美团新模型背后:一项关于“代码切换”的发现将多语言训练效率提升20倍

在一场由数据、算力和算法共同驱动的AI技术革命中,一个根本性挑战始终制约着大型语言模型(LLM)的全球化进程:预训练数据中“极端”的语言失衡 。当高质量的英文语料以TB甚至PB级别存在时,高质量的中文及其他语言数据却极度稀缺。这引出了一个核心问题:在数据配比可能高达100:1的悬殊背景下,LLM是如何实现跨语言知识迁移,并获得强大的多语言能力的?
近期,美团的研究团队发表了一篇名为《Investigating and Scaling up Code-Switching for Multilingual Language Model Pre-Training》的论文,系统性地回答了这一问题 。他们不仅揭示了“代码切换”(Code-Switching)这一语言现象在其中扮演的关键角色,更提出了一套能将特定训练效率提升 20倍的合成数据策略。
在此过程中,由OpenCSG社区构建并开源的Chinese-FineWeb-Edu-v2数据集,凭借其独特的、经过精心治理的数据特征,成为了这项研究得以启动和验证的关键基石 。
面临的挑战
美团团队的核心挑战是,在模拟真实世界数据稀缺性的前提下,精准拆解并量化影响LLM跨语言能力的关键因素:
归因困境:LLM的跨语言能力究竟从何而来?是共享的词元、模型架构的内在泛化性,还是数据中某些未被发现的特定模式?在庞大而混杂的预训练数据中,要分离出决定性变量极为困难。
效率瓶颈:在低资源语言(如中文)数据有限的情况下,如何最高效地提升模型在该语言上的性能?传统的“堆数据”方法不仅成本高昂,而且在高质量数据稀缺时根本不可行。
机制缺失:要提升跨语言能力,就需要促进不同语言在模型内部表示空间中的对齐(Alignment)。但如何通过数据工程的手段,系统性地、可控地增强这种对齐,业界尚无明确答案。
解决方案:从实证分析到规模化合成的系统性研究
为了应对上述挑战,美团团队设计了一套严谨的多阶段研究方案,其成功离不开对高质量数据源的敏锐洞察和深度利用。
理论突破:识别并解构“代码切换”的关键作用
美团的研究始于一个基础性假设:数据中连接不同语言的“桥梁”,是实现知识迁移的关键。他们将目光锁定在“代码切换”这一普遍但常被忽视的语言现象上。 技术细节:
精准分类:团队首先对代码切换进行了系统性分类,将其划分为“句子级”和“词元级”,每类又细分为“标注型”(Annotation)和“替换型”(Replacement)。

机制洞察:通过后续实验,团队发现“替换型”比“标注型”更能促进知识迁移。他们推测,这是因为“替换型”迫使模型主动将一个语言的词元整合到另一个语言的语境中进行理解,而“标注型”仅仅是并列呈现,模型的学习过程相对被动 。这一洞见为后续的合成策略指明了方向。
实验验证:高质量开源数据成为研究的“发现平台”
理论的验证离不开数据。美团团队需要一个富含自然代码切换现象的语料库作为研究的起点。 OpenCSG的角色:
一个惊人的发现:团队在对比多个高质量语料库后发现,以英文为中心的FineWeb-Edu数据集中,包含中英代码切换的文档比例仅为0.4%。然而,在OpenCSG的Chinese-FineWeb-Edu-v2数据集中,这一比例竟高达51.6%!
