
python-requests基础爬虫(以知乎为例)
requests是比较基础、同时对于初学者比较抽象的爬虫方法;requests一般用于获取请求网页的html内容的response对象,我们可以对其response对象进行text文本化或者json序列化,以方便后续抽取信息的操作。
(对知乎某话题评论文本的爬取需求来源于我大二上学期参加的市场调研比赛,这是一项十分硬核、注重统计实力的比赛)
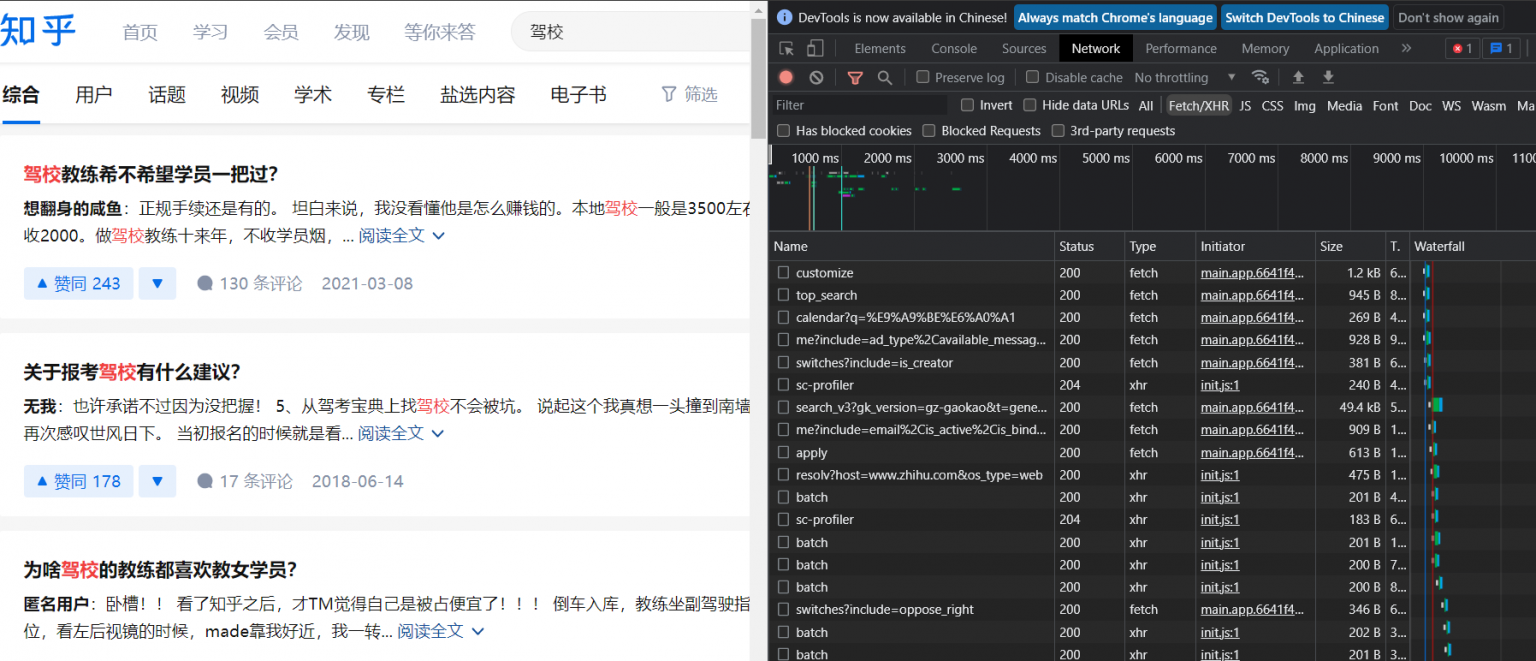
通过逐次点击这些数据包,查看其“preview|预览”,发现这种类似“search_v3?gk…”的数据包含有评论者的信息,图中列表0,1,2,3…..各自包含一大段评论的信息。
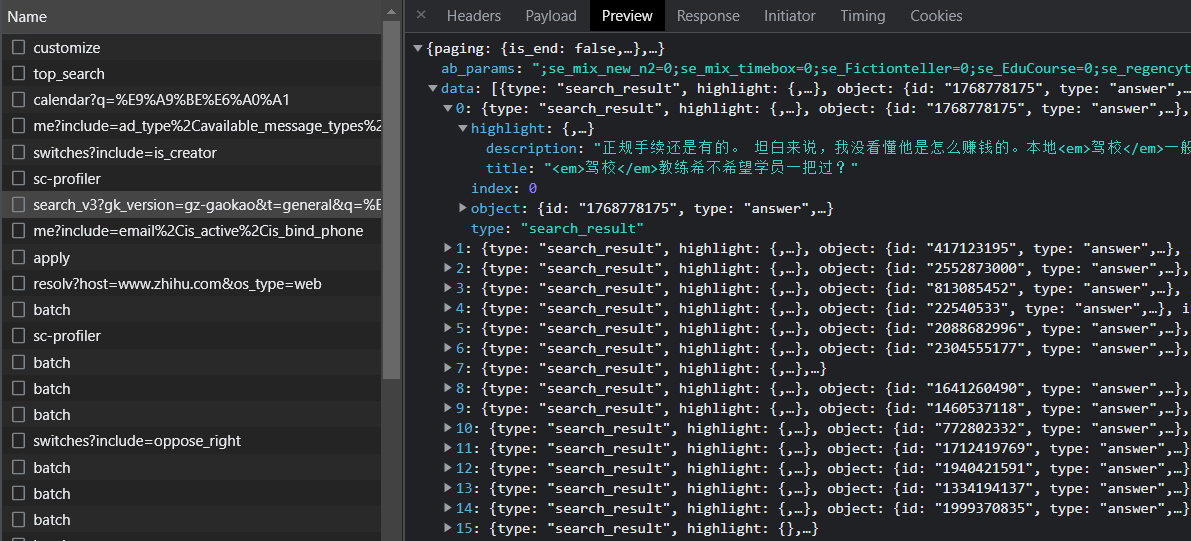
但实际上,这个数据包的“Headers|标头”的请求URL是无法通过输入浏览器地址栏直接访问的,否则它会显示 {“error”:{“code”:4041,”name”:”NotFoundError”,”message”:”资源不存在”}},这样就更别提request模块对其的访问了。
进一步探索
但是我们发现,点击“展开评论”,服务器会发给我们这种类型的数据包,形如“root_comments?order….”,这个数据包对于评论信息的内容,是属于刚刚那个“search_v3?gk…”数据包的子集的,而且它的“Headers|标头”的请求URL可以直接访问得到,如图:
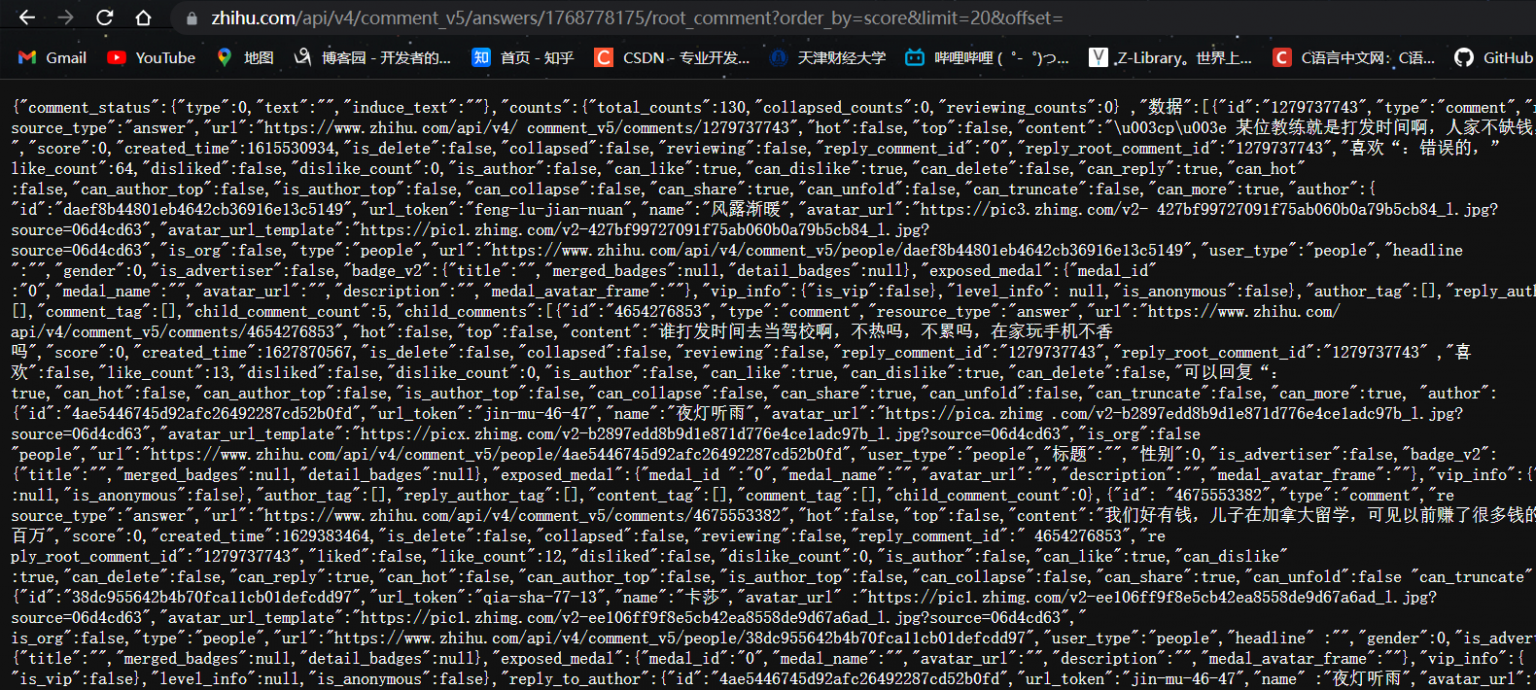
