Hadoop复习(4) Spark
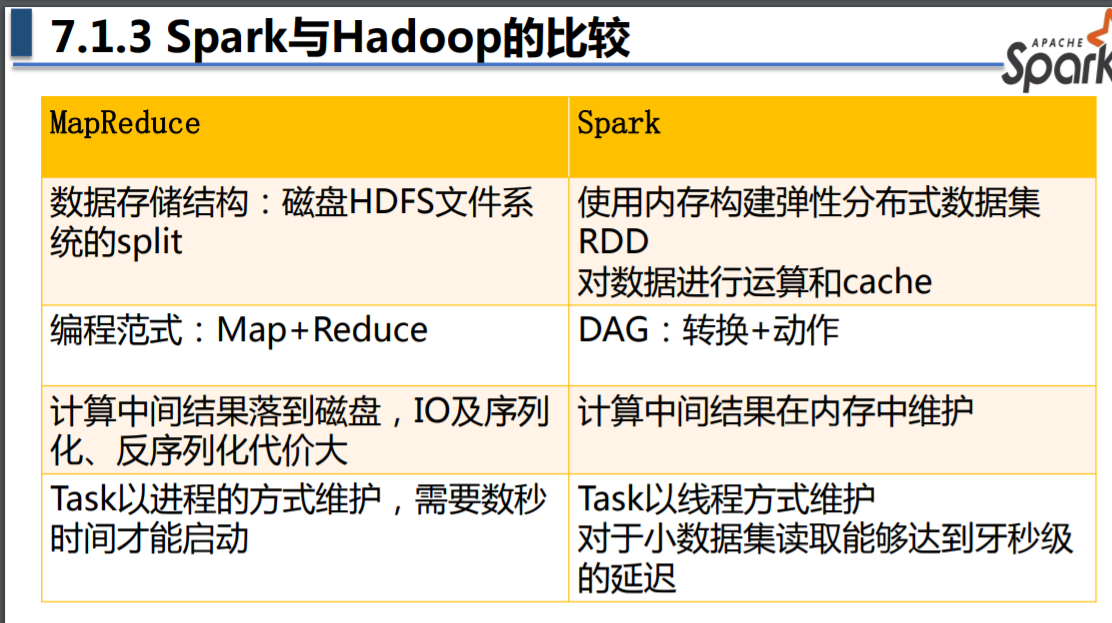
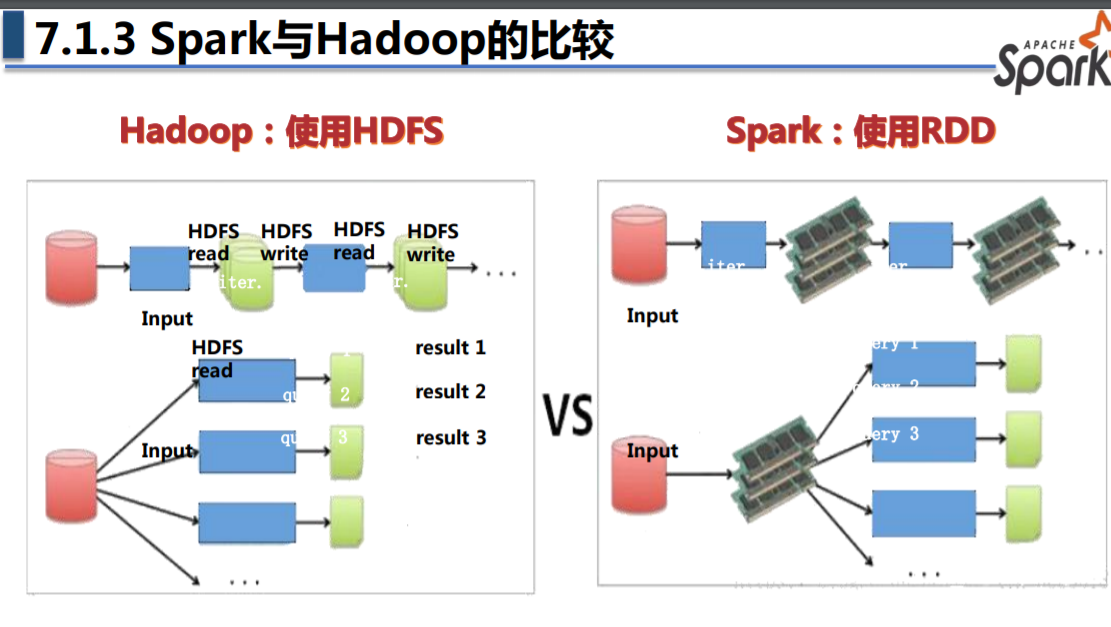
Spark 与 MapReduce 的主要区别
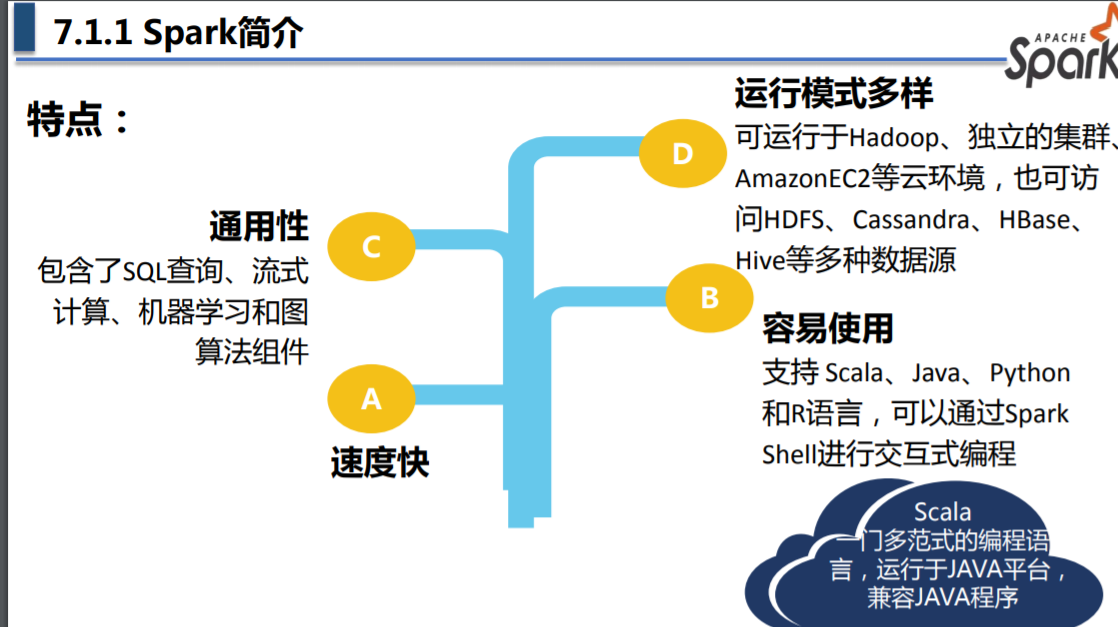
Spark 特点
