解决这两个世界级难题,自动驾驶就能够实现超进化?
引言
自动驾驶领域近几年来一直备受关注,但截止目前,自动驾驶在现实复杂场景下的大规模部署应用却一再延后。
其中一个很重要的原因是,目前业界对于动态和强交互性场景下的行为、轨迹预测问题(behavior prediction)始终没有得出很好的解决方案。缺乏对其他道路参与者的行为理解与预测,自动驾驶车辆便无法进行安全高效的决策、规划以及控制。
于是对于认知科学与行为预测的研究,成为了自动驾驶破局的关键。
1. 自动驾驶中的认知科学与行为预测问题
作为自动驾驶研究的重要细分方向之一,认知科学与行为预测问题吸引了大量专业人员的关注与研究。近年来,伴随着深度学习在自动驾驶领域的应用不断加深,行为预测的精度更是得到了大幅度的提升。
然而,现实世界中的驾驶场景极其复杂多样,不同的驾驶场景(高速、交叉路口、环岛等),无论是道路结构,还是驾驶模式都存在不小的差异。
从驾驶场景来看,当前的行为预测方法通过训练后可以在训练集内的场景中表现良好,但是一旦遇到一个全新的或者稍有差异的场景,模型的预测性能往往会崩溃或大幅下降。
通过上述行为预测方法训练出的模型,由于可迁移性/泛化能力(transferability/generalizability)的缺失,会极大地限制自动驾驶进行大规模部署应用。倘若需要针对每一个驾驶场景专门训练一个模型,可想而知开发成本会多么高昂。
除此以外,对真实驾驶环境中复杂多样的驾驶行为实现高效精准预测,也是一项不小的挑战。驾驶行为因人而异(heterogeneous) ,不同的驾驶员展现出的驾驶行为存在着较大差异,不同的驾驶员也有着不同的驾驶风格,有粗鲁莽撞的驾驶员,也有谨慎礼貌的驾驶员。
而目前的大部分预测方法,通过训练后仅仅能够预测出平均意义上的驾驶行为,却无法捕捉到驾驶员的个体差异。智能体对个体行为差异理解的缺失,将会始终制约行为预测的精度,因而自动驾驶行为的安全性也将难以得到保障。

针对以上两个问题,我们向大家介绍一种分层框架:
HATN(hierarchical,adaptable and transferable network)
此框架可在多智体密集交通环境中生成高质量的驾驶行为预测。
该方法从人类在驾驶过程中的认知模型和语义理解得到启发,对驾驶任务进行分层定义和并设计通用的环境表征,可以实现在不同驾驶场景上的迁移。此外,HATN方法还能通过在线适应模块捕捉个体和场景之间驾驶行为的变化。
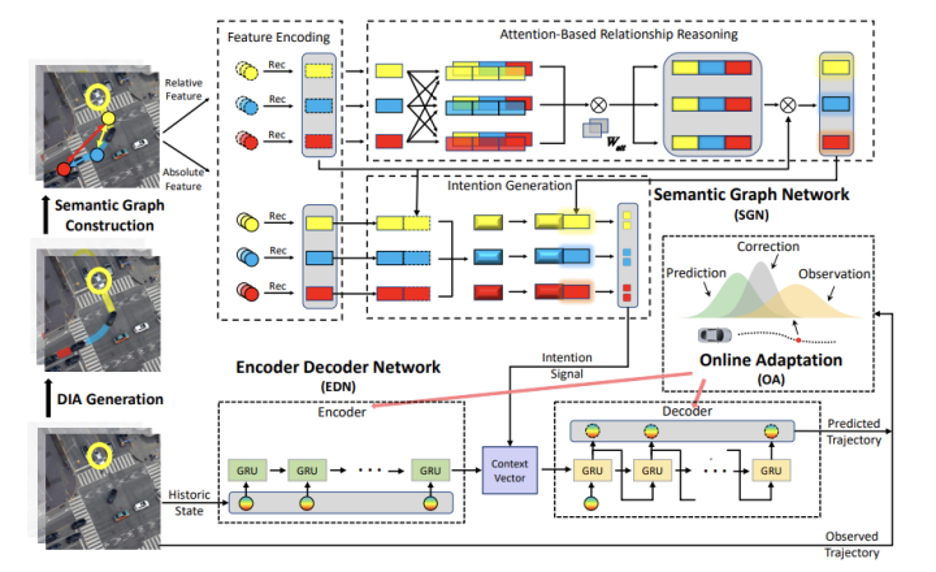
HATN行为预测框架由三部分组成:
-
负责上层意图决策任务的高级语义图网络(SGN);
-
一个底层编码器-解码器网络(EDN),根据历史信息和上层意图信号执行动作;
-
改进的扩展卡尔曼滤波器(MEKF)算法,执行在线自适应,实现更好的个性化定制和场景迁移。
下文将会围绕以下几个问题,对HATN展开详细的介绍:
-
如何实现预测模型在不同驾驶场景中的可迁移性?
