微调(Finetuning)
- 用比训练时小得多的数据量,试图通过较短的训练,提高模型在某个特定场景或者任务上的能力。
- 最基础的思路是全参数微调,空间开销和预训练完全相同,只是由于数据量等原因,耗时更短
- 为了降低要求,扩大使用范围(消费级硬件),省空间的微调方法不断被提出
PEFT:Parameter Efficient Finetuning
- 致力于在尽可能保持模型效果/微调效果的前提下,减小微调空间开销。
- 微调空间占用包括:
- 模型参数
- 优化器(动量、二阶动量)
- 激活向量(中间结果)
- 梯度
BitFit:只学习各线性层的bias
- qkv一般是线性层实现,学习给其加一个bias
- 后续ffn中线性层的bias
Adapter Tuning:加入带残差连接的模块,来附加“仅为任务设计的偏置”
![image]()
- 引入模块:下采样+非线性层+上采样+残差连接
- 优点:保留模型通用性,易于扩展
- 缺点:引入额外推理延迟,只能串行(模块内部?)
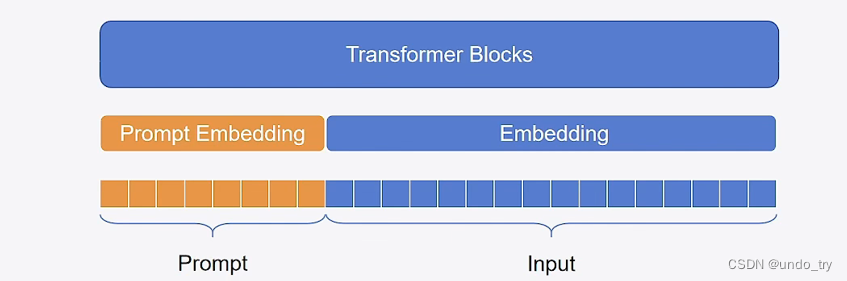
Prompt Tuning:在输入前额外一段Prompt,训练该Prompt的表示并拼接到输入embedding上
![image]()
- 可学习参数:一个Embedding层
- 优点:完全冻结模型原有参数
- 缺点:占用context length,且依赖模型自身能力,很难训练
Prefix-tuning:输入前拼接一段可训练前缀(virtual tokens)
![image]()
- 相比加入的离散的Prompt,调整空间更大,更好训练
- 加入了一个MLP做映射
- 调整了Transformer的每一层(不止Embedding层前面)
P-tuning:
- P-tuning V1:Prompt tuning的改进,用Embedding+MLP/LSTM来替代原有的Embedding
- P-tuning V2:在Prefix-tuning的基础上,删掉了MLP/LSTM的重参数化映射,并根据任务灵活调整长度
posted @
2025-05-20 18:41
Phile-matology
阅读(
47)
评论()
收藏
举报




 浙公网安备 33010602011771号
浙公网安备 33010602011771号