C++多线程笔记
C++多线程笔记
这篇笔记主要是在整理C++thread库的使用,对于较为高级的比如写一个线程池,在我之前的文章中有写过。
OK,让我们看看C++中的多线程吧。
1.1 创建一个线程
C++提供了std::thread来创建一个线程。使用时需要包含
来看看cppreference的这个例子(不得不说这个网站的例子是真的好)
#include <iostream>
#include <utility>
#include <thread>
#include <chrono>
void f1(int n){
for(int i = 0;i < 5;i++){
std::cout<<"Thread 1 executing\n";
++n;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
}
void f2(int &n){
for(int i = 0;i < 5;i++){
std::cout<<"Thread 2 executing\n";
++n;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
}
class foo{
public:
void bar(){
for(int i = 0;i < 5;i++){
std::cout<<"Thread 3 executing\n";
++n;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
}
int n = 0;
};
class baz{
public:
void operator()(){
for(int i = 0;i < 5;i++){
std::cout<<"Thread 4 executing\n";
++n;
std::this_thread::sleep_for(std::chrono::milliseconds(10));
}
}
int n = 0;
};
int main(){
int n = 0;
foo f;
baz b;
std::thread t1; //t1 is not a thread
std::thread t2(f1,n+1);//pass by value
std::thread t3(f2,std::ref(n));//pass by reference
std::thread t4(std::move(t3));//t4 is now running f2(),t3 is no longer a thread
std::thread t5(&foo::bar,&f);//t5 runs foo::bar() on object f
std::thread t6(b);//t6 runs baz::operator() on a copy of object b
t2.join();t4.join();t5.join();t6.join();
std::cout<<"Final value of n is "<<n<<"\n";
std::cout<<"Final value of f.n (foo::n) is "<<f.n<<"\n";
std::cout<<"Final value of b.n (baz::n) is "<<b.n<<"\n";
}
这体现了thread中传不同参数起到的效果。
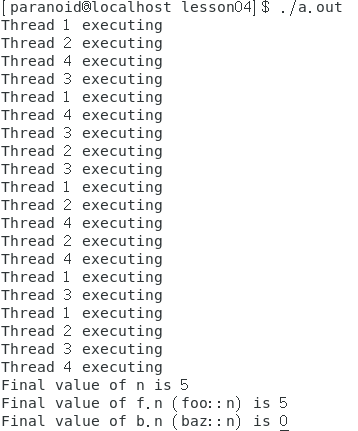
注意到代码中使用到了join()这个函数,这个函数阻断当前线程,直到*this标识的线程完成。说人话就是我们在主线程中创建子线程1、2,我们的主线程会阻塞,等待子线程1、2执行完我们的主线程才会开始继续工作。还有一个函数detach()也能取到类似的效果。两者的区别就是是否等待子线程结束。但是detach()有让引用对象失效的风险。
1.2 互斥量和临界区
什么是互斥量?
我们需要管理一小段代码,或者一些共享资源。可以这样想象:我们把资源放进保险箱,然后给保险箱加上一把锁,这把锁就是互斥量(mutex),我们可以上锁(lock),也可以解锁(unlock)。
要使用互斥量,需要导入#include
lock_guard()和unique_lock()这两个函数上锁和解锁的同时还具备raii风格。
1.2.1 lock_guard()和unique_lock()
先看看如何使用lock_guard()。
#include <iostream>
#include <utility>
#include <thread>
#include <chrono>
#include <map>
#include <mutex>
#include <string>
std::map<std::string,std::string> pages;
std::mutex m_mutex;
void save_page(const std::string &url){
std::this_thread::sleep_for(std::chrono::seconds(2));
std::string res = "fake content";
std::lock_guard<std::mutex> guard(m_mutex);
pages[url] = res;
}
int main(){
std::thread t1(save_page,"http://foo");
std::thread t2(save_page,"http://bar");
t1.join();t2.join();
for(const auto &pair: pages){
std::cout<<pair.first<<"->"<<pair.second<<std::endl;