-
如何使得预测模型能够自适应地捕捉驾驶行为的差异?
-
在对真实数据的预测任务中,可迁移性和自适应性预测性能有帮助吗?
![image]()
2. 如何实现预测模型在不同驾驶场景中的可迁移性?
相比起大多数预测算法在场景迁移中的无力,人类早已掌握了驾驶的精髓。当一个新手驾驶员在某一个驾驶场景练习驾驶时,他通过练习获得的驾驶经验以及驾驶技巧是可以迁移到其他场景上的。即使面对一个陌生的驾驶场景,人类依然能够复用以往的驾驶经验,毫不费力地驾驶车辆穿梭其间。
而现有的自动驾驶技术在面对陌生场景时的迁移能力与人类驾驶员之间仍然存在明显的差距。人类神奇驾驶能力背后所蕴含的认知和决策机制,自然而然地引起技术研究人员的好奇心。
受认知科学(cognition science)研究的启发,笔者观察到人类在密集的交通流和复杂的环境中之所以拥有强大的知识迁移能力,主要受益于两种认知机制:
1)分层结构(hierarchy):将复杂的任务分解为多个简单的子任务;
2)选择性注意(selective attention):在巨大的信息池中筛选识别出有效的、与任务相关的低维环境表征。
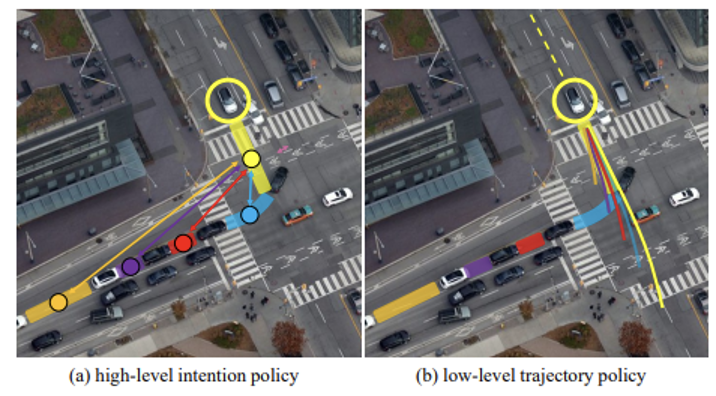
我们基于上述两种认知机制分析人类在驾驶过程中的驾驶行为,其决策过程是自然分层的。如图3所示,在上层的意图层面(high-level intention),人类开车时通常在做的一件事就是在不停寻找合适的“插入区域”。这些“插入区域”一般由车道线与道路参与者组成,在本文中将其称为Dynamic Insertion Area(DIA)。
文章的作者将每个DIA建立为一个结点(node),把所有节点进行有向连接便得到了一个语义图semantic graph。
在这样一个多智能体setting下的图表征中,车辆之间的交互行为由节点之间的连接edge所描述。而在底层的动作层面(low-level action),在决定了插入哪一个区域以后,人类将根据车辆当前以及历史的动力学状态,进行一系列的底层动作以实现目标。
从具体的方法上来看,文章中所提出的分层行为预测框架主要分为以下几个步骤:
1) 从环境中抓取动态插入区域(dynamic insertion area),并构建语义图(semantic graph)作为环境的一种通用表征(generic representation)。
2) 提出语义图网络(semantic graph network,SGN),对语义图中各个车辆之间的交互行为进行理解推理,预测出每个车辆未来将要插入的区域,以及所需要的时间以及行驶路程。其数学表示以及loss设计为:
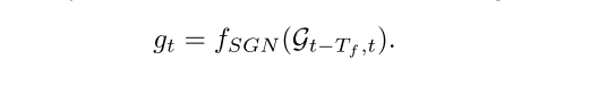
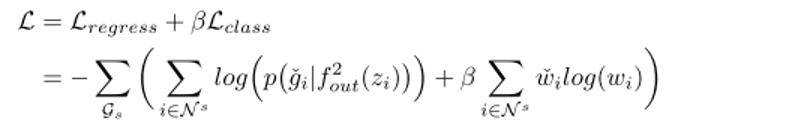