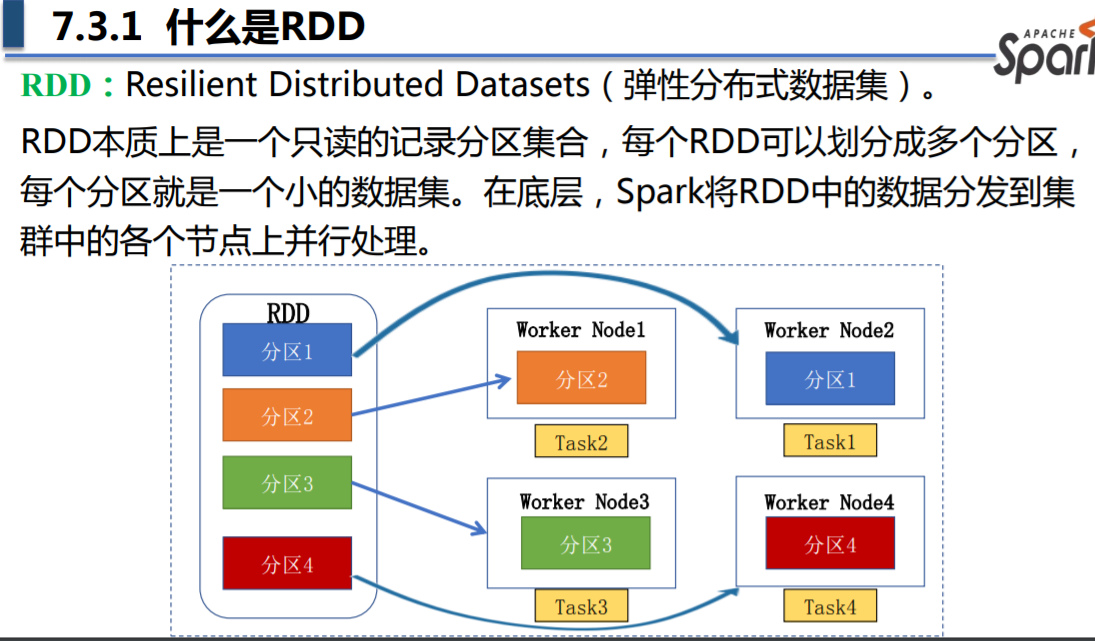
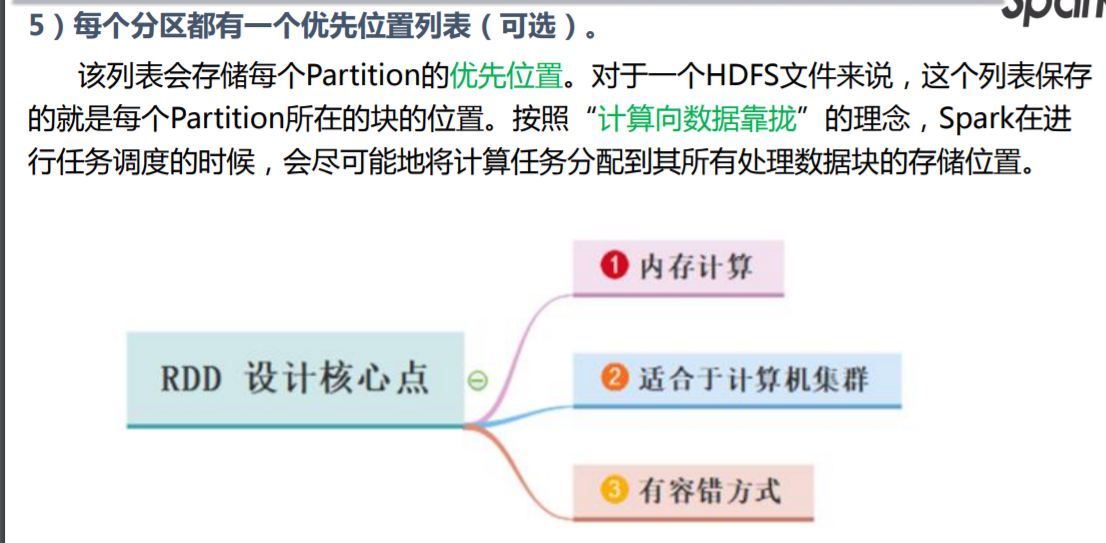
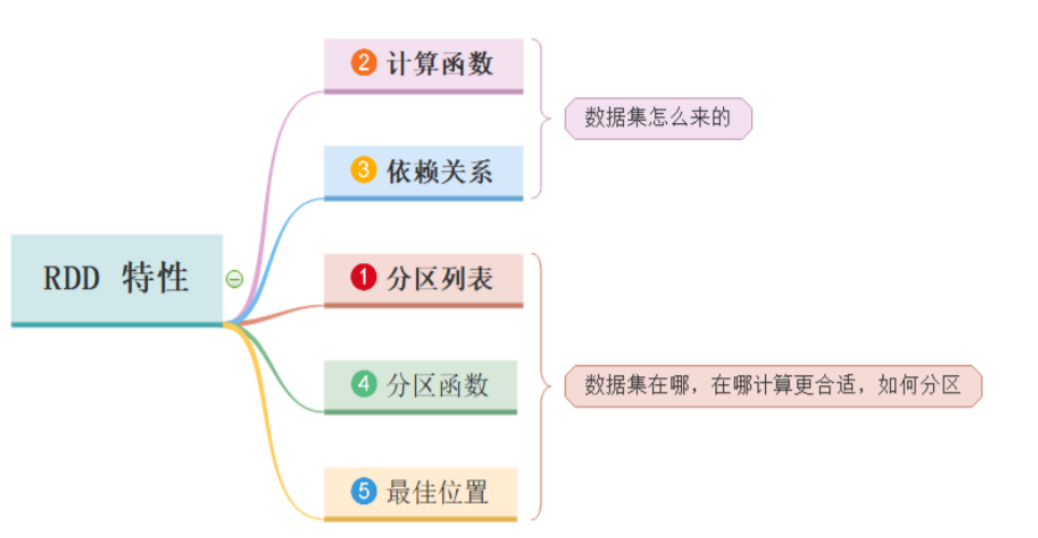
什么是 RDD(重点)



创建RDD


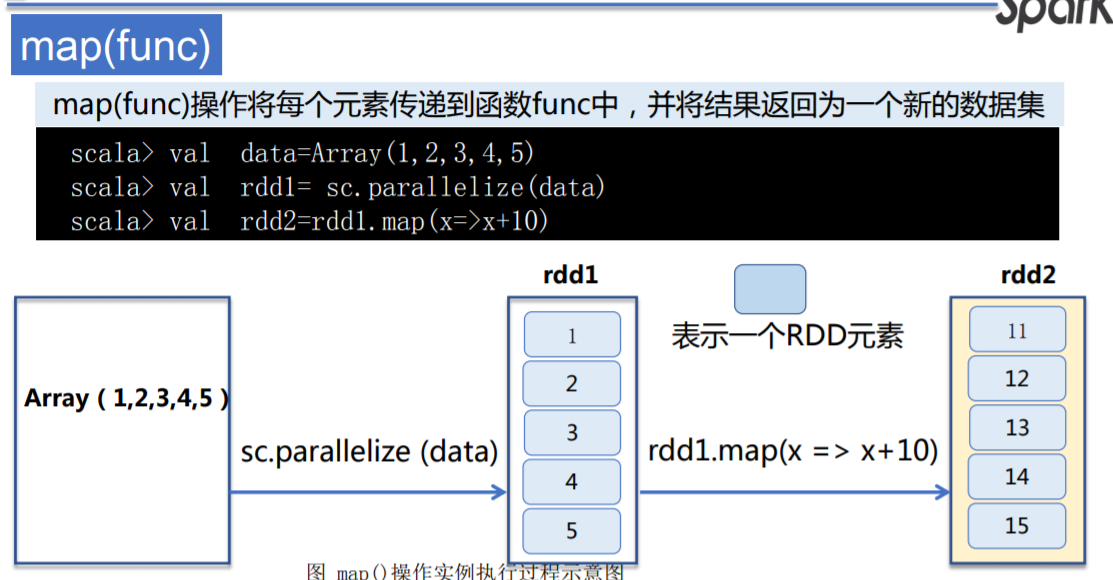
