


不平衡数据的处理
传统处理方法
1.加权
即其对不同类别分错的代价不同,这种方法的难点在于设置合理的权重,实际应用中一般让各个分类间的加权损失值近似相等。当然这并不是通用法则,还是需要具体问题具体分析。和代价敏感类似
有如下加权方法:
概率权重法:当数量差距不那么悬殊时,把各类标签的实例出现的频率比作权重,此特征权重来源于数据本身,能够较好的适应数据集的改变;
2.采样
采样方法是通过对训练集进行处理使其从不平衡的数据集变成平衡的数据集,在大部分情况下会对最终的结果带来提升。
采样分为过采样和欠采样,过采样是把小众类复制多份,欠采样是从大众类中剔除一些样本,或者说只从大众类中选取部分样本。随机采样最大的优点是简单,但缺点也很明显。过采样后的数据集中会反复出现一些样本,训练出来的模型会有一定的过拟合;而欠采样的缺点显而易见,那就是最终的训练集丢失了数据,模型只学到了总体模式的一部分。过采样会把小众样本复制多份,一个点会在高维空间中反复出现,这会导致一个问题,那就是运气好就能分对很多点,否则分错很多点。为了解决这一问题,可以在每次生成新数据点时加入轻微的随机扰动,经验表明这种做法非常有效。
因为下采样会丢失信息,如何减少信息的损失呢?第一种方法叫做EasyEnsemble,利用模型融合的方法(Ensemble):多次下采样(放回采样,这样产生的训练集才相互独立)产生多个不同的训练集,进而训练多个不同的分类器,通过组合多个分类器的结果得到最终的结果。第二种方法叫做BalanceCascade,利用增量训练的思想(Boosting):先通过一次下采样产生训练集,训练一个分类器,对于那些分类正确的大众样本不放回,然后对这个更小的大众样本下采样产生训练集,训练第二个分类器,以此类推,最终组合所有分类器的结果得到最终结果。第三种方法是利用KNN试图挑选那些最具代表性的大众样本,叫做NearMiss,这类方法计算量很大,感兴趣的可以参考“Learning from Imbalanced Data”这篇综述的3.2.1节。
传统的欠采样方法有:smote,smote—borderline,Adasyn等
3.数据合成
数据合成方法是利用已有样本生成更多样本,这类方法在小数据场景下有很多成功案例,比如医学图像分析等。
4.如何选择
解决数据不平衡问题的方法有很多,上面只是一些最常用的方法,而最常用的方法也有这么多种,如何根据实际问题选择合适的方法呢?接下来谈谈一些我的经验。
1、在正负样本都非常之少的情况下,应该采用数据合成的方式;
2、在负样本足够多,正样本非常之少且比例及其悬殊的情况下,应该考虑一分类方法;
3、在正负样本都足够多且比例不是特别悬殊的情况下,应该考虑采样或者加权的方法。
4、采样和加权在数学上是等价的,但实际应用中效果却有差别。尤其是采样了诸如Random Forest等分类方法,训练过程会对训练集进行随机采样。在这种情况下,如果计算资源允许上采样往往要比加权好一些。
5、另外,虽然上采样和下采样都可以使数据集变得平衡,并且在数据足够多的情况下等价,但两者也是有区别的。实际应用中,我的经验是如果计算资源足够且小众类样本足够多的情况下使用上采样,否则使用下采样,因为上采样会增加训练集的大小进而增加训练时间,同时小的训练集非常容易产生过拟合。
6、对于欠采样,如果计算资源相对较多且有良好的并行环境,应该选择集成 Ensemble方法。
5.Ensemble方法
