第一次个人编程作业
https://github.com/Pollux-75/Software-Engineering/tree/master/031902415/1st_personal_programming
一、PSP表格
(2.1)在开始实现程序之前,在附录提供PSP表格记录下你估计将在程序的各个模块的开发上耗费的时间。(3')
(2.2)在你实现完程序之后,在附录提供的PSP表格记录下你在程序的各个模块的开发上实际花费的时间。(3')
C++版本:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 40 | 40 |
| Estimate | * 估计这个任务需要多少时间 | 40 | 40 |
| Development | 开发 | 990 | 1520 |
| Analysis | * 需求分析 (包括学习新技术) | 300 | 600 |
| Design Spec | * 生成设计文档 | 60 | 60 |
| Design Review | * 设计复审 | 60 | 60 |
| Coding Standard | * 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| Design | * 具体设计 | 60 | 60 |
| Coding | * 具体编码 | 300 | 900 |
| Code Review | * 代码复审 | 60 | 120 |
| Test | * 测试(自我测试,修改代码,提交修改) | 120 | 300 |
| Reporting | 报告 | 210 | 210 |
| Test Repor | * 测试报告 | 60 | 60 |
| Size Measurement | * 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | * 事后总结, 并提出过程改进计划 | 120 | 120 |
| * 合计 | 1240 | 2370 |
Python版本:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| Estimate | * 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 1510 | 1290 |
| Analysis | * 需求分析 (包括学习新技术) | 240 | 180 |
| Design Spec | * 生成设计文档 | 30 | 10 |
| Design Review | * 设计复审 | 30 | 10 |
| Coding Standard | * 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | * 具体设计 | 120 | 60 |
| Coding | * 具体编码 | 900 | 600 |
| Code Review | * 代码复审 | 60 | 120 |
| Test | * 测试(自我测试,修改代码,提交修改) | 120 | 300 |
| Reporting | 报告 | 180 | 120 |
| Test Repor | * 测试报告 | 60 | 60 |
| Size Measurement | * 计算工作量 | 60 | 30 |