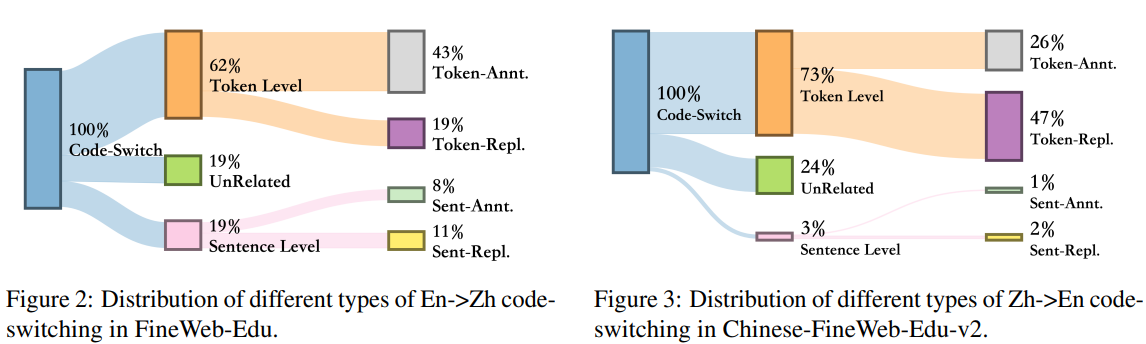
理想的“天然实验室”:这一悬殊的数据差异,使得Chinese-FineWeb-Edu-v2成为了分析代码切换现象独一无二的“富矿”。它为美团提供了足够丰富和多样的样本,使其能够进行细致的分布统计和类型分析,从而验证了代码切换现象的普遍性和重要性。
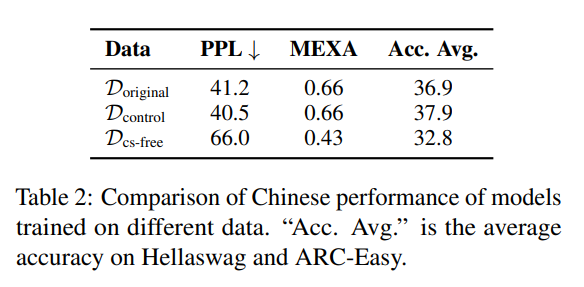
关键的消融实验:基于这些发现,团队进行了一项至关重要的消融实验。他们构建了一个移除了所有代码切换文本的数据集(D_cs-free),并用其训练模型。结果显示,模型的中文性能出现了“断崖式下跌”,多项指标显著恶化(如MEXA对齐分从0.66降至0.43)。这个实验无可辩驳地证明了,
自然代码切换是模型跨语言能力的关键来源之一。
工程飞跃:合成代码切换(SynCS)与后续扩展
既然自然代码切换如此重要,那么能否通过人工合成的方式将其效果规模化放大?这便是美团研究的核心创新。 技术细节:
SynCS合成管线:团队构建了一套低成本、高效率的合成管线。他们首先使用GPT-4o-mini生成少量高质量的种子数据,然后通过数据蒸馏的方式,微调了一个小模型(Qwen2.5-3B-Instruct),使其能够低成本、大规模地生成高质量的代码切换文本 。
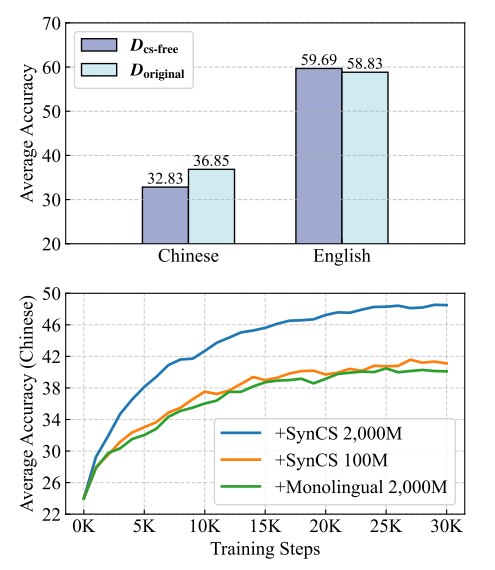
规模化扩展实验:团队在100:1的极端不平衡数据上,向高资源语言(英语)数据中逐步增加合成的中文代码切换词元。实验结果极为震撼:
20倍效率增益:仅添加1亿词元的合成代码切换数据(+SynCS 100M),对模型中文能力的提升效果,就足以媲美甚至超越添加20亿词元纯中文单语数据(+Monolingual 2,000M)的效果 。
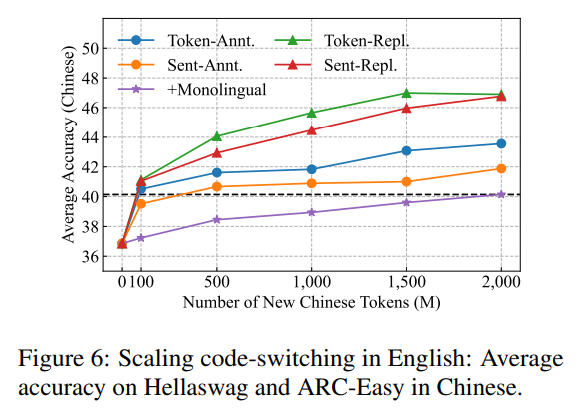
寻找最优混合策略:团队进一步探索了不同类型SynCS数据的混合策略。实验发现,将表现最好的两种“替换型”代码切换(En-Token-Repl. 和 En-Sent-Repl.)进行等量混合,能达到最佳效果,优于任何单一类型或简单的平均混合策略,证明了不同类型之间存在互补促进作用。
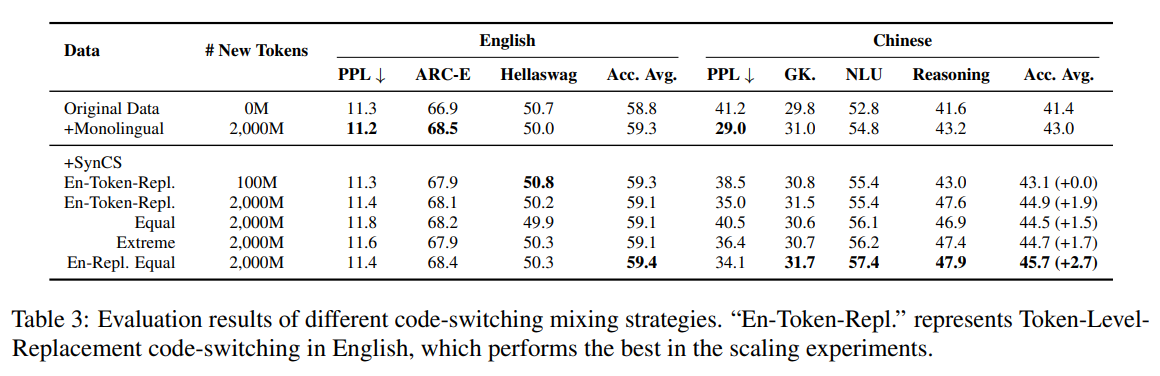
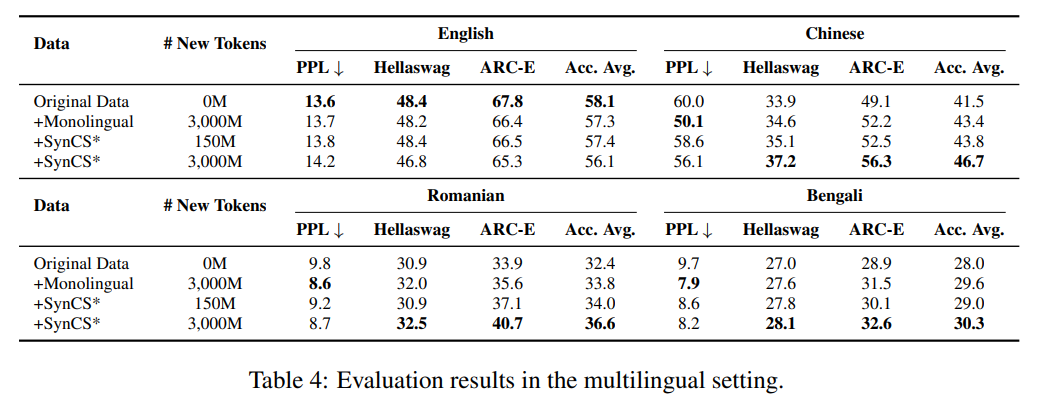
