Logistic回归明明称呼为回归但为什么是分类算法?
什么是“回归”?
回归分析就是用来探寻变量之间的关系的过程。百度百科给出的定义是:“(统计学中的)回归分析(Regression Analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法”。
例如,为分析气温和冰淇淋的销量之间的关系,我们用随机变量 表示气温、随机变量
表示冰淇淋的销量;我们假定二者之间存在某种定量的关系:
回归分析就是为了确定函数 的表达形式。如果我们继续假定
和
之间的关系是一种简单的线性关系,则
可以表示为:
其中 表示截距,
表示直线的斜率,
是误差项。通过对随机变量
、
进行观测、采集一定量的样本
,我们就可以利用最小二乘法估计出参数
、
的值——这个过程就是回归分析。
咬文嚼字之——回归
“回归”在日常用语中是一个动词,比如“回归自然”、“回归自我”。统计中的“回归”也可以理解成一个动词。
我们对两个变量 和
在总体(整个样本空间)中的关系进行猜测,假设二者之间的真实关系满足
;将其画在图上就是一条截距为
、斜率为
的直线。
然后我们每次从总体中抽取一组样本,利用最小二乘法就可以得到参数 、
的估计值
、
。估计值
、
一般非常接近真实值
、
,但不与之完全重合。如果抽样足够随机,样本量也足够大,参数的估计值
、
就不断地向真实值
、
靠拢。这个过程就可以看作是一种“回归”,是参数的“估计值”向其“真实值”的回归。
什么是“分类”?
分类也是一种回归。分类模型的目的也是为了探寻自变量和因变量之间的相互关系,只不过在分类模型中因变量是“离散的”。在上面的例子中,冰淇淋的销量 是一个连续变量;如果我们定义
表示销量较高、
表示销量较低,那上面的回归模型就会变成一个分类模型。再比如,如果要预测房价,如果我们将房价看成是一个连续变量,这就是一个回归问题;但是如果将房价
2万/平米划分到“高”的那一类,
万/平米划分到“中”的那一类,低于1万/平米划分到“低”的那一类,那么我们就把一个回归问题转化成一个分类问题。
回到问题本身
回到最初的那个问题——
Logistic回归明明称呼为回归但为什么是分类算法?
Logistic模型是一个回归模型,也可以用作分类。在二项Logit模型中,决策者 n 选择方案 i 的概率 是一个范围在[0,1]之间的连续变量(
的推导过程可以参见《你们要的二项Logit模型在这里——离散选择模型之八》一文)。根据上面的回归的定义可知,此时因变量
对应的二项Logit就是一个回归模型;假设我们用0.5作为分割阈值、并定义一个新的离散型随机变量
,规定:
时,n 选择方案 i,记为
时,n 选择方案 j,记为
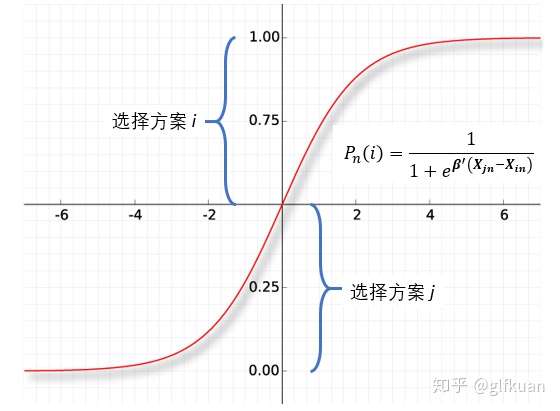 Fig 2
Fig 2
此时从变量 的角度看,Logistic模型便是一个分类算法。
原文:https://zhuanlan.zhihu.com/p/82927255

 浙公网安备 33010602011771号
浙公网安备 33010602011771号