《Lua的设计与实现5.3》笔记
一、数据类型
我们可以看到Lua中除了TNONE类型之外,还定义了额外的8种类型(LIGHTUSERDATA和USERDATA一样,都是void* ,区别在于Lua是不是需要关心它的生存期,分配释放的操作者是Lua内部实现还是外部实现,前者是外部,后者是内部)

#define LUA_TNONE (-1)
#define LUA_TNIL 0
#define LUA_TBOOLEAN 1
#define LUA_TLIGHTUSERDATA 2
#define LUA_TNUMBER 3
#define LUA_TSTRING 4
#define LUA_TTABLE 5
#define LUA_TFUNCTION 6
#define LUA_TUSERDATA 7
#define LUA_TTHREAD 8
由于Lua语言是由纯C语言实现的,我们可以从C的角度去理解一下如何实现面向对象的
先看第一种 定义一种基础类型
struct base{
int type;
}
struct string{
struct base info;
int len;
char *data[0];
}
string number{
struct base info;
double num;
}
再看第二种使用Union来将所有需要的数据包进来,这里理解一下这个union,这个union就是一个结构,Lua也是看上了它的内存分配的灵活性。
--[[
Union:
当多个数据需要共享内存或者多个数据每次只取其一时,可以利用联合体
1)联合体是一个结构;
2)它的所有成员相对于基地址的偏移量都为0;
3)此结构空间要大到足够容纳最"宽"的成员;
4)其对齐方式要适合其中所有的成员;
]]--
struct string{
int len;
char *data[0];
}
string number{
double num;
}
struct value{
int type;
union{
string str;
number num;
} value;
}
Lua其实是采用了这两个设计的结合,同时采用。
Lua在实现的时候 还添加了一个叫做Variant tags 来分别定义其子类型
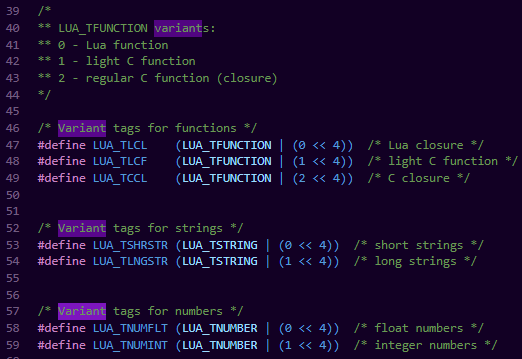
比如说string定义了长串和短串,number里由float和int类型。
那我们现在来看一下 Lua中一些关键的数据结构
Value和TValue
lua为了方便对所有的类型进行统一管理,把它们都抽象成了一个叫做Value的union结构:
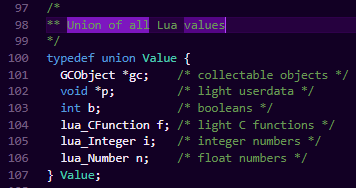
我们可以从定义看出来,主要把这些类型区分为了需要GC和不需要GC的类型,由于是定义的union,我们就可以知道,每个实例中同时是只会有一个字段有效的,至于是哪个字段,该Value是什么类型,Lua新定义了一个结构叫TValue。
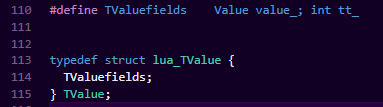
我们可以很清晰的看到,TValuefields中包含了Value字段和int类型。这也是Lua实现数据结构的主要手段。
GC相关结构
关于GC,Lua内部把所有值区分为了需要GC和不需要GC的类型
1、GCUnion
所有需要GC的类型被定义在了GCUnion中
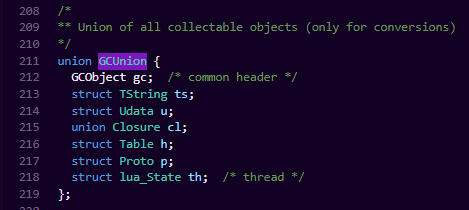
我们能看到lua中所有需要被GC的类型 被包含在了这个Union中。
那么这个时候 我们可以对比一下关于基础数据union结构的Value和GCUnion
大家来看看有什么不一样的呢?
因为是Union,所以是和Value一致,同时是只有一个字段是有效的,那我们自然会考虑到,Lua是不是和TValue一样,为我们封装了一层GCUnion呢?