多语言泛化验证:为了验证该方法的普适性,团队将SynCS策略扩展到中等资源语言(罗马尼亚语)和低资源语言(孟加拉语)。结果表明,SynCS在这些语言上同样显著优于添加等量单语数据,证明了其强大的跨语言泛化能力。
下游任务赋能:最终,研究证明了这种预训练阶段的改进能直接赋能下游应用。与使用单语数据训练的模型相比,使用SynCS预训练的模型在翻译和零样本跨语言迁移(ZS-CLT)任务上均取得了显著更优的性能,证明其构建了更强大的跨语言基础能力。
背后功臣:OpenCSG Chinese-fineweb-edu 的构建之道
美团研究的成功,尤其是其初期发现和验证阶段,与Chinese-fineweb-edu-v2数据集的卓越品质密不可分。高达51.6%的代码切换率并非偶然,而是OpenCSG一套严谨、科学的数据治理流程的必然结果。
技术细节:
系统化的数据源聚合:
Chinese-fineweb-edu并非单一来源,而是系统性地整合了Wudao、Skypile、CCI等多个主流中文开放语料,确保了源数据的多样性和覆盖面。
基于先进模型的自动化打分:
技术核心:OpenCSG创新性地使用了一个基于Qwen2.5-14b-instruct微调的打分模型,对每一份文本的“教育价值”(educational value)进行0-5分的量化评估。
严谨的打分标准:其评估Prompt极为详尽,从内容的教育价值、连贯性、深度、结构化程度等多个维度进行考量,确保了打分体系的科学性和一致性。
结果导向的过滤:只有得分高于3分的高价值样本才被保留。OpenCSG的实验表明,在原始混合语料中,仅有约17.5%的样本能达到此标准,这体现了其筛选的极致严格。
高效的去重技术:
采用Min-Hash算法,以0.7的重叠阈值进行去重,在保证数据多样性的同时,极大地提升了计算效率。
解决的挑战:正是这套以“教育价值”为核心的筛选流程,天然地富集了大量科技、学术和专业领域的文本。在这些文本中,为了解释外来术语、引用前沿概念,中英代码切换是一种极其自然和普遍的表达方式。因此,OpenCSG无心插柳地构建了一个研究该现象的完美数据集,为美团的后续研究铺平了道路。
从社区到产业基石:OpenCSG 的核心影响力
美团的这项前沿研究,仅仅是OpenCSG高质量数据集赋能整个AI生态的一个缩影。通过持续构建和开放高质量、可复现的中文语料,OpenCSG不仅是一个数据提供方,更已成为驱动中国乃至全球AI发展不可或缺的“数字基建”。其核心影响力体现在多个维度:
- 奠定行业基石,确立标杆地位
