


Redis相关知识
redis的持久化方式
1.rdb快照----持久化数据
redis 根据设置每隔一段时间进行持久化(60 秒内有至少有 1000 个键被改动)
save持久化:同步
bgsave持久化:异步
bgsave的cow(写时复制的机制)机制:bgsave异步复制主要是主线程fork生成一个子线程,当进行持久话写入rdb文件时,主线程还可以进行写的操作(读的操作无影响),此时写的这块数据会被复制一份,bgsave子线程会吧这个副本数据写入rdb文件中,而这个过程中,主线程仍可以对原来数据直接进行修改。
2.aof----对操作命令进行持久化
通过设置对redis的每次写操作命令进行保存。
appendfsync always:每次有新命令追加到 AOF 文件时就执行一次 fsync ,非常慢,也非常安全。
appendfsync everysec:每秒 fsync 一次,足够快,并且在故障时只会丢失 1 秒钟的数据。appendfsync no:从不 fsync ,将数据交给操作系统来处理。更快,也更不安全的选择。
3.aof重写:
![]()
对aof的命令进行合并,比如每次incr 1,连续5次,aof会记录5次,会造成文件比较大,命令特别多,进行恢复时比较慢。重写合并后可以直接为set 5,减少aof文件的大小,和aof的数据恢复速度。
aof重写频率可以进行配置
auto‐aof‐rewrite‐min‐size 64mb //aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就很快,重写的意义不大
auto‐aof‐rewrite‐percentage 100 //aof文件自上一次重写后文件大小增长了100%则再次触发重写
auto‐aof‐rewrite‐percentage 100 //aof文件自上一次重写后文件大小增长了100%则再次触发重写
4. rdb和aof区别
生产环境可以都启用,redis启动时如果既有rdb文件又有aof文件则优先选择aof文件恢复数据,因为aof一般来说数据更全一点
1)rdb恢复数据较快,但易造成数据的丢失,aof数据恢复慢,但比较安全
2)rdb文件较小 aof由于记录的是每个操作命令,文件较大
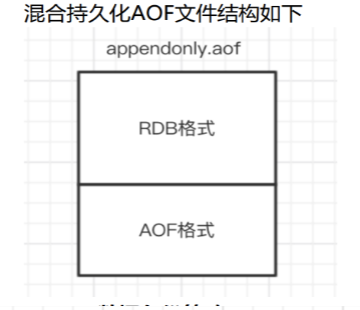
5. redis 4.0之后采用的混合持久化的方式--由于是基于aof的,所以必须开启aof
aof进行重写时,AOF在重写时,不再是单纯将内存数据转换为RESP命令写入AOF文件,而是将重写这一刻之前的内存做RDB快照处理,并且将RDB快照内容和增量的AOF修改内存数据的命令存在一起,都写入新的AOF文件,
重写完成覆盖原来的aof文件。