通过聚合多个分类器的预测来提高分类的准确率,这种技术称为组合方法(ensemble method) 。组合方法由训练数据构建一组基分类器,然后通过对每个基分类器的预测进行权重控制来进行分类。
Ensemble技术在数据挖掘的三个方向:
1.在样本上做文章,基分类器为同一个分类算法,主要的技术有bagging,boosting;
2.在分类算法上做工作,即用于训练基分类器的样本相同,基分类器的算法不同,
3.在样本属性集上做文章,即在不同的属性空间上构建基分类器,比较出名的是randomforestTree算法,这个在weka中也有实现。
Ensemble Methods大致包括三种框架——Bagging,Boosting,Stacking。
对于Bagging来说,添加随机变量的学习器反而能够提高整体的效果。这三种方法中,Boosting是表现最好的模型,它与有着广泛研究基础的加性模型(addictive models)的统计技术有着相近的关系。
在验证数据集上找到表现最好的模型作为最终的预测模型:
1)对多个模型的预测结果进行投票或者取平均值;
对于数据集训练多个模型,对于分类问题,可以采用投票的方法,选择票数最多的类别作为最终的类别,而对于回归问题,可以采用取均值的方法,取得的均值作为最终的结果。在这样的思路里最著名的是Bagging方法.Bagging即BoostrapAggregating,其中,Boostrap是一种有放回的抽样方法,其抽样策略是简单的随机抽样。每次的训练集由初始的训练集中随机取出的训练样本组成,初始的训练样本在某次的训练集中可能出现多次或者根本不出现。
2)对多个模型的预测结果做加权平均;
在上述的Bagging方法中,其特点在于随机化抽样,通过反复的抽样训练新的模型,最终在这些模型的基础上取平均。而在对多个模型的预测结果做加权平均则是将多个弱学习模型提升为强学习模型,这就是Boosting的核心思想。Boosting算法中,初始化时对每个训练样本赋予相等的权重,如frac{1}{n},然后用该学习算法对训练集训练G轮,每次训练后,对训练失败的训练样本赋予更大的权重,也就是让学习算法在后续的学习中几种对比较难学的训练样本进行学习,从而得到一个预测函数序列left { h_1,cdots ,h_G right},其中每个h_i都有一个权重,预测效果好的预测函数的权重较大。
组合分类器优于单一分类器的必须满足条件:
基分类器之间是相互独立的
基分类器应当好于随机猜测分类器
强弱可学习算法
在概率近似正确(probably approximately correct,PAC)学习的框架中,一个概念(一个类),如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么就称这个概念是强可学习的。一个概念,如果存在一个多项式的学习算法能够学习它,学习正确率仅比随机猜测略好,那么就称这个概念是弱可学习的。Schapire指出在PAC学习框架下,一个概念是强可学习的充分必要条件是这个概念是弱可学习的。那么对于一个学习问题,若是找到“弱学习算法”,那么可以将弱学习方法变成“强学习算法”。
提升学习方法有两个问题:
1. 每一轮如何改变训练数据的权重或概率分布
2. 如何将弱分类器整合为强分类器。
①提高被前一轮弱分类器错误分类的权值,而降低那些被正确分类样本权值,这样导致结果就是那些没有得到正确分类的数据,由于权值加重受到后一轮弱分类器的更大关注。
