


Mysql
![]() 索引
索引
 索引
索引
索引是帮助MySQL高效获取数据的排好序的数据结构
![]() 索引数据结构
索引数据结构
 索引数据结构
索引数据结构二叉树
红黑树
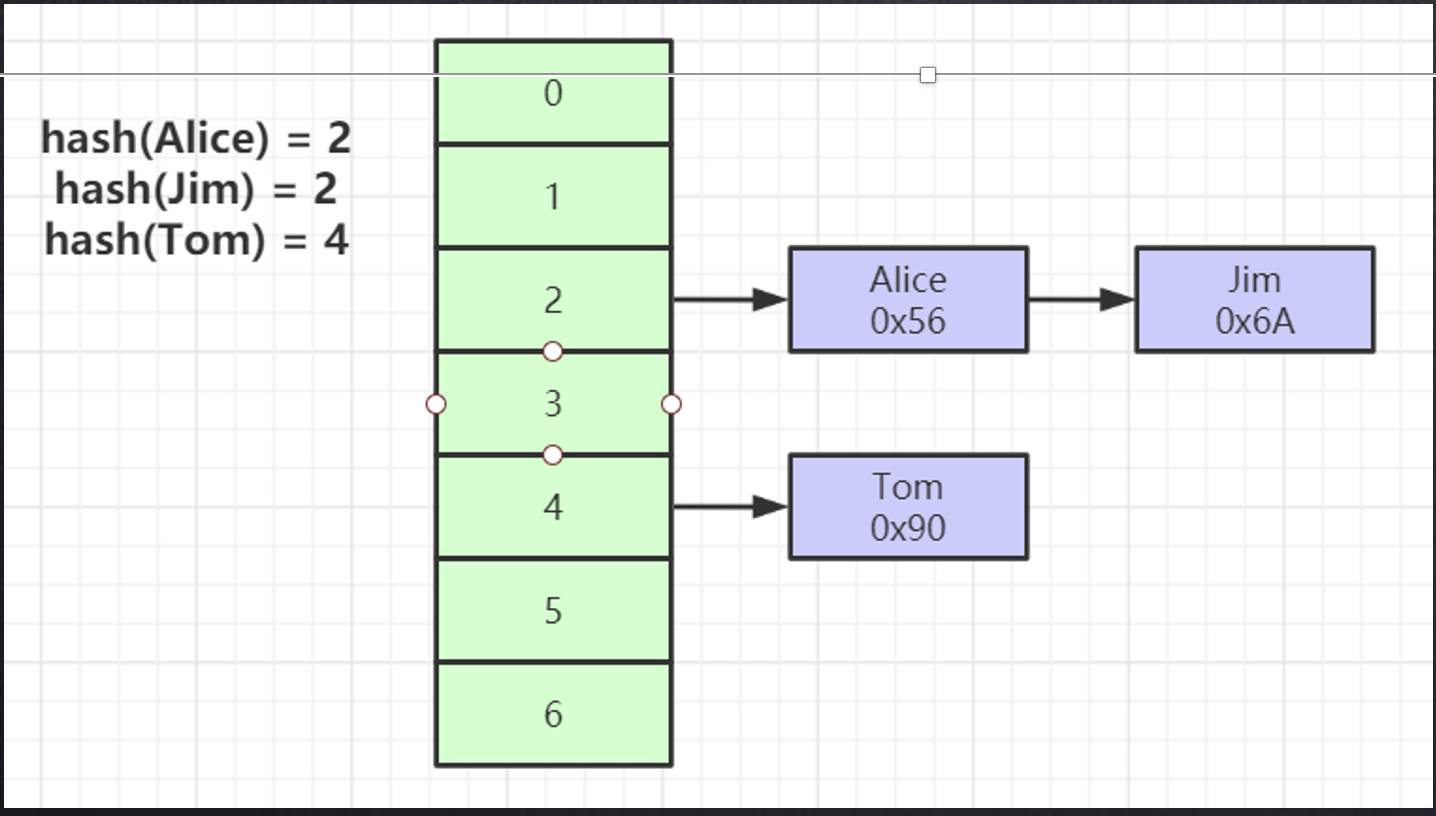
Hash表
对索引的key进行一次hash计算就可以定位出数据存储的位置
很多时候Hash索引要比B+ 树索引更高效
仅能满足 “=”,“IN”,不支持范围查询
hash冲突问题
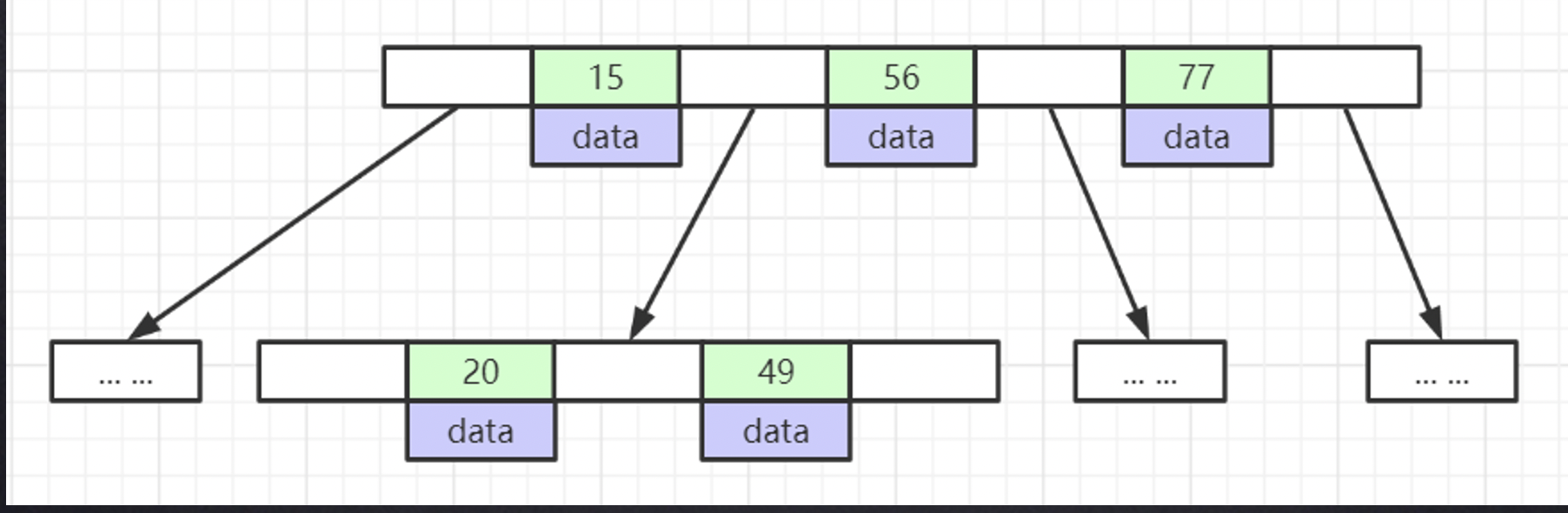
B-Tree

-
叶节点具有相同的深度,叶节点的指针为空,所以对区间查询不太友好;