redis进行重启时,先加载rdb中的内容,然后再加载增量的aof日志
6. redis数据的备份的策略
1)用crontab定时调度脚本,每小时,将aof和rdb文件copy的一个目录中,仅仅保留最近48h 的备份
2)每天都保留一份当日的数据到其他目录中去,可保留一个月
3)删除太久的数据
4)每天将当日的备份数据同步到其他机器上,防止机器事故,导致数据丢失。
redis的管道命令
redis可以通过pipeline管道,打包同时执行多条命令,命令也不是越多越好;这些命令不是原子性的,一条命令失败后,后续的其他命令也是可以执行成功的。
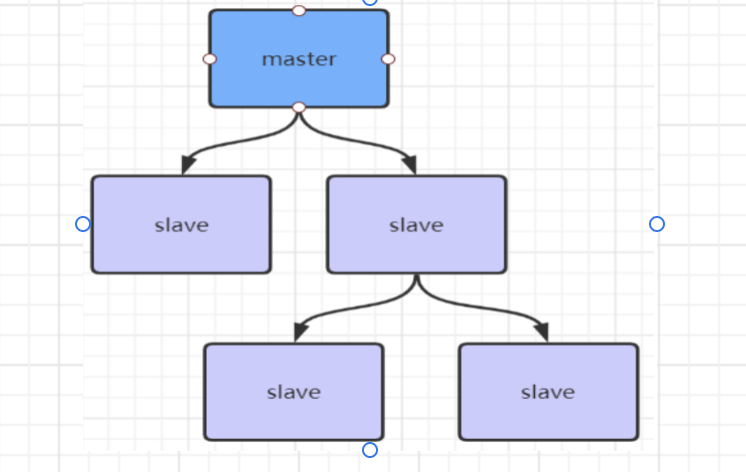
redis的主从复制风暴
redis的很多从节点到主节点同时同步数据
可以用以下方式解决:
Redis哨兵高可用架构
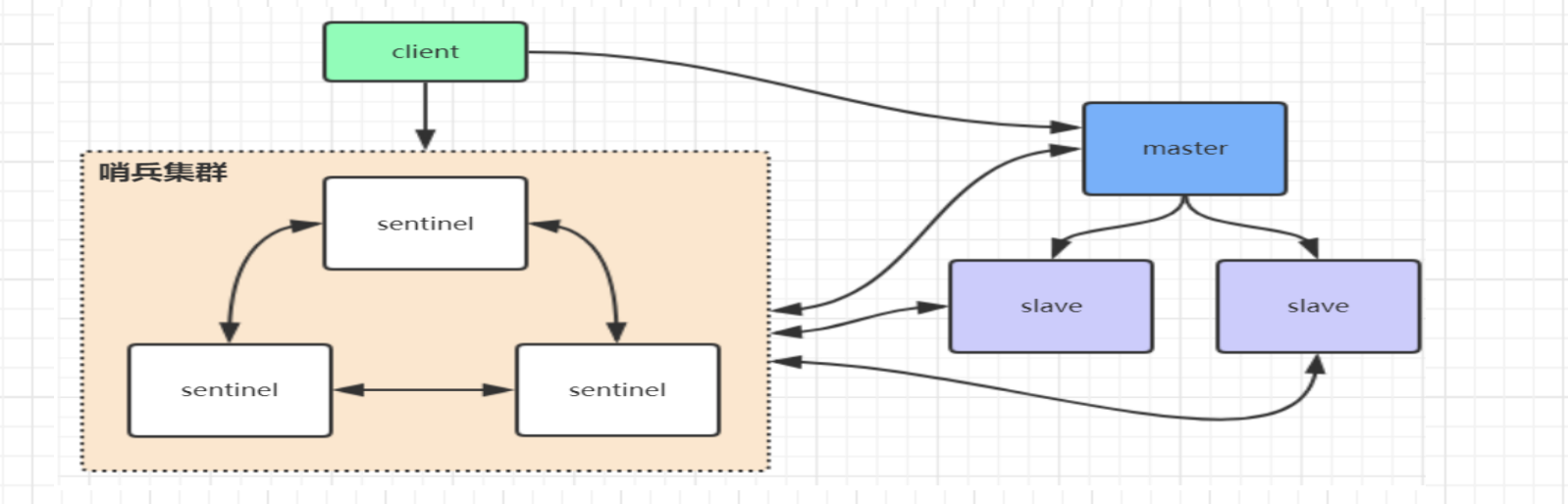
redis的哨兵是一种特殊的redis的服务,并不对外提供读写服务,只有在client第一次访问时,告诉client主节点,后续直接由主节点和clent和进行交互了,不用每次访问redis sentinel 哨兵集群。
当主节点挂了后,哨兵会第一时间感知到,进行重新选举,通知客户端client新的主节点。
缺点:1)主节点挂了后,会存在访问瞬断的情况,选举较慢
2)只有单一主节点对外访问,压力比较大,没发支持很高的并发
3)redis的主节点内存也不宜过大,会导致持久化文件过大,影响数据恢复和主从同步效率
4)配置还比较麻烦
Redis的集群架构
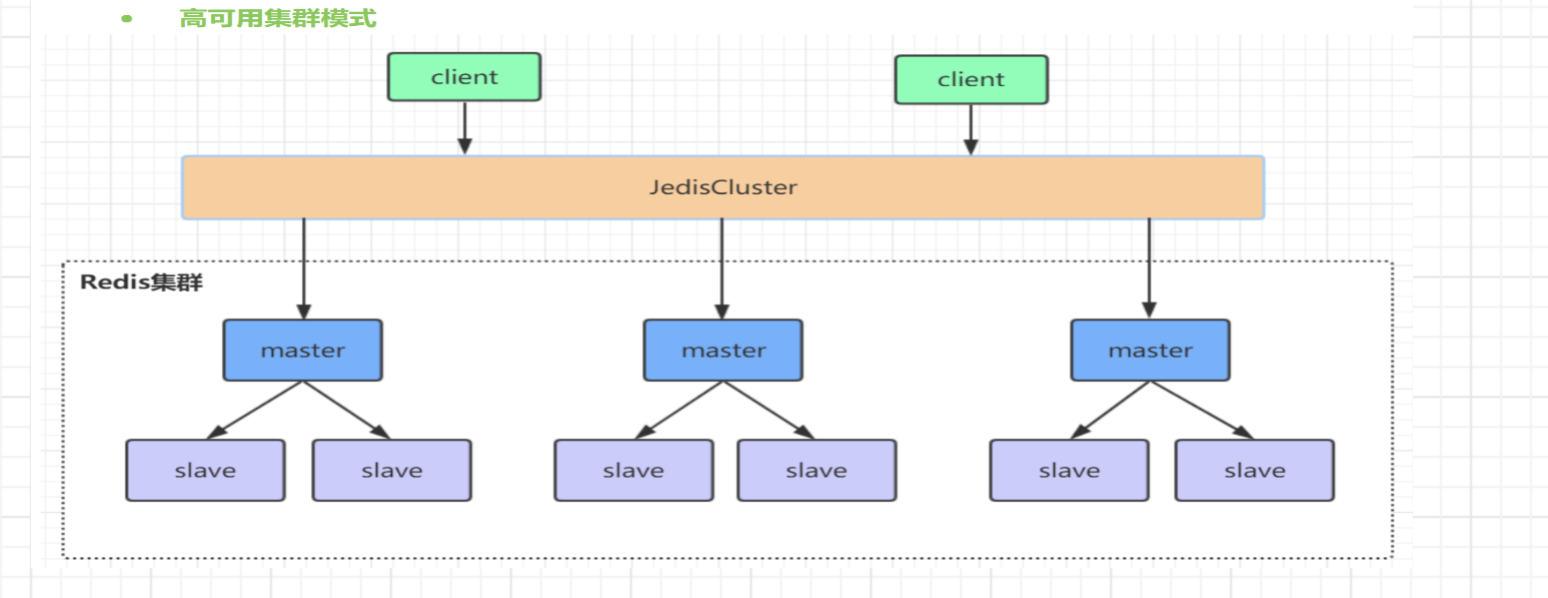
redis集群需要至少三个master节点
1.原理分析:
redis cluster将数据分为16384个slot(槽位),每个节点负责一部分槽位,槽位信息存在每个节点中,如下,集群启动后可以看到对应的槽位信息。
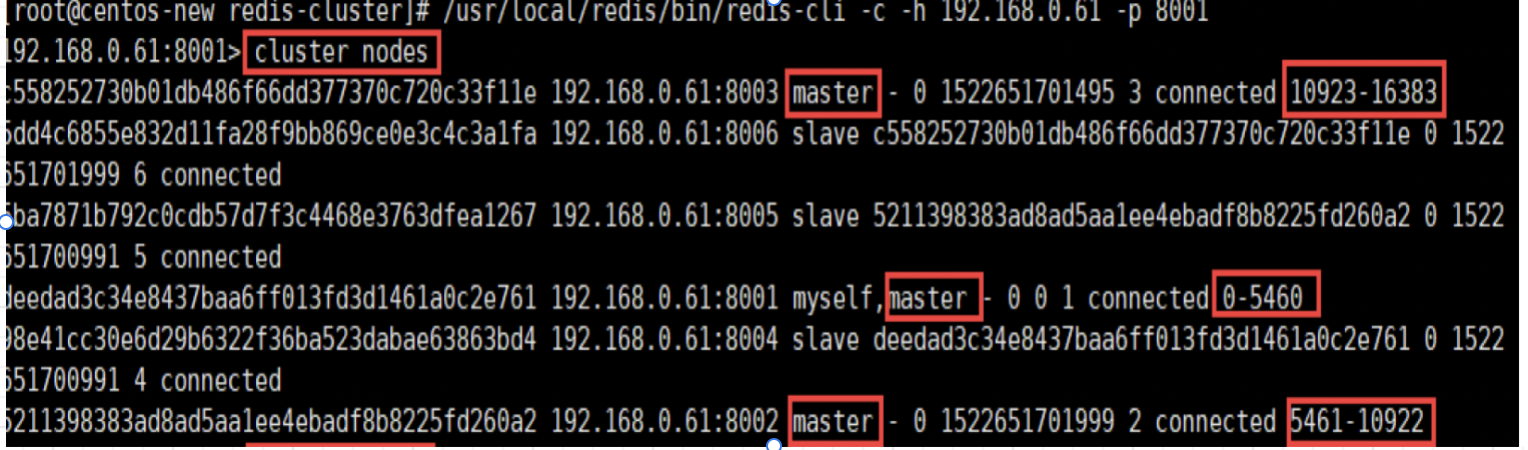
当client连接集群时,将对应的槽位信息在客户端,也存储一份;
由于客户端存储的槽位信息和节点存储的槽位信息可能不一致,也有对应的纠正机制对槽位信息进行纠正。
当操作某个key时,计算key对应的槽位(crc16 计算对应的hash值,对16384进行取余,得出对应的槽位)
HASH_SLOT = CRC16(key) mod 16384
跳转重定位
当客户端存储的槽位信息和节点的槽位信息不一致时,节点槽位发生了改变,节点会向客户端发送一个跳转正确槽位的指令,同时会更新缓存在客户端的槽位信息,后续再进行访问,利用新的槽位信息进行访问。
2.redis集群间的通信方式
redis集群间的通信方式采用的是gossip协议