| Postmortem & Process Improvement Plan | * 事后总结, 并提出过程改进计划 | 60 | 30 |
| * 合计 | 1700 | 1420 | |
二、计算模块接口
(分别用了C++和Python做了项目,C++是第一周做的,Python是第二周做的,辛苦审核大大了,球球多给点分)

先上第一周做的C++:
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18')
(3.1.1) 计算模块接口的设计:3个.cpp,2个类,n个函数:
sth_to_sth.cpp:
| 函数 | 解释 |
| :----: | :----: | :----: | :----: |
| UTF8ToGBK | UTF8转GBKd |
| GBKToUTF8 | GBK转UTF8 |
| int_to_char_to_string | int转string |
| ChineseConvertPy | 中文转拼音 |
file_io.cpp:
| 函数 | 解释 |
| :----: | :----: | :----: | :----: |
| open_file | 打开文件 |
| close_file | 关闭文件 |
main.cpp:
| 类 | 解释 |
| :----: | :----: | :----: | :----: |
| word | 用来储存和判断敏感词 |
| ans_word | 用来保存要输出的敏感词 |
| 序号 | 函数 | 解释 |
| :----: | :----: | :----: | :----: | :----: |
| ① | eng_sign | 判断英文符号 |
| ② | cn_sign | 判断中文符号 |
| ③ | put_full_pinyin_into_words_hash | 完整拼音识别 |
| ④ | put_head_pinyin_into_words_hash | 首字母拼音识别 |
| ⑤ | put_into_words_hash | 把单个敏感词放入words_hash以供之后查找判断 |
| ⑥ | get_words | 获得敏感词列表 |
| ⑦ | have_words | 从一句话下标i开始检测是否为敏感词 |
| ⑧ | deal_org | 对文本检测敏感词 |
| ⑨ | write_ans | 输出答案 |
(3.1.2)算法的关键:(流程图看后面)
程序的核心函数是⑤⑥⑦⑧:
其中 “ ⑤ 和 ⑥ ” 与 “ ⑦ 和 ⑧ ” 之间的关系基本一致,
都是“ 具体元素的处理方法 和 元素集合的处理方法 ”的关系
后者将频繁调用前者,来建立敏感词表或者在文本中查找敏感词
名词解释:
DFA,全称 Deterministic Finite Automaton 即确定有穷自动机:从一个状态通过一系列的事件转换到另一个状态,即 state -> event -> state。
确定:状态以及引起状态转换的事件都是可确定的,不存在“意外”。
有穷:状态以及事件的数量都是可穷举的。
其中⑤运用了DFA和链表的思想。用哈希表建立了敏感词搜索树。一部分拓展模块在这里安装:完整拼音识别、首字母拼音识别、部首识别等。