}
}
就像很多在栈区的变量一样,lock_guard会在{}结束的时候自动回收。
当然有的时候也需要的时候手动上锁和解锁,lock_guard()没有实现了这个功能,所以细粒度的unique_lock()也就诞生了。
除了上面这种传一个参数的用法,lock_guard()还可以传两个参数,第二个参数只能是adopt_lock,出现这个标识则需要提前手动上锁。而unique_lock则提供了更多的选择,它的第二个参数还可以是try_to_lock和defer_lock。
try_to_lock:尝试锁定。得保证锁处于unlock的状态,然后尝试现在能不能获得锁;尝试用mutex的lock()去锁定这个mutex,但如果没有锁定成功,会立即返回,不会阻塞在那里
defer_lock:初始化一个解锁状态的mutex。
1.2.2 死锁
死锁是一种现象,多个线程争夺共享资源导致每个线程都不能取得自己所需的全部资源。
死锁的四个必要条件:
- 互斥(资源同一时刻只能被一个进程使用)
- 请求并保持(进程在请资源时,不释放自己已经占有的资源)
- 不剥夺(进程已经获得的资源,在进程使用完前,不能强制剥夺)
- 循环等待(进程间形成环状的资源循环等待关系)
死锁预防:
破坏死锁产生的四个条件(完全杜绝死锁)
死锁避免:
对分配资源做安全性检查,确保不会产生循环等待(银行家算法)
死锁检测:
允许死锁的发生,但提供检测方法
死锁解除:
已经产生了死锁,强制剥夺资源或者撤销进程
然而这篇笔记的主题重在使用,死锁更加详细博客应该会在之后给出(希望不会鸽掉)
1.2.3 条件变量
条件变量std::condition_variable就是为了解决死锁问题而被引入的。condition_variable实例被创建主要是用于唤醒另外一个线程从而避免出现死锁。
先来看看如何使用:
#include <iostream>
#include <utility>
#include <thread>
#include <chrono>
#include <map>
#include <mutex>
#include <string>
#include <condition_variable>
std::mutex m;
std::condition_variable cv;
std::string data;
bool ready = false;
bool processed = false;
void Worker(){
std::unique_lock<std::mutex> lk(m);
cv.wait(lk,[]{
return ready;
});
std::cout<<"worker thread is processing data\n";
data += "after processing";
processed = true;
std::cout<<"worker thread signals data processing completed\n";
lk.unlock();
cv.notify_one();
}
int main(){
std::thread worker(Worker);
data = "Example data";
{
std::lock_guard<std::mutex> lk(m);
ready = true;
std::cout<<"main() signals data ready for processing\n";
}
cv.notify_one();
{
std::unique_lock<std::mutex> lk(m);
cv.wait(lk,[]{
return processed;
});
}
std::cout<<"Back in main(),data = "<<data<<"\n";
worker.join();
}
来看下执行结果

第一个需要关注的函数是wait(lk,条件函数),它会一直阻塞直到条件满足为止。一旦当前线程被另外一个线程使用notify_all/notify_one唤醒,wait函数自动调用lock。
条件变量还有一个问题值得关注,那就是虚假唤醒。唤醒线程时,可能会唤醒多个线程,但是如果对应的资源只有一个线程能获得,其余线程就无法获得该资源,因此其余线程的唤醒是无意义的(有时甚至是有危害的),其余线程的唤醒则被称为虚假唤醒。
解决办法就是每次使用共享数据的时候判断一下如果不正确就等一下,这一个过程用while不用if。
2.1 实现一个生产者消费者模型
在有了之前的知识之后已经可以用多线程编程来写一个生产者消费者模型了。
#include <iostream>
#include <utility>
#include <thread>
#include <chrono>
#include <map>
#include <mutex>
#include <string>
#include <condition_variable>
#include <queue>
#include <vector>
std::mutex m;
std::condition_variable cv;
std::queue<int> produced_que;
bool notify = false;
void producer(){//生产者
int i = 0;
while(1){
std::this_thread::sleep_for(std::chrono::seconds(1));
std::unique_lock<std::mutex> lk(m);
std::cout<<"produce: "<<i<<std::endl;