一般集群间的通信方式分为集中式和gossip两种,各有优缺点
1)集中式
元数据的更新和获取时效性比较好,元数据进行变更时会立即更新到集中式的存储中,同时其它节点进行获取时,也会立即感知到,但是由于集中式储存管理元数据,导致集中的地方存储压力比较大,很多中间件利用zookeeper进行集中式管理。
2)gossip协议
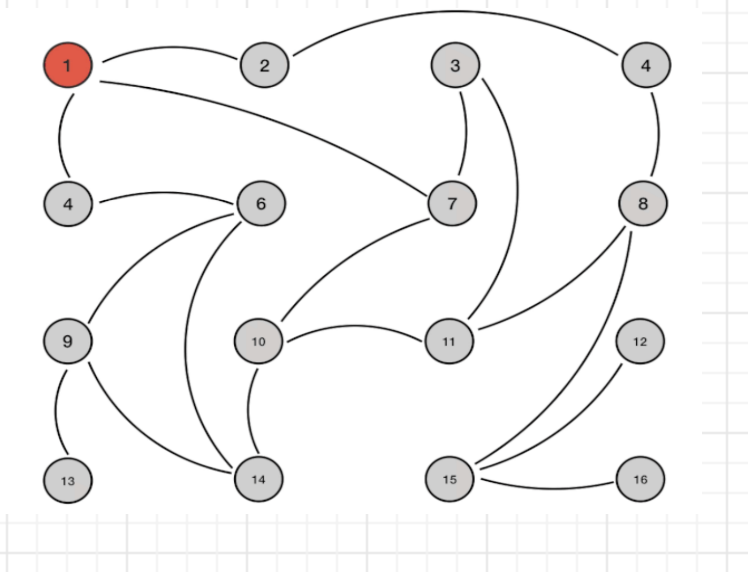
gossip协议包含meet、ping、pong、fail等
meet:某个节点对新加入的节点发送meet消息,让新加入节点与其他几点进行通信
ping:节点之间不断进行互相ping,包含自己的状态信息和自己维护的元数据信息(槽位信息)
pong:节点收到ping和meet后的返回,包含自己的状态信息和自己维护的元数据信息(槽位信息)
fail: 当一个节点发现另外一个节点挂了后,会发送fail消息给其他节点,通知说这个节点挂了
gossip协议缓解了集中式存储元数据信息的压力,节点的元数据信息分布在各个节点上,但是节点更新时,其他节点也不能立即感应到,存在一定的延时。
3.redis集群的选举流程:
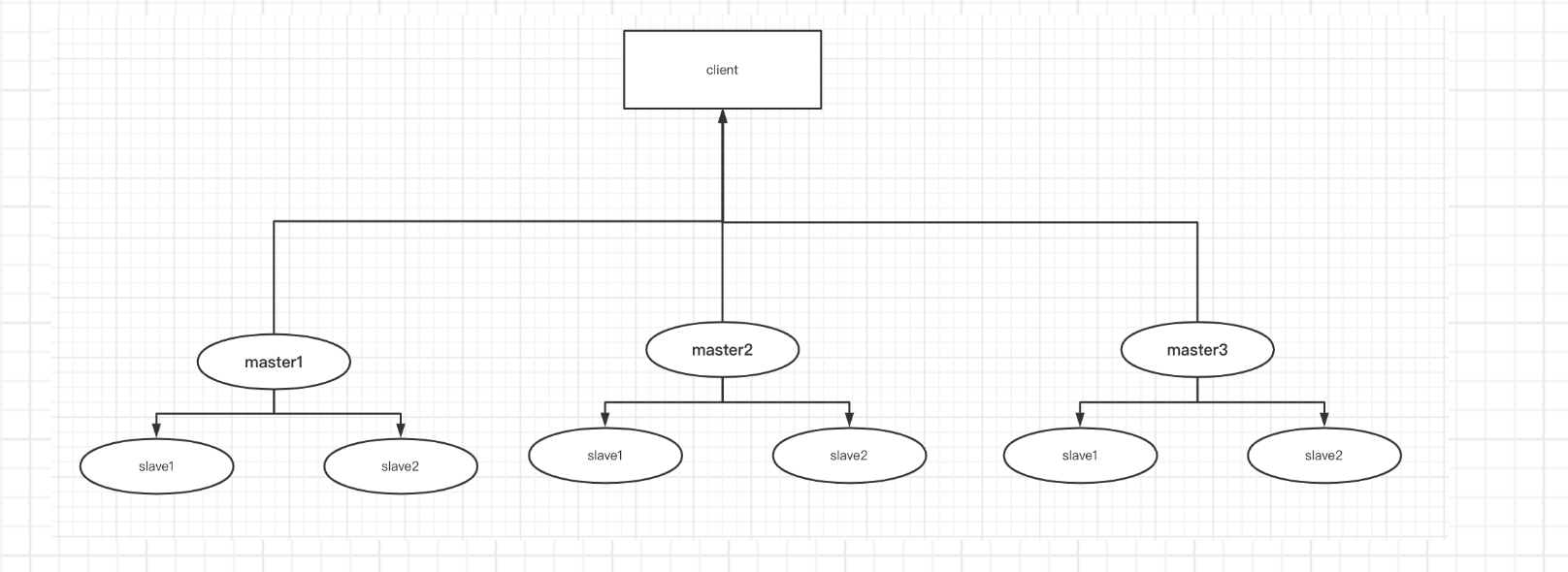
当master1宕机后,slave节点并不会立即竞争成为主节点,而是等待一定的时间,确认是宕机了才会进行主从切换,因为可能是因为网络抖动引起的短暂访问不到,防止频繁进行主从切换。
当真正宕机后,会等一段时间,master1宕机信息传递到其他节点时,才会进行重新选举,否则其他master是不会进行选举投票的(gossip传递需要一段的时间)
选举流程:
1)slave1和slave2 开始竞争,都将自己的currnetEpoch(记录集群状态变更的递增版本号)加1,向其他节点发送选举的消息,只有master节点才会进行ack响应,验证合法性,master收到slave1后就不会向slave2发送ack了,只会向一个从节点发送ack响应消息。
2)当节点收到ack的大于一半,就会成为新的master,如果slave1和slave2各为1,重复进行上面流程,进行选举。
4. Redis集群为什么至少需要三个master节点,并且推荐节点数为奇数?
因为redis选举master是超过半数才可以成为master的,如果只有两个节点(注意:宕机的主节点也包括在内),那么各占50%,当一个挂掉后,另一个只能投50% 的票,未超过半数,所以不能选举成功。
推荐节点为奇数,是为了节省服务器,因为3个master节点和4个master几点允许宕机也只能是1个,比如4个master,如果宕机两台,那么其他两选举,也只能占50%,并不能选举成功。
5.redis集群的脑裂问题