但是其实并没有,GC的实现方式略有不同,是让各自的实现类,比如TString,在定义的开头,实现了一个叫做CommonHeader的宏,这个宏里就包含了type和一些其他的字段
2、ComonHeader
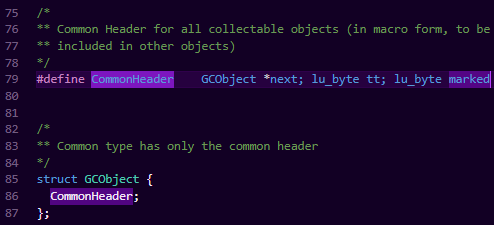
我们能看到,实现了三个字段
next:指向GCObject的指针,用于GC算法内部实现链表
tt:指该GC对象的具体类型(没错,类型就算由这个继承的"基类"的宏来储存判断的)
marked:是GC算法内部的实现,稍微提一句,lua是三色标记法,根据的就是这个字段来判断颜色。
3、GCObject
我们看了有两个字段GCUnion和ComonHeader中都有一个字段GCObject,其实这边的GCObject就是把CommonHeader这个数据区包成了一个结构,它的好处在于lua可以把所有的GC类型的对象都视作一个GCObject。
我们来看一个lua中创建一个gcobject的函数
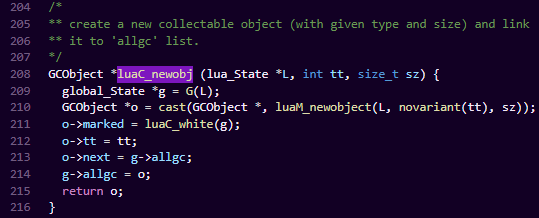
每一个像String、Table这种子类型的,他们的创建,都会调用这个接口去创建一个GCObject实例,区别只是在于传入的type和内存size不一样而已。而这个公用函数会帮你初始化掉关于commonheader部分的数据,每个类型创建的实例剩余内存部分自己设置好就可以。
我们来看下String的创建
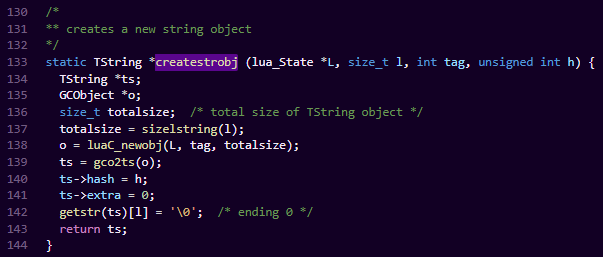
可以看出string在创建完成以后,调用了内部的gco2ts函数,把本来指向GCObject指针强转成了指向TString的指针,然后赋予了一些TString的额外元数据。
我相信这个时候大家应该也能理解 为什么基础的结构“Value”这个Union结构中,没有string和table的存在了吧
顺便提一嘴,lua内部在做类型转换的时候,是分别将结构体内部的value和类型tt分别转换,然后分配内存
二、String
其实我们不管从哪个语言来看这个类型,我们都知道 string的核心无非就两个属性:
1、长度
2、指针
那我们知道,lua里的string是存放引用的,那我们理解了这一个概念,很多东西也就是共通的,顺着自己的思路理解就好了。
内部会分成短串shortStr和长串longStr处理 区别规则是长度40 大于是长串 反之是短串
1、结构体
CommonHeader: 通用GC
extra: 对于短串,主要用于实现保留字符串;对于长串,作为一个标识,来表示该串有没有进行过hash;extra == 0 时 表示未计算过hash值反之则计算过。
shrlen: 短串的长度,对于长串没有意义。注意长串和短串没有共用一个字段来表示它们的长度(短串一个字节就搞定 最多40)
hash: 如果是短串,该hash值是在创建时就计算出来的,这是因为短串会加入到全局的stringtable这个hashmap结构中;对于长串来说,这个hash字段是按需的,只有真正需要它的hash值时,手动调用luaS_hashlongstr函数,才会生成该值,lua内部现在只有在把长串作为table的key时,才会去计算它。