OpenCSG的中文预训练数据集已成为事实上的行业标准之一,其全球下载量稳居中文预训练数据集前三。其卓越品质不仅支撑了像Llama3-Chinese、DeepSeek等众多知名模型的训练,更因其严谨的构建方法和可靠的性能表现,被包括斯坦福大学、清华大学在内的全球超过20家顶尖学术机构的论文所引用,成为衡量和推动大模型研究的基准。
- 获得顶尖机构的广泛认可
OpenCSG的价值得到了学术界和工业界的双重认可。在学术领域,除了斯坦福和清华,中国人民大学高瓴人工智能学院、上海人工智能实验室(Shanghai AI Lab)、北京智源研究院(BAAI)等国内顶尖科研力量均在研究中采用了OpenCSG的数据。在产业界,其影响力同样深远,面壁智能(ModelBest)、中国移动、中国联通等行业巨头,乃至英伟达(NVIDIA)这样的全球技术领导者,都已将OpenCSG的数据集应用于其模型研发和应用中。
- 催化繁荣的开源生态
高质量的基础资源是创新的催化剂。OpenCSG的开放数据集不仅被用于模型预训练,更激发了社区的二次创新活力。基于其语料,社区已衍生出超过10个针对医疗、法律、金融等领域的垂直微调模型,将通用大模型的能力精准赋能于各行各业。同时,围绕其数据,社区自发催生了30多个GitHub开源项目,涵盖了数据清洗工具、模型评估框架等,极大地丰富和完善了中文AI的工具链。
- 经过大规模、高强度的实践验证
社区的广泛采用是对数据集质量最有力的证明。OpenCSG的数据集月下载量稳定破万次,日均数据请求高达数千次。其数据套件总计体量达到2.42TB,覆盖9.57亿条高质量文本,并通过集成13项细分数据集,形成了一套完整的中文训练解决方案。这种规模化的验证,确保了其在真实、多样的应用场景下的稳定性和有效性。
开放、高质量的数据是通往通用AI的基石
美团与OpenCSG的成功合作为中文AI开源社区树立了典范。它雄辩地证明,在算法和模型日益趋同的今天,数据,尤其是经过精心治理的高质量数据,正成为驱动AI创新的核心引擎。随着OpenCSG语料库的不断迭代,以及更多像美团这样的顶尖团队的深入研究,一个由开放、协作和高质量数据共同驱动的良性创新循环正在形成,持续推动着AI技术的边界。
下载链接
数据集链接:https://opencsg.com/datasets/AIWizards/Fineweb-Edu-Chinese-V2.1
模型链接:https://opencsg.com/models/AIWizards/LongCat-Flash-Chat

 浙公网安备 33010602011771号
浙公网安备 33010602011771号