原master由于“假故障”触发了重新选举的机制,此时有两个master都可以对外防问,其中的一个master会降为slave,原主节点降级为slave,需要清空原来的rdb文件,同步新master的rdb文件,如果此时还有数据写入老的master,就会造成新写入的数据丢失。我们可以进行配置,避免脑裂,min‐replicas‐to‐write 1 //写数据成功最少同步的slave数量,此时我们老的master就不可以写入数据了,都从新master写入数据,避免数据丢失。

6. 哨兵leader选举流程
当一个master服务器被某sentinel视为下线状态后,该sentinel会与其他sentinel协商选出sentinel的leader进行故障转移工作。每个发现master服务器进入下线的sentinel都可以要求其他sentinel选自己为sentinel的leader,选举是先到先得。同时每个sentinel每次选举都会自增配置纪元(选举周期),每个纪元中只会选择一个sentinel的leader。如果所有超过一半的sentinel选举某sentinel作为leader。之后该sentinel进行故障转移操作,从存活的slave中选举出新的master,这个选举过程跟集群的master选举很类似。哨兵集群只有一个哨兵节点,redis的主从也能正常运行以及选举master,如果master挂了,那唯一的那个哨兵节点就是哨兵leader了,可以正常选举新master。不过为了高可用一般都推荐至少部署三个哨兵节点。为什么推荐奇数个哨兵节点原理跟集群奇数个master节点类似。
7.redis集群可以动态扩展和删除水平节点
redis分布式锁
redis分布式锁的注意问题:
- 设置锁过期时间,防止由于程序问题,不能解锁
- 解锁的必须是当前线程,其他线程不能解锁,可用线程id
- 可设置看门狗(再起一个线程,延长锁过期时间)
redis的lua脚本是原子性操作
redisson源码 -可重入式锁
源码解读:https://zhuanlan.zhihu.com/p/350153428
redisson红锁:可针对主从redis,锁失效问题引起的,由于主节点设置key加了锁了,从节点还未同步key加锁,主节点挂了,这时锁失效了;
redisson原理时给同步给其它节点设置key加锁,同步成功,才算加锁成功;
红锁本质上就是使用多个Redis做锁。例如有5个Redis,一次锁的获取,会对每个请求都获取一遍,如果获取锁成功的数量超过一半(2.5),则获取锁成功,反之失败;
释放锁也需要对每个Redis释放
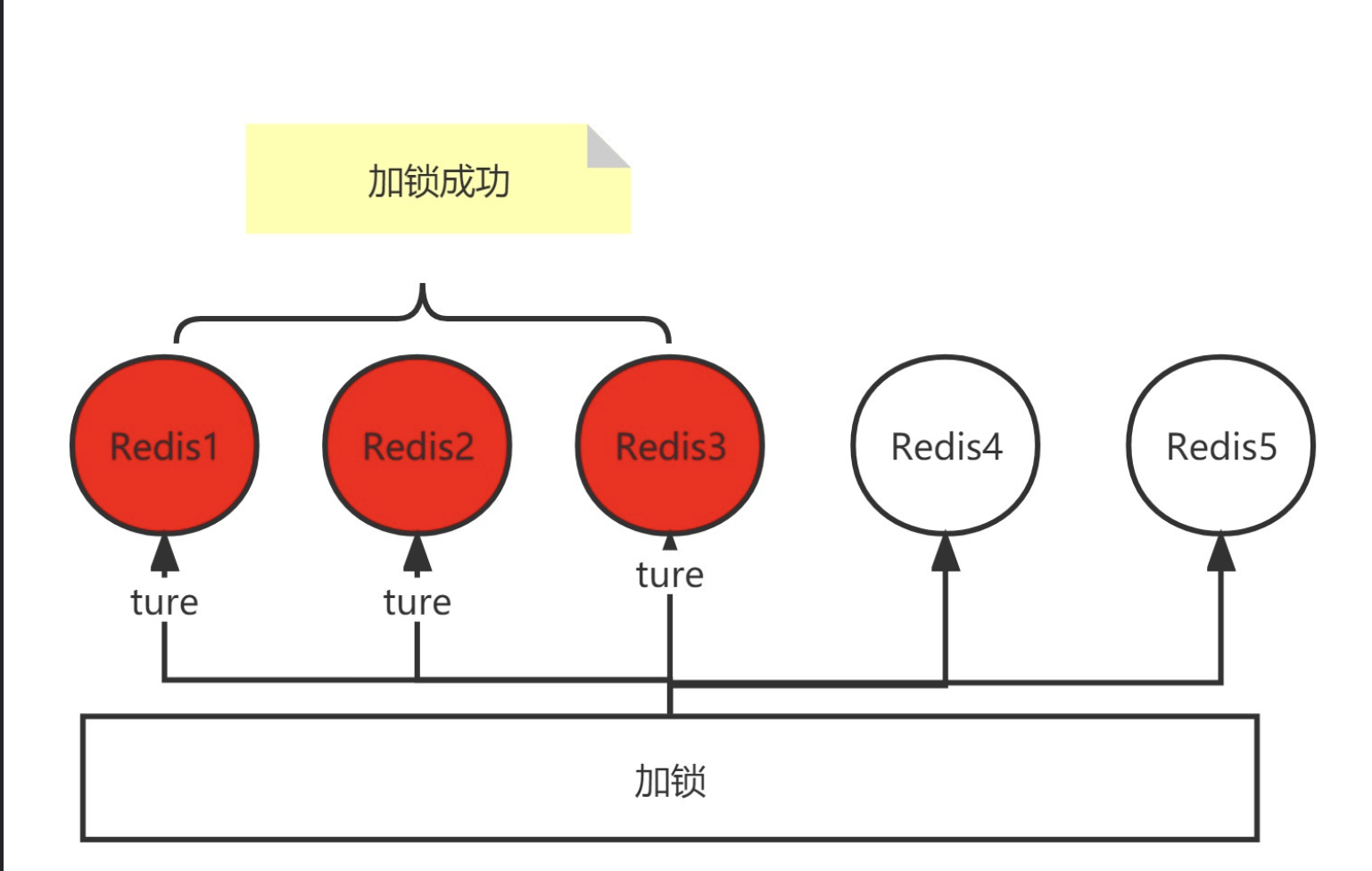
红锁可能产生的问题
