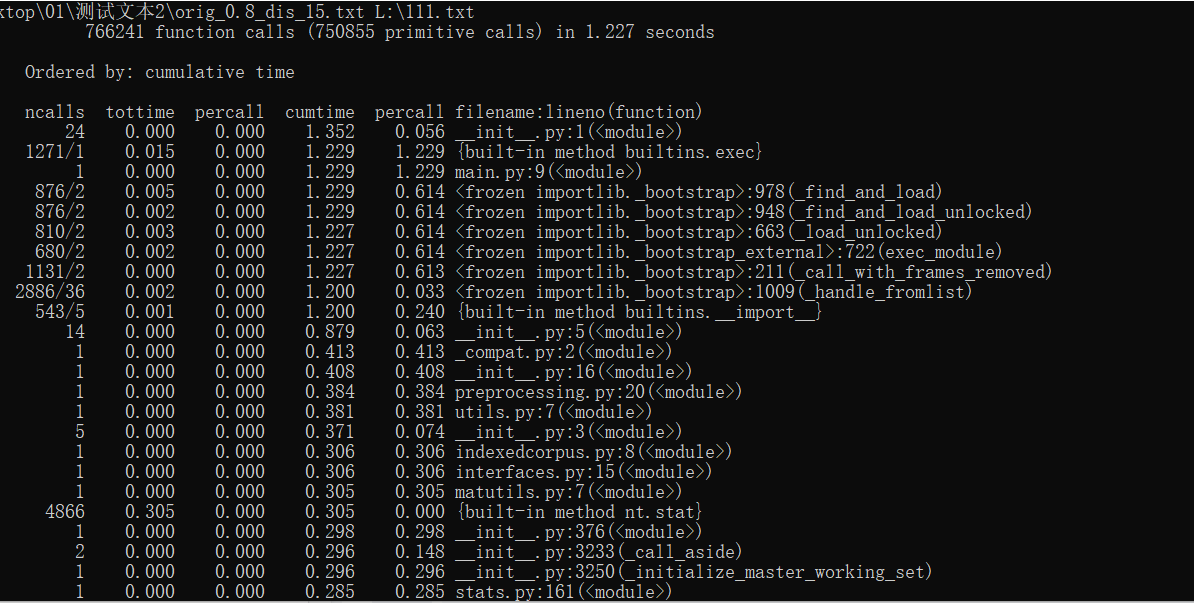

使用-s cumulative 可按时间进行排序。 - 各个函数运行时间
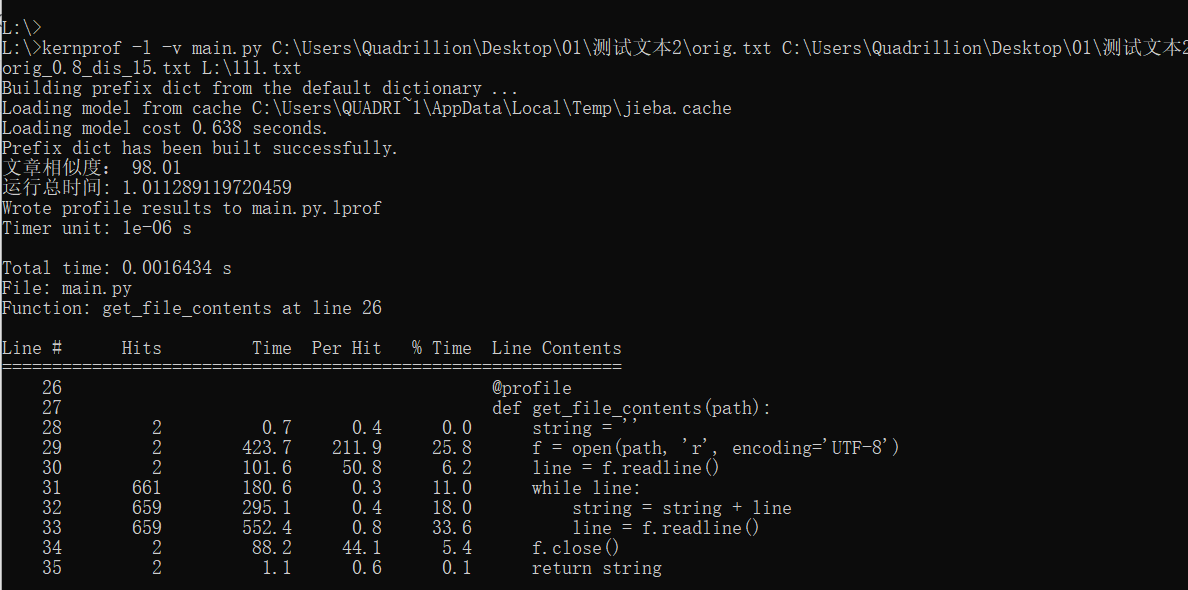


使用line_profiler分析各个函数。
(发现加入性能分析的版本好像会导致整个时间延长欸)
单元测试
- 单元测试(第五版)
import unittest
from main import main_test
from main import get_file_contents
class MyTestCase(unittest.TestCase):
def test_something(self):
self.assertEqual(main_test(r'C:\Users\Quadrillion\Desktop\01\测试文本2\orig.txt',r'C:\Users\Quadrillion\Desktop\01\测试文本2\orig_0.8_dis_1.txt'),99.83000159263611)
#unittest2 文件0000为我编写的空txt文件
class MyTestCase2(unittest.TestCase):
def test_something(self):
self.assertEqual(main_test(r'C:\Users\Quadrillion\Desktop\01\测试文本2\0000.txt',r'C:\Users\Quadrillion\Desktop\01\测试文本2\orig_0.8_dis_1.txt'),0)
#unittest2 文件0001内容为"无事发生"
class MyTestCase3(unittest.TestCase):
def test_something(self):
self.assertEqual(get_file_contents(r'C:\Users\Quadrillion\Desktop\01\测试文本2\0001.txt'),"无事发生")
if __name__ == '__main__':
unittest.main()

- 覆盖率

覆盖率截图,覆盖率百分之百达成目标!
异常处理
设计
设计上来讲要求的输入格式是 Python: python main.py [原文文件] [抄袭版论文的文件] [答案文件]
而其它部分只是普通运行,因此主要的异常应该就是出现在输入的异常。
在我的理解下主要有四种:
- 输入文件数量错误。
- 输入文件本身格式错误(比方说不是txt的文本)。
- 输入文件不存在。
- 原文文件或者抄袭文件为空。
说是这么说其实前两个在我个人的测试下其实都会直接在命令行报错,只有第三个会让程序运行得到重复率为0的结果,但文章为空,逻辑上来讲那确实没有重复吧。
具体实现
- os.path.exists
- .endswith
- os.path.getsize