produced_que.push(i);
notify = true;
cv.notify_all();
i++;
}
}
void consumer(int n){//消费者
while(1){
std::unique_lock<std::mutex> lk(m);
while(!notify){//避免虚假唤醒
cv.wait(lk);
}
lk.unlock();
std::this_thread::sleep_for(std::chrono::seconds(2));
lk.lock();
while(!produced_que.empty()){
std::cout<<"consum "<<n<<": "<<produced_que.front()<<std::endl;
produced_que.pop();
}
notify = false;
}
}
int main(){
std::thread pro(producer);
std::thread con[6];
for(int i = 0;i <= 5;i++) con[i] = (std::thread(consumer,i));
pro.join();
for(int i = 0;i <= 5;i++) con[i].join();
}
3.1 异步线程
3.1.1 异步
C++11引入了std::async,也就是异步运行。
我们都知道线程可以将一个任务转移到thread中执行,这个任务往往是一个函数。但有一个问题,函数都有返回值,我们怎么获得返回值呢?一个很明显的做法是使用一个变量来存储,这太复杂了显然不是一个好方法。std::async就是这样一个过程,它会自动创建一个线程,返回一个std::future,线程的结果就是future,我们在需要的时候调用它即可。当然在此之前我们还需要了解std::promise、std::future、std::packagerd_task。
3.2.1 std::future
简单来说,std::future提供了一种访问异步操作结果的机制。它直译过来是未来,我们站在当前线程考虑它调用了一个std::async得到了一个结果,我们在这个时刻使用的结果是将来std::async执行结束的结果。这就像是我们使用了未来的东西。
std::future<int> f = std::async(Task);
我们可以通过get(等待异步操作结束并且返回结果)、wait(等待异步操作完成)、wait_for(超时等待)获得结果。
3.2.2 std::promise
获取线程函数中的某一个值提供便利,在线程函数中给外面传来promise赋值,结束之后通过promise获得值。
它可以这样使用:
std::promise<int> pro;
std::thread t([](std::promise<int>& p){
p.set_value_at_thread_exit(9);
},std::ref(pro));
std::future<int> f = pr.get_future();
auto a = f.get();
3.2.3 std::packaged_task
packaged_task是将一个任务打包,这个任务可以是function,lambda表达式,bind或者其他的函数表达式。它和promise在某种程度上比较像。
它可以这样使用:
std::packaged_task<int()> task([](){return 7;});
std::thread t1(std::ref(task));
std::future<int> f = task.get_future();
auto a = f.get();
最后感谢这几分资料
C++多线程基础教程
[C++多线程并发基础入门教程]( https://zhuanlan.zhihu.com/p/194198073#:~:text=C%2B%2B多线程并发: ,%EF%BC%88%E7%AE%80%E5%8D%95%E6%83%85%E5%86%B5%E4%B8%8B%EF%BC%89%E5%AE%9E%E7%8E%B0C%2B%2B%E5%A4%9A%E7%BA%BF%E7%A8%8B%E5%B9%B6%E5%8F%91%E7%A8%8B%E5%BA%8F%E7%9A%84%E6%80%9D%E8%B7%AF%E5%A6%82%E4%B8%8B%EF%BC%9A%E5%B0%86%E4%BB%BB%E5%8A%A1%E7%9A%84%E4%B8%8D%E5%90%8C%E5%8A%9F%E8%83%BD%E4%BA%A4%E7%94%B1%E5%A4%9A%E4%B8%AA%E5%87%BD%E6%95%B0%E5%88%86%E5%88%AB%E5%AE%9E%E7%8E%B0%EF%BC%8C%E5%88%9B%E5%BB%BA%E5%A4%9A%E4%B8%AA%E7%BA%BF%E7%A8%8B%EF%BC%8C%E6%AF%8F%E4%B8%AA%E7%BA%BF%E7%A8%8B%E6%89%A7%E8%A1%8C%E4%B8%80%E4%B8%AA%E5%87%BD%E6%95%B0%EF%BC%8C%E4%B8%80%E4%B8%AA%E4%BB%BB%E5%8A%A1%E5%B0%B1%E8%BF%99%E6%A0%B7%E5%90%8C%E6%97%B6%E5%88%86%E7%94%B1%E4%B8%8D%E5%90%8C%E7%BA%BF%E7%A8%8B%E6%89%A7%E8%A1%8C%E4%BA%86%E3%80%82)
C++11多线程-异步运行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号