②adaboost采取加权多数表决方法,加大分类误差率小的弱分类器的权值,使其在表决中起到较大的作用,相反减小误差率的弱分类的权值,使其在表决中较小的作用。
具体说来,整个Adaboost 迭代算法就3步:
1)初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权重:1/N。
2)训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权重就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。然后,权重更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
3)将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
6.模型算法
Cost-Sensitive 算法
paper: The Foundations of Cost-Sensitive Learning
MetaCost算法
paper: https://homes.cs.washington.edu/~pedrod/papers/kdd99.pdf “MetaCost”
github: https://github.com/Treers/MetaCost “MetaCost-Python-Coding”
步骤为:
-
在训练集中多次采样,生成多个模型。
-
根据多个模型,得到训练集中每条记录属于 每个类别的概率。
-
计算训练集中每条记录的属于每个类的代价, 根据最小代价,修改类标签。
-
训练修改过的数据集,得到新的模型。
![]()

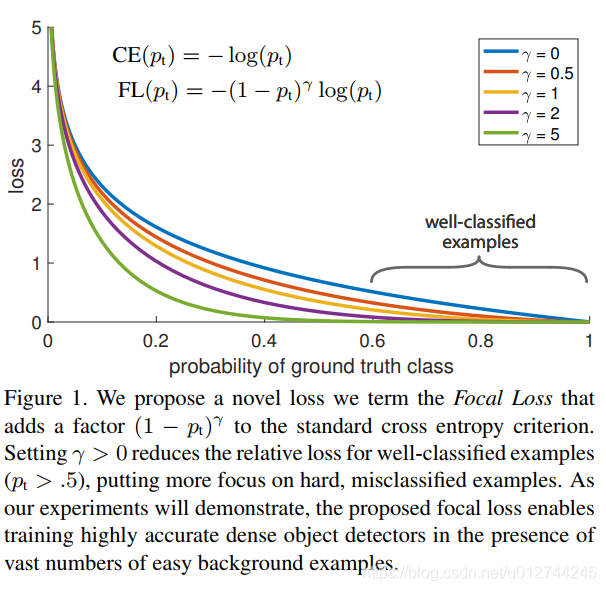
Focal Loss
paper: Focal Loss for Dense Object Detection
Focal loss 是在标准交叉熵损失基础上修改得到的,通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。
7.数据增强
UDA (Unsupervised Data Augmentation)
paper: Unsupervised Data Augmentation For Consistency Training
github: Unsupervised Data Augmentation
一个半监督的学习方法,减少对标注数据的需求,增加对未标注数据的利用。
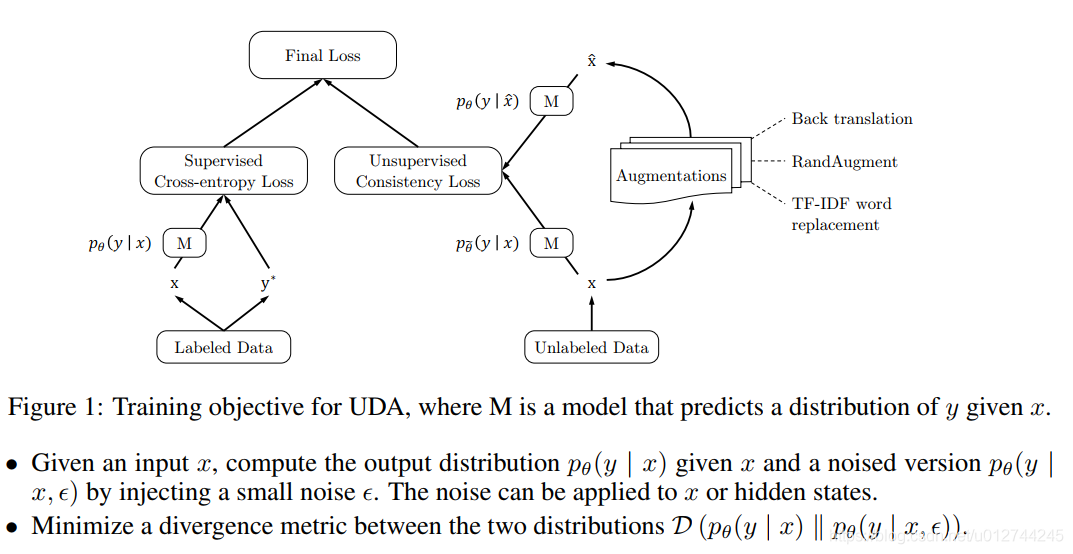
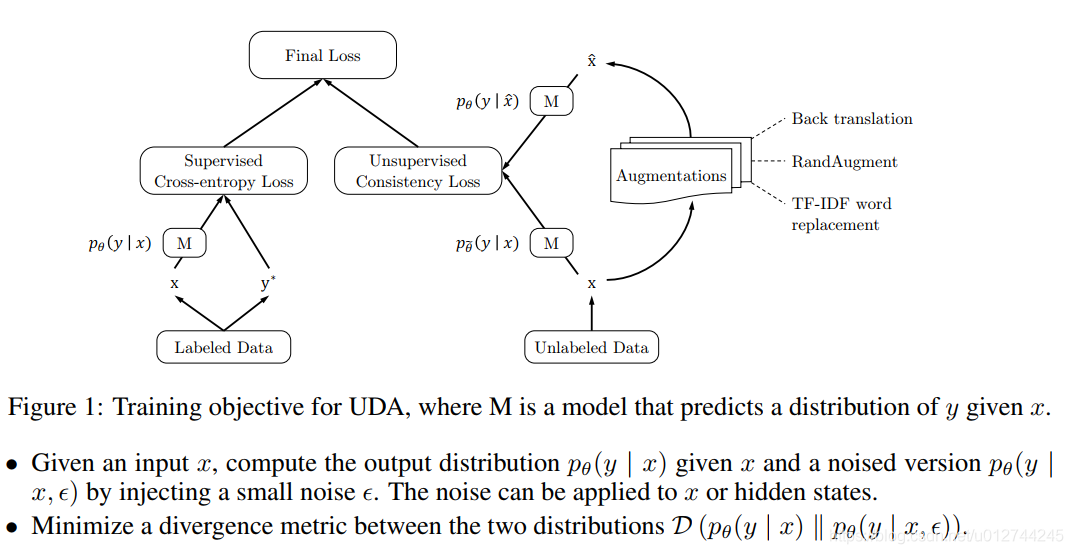
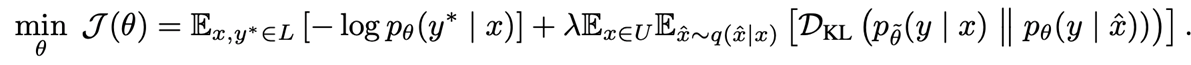
UDA使用的语言增强技术——Back-translation:回译能够在保存语义不变的情况下,生成多样的句式。

那么如何添加噪声ϵ ,来得到增强的数据集x ^ ?
文章给出3类noise:
valid noise: 可以保证原始未标注数据和扩展的未标注数据的预测具有一致性。
diverse noise: 在不更改标签的情况下对输入进行大量修改,增加样本多样性,而不是仅用高斯噪声进行局部更改。