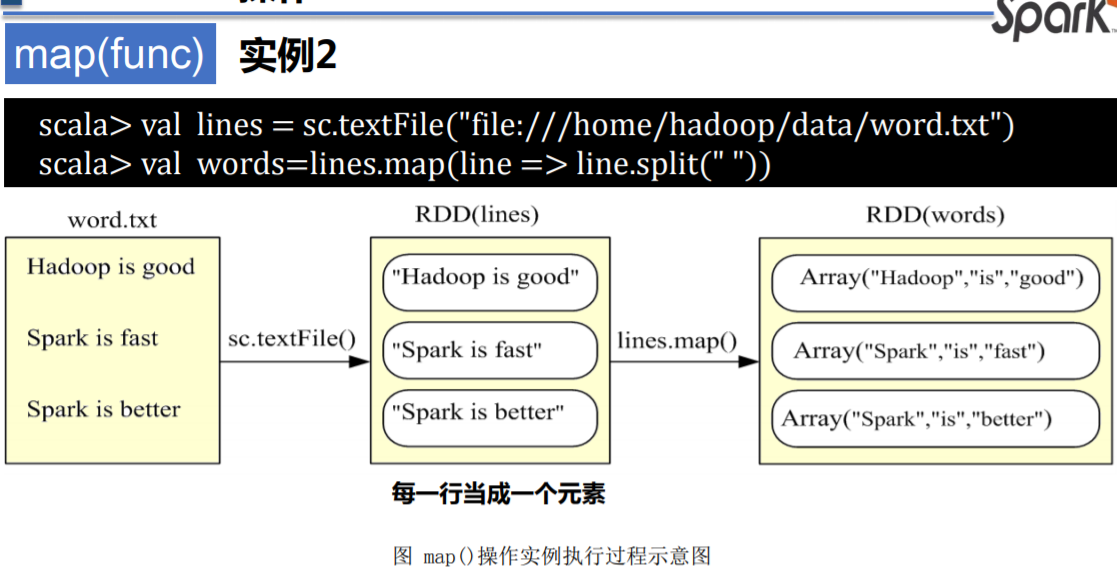
RDD map
flatMap(func)
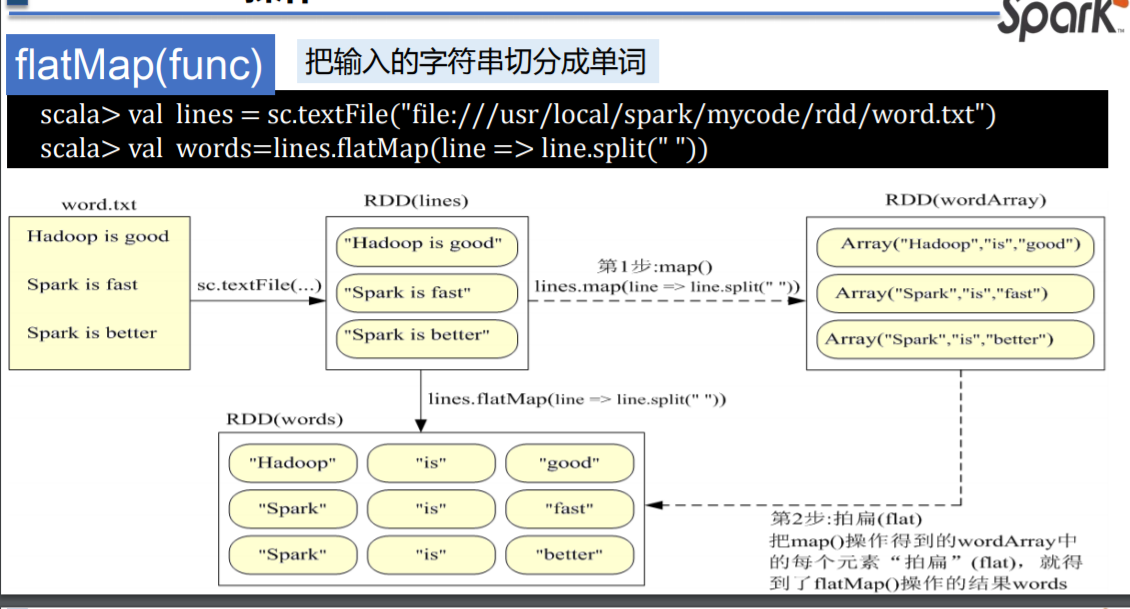
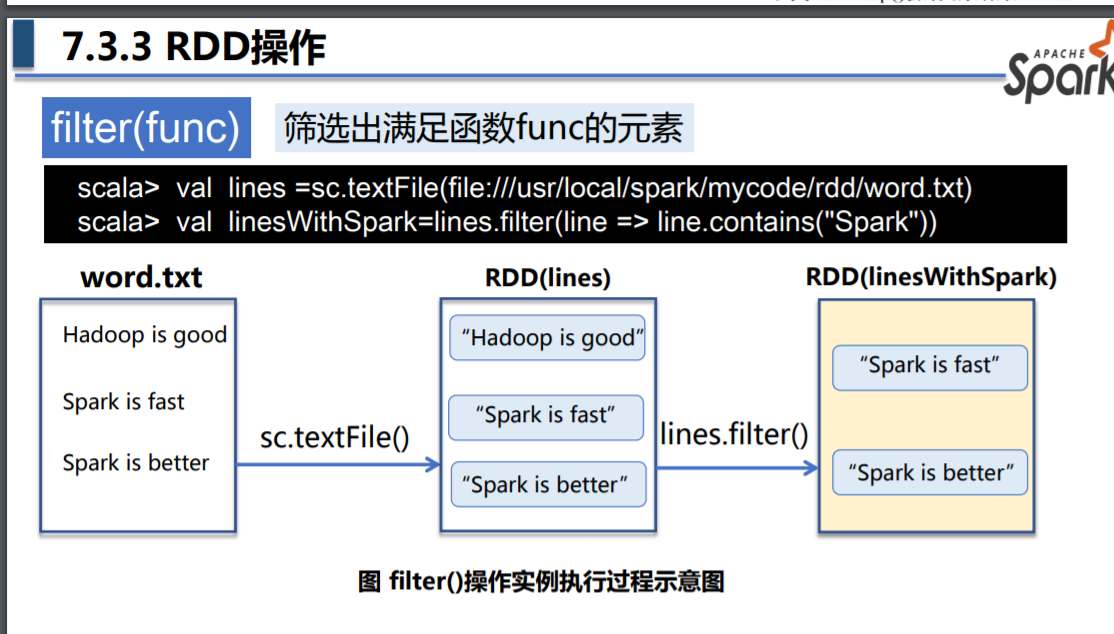
filter(func)
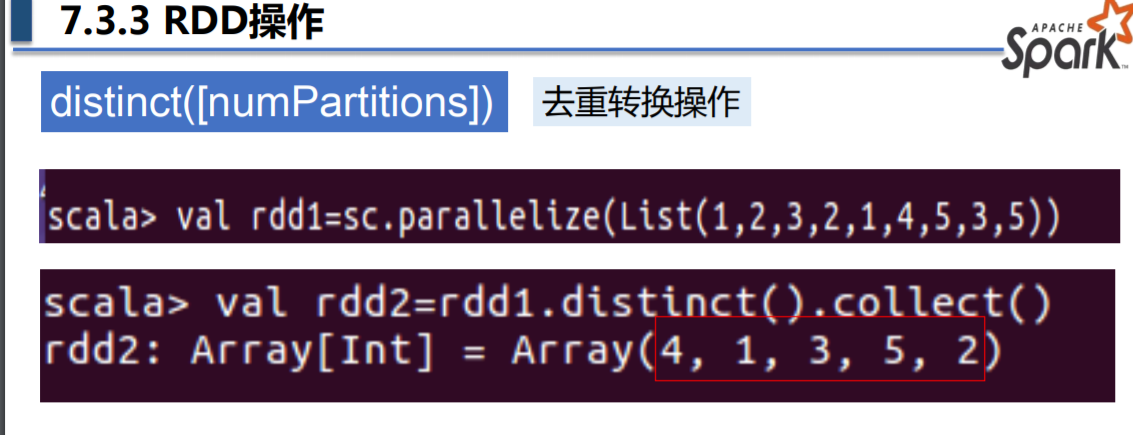