但是,这个root数据包仅仅包含部分评论信息,想要实现批量自动化抓取,得探究root包和search包的关系。
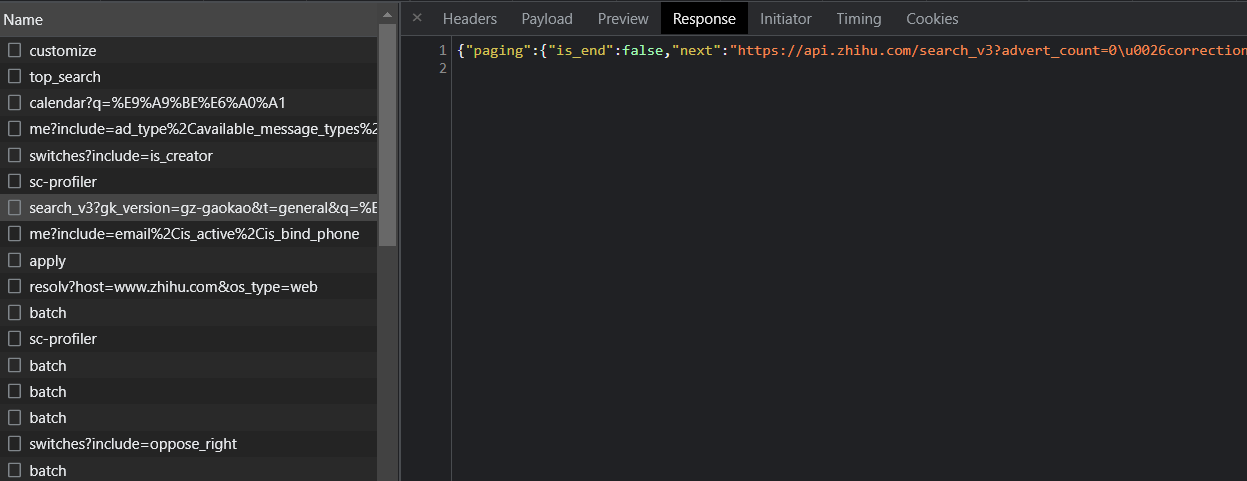
不难发现,search包的“preview|预览”中第0行的id是1768778175,而root包的“Headers|标头”的请求URL中就包含了这个id;从而认为后续的root包的链接id会陆续为search包的后几行的id;代入id验证,发现确实如此。
撰写程序
于是需要对search包中的id通过正则表达式抽取出来,应用于root包的请求;但首先,search包本身不能直接得到,需要在知乎中搜索后,在开发者工具中找到它,点击它的“response|响应”,将其json文本写入文本文件,比如“record.txt”中;
防止被浏览器辨认出是爬虫,需要进行UA伪装,成为一个“有头有脸”的访问者,其‘User-Agent’和‘cookie’可以在数据包的“Headers|标头”里下滑寻找,代码如下:
1 import requests
2 import re
3 #UA伪装
4 headers={
5 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62',
6 "cookie":"cookie: SINAGLOBAL=4294748467755.9355.1604583148568; SUB=_2AkMXx8M8f8NxqwJRmPAQxWLgbYp_zQvEieKhmzLnJRMxHRl-yT9jqnVctRB6PEft03IfSAYiIrdF89z829EQPm__FPcY; UOR=,,cn.bing.com; ULV=1633267280794:3:1:1:4620029788264.748.1633267280789:1606139228123; XSRF-TOKEN=iINEPWBhUrKU8iQ9al1GsSdG; WBPSESS=durPiJxsbzq5XDaI2wW0NwyiqGwsc0LjLM7hQHT-OwXXHDkMbPvx-wTbNNdrrGZpwuTJoOyVWfGMuRWlBHJ4NtIUmXtkhyl5AFzVUYUURPHU42WskzXD7H05rm1dRCaB",
7 }
8 li=[]
9 #将若干二级url放入txt文件中(因为这不能直接爬取)
10 f=open("E:\\desktop\\record.txt","r",encoding='utf-8')
11 obj=re.compile(r'"object":{"id":"(?P<id>.*?)",("type"|"title")') #针对知乎百科专题的re筛选
12 #obj=re.compile(r'"created_time":.*?"id":(?P<id>.*?),"(token|url)".*?"topic_thumbnails"')#针对知乎讨论专题的re筛选
13
14 ids=obj.finditer(f.read())
15 for it in ids:
16 dic=it.groupdict() #将对象dict化
17 if len(dic['id'])<=11: #有的并非是id,因为id一般小于11位
18 li.append(dic['id']) #将回答者的id存储进列表
19 f.close()
20 #将评论文本存储进txt文件
21 with open("E:\\desktop\\comments2.txt",'w',encoding='utf-8')as f:
22 for id in li:
23 url="https://www.zhihu.com/api/v4/answers/"+str(id)+"/root_comments?order=normal&limit=20&offset="
24 resp=requests.get(url,headers=headers)
25 try:
26 for data in resp.json()['data']:
27 content=data['content']
28 id=data['id']
29 f.write(str(id)+":"+content+"\n")
30 except KeyError:
31 pass
结束语
一般对于单个search包,仅仅能爬取200-300条评论信息;若需要加量,可以直接在知乎里下滑展开查看,浏览器便会收到新的search包,再将其“response|响应”内容复制到record.txt文件即可;最后爬取的评论信息会在comments.txt文件里找到。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号