其中⑦运用了递推,在敏感词哈希表中找到对应的字母/汉字/部首则层层递推,直到遇到isEnd=1标志的一个敏感词的结束。然后记录相关数据,返回。一部分拓展模块在这里安装:干扰字符识别、谐音字识别、繁体字识别等。
对于迷惑性的字符则直接加入堆栈并跳过,如果最后敏感词判定成功则一同作为检测到的敏感词。否则清空堆栈。
(3.1.3)独到之处:
比较关键的要素就是DFA,哈希表,链表,还有对于拓展模块具体实现位置的安排:完整拼音识别、首字母拼音识别、部首识别等在读入实现,干扰字符识别、谐音字识别、繁体字识别等在判断实现
流程图


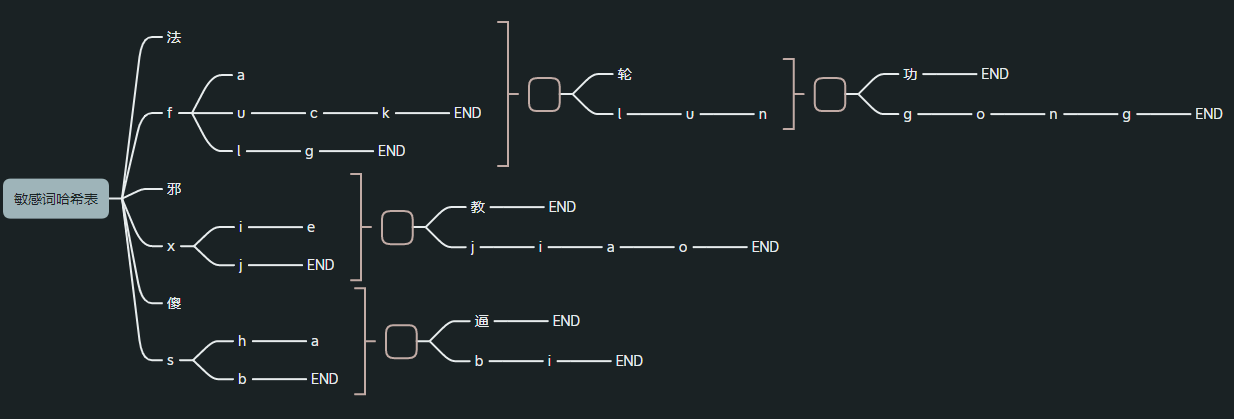
敏感词哈希表范例:
然后是第二周的Python:
还是DFA,但是进行了一定的改进
在C++版本中,我尝试构建一张 功能强大的敏感词查询表,能够应对直接对文本查询敏感词,但是这其中遇到一些问题:
以谐音敏感词为例,我不可能把原敏感词的所有谐音字都放到查询表里,所以判断的时候我肯定得对文本中的具体字再做分析,然后再去查表,从这个角度看,所谓“功能强大”的敏感词表似乎8太行。
在python版本中,这个“功能强大”的敏感词查询表又出了点问题:
python没有C++那样具体到指针/内存的操作(其实是我菜),
所以想要在查询表中进行上面C++那样的并列拓展存在难度。所以我想干脆放弃“功能强大”这个目标,
构建一张依据敏感词表得到的敏感词查询表(和上面“功能强大”不同,可以理解为最“朴素”的一张表),
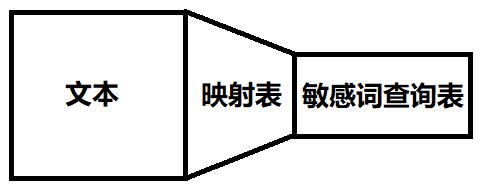
然后再构建一张映射表,在映射表上拓展拼音、部首之类的。也就是 详细的映射表 + 朴素的查询表
映射表其实就是个“转接器”
(3.1)计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。(18')
(3.1.1) 计算模块接口的设计:2个类,n个函数:
| 类 | 解释 |
| :----: | :----: | :----: | :----: |
| Stack | 栈 |
| DFA | DFA树的结点 |
一些简单的判断函数:
| 函数 | 解释 |
| :----: | :----: | :----: | :----: |
| is_chinese | 是否是中文 |
| homophonic | 是否在映射表中存在同音字 |
一些输入输出、初始化函数:
| 函数 | 解释 |
| :----: | :----: | :----: | :----: |
| read_file | 读文件 |
| write_file | 写文件 |
| do_some_initial | 搞点初始化 |
项目实现的主体函数:
| 函数 | 解释 |
| :----: | :----: | :----: | :----: |
| deal_words | 处理敏感词列表,得到敏感词查询表、敏感词映射表 |
| deal_org | 对文章检测敏感词 |
| find_word | 对句子检测敏感词 |
在敏感词映射表上添加的模块:
| 函数 | 解释 |
| :----: | :----: | :----: | :----: |
| add_full_pinyin_to_words_map | 添加 全拼音识别 |
| add_title_pinyin_to_words_map | 添加 首拼音识别 |
| add_tradition_to_words_map | 添加 繁体字识别 |