union{lnglen, hnext}: 表示长串的长度;当是短串时,由于会被加入到全局stringtable的链表中,所以在该结构中保存了指向下一个TString的指针;注意长串和短串没有共用一个字段来表示它们的长度!!!(再次强调)
2、StringTable(全局的hashmap. 用于保存):
hash: 基本结构是一个数组,每个数组里存的是相同hash值的TString的链表
nuse: 当前实际的元素数。该hash里面有多少元素TString
size: 当前桶的大小,也就是该hash的大小
luaS_resize(): (短串被创建或者GC字符串时发现桶大于了4倍的元素数量减半)newSize > OldSize 先扩容,然后rehash 反之则先rehash 再减半
Lua为了实现内化STRING类,必然是需要在Lua虚拟机中有一个全局的地方去存放当前系统中的所有字符串,以便在新创建字符串时,能够自己内部查找和维护这个系统。
3、NewString
longStr: 是每次都创建一份 不管你是不是已经在内存中申请过,都直接走createstrobj函数
理由是因为长度过长 字符串哈希耗时会很长 并且字符串对比消耗也会比较大 因为Lua一般是游戏开发 长串字符串一般来说很难会有一模一样的
shortStr: 先去算hash值,然后去全局stringtable中查找。查到了直接用链表连起来。查不到,并且table的数量比桶还多,就对stringtable 进行ReSize(也就是LuaS_resize()函数)。然后创建对应的string 包括内存分配,字段填充。再去更新对应的stringtable。
这个重新分配的过程的目的 其实也是因为,如果一直用散列桶来装数据,那么数据量大的时候,每个桶装的数据就会非常多,整个过程就变成了线性的查找
这边有几个细节 稍微提一下
有一步是需要计算string的哈希值,这个时间会和string的大小有关的,所以Lua在计算哈希值的时候,不会逐位取计算,而是每个步长单位取一个字符就可以了,具体步长是(length>>5)+1
另外在GC的时候会判断是不是当前GC的对象,是的话需要重新改变状态然后重新引用。
调用luaC_newobj来创建一个GC对象,根据实际传入的内存大小来开辟空间
最后一个小tips是,大量的字符串拼接的时候 ,我们已经是消耗巨大的了 这个时候我们可以利用table.concat来实现字符串拼接。具体细节可以去查api。
三、TABLE
1、结构体
CommonHeader: 通用GC
gclist: GC的链表保存,用于垃圾回收
metatable: 元表
flags: 用于缓存该表实现了哪些元方法。
array: 数组头指针
sizearray: 数组部分的大小 只会是二次幂的大小,注意这里是int类型
node: 哈希表头指针
lastfree: 哈希表的尾指针
lsizenode: 哈希表的大小 只会是2次幂的大小,注意这里是byte类型。由于hash桶的存在,hash值相同的数据 会以链表的形式串起来,因此这边就算数量用完了也是没关系的
