第一次个人编程作业
| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 完成一个论文查重系统,并学会使用Git、JProfiler、JUnit等工具 |
| 作业的GitHub地址 | |
| 一、PSP表格 | |
| ==== | |
| PSP2.1 | Personal Software Process Stages |
| :-- | :-- |
| Planning | 计划 |
| Estimate | · 估计这个任务需要多少时间 |
| Development | 开发 |
| Analysis | 需求分析 (包括学习新技术) |
| Design Spec | 生成设计文档 |
| Design Review | 设计复审 |
| Coding Standard | · 代码规范 (为目前的开发制定合适的规范) |
| Design | 具体设计 |
| Coding | 具体编码 |
| Code Review | 代码复审 |
| Test | 测试(自我测试,修改代码,提交修改) |
| Reporting | 报告 |
| Test Repor | 测试报告 |
| Size Measurement | 计算工作量 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 |
| Total | 合计 |
| 二、模块接口的设计与实现 | |
| ==== |
(一)读写文件模块
在main方法中提取数组参数args,来获得在命令行输入的文件地址。再用简单的IO接口即可实现。此处需要注意与cmd的编码是否一致,若不一致,需要在输入的时候转换编码。
(二)文本过滤
为了让文本更好地进行分词操作,需要对文本进行过滤。主要是用Jsoup来过滤html标签,再利用String的replaceAll方法与正则表达式过滤无关内容。
(三)核心算法(SimHash)
1、算法思路
将原始文本映射为64位二进制数字串(因此选择了BigInteger,BigDecimal更高精度的类),然后通过对比两文本映射后的数字串的差异来计算相似度。
2、具体步骤
1、分词。把文本分解出多个关键词,并为每个关键词加上权重。在本项目中,我用Jsoup类等对文本进行过滤后,再用StandardTokenizer类对文本进行分词,同时该类会根据每个词的词性来进行赋权。
2、计算hash值。通过hash算法,为每个分词赋予一个hash值。
3、加权。在得到分词的hash值后,需要按照分词的权重形成加权数字串。比如“计算机”的hash值是“100101”,权重为5,通过加权得到“5 -5 -5 5 -5 5”。
4、合并。在每个分词都进行加权运算后,把得到的值相累加,得到一个数字串。比如“计算机”加权后的值是“5 -5 -5 5 -5 5”,“键盘”加权后的值是“4 -4 -4 4 -4 4”,两次通过合并运算后得到“9 -9 1 -1 1 9”。
5、降维。在所有分词都进行合并运算后,把得到的值变成01串。每一位如果大于0,则该位变为1,否则为0。
经过以上步骤,就能得到一份文本的SimHash值。
3、具体代码
//计算simhash值
public BigInteger simHash(String content) {
content = cleanWords(content);
setWeight();
//content内各关键字权值数组,用于合并运算
int[] array = new int[hashBits];
//把内容进行分词操作
List<Term> terms = StandardTokenizer.segment(content);
for (Term term : terms) {
//判断该分词是否该被过滤
boolean flag = wordFilter(term);
if (flag == true) {
continue;
}
//计算关键词的哈希值
BigInteger hash = hash(term.word);
//关键词的权值
Integer weight = natureWeight.get(term.nature.toString());
if (null == weight) {
weight = 1;
}
//加权与合并操作
addWeight(hash, weight, array);
}
//降维操作后返回simHash值
return subDimension(array);
}
(四)计算相似度
两文本在经过以上步骤后,得到各自的SimHash值。若两者内容相似,则SimHash值也相近,两者相除即可得到相似度。
//文本对比
public String compare(String content1, String content2) {
BigDecimal simHash1 = new BigDecimal(simHash(content1));
BigDecimal simHash2 = new BigDecimal(simHash(content2));
BigDecimal result;
//较小的simhash作为被除数,较大的作为除数,商即为相似度,越接近1越相似。
if (simHash1.compareTo(simHash2) > -1) {
result = simHash2.divide(simHash1, 4, RoundingMode.HALF_UP);
} else {
result = simHash1.divide(simHash2, 4, RoundingMode.HALF_UP);
}
return result.toString();
}
三、性能分析 ====   **能改进的地方:**计算的准确度还有待提高。
四、单元测试 ==== ##1、测试过滤 
2、SimHash计算测试
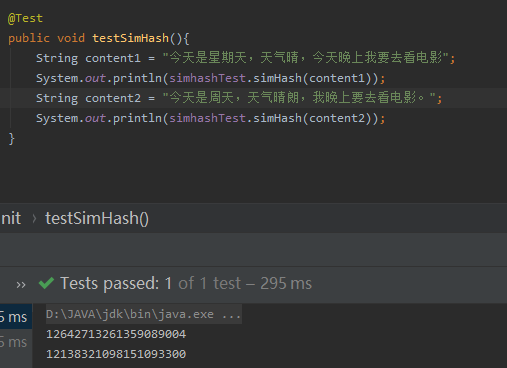
3、文本相似度测试
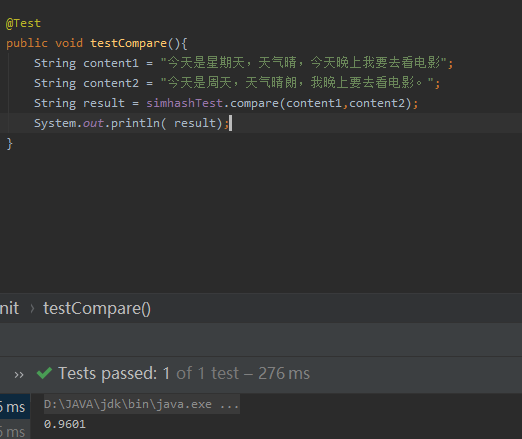
4、异常处理测试
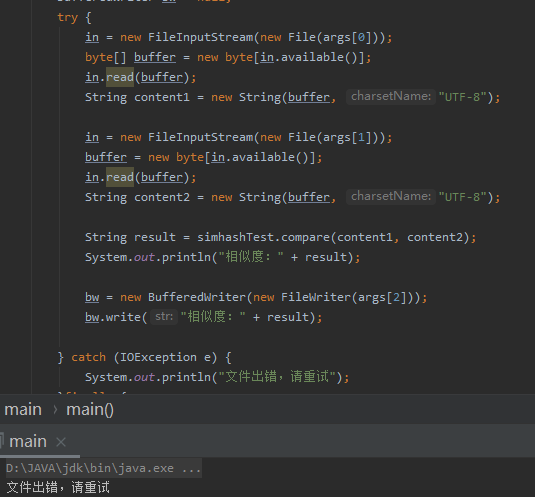
五、异常处理 ==== 主要是输入和输出文件时进行IO操作时容易出现IOException,比如输入了不存在文件地址或者文件正在被访问。在该部分用try-catch即可解决。 
个人心得 ==== 这份作业难点主要是在算法上。一开始我自己也想过很多算法,但都过于复杂而不能实现。这份代码参考了别人的项目,有些部分实在不懂(hash的算法),就照着写一次,虽然仍有地方不太懂,但照着写了一遍感觉很多地方都想通了。而且在这次作业中,我也学到了一些工具的使用,能为我今后的学习带来很大的便利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号