targeted inductive biases: 不同的任务需要不同的归纳偏差。
UDA论文中对图像分类、文本分类任务做了实验,分别用到不同的数据增强策略:
Image Classification: RandAugment
Text Classification: Back-translation回译,保持语义,利用机器翻译系统进行多语言互译,增加句子多样性。
Text Classification: Word replacing with TF-IDF ,回译可以保证全局语义不变,但无法控制某个词的保留。对于主题分类任务,某些关键词在确定主题时具有更重要的信息。新的增强方法:用较低的TF-IDF分数替换无信息的单词,同时保留较高的TF-IDF值的单词。
EDA (Easy Data Augmentation)
国内中文EDA代码实现:https://link.csdn.net/?target=https%3A%2F%2Fgithub.com%2Fzhanlaoban%2FEDA_NLP_for_Chinese
EDA paper:https://link.csdn.net/?target=https%3A%2F%2Farxiv.org%2Fabs%2F1901.11196
EDA GitHub:https://link.csdn.net/?target=https%3A%2F%2Fgithub.com%2Fjasonwei20%2Feda_nlp
EDA 的4个数据增强操作:
同义词替换(Synonym Replacement, SR):从句子中随机选取n个不属于停用词集的单词,并随机选择其同义词替换它们;
随机插入(Random Insertion, RI):随机的找出句中某个不属于停用词集的词,并求出其随机的同义词,将该同义词插入句子的一个随机位置。重复n次;
随机交换(Random Swap, RS):随机的选择句中两个单词并交换它们的位置。重复n次;
随机删除(Random Deletion, RD):以 p的概率,随机的移除句中的每个单词;
使用EDA需要注意:控制样本数量,少量学习,不能扩充太多,因为EDA操作太过频繁可能会改变语义,从而降低模型性能
二:新方法
1.双邻域:通过双邻域机制判断查询邻域中少数类实例的稀疏性,并利用倾向权重机制为易误判的少数类实例加权,由此来提高算法对少数类的敏感性,最后根据加权投票规则完成分类;
2.基于惩罚函数:基于不平衡度提出惩罚函数计算出最大的信息损失量,计算出最多消除多少实例。通过计算每个实例的贡献度来决定消除那个实例。
3.在多分类问题中,可以通过把少数类结合,使他们在数量上与多数类相近,最后变成二分类问题。
4.尝试一个新的角度理解问题:
我们可以从不同于分类的角度去解决数据不均衡性问题,我们可以把那些小类的样本作为异常点(outliers),因此该问题便转化为异常点检测(anomaly detection)与变化趋势检测问题(change detection)。
异常点检测即是对那些罕见事件进行识别。如通过机器的部件的振动识别机器故障,又如通过系统调用序列识别恶意程序。这些事件相对于正常情况是很少见的。
变化趋势检测类似于异常点检测,不同在于其通过检测不寻常的变化趋势来识别。如通过观察用户模式或银行交易来检测用户行为的不寻常改变。