Redis1、Redis2、Redis3、Redis4、Redis5五个Redis,Redis1、Redis2、Redis3成功,Redis4、Redis5失败,获取锁之后,Redis3挂掉了后重启,这是Redis3中这个作为锁的key丢掉,导致新的请求在Redis3、Redis4、Redis5中加锁成功,照成锁冲突问题?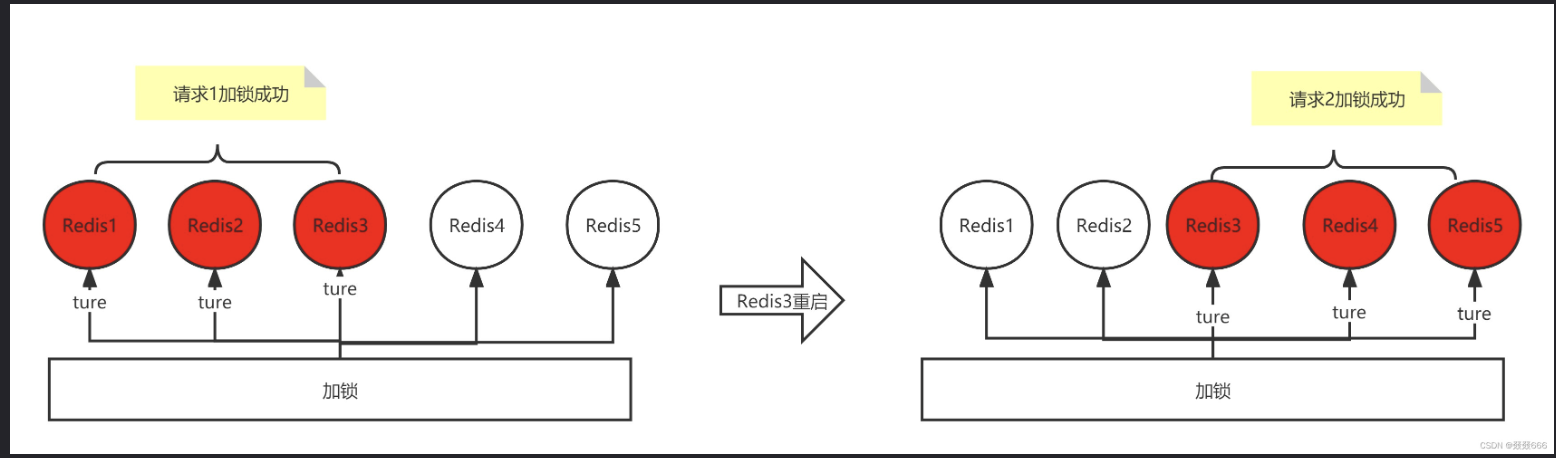
解决方案:
Redis挂了之后,不要立刻重启,要延迟一段时间之后在进行重启
redis需要注意的问题
1.redis缓存穿透----查询redis中根本不存在的key值,导致大量请求,会落到db上,造成数据的压力,黑客攻击
解决:1).缓存空值 2).使用布隆过滤器
2.redis击穿-----redis key值在某一时刻同时失效,都请求db
解决:1)设置不同的过期时间(针对不同的key) 2)使用redis分布式锁(高并发请求相同的key,要用分布式锁,减少数据库的压力,更新缓存)
3.redis 雪崩-----缓存层失效,大量请求(不同的key)落到db上
1)设置不同的过期时间
2) 构建高可用的redis集群
3)限流降级
4.redis存储热数据,保证redis内存存储的都是热点数据,避免不经常查询的数据一直在redis中存储,占用大量的内存
放入redis中的数据设置过期时间,查询时再次放入redis。
5.高并发下redis的读写一致性问题
redis分布式锁 redis延时双删策略
6.对于查询和更新操作,可以使用redisson的读写锁
7.高并发下,也可以结合分段式锁的设计,增大锁粒度,例如:秒杀场景下,库存,使用stock:id作为key,替换使用stock,这样仅仅会对操作同一件商品的请求阻塞,不会影响其他商品。也可以(id:0-100 100-200)这样设计分段锁,降低锁粒度
redis延时双删策略

假如是单删,没有延时删除,线程1、2、3同步执行,线程1更新了DB,并删除了redis,线程3此时进行查询redis为空,从DB中获取,查询到的是线程1修改的数据,还未放入缓存时,线程2进行更新操作,完成后,线程3放入了缓存,此时,缓存中有数据,存放的是线程1的老数据,此后,其他线程进行查询时,获取到的都是线程1的老数据,有问题。
有了延时删除后,过了延时的时间,会删除redis数据,其他线程查询时会重新从DB中获取更新到redis,避免了上述问题的出现,当然也会在延时的时间内出现上述问题,只不过持续时间没有那么长。(可以用mq 定时任务实现延时删除)
利用cannel监听数据库binlog,实现redis和数据库一致性