- 所有索引元素不重复
-
节点中的数据索引从左到右递增排列
- 所有的节点都存粗数据和索引
B+Tree
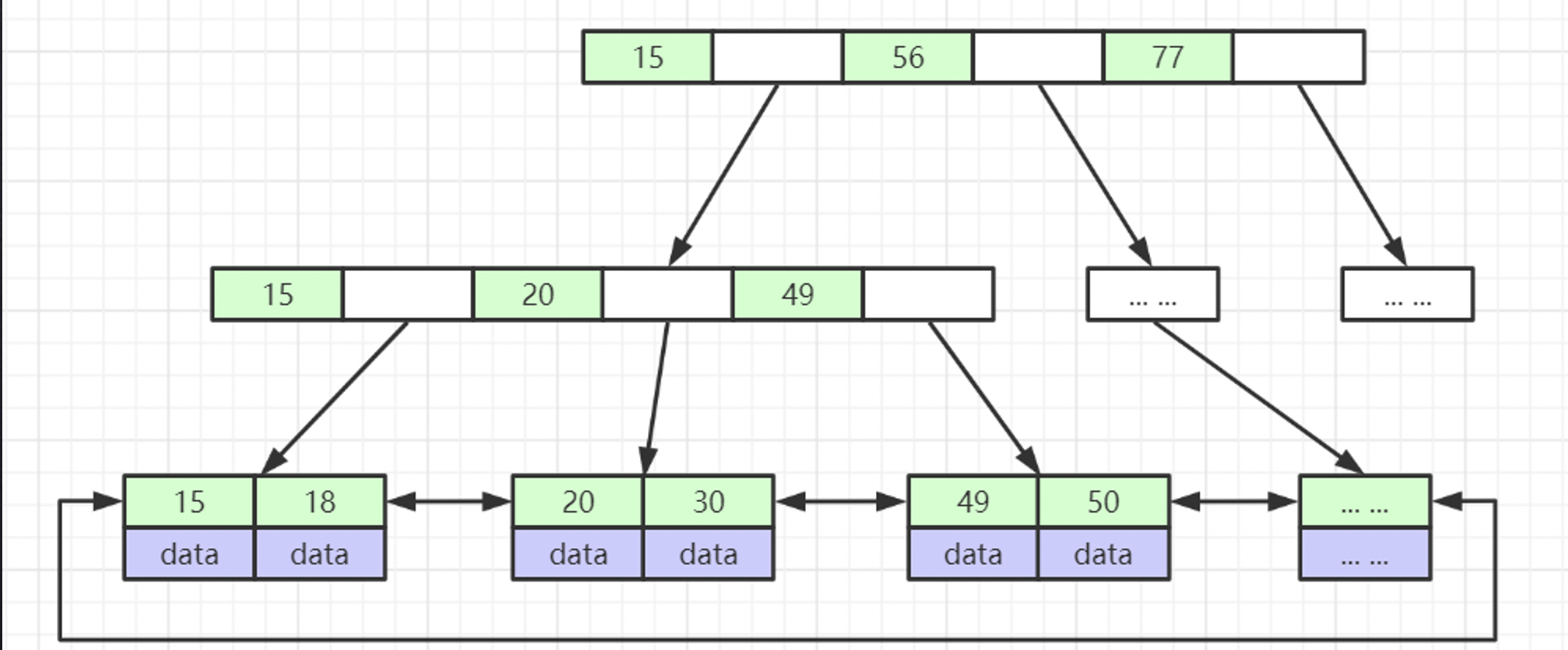
- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引
- 叶子节点包含所有索引字段
- 叶子节点用指针连接,提高区间访问的性能
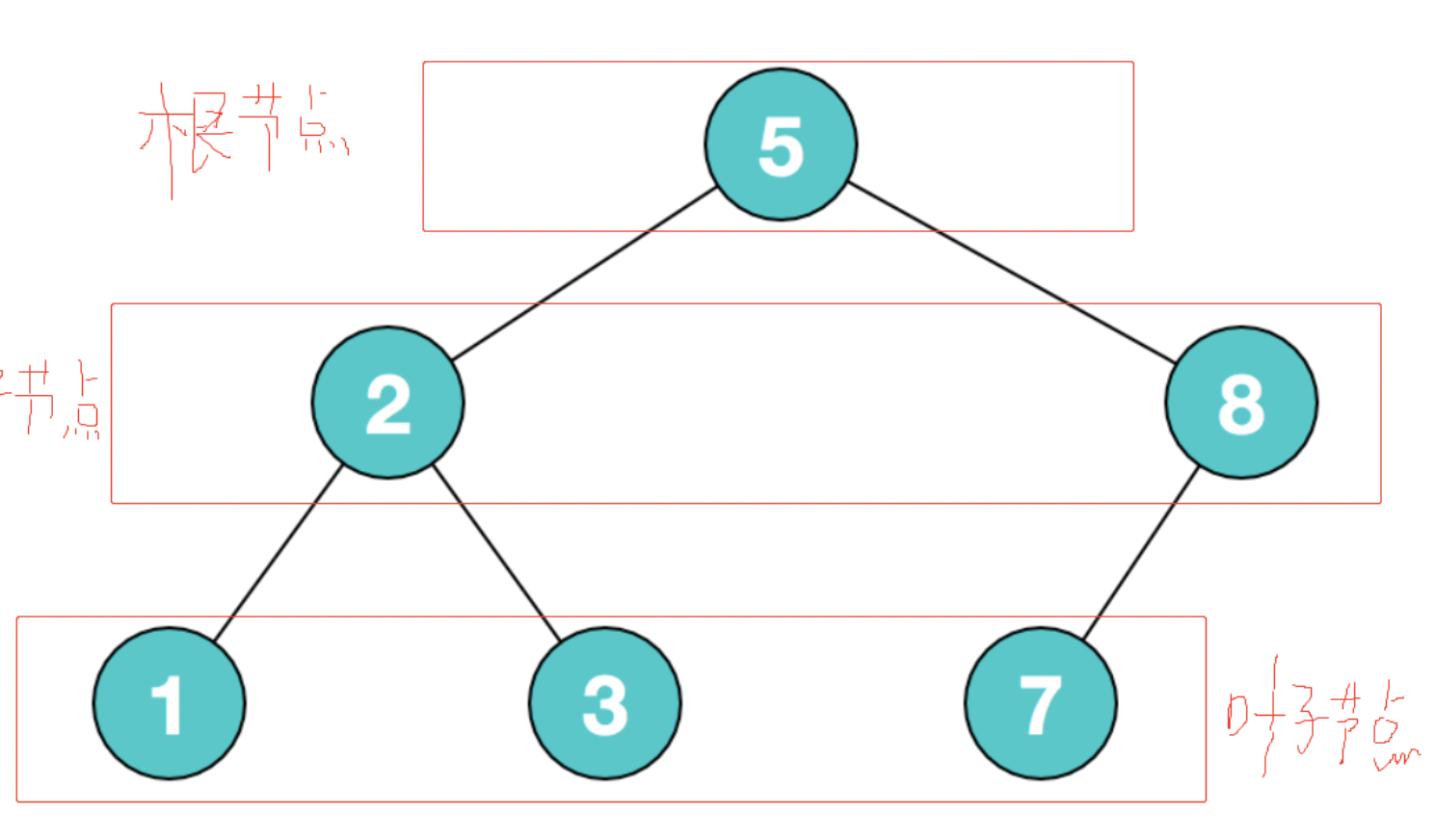
根节点、子节点、叶子节点是什么?
B+tree的IO次数
