Python+RobotFrameWork自动化测试(一):解决selenium适配360急速浏览器问题
背景
新项目的指定浏览器是360急速浏览器,所以使用RobotFarmeWork做前端自动化测试时,需要适配360急速浏览器。在实际应用中robotframework OpenBrowser参数不支持打开360急速浏览器。
问题现象
在安装Selenium2Library依赖包后,使用最新版的python(3.10)+ selenium(4.10)测试打开浏览器失败,报错如下:

简单修改
修改目标文件 selenium\webdriver\chromium\options.py 中 binary_location的方法,可以直接指定浏览器位置
def binary_location(self) -> str:
"""
:Returns: The location of the binary, otherwise an empty string
"""
# test
# if self.capabilities.get("browserName") == "chrome":
# self.binary_location = os.getenv('Chrome360',
# "xxxxxx") # 默认位置
声明
1.由于Selenium WebDriver 版本与库文件的兼容问题,本文描述方法仅支持selenium 4.9.1的版本
此方法把chrome关键字指定为360急速浏览器,缺点是不能使用chrome和360急速同时进行测试
兼容方法如下
解决过程
robotframework调用driver实现过程
通过在IDE中编写测试类如下:
from Selenium2Library import Selenium2Library
se = Selenium2Library()
se.open_browser('http://www.baidu.com', '360chrome')
se.close_browser()
执行后找到robotframework调用driver实现过程如下
【注意:不同版本的文件位置不太一样,建议按照关键字browsermanagement确定文件位置】
- 在SeleniumLibrary\keywords\browsermanagement.py文件中执行 make_new_browser创建新的浏览器;
- make_new_browser 主要是返回了一个driver实例
- driver是在SeleniumLibrary\keywords\webdrivertools\webdrivertools.py中通过 create_driver实现 ,查看代码可以发现直接报错原因。
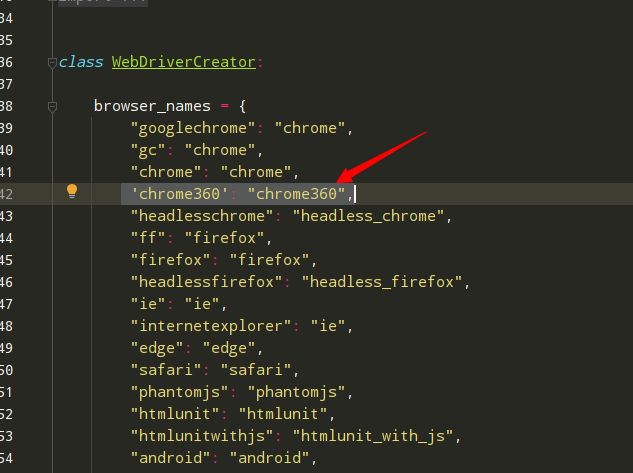
报错直接原因 : browser not in self.browser_names:
def _get_creator_method(self, browser):
if browser in self.browser_names:
return getattr(self, f"create_{self.browser_names[browser]}")
raise ValueError(f"{browser} is not a supported browser.")
需要在 self.browser_names增加关键字 'chrome360': "chrome360",如下图
4. create_driver 主要调用了两个方法 通过 _get_creator_method方法动态调用创建 driver
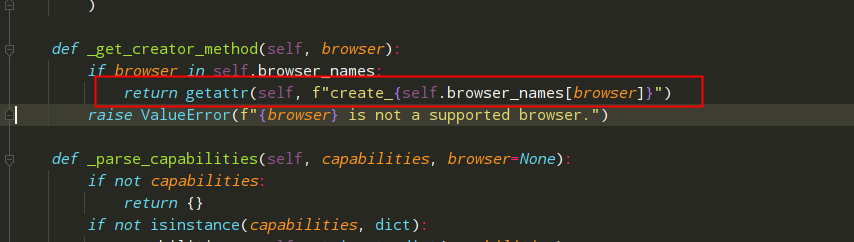
5. 所以需要根据chrome仿写方法
# 360兼容
def create_chrome360(
self,
desired_capabilities,
remote_url,
options=None,
service_log_path=None,
executable_path="chromedriver",
):
if remote_url:
defaul_caps = webdriver.DesiredCapabilities.CHROME360.copy()
desired_capabilities = self._remote_capabilities_resolver(
desired_capabilities, defaul_caps
)
return self._remote(desired_capabilities, remote_url, options=options)
if not executable_path:
executable_path = self._get_executable_path(webdriver.Chrome360)
return webdriver.Chrome360(
options=options,
service_log_path=service_log_path,
executable_path=executable_path,
**desired_capabilities,
)
def create_headless_chrome360(
self,
desired_capabilities,
remote_url,
options=None,
service_log_path=None,
executable_path="360chromedriver",
):
if not options:
options = webdriver.ChromeOptions()
options.headless = True
return self.create_chrome360(
desired_capabilities, remote_url, options, service_log_path, executable_path
)
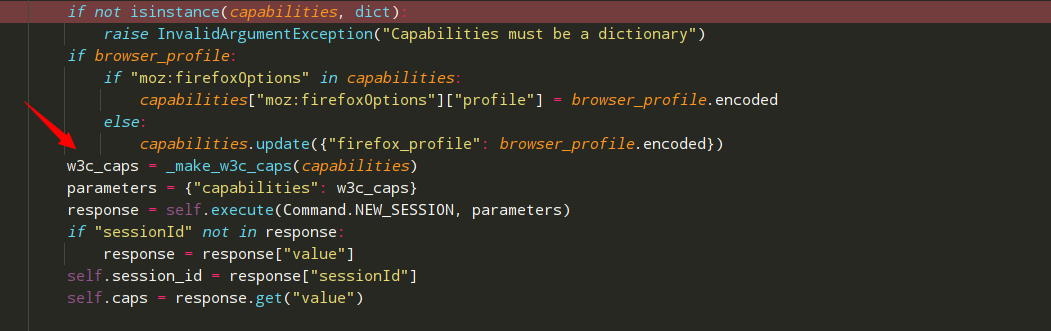
需要注意的是,因为selenium4.0过滤了不符合W3C结构的数据,所以在仿写时,不要修改从chrome包中复制的文件内容,本人自作聪明,修改了 DesiredCapabilities.CHROME变量,
导致selenium创建浏览器连接时直接报错。如图:

