
强化学习在LLM上的部分应用
偏好学习:向人类的对齐
- LLM需要学习到人类的偏好,提供人类更喜欢的输出
- 没有一个明确的指标可以用于计算“一段输出是否足够好”
- 人类现场标注不可能跟得上LLM的优化节奏
奖励模型Reward Model
- 收集人类的偏好对
- 根据偏好对输入同一个网络的分差与实际分差作为loss
- 训练得到一个能模拟人类喜欢的reward model
Proximal Policy Optimization on RLHF
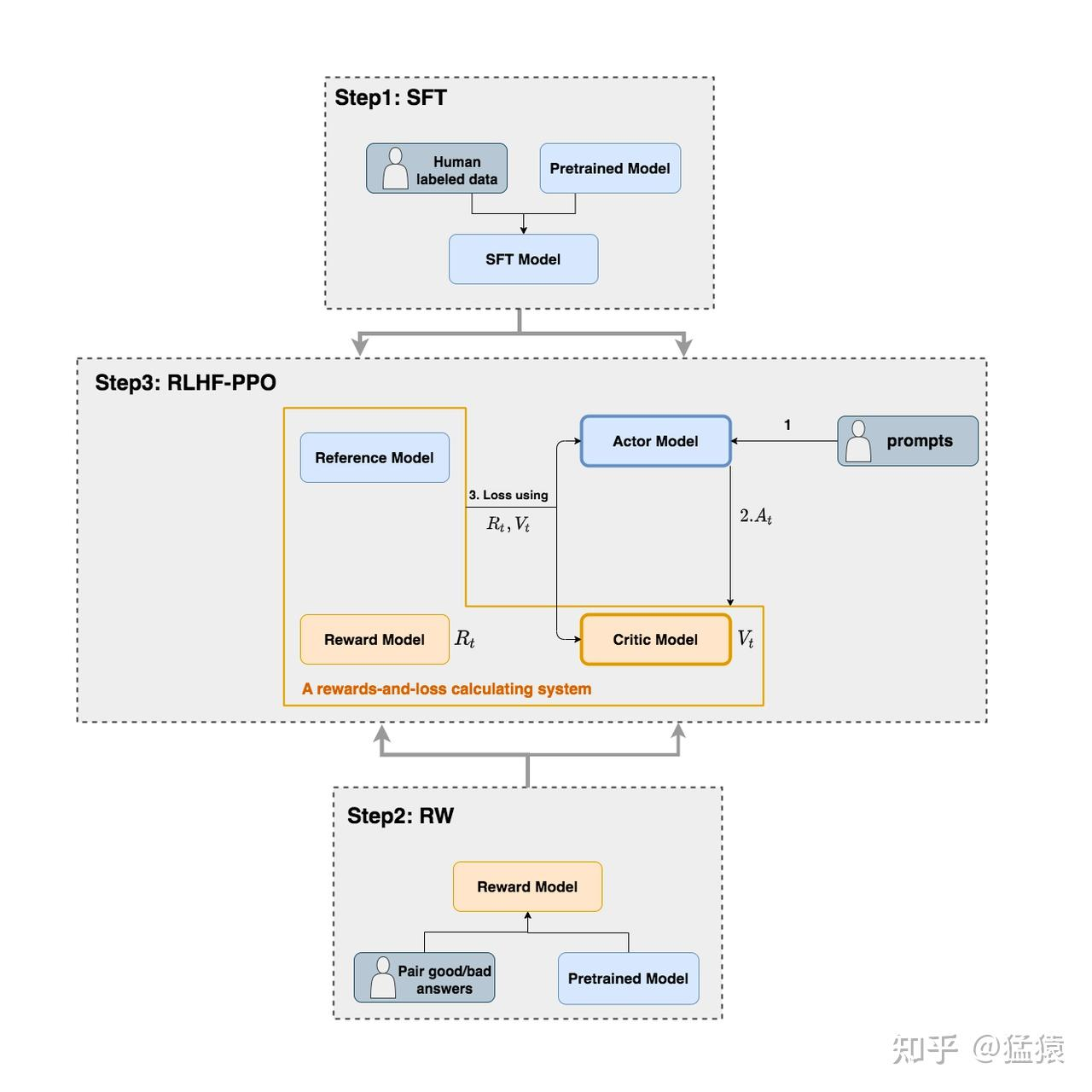
Stage 1:SFT
Stage 2:Reward model
Stage 3:RLHF-PPO
![image]()
- Actor model:待对齐的目标模型,参数可训练,由SFT model初始化
- Reference model:参考模型防止训练走偏太多,参数冻结,也由SFT model初始化
- reward model:用偏好对训练的RW,参数冻结,提供“生成当前token的奖励R”
- Critic model:预测“直至生成结束的总计奖励V”,可训练参数
Loss:Actor loss与critic loss
- actor loss:
- 如果当前输出对应的总奖励>0,则强化输出当前输出的概率
- 计算actor输出token的对数概率分布与ref的差(即二者分布的kl散度),来判断输出是否偏离ref
- critic收益:
- 预估收益:Vt
- 实际收益:Rt+V(t+1)
- 两者限制范围后做类似MSELoss
过程
- Actor拿到一个batch的数据,输出回复
- 输入+回复一起给其他三个模型,生成RL的各个部分,用于计算两个loss
- 计算loss并更新两个待训练模型
DPO:Direct Preference Optimization
- PPO等方法要训练一个reward model
- DPO直接通过对loss的数学推导,把基于reward的梯度变成了基于Policy的梯度
- 相当于直接在Policy上“记住”偏好
- 数学推导我是真看不懂
GRPO:Group Relative Policy Optimization
- 出发点:数学任务(多步依赖、部分正确、奖励集中),RM难以建模
- 操作方法:对于一个prompt生成多个response,构成一个group
- 组内利用奖励值计算标准化优势与排名优势,加权得到最终优势
- 目标是最大化所有组的平均最终优势,其余处理和PPO基本一致
posted @
2025-05-22 01:04
Phile-matology
阅读(
49)
评论()
收藏
举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号