索引文件和数据文件都在磁盘上存储,每次查询时,首先把索引文件从磁盘中加载到内存中进行查询比较,每次加载是按页进行加载的,每页可存储的数据时16kb,大部分资源耗费在IO操作上了,所以要尽可能的每页上多
放数据,减少IO次数;(Innodb 甚至可能把一二级索引都放在内存中,如果深度为3时,只需要进行一次IO操作就可以了)
Mysql 页的理解
MyISAM索引文件和数据文件是分离的(非聚集)
数据结构也采用的是B+tree;
叶子节点存储的数据的地址,所以最后获取数据时,还需要进行一次IO操作,根据地址,从磁盘中再加载一次
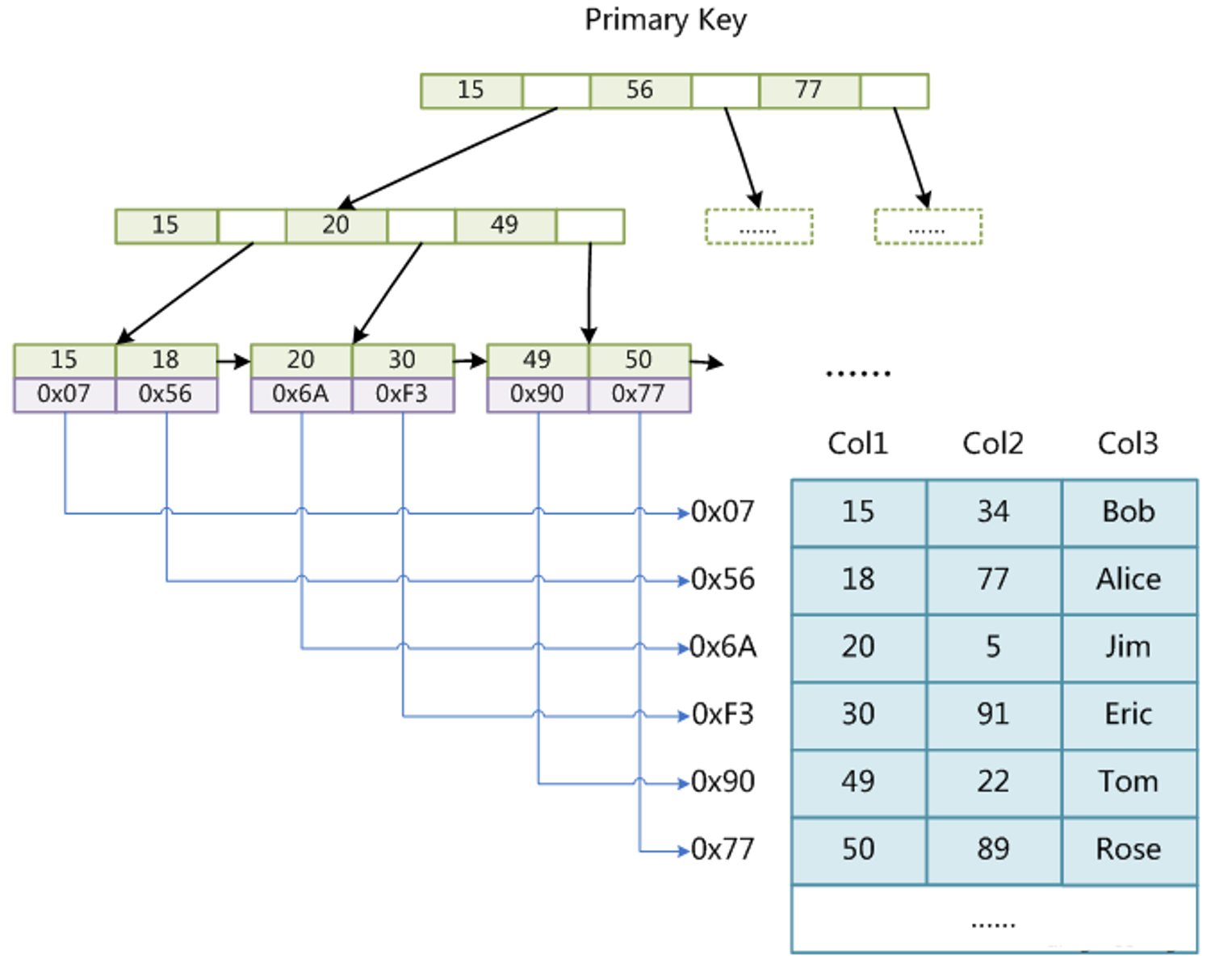
InnoDB索引实现(聚集索引)