在这获取session时,过滤了非W3C结构的数据
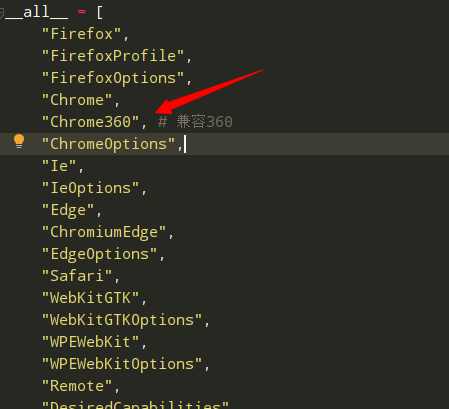
仿写后发现在 Webdriver中缺少方法Chrome360d的子类,再次仿照chrome生成一个Chrome360的python包,包含Chrome包中的所有文件
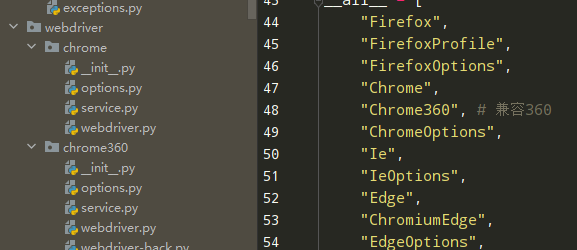
在 selenium.Webdriver 的init文件中增加引用
同时防止被过滤
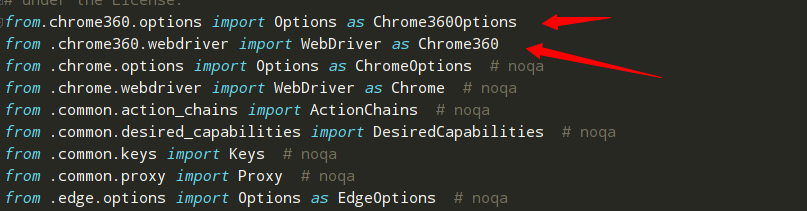
5.再次执行测试类,发现有参数报错TypeError: init() got an unexpected keyword argument ‘service_log_path’
在测试类中切换浏览器关键字,发现使用chrome浏览器依旧报错,由此可以确定是selenium版本存在问题,百度确定支持版本,详见 https://blog.csdn.net/weixin_45014379/article/details/131224717
降低版本至4.9.1
6.再次执行,发现测试类可以执行,但是打开的是chrome
打开浏览器是selenium中的功能,所以,这次我们需要在selenium中找到打开指定浏览器的方法
修改目标文件 selenium\webdriver\chromium\options.py 中 binary_location的方法,可以直接指定浏览器位置,为了更加通用,做了一个小小的优化,将浏览器地址放在了公共变量中,通过os.getenv方法动态获取
@property
def binary_location(self) -> str:
"""
:Returns: The location of the binary, otherwise an empty string
"""
# test
if "360" in str(self):
self.binary_location = os.getenv('Chrome360',"xxxxxxx") # 可以设置一个默认地址
return self._binary_location
如上解决问题

 浙公网安备 33010602011771号
浙公网安备 33010602011771号