| add_side_split_to_words_map | 添加 拆分字识别 |
(同音字识别在find_word中实现)
(3.1.2)算法的关键:(请结合(3.1.3)食用)
- 算法基本上就是对C++版本的改进:
文本 -> 敏感词映射表 -> 敏感词查询表 -> 是否为敏感词
- 各种额外的识别模块在映射表中添加(除了同音字识别在遇到具体字时在映射表中查找)
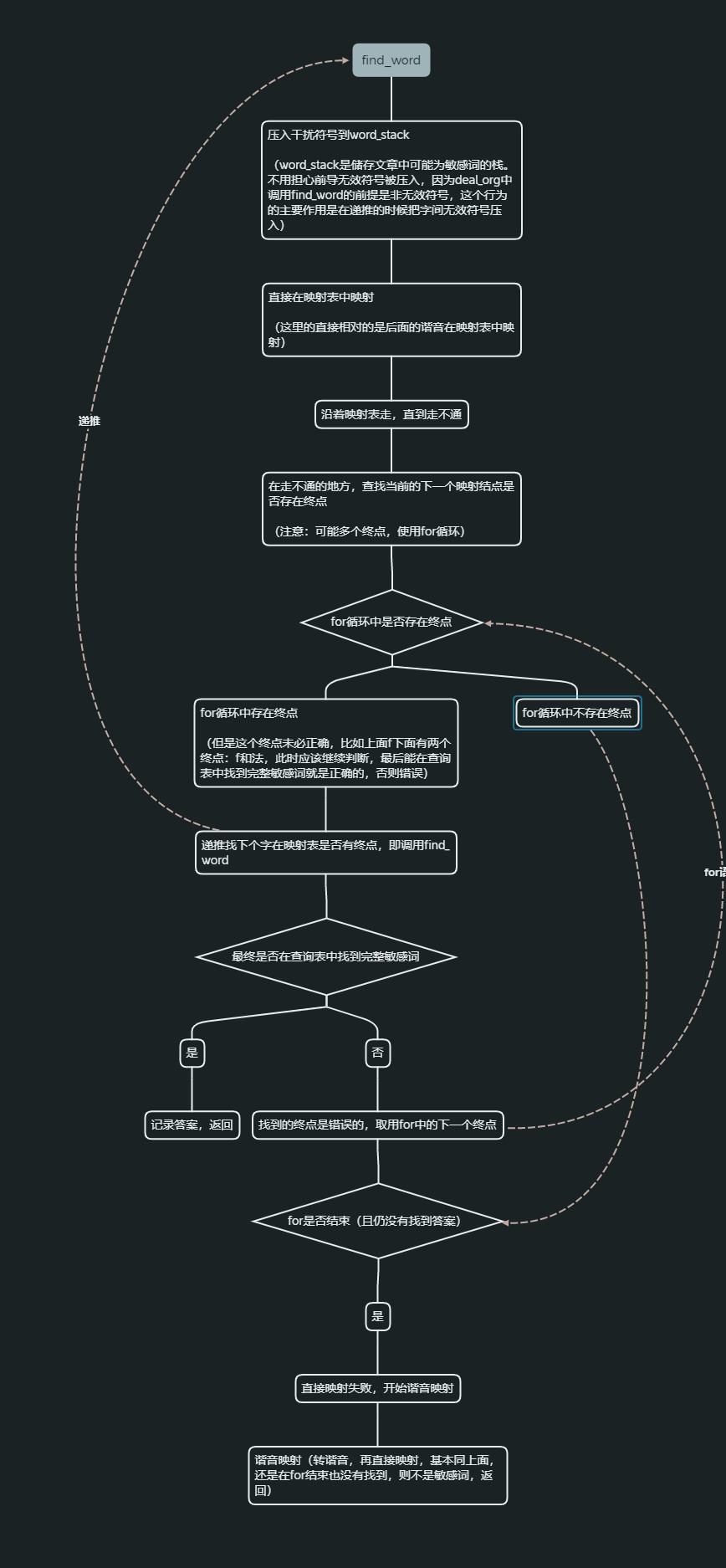
- 算法最关键的函数就是find_word了。要衔接 对文章的识别 和 对字的识别。164行代码,所有函数里最大的一个,本来想拆开的,但是传参麻烦就不拆了,进行了详细注释和分割:
find_word函数:
从sentence下标i开始,目标是找到整个敏感词
整个函数大体分两个部分:字本身的判断,字谐音的判断
算法具体内容请看下面
(3.1.3)独到之处:
相比于C++版本,无非是多了一个映射表,映射表中实现了除同音字识别外的所有识别,都是模块化的。至于同音字,在find_word中通过函数homophonic判断在映射表中是否有同音字。看图:

除了模块化映射表,独到之处大概就是find_word函数了
(详细过程建议配合代码注释食用,代码有详细注释)
(3.2)计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。(12')
性能分析图(使用的群里给的用例):
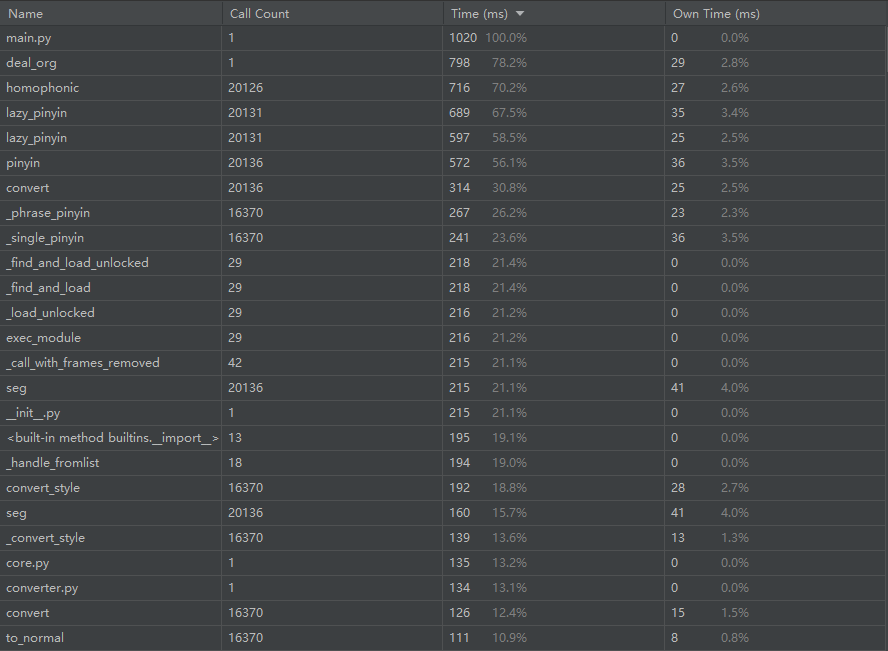
可以看到建表花了约22%的时间,剩下约78%在查表。比较让我意外的是检查有没有同音字的homophonic耗时竟然排在第三位,仅次于main和deal_org,尝试了加条件,在中文的时候才判断,不过效果不佳(大概因为英文敏感词并不多)

但是仔细想想似乎又在情理之中:对每个中文都要担心是不是谐音,确实挺花时间,但这部分判断又是必须的,目前没找到其它好方法。
不过其实仔细一看,homophonic的用时其实是被lazy_pinyin顶起来的,应该说本质上最花时间的是拼音相关的库,对每个字查拼音的行为占了大约70%的时间。不过知道自己几斤几两的我还是不去改大佬做的库了。
不得不说profile真是个好东西,短板瞬间暴露。不过我用的community没有profile,下了企业版才有……试用期30天难受
排名第一的main和第二的deal_org没有展示的必要,就展示homophonic,可以看到homophonic经常调用lazy_pinyin(用时第四位)
# 在敏感词映射表中是否存在同音字
def homophonic(single_word, now_map):
global homo
global homo_now_map
homo = False
single_word_pinyin = lazy_pinyin(single_word) # 转换全拼音
for i in single_word_pinyin[0]:
if i not in now_map.dict:
return homo
else:
now_map = now_map.dict[i]
for key in now_map.dict:
if now_map.dict[key].is_end:
homo = True
homo_now_map = now_map