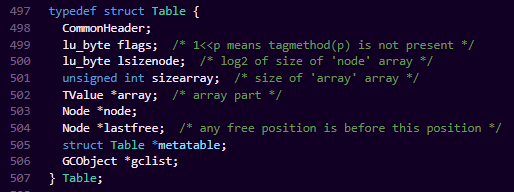
我们可以一个个来看
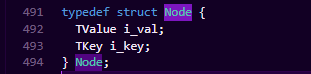
我们看到Node的类型定义,它包含两个成员,一个是表示结点的Key,另一个是表示结点的Value。
value部分就不用多说了,是通用的TValue结构。
我们来看下这个TKey
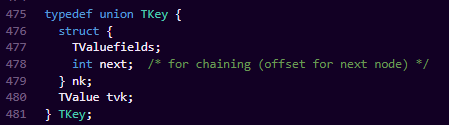
这是一个union结构,那我们是不是就很一目了然的能知道一件事情,就是Lua这边肯定是打算用这个字段表示多种用途,并存但互斥。
那这个时候 我们就能分析出一件事情,那就是Lua的table的Key值绝对不止储存一种结构,所以我们就很显然的能理解,lua的table能同时容纳数组和哈希的原因了。
2、内部实现划分
table分为数组部分 和 哈希部分
Lua的table中,分为数组部分和哈希部分。
然后我们增加几个理解上的概念:
a、整数键部分和非整数键(包括string和double)部分
b、连续键部分和非连续键部分
这个对于理解table来说 是非常好的两个引入概念
3、ReHash
两层理解
第一层理解为table内部,划分hash和数组;
第二层理解为hash部分的重新整理
第一层理解:(理解为table内部,划分hash和数组)
新建一个数组nums,长度初始化为MAXABITS+1(保证int值的范围能全部落进来);
然后根据当前键Key 所落区间(2^(i-1) < k <= 2^i)累加计数(这边有一个要注意的点是,每个区间的计数是累加+=的
详情可以去翻阅ltable.c的computesizes方法)
填充好nums数组以后,对nums数组进行翻新,但凡是某个子区间的填充率小于等于1/2的,那么后续整型Key都存储到hash表中去
注意这里抛弃掉的是后续整型Key,而不是当前区间的Key
第二层理解:(hash部分的重新整理)
上面抛弃掉的Key值和非整型key 会塞入hash部分进行hash桶的处理
详细可以看新增操作相关
4、查询操作(赋值会先查找后新增)
伪代码:
if type(key) =='int' then
if key < t.sizearray and key > 0 then
return t[key]
else
calcuHash(key) and return hash
end
else
calcuHash(key) and return hash
end
看key是不是int类型,肯定则判断是不是小于sizearray,是就直接返回
不是则算出hash值,找到hash桶所在的位置mainposition,遍历该桶的链表,找到该key为止。
查询找不到就返回nil
赋值如果找不到就会新增元素
5、新增操作:(luaH_newkey)
调用getfreepos(t) 查询当前table的freepos是否null
如果是 则调用rehash操作去拓容
如果不是,去找当前newkey的mainposition 看是否可用。
如果是,则直接使用并赋值
如果不可用,说目已经被占用,则去查找当前key的哈希值,看是否与占用的节点相同