1、表数据文件本身就是按B+Tree组织的一个索引结构文件
2、聚集索引-叶节点包含了完整的数据记录
3、为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
-
如果设置了主键,那么InnoDB会选择主键作为聚集索引、如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引、如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作 为隐含的聚集索引(ROWID随着行记录的写入而主键递增)
- 使用整型,一方面是为了节省空间,另一方面是为了更快的进行比较(1<2要比hello和heyy比较的快)
-
如果表使用自增主键那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,主键的顺序按照数据记录的插入顺序排列,自动有序。当一页写满,就会自动开辟一个新的页
-
如果使用非自增主键(如果身份证号或学号等)由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置,此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面什么

4、非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
减少了出现行移动或者数据页分裂时二级索引的维护工作(当数据需要更新的时候,二级索引不需要修改,只需要修改聚簇索引,一个表只能有一个聚簇索引,其他的都是二级索引,这样只需要修改聚簇索引就可以了,不需要重新构建二级索引);
一致性:假如所有的索引都要存储数据时,当数据行发生变化时,所有的索引都需要重新修改和构建,这样做减少了构建成本,也避免了同步修改不及时的数据不一致;
节省存储空间:二级索引只存储一级索引的主键,节省了大量的存储空间;
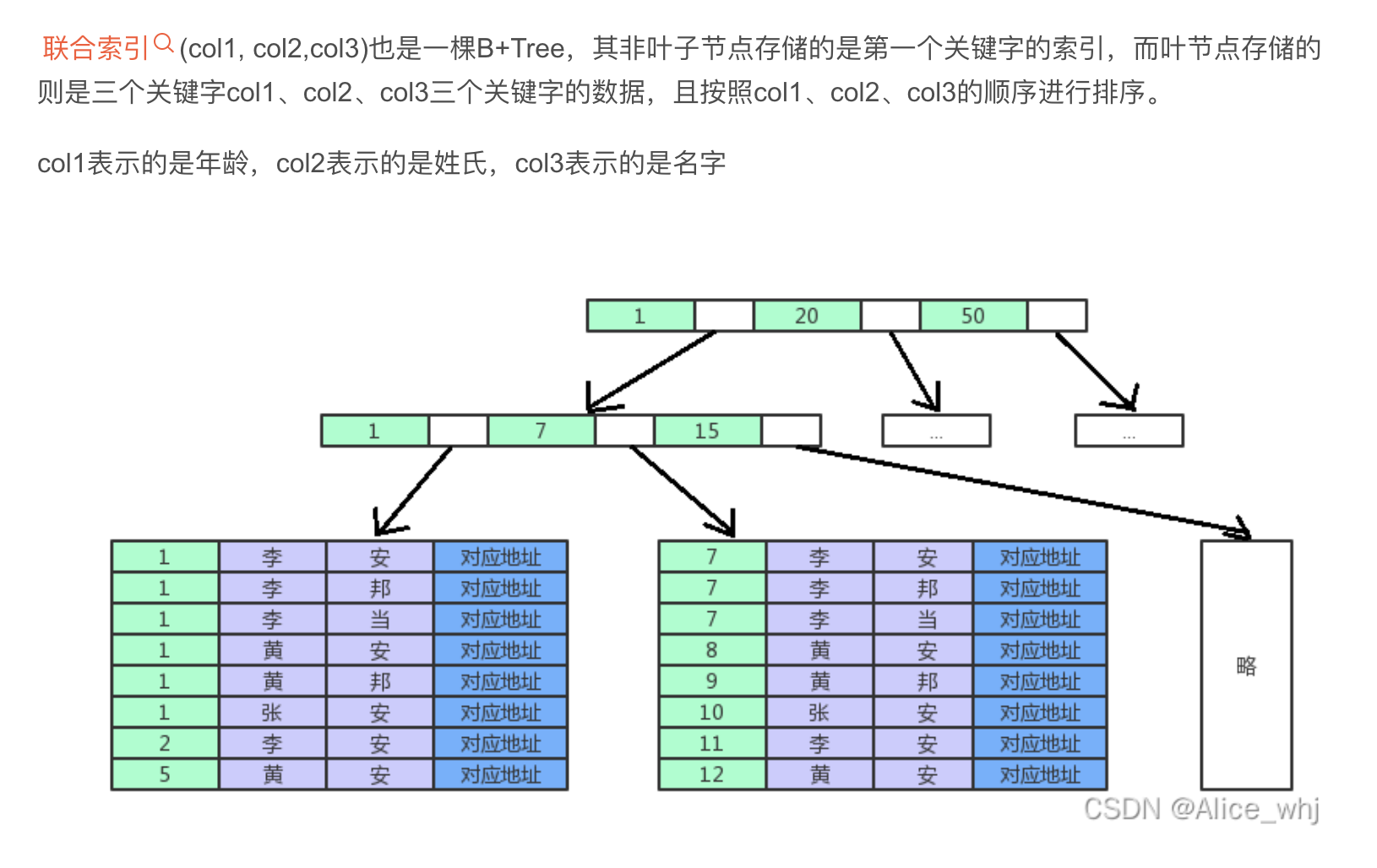
联合索引的底层存储结构长什么样?