return homo
return homo
(3.3)计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。(12')
部分单元测试代码:
class MyTestCase(unittest.TestCase):
def test_something(self):
right_ans = []
main.do_some_initial()
main.read_file()
main.deal_words()
main.deal_org()
self.assertEqual(main.ans, right_ans)
测试的函数:测试deal_org
构造测试数据的思路:
· 拆分字
· 繁体字
· 同音字
· 全拼字
· 首拼字
· 每种类型穿插无效字符
单元测试得到的测试覆盖率截图:
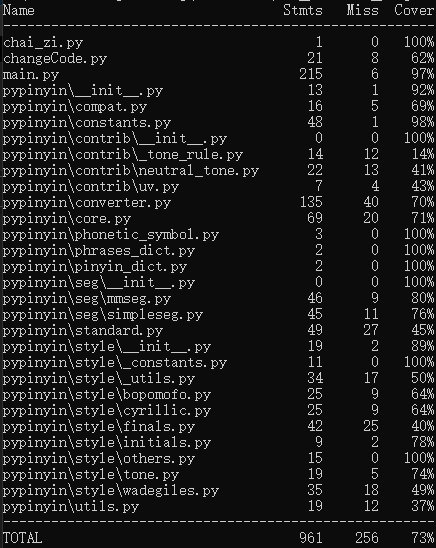
(3.4)计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。(6')
找不到文件的时候接住抛出的异常,并在控制台说明
try:
file_in_words = open(sys.argv[1], 'r', encoding='utf-8')
file_in_org = open(sys.argv[2], 'r', encoding='utf-8')
file_out_ans = open(sys.argv[3], 'w', encoding='utf-8')
except FileNotFoundError:
print("发生异常:找不到文件!")
三、心得
(4.1)在完成本次作业过程的心得体会(3')
第一周:
属于是被毒打了。
本来有点想法,也感觉这个作业自己应该能一步步完成。
接着就在逐步实现的过程中被各种问题来回折腾,马马虎虎地实现最最基本的检测功能。
但是花了巨多的时间(甚至用掉了本来就不多的应该花在其他地方学习的时间),但是最终完成的事情并不多。
真正绷不住的地方是找API。在github上找趁手的API的时候,Java搜出来70+个,Python搜出来50+,C++搜出来只有11个,而且都是没啥热度的。当时真的蚌埠住了,甚至有“换语言算了”的想法。
However,人不行不能怪路不平。现在的问题是怎么从中吸取教训:
- 应该进一步规划时间。不能盲目地投入时间否则反而效率低下并且占用其它事情的时间;
- 建立代码规范。项目开始的时候并没有参考大厂的代码规范,而是按自己向来的习惯来写,这对于团队项目肯定是不好的;
- 锻炼寻找,使用API的能力,避免重新造轮子;
第二周:
有时候路不平确实会导致人不行
(Python真的绝绝子)
这是我写的第一个Python项目,但是花的精力甚至不到C++的一半……当场蚌埠住了我一星期前在干嘛我为什么要抱着C++不放我浪费了多少时间

C++版本的反思在Python版基本都有实现。
- Python开发时在时间方面比较吝啬,注重效率;
- 代码规范没有完全按照Python PEP8来,但是也不至于太乱;
- 对于Python来说API找起来确实比C++容易;
另外也学习了性能分析工具,了解到了单元测试,这几个功能以后要多用起来
算法方面还不够优化,还要多学习高效算法

 浙公网安备 33010602011771号
浙公网安备 33010602011771号