如果相同 则直接插入,并将next指针指向当前key
如果不相同,我们可以认为,当前节点是该table在上一次hash的过程中为了节省hash桶而将该key挤到当前位置,那么我们可以将当前的节点key移到freepos中,然后让newkey入住。移出去的key一样的操作 先进行几次判断 最后进行放置
6、迭代操作
这边主要是实现了lua的迭代函数,他主要传入的 不是迭代器 而是一个Key
主要逻辑理解:
在数组部分查找,查找成功,返回Key的下一个数据
否则查hash,返回下一个数据,遇nil终止。
看起来好像很简单,但是这边有一个点提一下,在我们查询index的时候,会一开始就会走查询相关操作,所以我们可以保证一点就是
一个key只会独立在各自的数据结构中查找 而不会查找两遍
7、查询长度
首先理解一个概念,我们是会在t的序列部分进行查长度,而不是仅仅查询并返回当前数组部分的长度。
当然了 不管是不是返回数组的长度 我们都要肯定的一点就是 算长度的概念 仅仅是局限在int整型类型Key的部分中。
Lua查长度利用的是二分查找,每次二分,然后去判断 t[i]!=nil and t[i+1]!=nil,那么我们可以返回最大长度i
我们来举4毛钱的栗子看看啊
print(#{[1]=1,[2]=2,[4]=1,[8]=2,[16]=1,[24]=2,[28]=1,[30]=30})
print(#{[1]=1,[2]=2,[4]=1,[8]=2,[16]=1,[24]=2,[30]=30})
自己先判断一下 长度到底是多少?然后去问问代码结果是什么!思考一下为什么?你就会懂上面这段话了
四、虚拟机简单了解
我们先理解一下虚拟机的基本概念
虚拟机指借助软件系统对物理机器指令执行进行的一种模拟。
至少要完成以下工作:
1、将源代码编译成虚拟机可识别的字节码。
2、为函数调用准备调用栈。
3、内部维持一个IP(Instruction Pointer,指令指针)来保存下一个将执行的指令地址。在Lua代码里,IP对应的是PC指针。
4、模拟一个CPU的运行:循环拿出由IP指向的字节码,根据字节码格式进行解码,然后执行字节码。
类型区分:
1、基于栈的虚拟机
字节码的操作数是从栈顶上弹出,在执行完操作之后再压入栈顶。
比如 1+2=3 需要先pop1 然后pop2 然后调用add 最后输出结果3
优点是不需要关心操作数的地址,实现起来简单,移植性强。
缺点是指令数量多,数据转移次数多。
2、基于寄存器的虚拟机
操作数是放在“CPU的寄存器”中(不是物理的寄存器),字节码中带上具体操作数所在的寄存器地址
比如 1+2=3 直接在新的寄存器中保存相加的结果,一条指令就可以完成,但此时需要关注操作数所在的位置。
优点是指令少,数据转移次数少。
缺点是单条指令长度较长
Lua 在这里用的是基于寄存器的虚拟机,我们需要弄明白的几个核心点是:
1、设计一套字节码,分析源代码文件生成字节码。
2、在虚拟机中执行字节码。
3、如何在整个执行过程中保存整个执行环境。
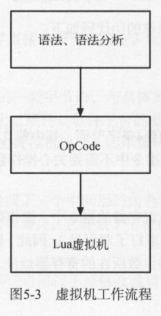
简单点概括 就是 源码->字节码生成->字节码执行 这一系列操作