package com.tulin.payton.redis; import com.tulin.payton.util.RedisUtil; import org.redisson.Redisson; import org.redisson.api.RLock; import org.redisson.api.RReadWriteLock; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.PathVariable; import org.springframework.web.bind.annotation.RequestMapping; import java.util.Random; /** * 使用redis需要注意的问题 * <p> * 1.redis缓存穿透----查询redis中根本不存在的key值,导致大量请求,会落到db上,造成数据的压力,黑客攻击 * 解决:1).缓存空值 2).使用布隆过滤器 * 2.redis击穿-----redis key值在某一时刻同时失效,都请求db * 解决:1)设置不同的过期时间(针对不同的key) 2)使用redis分布式锁(高并发请求相同的key,要用分布式锁,减少数据库的压力,更新缓存) * <p> * 3.redis 雪崩-----缓存层失效,大量请求(不同的key)落到db上 * 1)设置不同的过期时间 * 2) 构建高可用的redis集群 * 3)限流降级 * <p> * 4.redis存储热数据,保证redis内存存储的都是热点数据,避免不经常查询的数据一直在redis中存储,占用大量的内存 * 放入redis中的数据设置过期时间,查询时再次放入redis。 * <p> * 5.高并发下redis的读写一致性问题 * redis分布式锁 redis延时双删策略 * <p> * 6.对于查询和更新操作,可以使用redisson的读写锁 * <p> * 7.高并发下,也可以结合分段式锁的设计,增大锁粒度,例如:秒杀场景下,库存,使用stock:id作为key,替换使用stock, * 这样仅仅会对操作同一件商品的请求阻塞,不会影响其他商品。也可以(id:0-100 100-200)这样设计分段锁,降低锁粒度 */ /** * 热门知识点,热门的知识(频繁的进行编辑更新,前端页面进行展示最新的-----并发200),知识点会发生变化 */ @RequestMapping("/hotknowledge") public class HotKnowledge { private static final String PORDUCT_PREFIX = "product:"; private static final String PORDUCT_EMPTY = "empty"; private static final Long PORDUCT_EXPIRE_TIME = 60 * 60 * 24L; private static final String LOCK_PRODUCT_HOT_CACHE = "lock_product_host"; private static final String LOCK_PRODUCT_UPDATE = "lock_product_update"; @Autowired private Redisson redisson; @Autowired private RedisUtil redisUtil; @RequestMapping("/add/{id}") public void addHotProdouct(@PathVariable Integer id) { String redisKey = PORDUCT_PREFIX + id; //存入db String product = saveDB(id); redisUtil.set(redisKey, product, getPorductExpireTime()); } @RequestMapping("/update/{id}") public void updateHotProdouct(@PathVariable Integer id) { //高并发下的双写一致性问题,要获得的这个商品,被更新了,要保证获取的是数据中更新后的商品 RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE); Redisson redisson=new Redisson(); redisson.getRedLock(); RLock rLock = readWriteLock.writeLock(); try { rLock.lock(); String product = saveDB(id); String redisKey = PORDUCT_PREFIX + id; redisUtil.set(redisKey, product, getPorductExpireTime()); } finally { rLock.unlock(); } } @RequestMapping("/get/{id}") public String saveHotProdouct(@PathVariable Integer id) { String redisKey = PORDUCT_PREFIX + id; String product = (String) redisUtil.get(redisKey); if (product != null && !PORDUCT_EMPTY.equals(product)) { //更新redis,续命 