
补全llm知识体系的地基:LoRA
LoRA:low rank adaptation低秩分解
- 启发点:越大的模型参数矩阵,越可能具有很小的Intrinsic dimension,即只需要调整其一部分参数就能有效影响其在特定输入上的输出
- \(W_0 = W + AB\),假设W的维度是d * k,则A是dr,B是rk,r可以远小于d和k,这样就节省了大量用于存储原本的\(\delta W\)的空间
- 微调时,直接用W + AB来替代W进行计算,反向传播时冻结W,只训练AB
![image]()
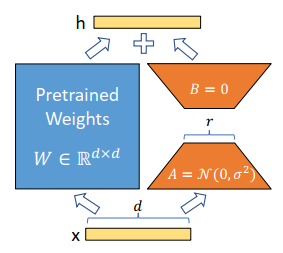
LoRA在微调Transformer时的特性
- 要尽可能把有限的参数空间(准确来说,秩,即前述r),分散到不同的参数矩阵上。在一个Transformer模块中,以分配给q、v为佳
![image]()
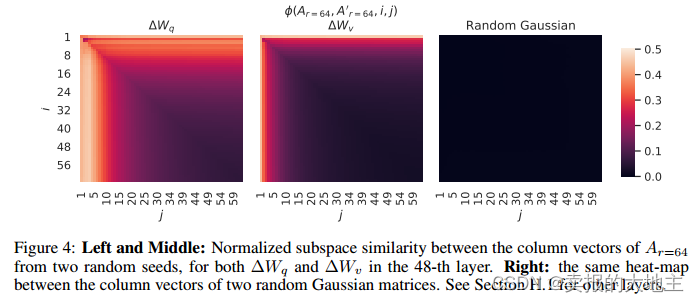
- 很大的r不能提高效果,同样设定下r=8的奇异向量占据了r=64的头部,证明实际的Intrinsic dimension可能更小
- 参数更新AB和原参数W的关系:
- 参数更新部分和W更为相似(对比随机向量),证明微调是在放大部分维度
- 相似的部分并不是权重中的头部奇异向量,证明调整的不是重要能力,而是与任务密切相关的能力
- 被微调的相似部分,放大倍数非常大(20倍以上)
![image]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号