联合索引遵循最左匹配原则,按照顺序,以最左边的顺序开始比较建立索引;
当查询age=30 and position=dev的时候索引不生效,因为构建索引是先比较的name,name相同再比较age,age相同再比较positon,所以只有age,在索引中是无序的,如下图;
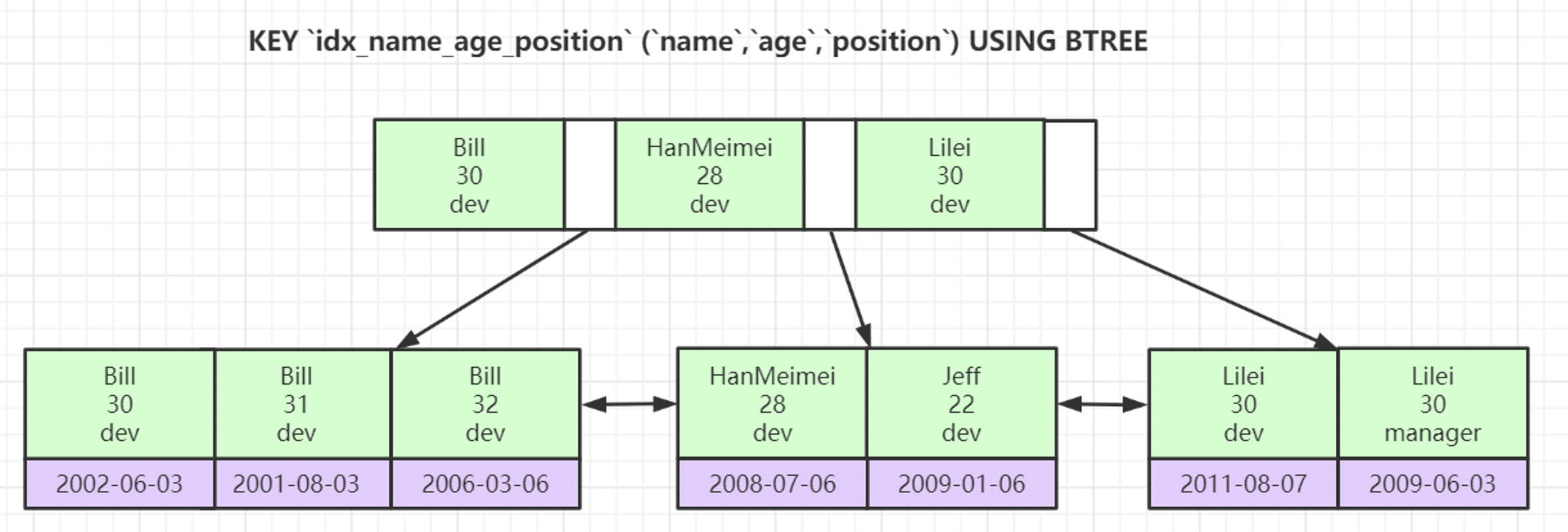
数据库联合索引失效
https://blog.csdn.net/Alice_whj/article/details/122794075
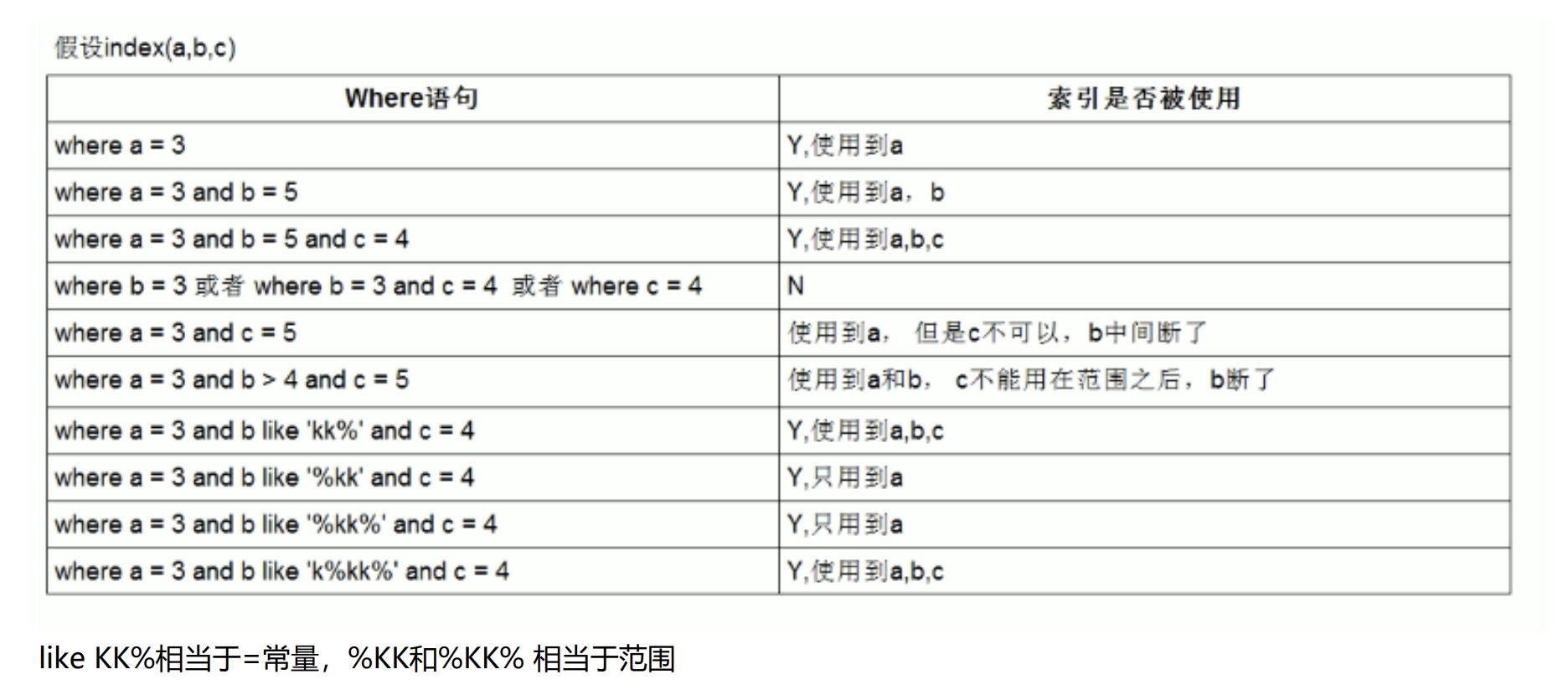
like KK%其实就是用到了索引下推优化
对于辅助的联合索引(name,age,position),正常情况按照最左前缀原则,SELECT * FROM employees WHERE name like 'LiLei%' AND age = 22 AND position ='manager' 这种情况只会走name字段索引,因为根据name字段过滤完,得到的索引行里的age和position是无序的,无法很好的利用索引。