redisUtil.expire(redisKey, getPorductExpireTime()); return product; } //高并发下请求同一个产品,防止全部请求,打到数据库db上,造成较大的压力------缓存击穿 RLock lock = redisson.getLock(LOCK_PRODUCT_HOT_CACHE); //高并发下的双写一致性问题,要获得的这个商品,被更新了,要保证获取的是数据中更新后的商品 RReadWriteLock readWriteLock = redisson.getReadWriteLock(LOCK_PRODUCT_UPDATE); RLock rLock = readWriteLock.readLock(); try { rLock.lock(); lock.lock(); product = getProductFromCache(id); } finally { rLock.unlock(); lock.unlock(); } return product; } public String getProductFromCache(Integer id) { String redisKey = PORDUCT_PREFIX + id; String product = (String) redisUtil.get(redisKey); if (product != null && !PORDUCT_EMPTY.equals(product)) { //更新redis,续命 redisUtil.expire(redisKey, getPorductExpireTime()); return product; } product = productFromDB(id); redisUtil.set(redisKey, product, getPorductExpireTime()); return product; } //防止高并发下不同的产品同一时间过期,导致发生redis击穿的问题-----缓存雪崩 public Long getPorductExpireTime() { return PORDUCT_EXPIRE_TIME + new Random().nextInt(30); } //查询数据库--从数据库中获取产品 public String productFromDB(Integer id) { return "productA"; } //放入数据库 public String saveDB(Integer id) { return "product" + id; } }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号