将小类样本作为异常点这种思维的转变,可以帮助考虑新的方法去分离或分类样本。这两种方法从不同的角度去思考,让你尝试新的方法去解决问题。
5.尝试创新
仔细对你的问题进行分析与挖掘,是否可以将你的问题划分成多个更小的问题,而这些小问题更容易解决。你可以从这篇文章In classification, how do you handle an unbalanced training set?中得到灵感。例如:
- 将你的大类压缩成小类;
- 使用One Class分类器(将小类作为异常点);
- 使用集成方式,训练多个分类器,然后联合这些分类器进行分类;
6.设超大类中样本的个数是极小类中样本个数的L倍,那么在随机梯度下降(SGD,stochastic gradient descent)算法中,每次遇到一个极小类中样本进行训练时,训练L次。
7.将大类中样本划分到L个聚类中,然后训练L个分类器,每个分类器使用大类中的一个簇与所有的小类样本进行训练得到。最后对这L个分类器采取少数服从多数对未知类别数据进行分类,如果是连续值(预测),那么采用平均值。
8.设小类中有N个样本。将大类聚类成N个簇,然后使用每个簇的中心组成大类中的N个样本,加上小类中所有的样本进行训练
9.在最近的ICML论文中,表明增加数据量使得已知分布的训练集的误差增加了,即破坏了原有训练集的分布,从而可以提高分类器的性能。这篇论文与类别不平衡问题不相关,因为它隐式地使用数学方式增加数据而使得数据集大小不变。但是,我认为破坏原有的分布是有益的
10.http://web.stanford.edu/~sidaw/cgi-bin/home/lib/exe/fetch.php?media=papers:fastdropout.pdf
三,相关文献
书:
论文:
- Data Mining for Imbalanced Datasets: An Overview
- Learning from Imbalanced Data
- Addressing the Curse of Imbalanced Training Sets: One-Sided Selection (PDF)
- A Study of the Behavior of Several Methods for Balancing Machine Learning Training Data
网页:
https://blog.csdn.net/u012744245/article/details/108602036?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2~all~first_rank_v2~rank_v28-8-108602036.nonecase&utm_term=%E6%AD%A3%E4%BE%8B%E5%92%8C%E8%B4%9F%E4%BE%8B%E6%95%B0%E6%95%B0%E6%8D%AE%E9%9B%86%E7%9A%84%E4%BF%A1%E6%81%AF%E9%87%8F&spm=1000.2123.3001.4430
https://www.cnblogs.com/yuesi/articles/9236796.html
https://www.cnblogs.com/dyl222/p/11055756.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号