Lua中实现doFile的操作是基于一个 lua定义的宏 先调用load 再pcall

luaL_loadfile :我们先不深究这个函数到底是怎么分析代码的,我们先看他return的是什么,它最终会调用具体的parser。
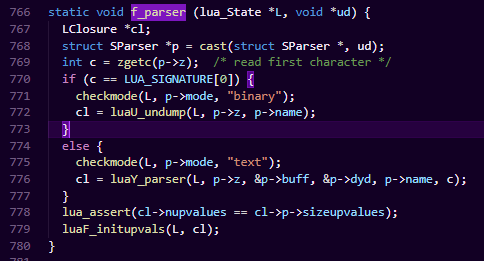
它会对lua文件进行进行词法和语法分析,把source转化成opcode,并创建Proto结构保存该opcode和该函数的元信息
Proto结构如下:
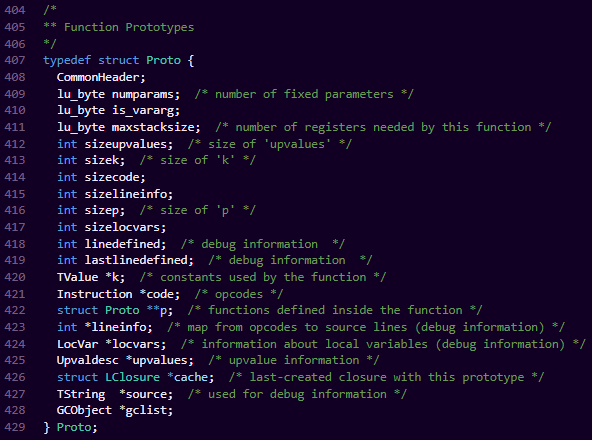
它主要涵盖了该函数的所有分析信息。主要包括:
1、常量表。
2、局部变量信息。
3、Upvalue信息。包含归属本函数栈还是外层函数栈
4、opcode列表。
lua_pcall:这个函数最终会调到luaD_call,也就是lua虚拟机里函数执行的主要函数。
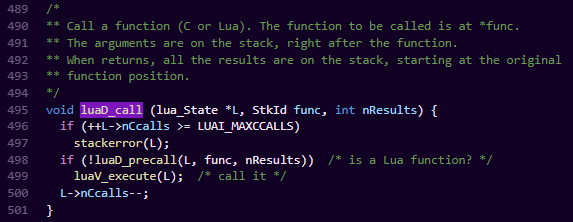
luaD_precall:
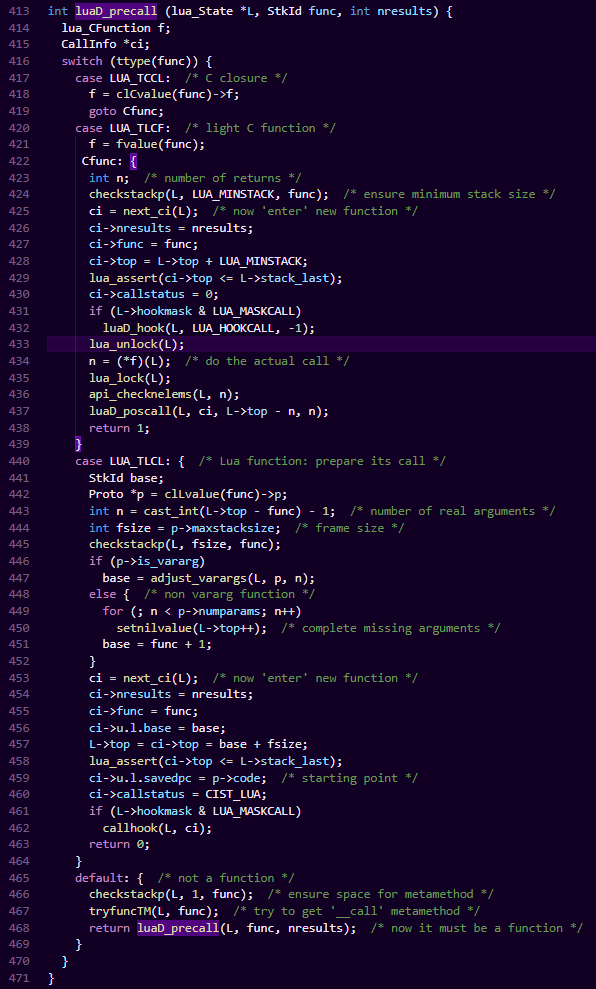
如果是C函数或者C闭包,会直接创建单个函数调用的运行时结构CallInfo,来完成函数的进栈和出栈。
如果是lua闭包,在precall中只会做函数调用前的准备工作,实际执行会在后一步luaV_execute中进行。这里的准备工作主要包括:
(1)处理lua的不定长参数、参数数量不够时的nil填充等。
(2)分配CallInfo结构,并填充该函数运行时所需的base、top、opcode等信息。
注意CallInfo结构里还有个很关键的func字段,它指向栈里对应的LClosure结构,这个结构为虚拟机后续执行提供upvalue表和常量表的查询,毕竟后续对常量和upvalue的read操作,都是需要把它们从这两个表中加载到寄存器里的。
luaV_execute:
这一步就是我们前面提到的lua虚拟机的CPU了,因为所有指令的实际执行都是在这个函数里完成的。它做的主要工作,就是在一个大循环里,不断的fetch和dispatch指令。每次的fetch就是把pc加1,而dispatch就是一个大的swtich-case,每个不同类型的opcode对应不同的执行逻辑。
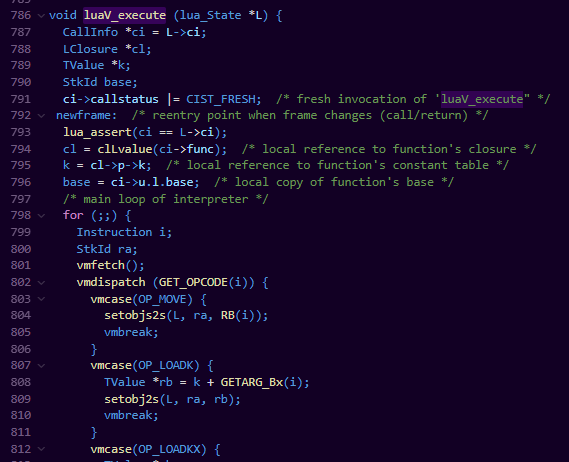
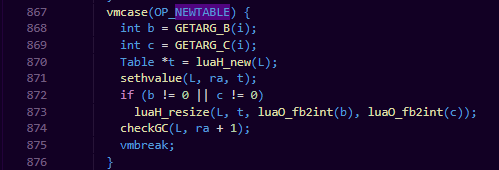
比如说我们看看当我们创建一张表的时候,我们能看到,lua会首先对32位指令进行位操作,得到该table的初始数组呵hash表部分的大小b和c,然后调用luaH_new来创建table,最后根据b和c的值,对table进行resize操作。
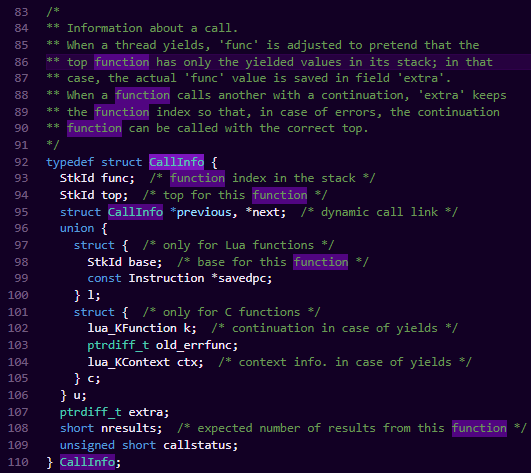
另外,前面提到的CallInfo结构,包含了单个函数调用,lua虚拟机所需要的辅助数据结构,它的结构如下:
下图是lua虚拟机在执行函数时的一个栈示意图:
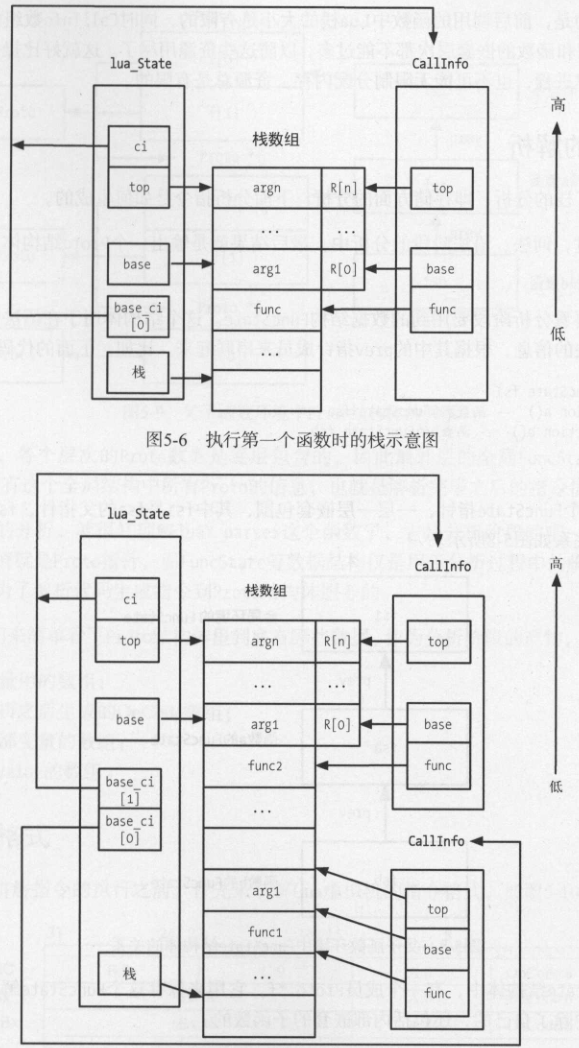