distinct([numPartitions])
groupByKey ()
和Mapreduce的归并操作一致

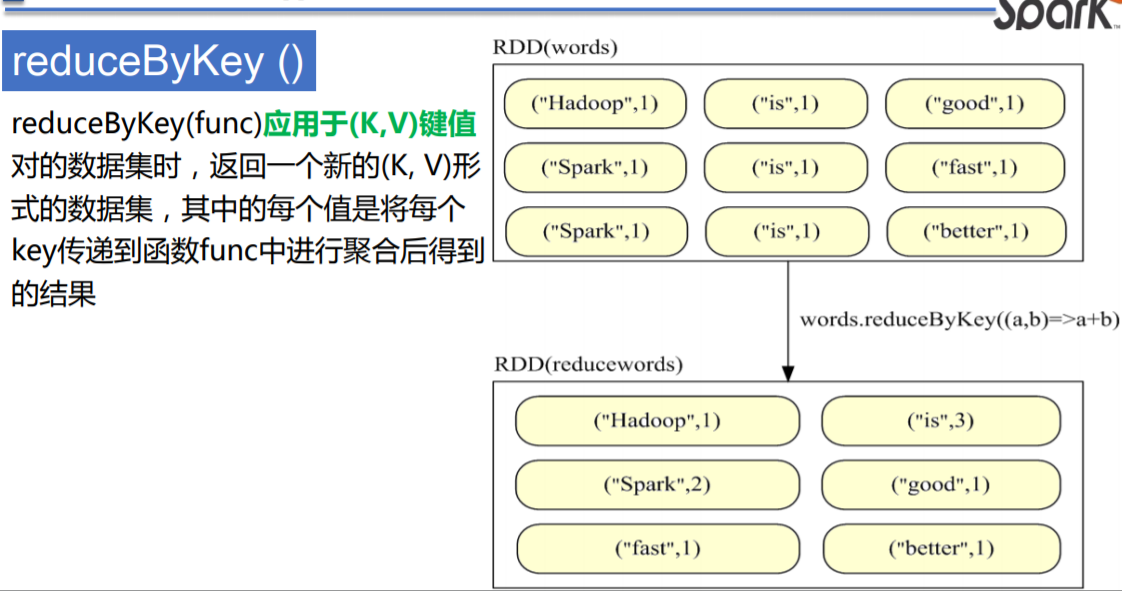
reduceByKey ()
join()

查看数据的几个函数
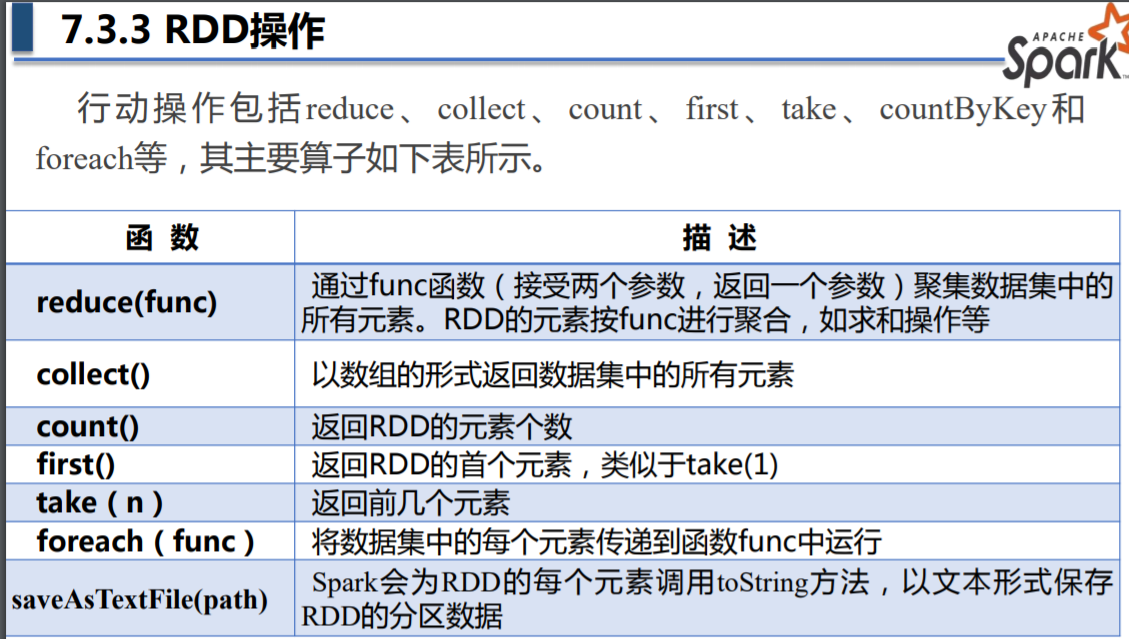
其他函数