3) 提出编码解码网络(encoder decoder network,EDN),在预测出的意图intention基础上,对每辆车未来具体的行驶轨迹进行生成预测。其数学表示以及loss设计为:
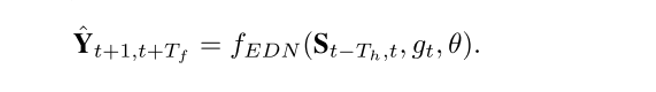
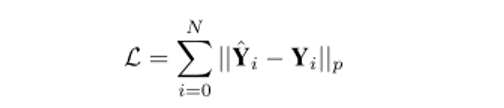
这种分层的任务划分方式,不仅大大降低了学习难度,也通过对于每一个子任务(sub-task)选取通用的环境表征,使得各个子策略(sub-policy)可以跨场景地泛化学习。
3. 如何使得预测模型能够自适应地捕捉驾驶行为的差异?
人类行为天然是异质的、随机的和随时间变化的(heterogeneous, stochastic, and time-varying)。不同的驾驶场景也会产生不同的驾驶模式(driving pattern)。捕捉驾驶行为的个体以及环境差异,有益于进一步提升预测方法的精度以及泛化能力。因此,文中使用一个在线自适应模块(online adaptation)将个体以及场景的差异注入模型当中。
在线自适应的原理是,虽然人类驾驶员之间不能够直接进行沟通与交流,但其历史的驾驶行为(historic behavior)暴露了其个体的驾驶特点。通过挖掘历史行为中的线索,我们可以对模型参数进行微调,以更好地贴合个体的驾驶行为。
具体而言,本文使用了改进的拓展卡尔曼滤波(Modified Extended Kalman Filter, MEKF)以对模型参数进行在线更新。我们将模型参数视为想要估计的state,预测出的历史轨迹作为prediction,观察到的历史真实轨迹作为observation,对模型参数进行最优估计。其数学表示如下:
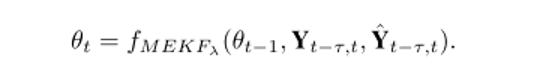
4. 实验验证
本文在真实的人类驾驶数据集INTERACTION DATASET中对所提出的方法进行验证,以测试所提出方法的预测精度,迁移能力,以及自适应能力。该论文中对每个模块进行了大量的ablation study以寻找最优的模型结构,数据表征,以及超参数,本文简略地介绍案例分析以及性能比较。细节实验请参考文章末尾列出的原文。
4.1 案例分析
首先,本文给出三个案例分析以展示预测效果:
1)一次交互:在交叉路口中,自车与其他车辆交互,通过共同的冲突点(conflict point);
2)系列交互:在交叉路口中,自车与其他车辆交互,通过一系列冲突点;
3)场景迁移:将自车直接迁移到环岛场景,自车与其他车辆交互,通过冲突点。
🌟重要注释:
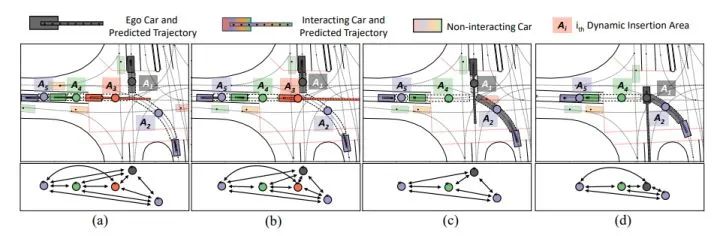
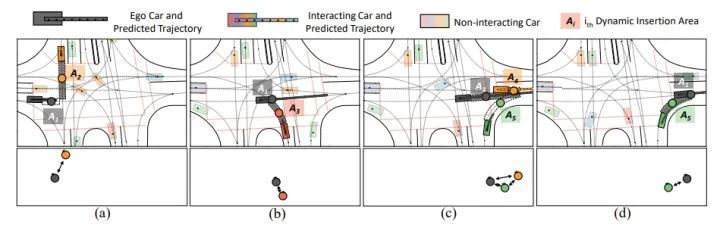
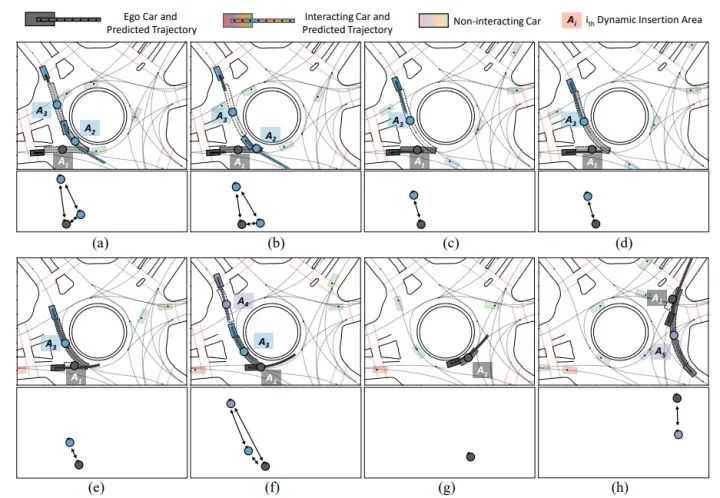