我们来看下lua_State里与之相关的几个字段:
stack。TValue* 类型,记录了"内存"起始地址。
base。TValue* 类型,记录当前函数的第一个参数位置。
top。TValue* 类型,记录当前函数的栈顶。
base_ci。当前栈里所有的函数调用CallInfo数组。
ci。当前函数的CallInfo。
可以发现,通过这样的组织结构,luavm可以方便的获取到任意函数的位置以及其中的所有参数位置。而每个CallInfo里又记录了函数的执行pc,因此vm对函数的执行可以说是了如指掌了。
在讲指令的执行之前,我们先来了解一个东西
Lua虚拟机的指令格式
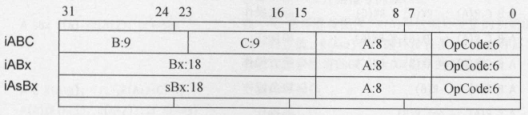
首先看到的是,Lua的指令是32位的
最低6位的OpCode,称为操作数,这边能看到操作数是6位的,也就是说,Lua最多支持2^6-1=63个指令,
紧跟着就是A、B、C、Bx、sBx参数。
参数的值通常指的是一个相对偏移,例如相对于当前函数base的偏移,相对于常量表头的偏移等
另外,根据指令的不同,参数个数和类型也可能不同。
我们来举几个常用的例子。
EX:从变量赋值
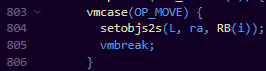
其实很简单的就是把寄存器RB(i)的值赋值到寄存器RA(i)中去,这里的寄存器指的就是我们栈里头的某个坑位,所以这里的RA和RB宏,都是一个栈地址获取操作。
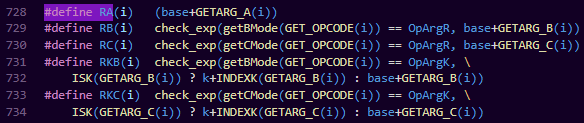
这些宏的内部实现主要分为2步:通过GETARG_XXX(i)从当前指令中获取参数XXX的值用函数base或者常量表base去加这个参数值得到最终的栈(寄存器)地址
EX:从常量赋值
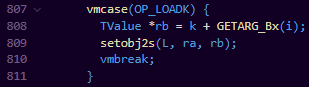
与变量赋值唯一的不同,就是RB是基于常量表的偏移。
EX:设置table字段
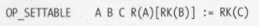
这里RK是一个条件宏,因为有可能是t[a]=b, 也可能是t[1]=b,key如果是变量a,说明a肯定是在函数栈里头的变量,对应的寻址就用RB,而如果key是1,说明它不存在函数栈里头,而是在函数常量表里头,寻址就用KB。
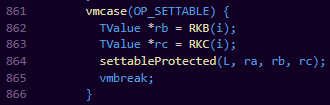
我们来看一个例子:
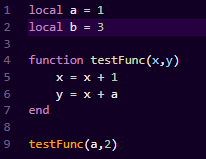
我们用ChunkSpy工具来反编译一下OpCode:
一个函数最终的字节码,基本就包含三块:常量表、upvalue表和code。所有的字节指令,都是在玩常量表、upvalue表和寄存器栈。
总结
虚拟机执行流程图
在梳理完整个lua虚拟机的源码分析,opcode的生成和执行逻辑以后,我们可以上书中的一个总流程图来回顾一下:
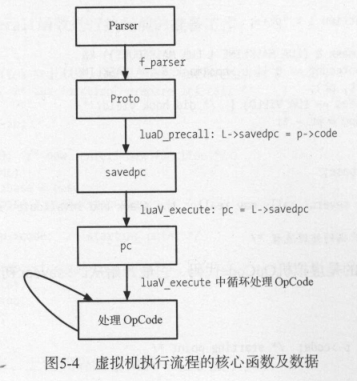