if __name__ == '__main__':
text1_abs_path = sys.argv[1]
text2_abs_path = sys.argv[2]
save_abs_path = sys.argv[3]
if not os.path.exists(text1_abs_path) :
print("论文原文文件不存在!")
exit()
if not os.path.exists(text2_abs_path):
print("抄袭版论文文件不存在!")
exit()
if not os.path.exists(save_abs_path):
print("答案文件文件不存在!")
exit()
if text1_abs_path.endswith('.txt')==False:
print("原文文件格式错误!")
exit()
if text2_abs_path.endswith('.txt')==False:
print("抄袭版论文文件格式错误!")
exit()
if save_abs_path.endswith('.txt')==False:
print("生成文件格式错误!")
exit()
if os.path.getsize(text1_abs_path) == 0:
print("论文原文文件是空的")
if os.path.getsize(text2_abs_path) == 0:
print("抄袭版论文文件是空的")
总结
- 不足之处
感觉自己是真的技不如人,对于优化没什么自己的思路,因为算法知识不够吧。
在进行异常处理和性能分析的时候可以说是毫无经验全是现学现卖。
自己的开发流程还是不够规范,到了第二第三版本的时候开始乱了,且对程序进行大规模改动。
在开发过程中bug很多,全靠试错一点点改,说到底是对python不够熟悉。
总之希望设计的时候可以更加清晰,成熟。 - 收获
学会了关于文本处理的算法,了解了很多python的相关的库的使用。
了解了一个项目开发的规范的流程。
学会了python的命令行相关知识。
初步了解了版本管理,确实觉得很方便。
了解了软件性能分析的相关。下次去下个pycharm吧
编写代码的能力也自然提升了。
边做软件边学习的能力大大增加了。 - 个人感想
是第一次按照软件工程的方式写一个程序,以前其实写过一些算法题,也写过java的课程设计,但都是想到哪写到哪,这次是第一次以一个特别系统的流程来进行,虽然说在写这个博客的过程中已经有部分同学提交了作业,深刻的感受到了自己的水平不如他们(特别是写了机器学习的),但至少这次的作业我个人是满意的,我也尽力学习了很多新的技术,解决了各种各样的问题,实现了老师的目标,特别是第一次学会了性能分析,仿佛打开了新世界的大门,毕竟之前都是那种只要程序能跑起来没有bug实现了功能就一切安好的人,甚至连代码美观都不怎么注意的。总之就是有进步,并且进步还挺大的,所以很满意!
希望以后也能学到更多知识!