在MySQL5.6之前的版本,这个查询只能在联合索引里匹配到名字是 'LiLei' 开头的索引,然后拿这些索引对应的主键逐个回表,到主键索引上找出相应的记录,再比对age和position这两个字段的值是否符合。
MySQL 5.6引入了索引下推优化,可以在索引遍历过程中,对索引中包含的所有字段先做判断,过滤掉不符合条件的记录之后再回表,可以有效的减少回表次数。使用了索引下推优化后,上面那个查询在联合索引里匹配到名字是 'LiLei' 开头的索引之后,同时还会在索引里过滤age和position这两个字段,拿着过滤完剩下的索引对应的主键id再回表查整行数据。
索引下推会减少回表次数,对于innodb引擎的表索引下推只能用于二级索引,innodb的主键索引(聚簇索引)树叶子节点上保存的是全行数据,所以这个时候索引下推并不会起到减少查询全行数据的效果。
为什么范围查找Mysql没有用索引下推优化?
估计应该是Mysql认为范围查找过滤的结果集过大,like KK% 在绝大多数情况来看,过滤后的结果集比较小,所以这里Mysql选择给 like KK% 用了索引下推优化,当然这也不是绝对的,有时like KK% 也不一定就会走索引下推 ,具体还要看MySQL分析各个索引使用成本,找出最优访问路径。




 浙公网安备 33010602011771号
浙公网安备 33010602011771号