这个图中最核心的两块,一个是Proto结构,它是分析阶段和执行阶段的桥梁;另一个是OpCode的执行,这一块可以结合前面虚拟机概念,以及Stack-based和Register-based VM的区别一起理解,包括但不限于:从CallInfo里fetch指令,指令执行时的switch case跳转和操作数的寻址,运行时的栈帧布局,lua_State中的关键字段等等。
五、函数
函数闭包
首先,所有的lua函数,都是一个函数闭包。函数闭包是目前主流语言几乎都支持的一个机制,它指的是一个内部结构,该结构存储了函数本身以及一个在词法上包围该函数的环境,该环境包含了函数外围作用域的局部变量,通常这些局部变量又称作upvalue。
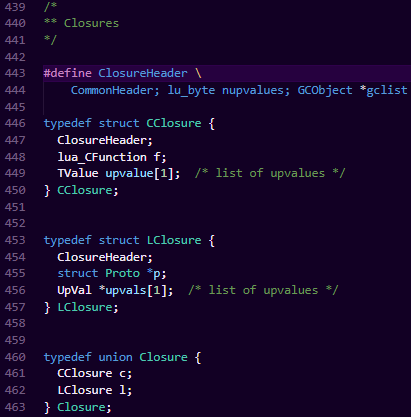
我们能看到Lua的函数闭包定义区分为了CClosure和LClosure两种类型,任意Lua的函数调用栈中的函数,无非也就是这两种类型。其中CClosure是指使用Lua提供的lua_pushcclosure这个C Api加入到虚拟栈中的C函数,它是对LClosure的一种C模拟,因此本文主要着重讲解最纯粹的lua函数实现,也就是LClosure。
LClosure
LClosure结构
主要由3部分构成:
ClosureHeader:跟GC相关的结构,因为函数与是参与GC的。
upvals:函数的upvalue指针列表,记录了该函数引用的所有upvals。正是由于该字段的存在,导致函数对upvalue的访问要快于从全局表_G中向下查找。
函数对upvalue的访问,一般就2个步骤:(1)从closure的upvals数组中按索引号取出upvalue。(2)将upvalue加到luastate的stack中。源码如下图:
Proto p:因为Closure=函数+upvalue嘛,所以p封装的就是纯粹的函数原型。该结构中封装了函数的很多基本特性,如局部变量、字节码序列、函数嵌套、常量表等。
Proto结构
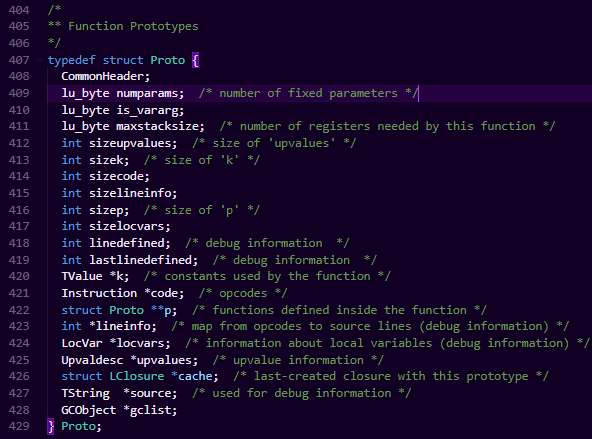
这里对其中牵涉关键特性的字段进行一个解释:
CommonHeader:说明Proto也是会走lua GC去释放内存的。
TValue * k:常量表。比如函数中定义的类似123,"test"这种字段,都会存储到常量表中,在虚拟机执行的时候,会从常量表加载到函数当前栈中来进行运算。
Instruction * code:该函数的实际执行字节码序列。每个字节码是经过encode的一个32位整型,该整数包含了操作类型和操作数地址等信息。关于字节码详情,可以参考专栏中的虚拟机篇。
Proto ** p:在该函数中定义的嵌套函数的原型数组。所以其实经过lua解析器解析过后,函数原型实际上呈现一个树状结构,详情可以参考第3节函数的定义和执行。
localvars、upvalues:注意这里的localvars和upvalues字段并不是指实际的局部变量和upvalue变量,而是在解析过程中生成的一些原信息,实际的局部变量是存储在函数栈中的,而实际的upvalue索引,上面介绍了是存储在LClosure的upvals字段中的。
函数的定义和执行
--TODO

 浙公网安备 33010602011771号
浙公网安备 33010602011771号