在下方图4/5/6中,黑车代表自车;透明色车表示非交互汽车;鲜艳的汽车表示与自车交互的车辆。每个提取出的DIA用虚线和一个节点标记。同一个DIA的节点与其队形的后方车辆使用相同的颜色。每一个场景的语义图如每个场景图下方所示。每个DIA颜色越暗,自我汽车越有可能插入该区域。预测出的自车及其交互车辆的未来最可能轨迹于每辆车的颜色相同。
案例1 一次交互
在本次交互中,在 (a)(b) 时,自车首先让出红色汽车,然后在 (c)(d) 中的其他汽车之前通过。
案例2 系列交互
本文方法可以不断识别交互的车辆,并提取可插入区域。自车首先在(a)中与黄车交互,然后与(b)中的橙车交互,最后和 (c)(d) 中的绿色和橙色汽车交互并驶出交叉路口。
案例3 场景迁移
在交叉路口场景中训练后,本文的方法可在无需额外训练的情况下,直接迁移到环岛场景中。自车首先在(a)(b)中对右侧的蓝色汽车让车,然后在(c)(d)(e)(f)抢在上方的蓝色汽车之前通过 。值得一提的是,由DIA的颜色深浅所示,本文的方法捕获了人类的犹豫和意图转换。自车随后继续在 (g) 中独自行驶,并在 (h) 中紫色车前离开环岛。
4.2 性能比较

我们在图7中,将所提出方法与传统的Rule-based方法,以及Learning-based方法进行了多个场景,多个metric,以及多个horizon下的细致比较。
其中包含了Grip++以及Trajectron++两种近两年的SOTA方法。根据图7的数据,我们可以看出,该论文提出的HATN性能明显超越了其它方法,尤其是在长期(long horizon 3s)的行为预测上,在各个metric与场景下相比Trajectron++性能提升了30%-50%。
参考文献
[1] Conference Version: Letian Wang, Yeping Hu, Liting Sun, Wei Zhan, Masayoshi Tomizuka, Changliu Liu. "Hierarchical Adaptable and Transferable Networks (HATN) for Driving Behavior Prediction". Neurips 2021 ML4AD.
[2] Extended Version: Letian Wang, Yeping Hu, Liting Sun, Wei Zhan, Masayoshi Tomizuka, Changliu Liu. "Transferable and Adaptable Driving Behavior Prediction". arXiv preprint arXiv:2202.05140.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号