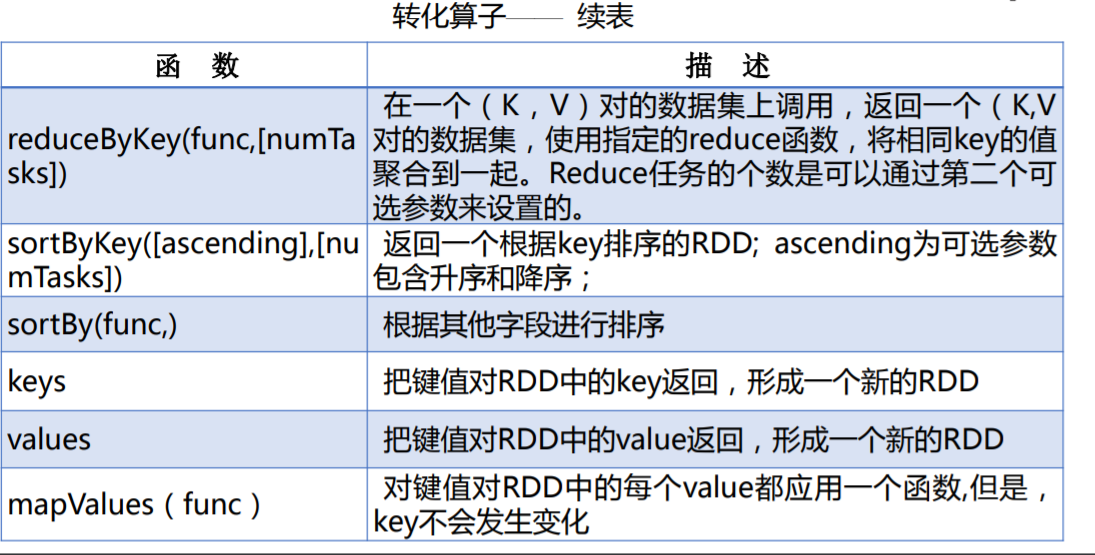

分区的目的、自定义分区的方法有哪些


自定义分区方法

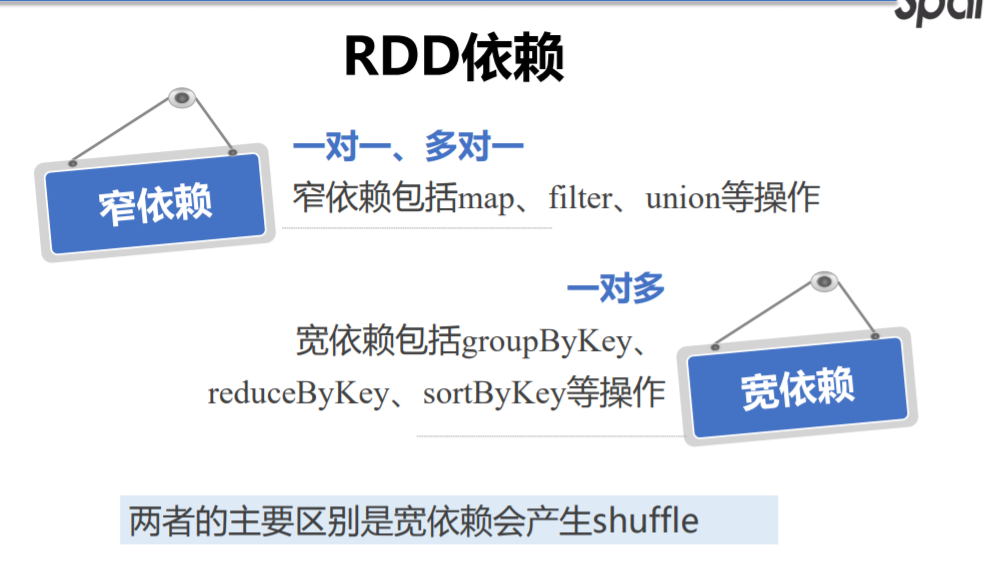
Stage 阶段划分


Spark 架构


查找
从本地文件系统读取/home/hadoop/wordData目录下的文件,在spark-shell中编程查找所有文件包含“Hadoop”的行,并把结果输出到界面。
val textFile = sc .textFile("file:///home/hadoop/wordData")
val search = textFile.filter(line => line.contains("Hadoop"))
search.foreach(x => println(x))
去重
在spark-shell中编程实现:读取/home/hadoop/sparkData3目录下两个文件A和B,然后对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。
val textFile = sc.textFile("file:///home/hadoop/sparkData3")
val distinct = textFile.distinct()
distinct.foreach(x => println(x))
distinct.repartition(1).saveAsTextFile("file:///home/hadoop/sparkData3_out")
课程成绩分析






 浙公网安备 33010602011771号
浙公网安备 33010602011771号