
什么是视觉语言模型 (VLM)?
视觉语言模型
视觉语言模型(VLM)是一种结合了大语言模型(LLM)*和*视觉编码器的大语言模型,让 AI 能“看图说话”。
VLM 能接收图像/视频 + 文本作为输入,并输出文本结果,比如生成图像描述、回答关于图像的问题,或识别图像/视频中的内容。
传统的计算机视觉的模型 (如yolo) 是基于特定的任务(如分类、检测)或固定的标签集合做任务的。而VLM是基于LLM在大规模图文数据上训练的,能理解自然语言指令并完成多种视觉任务。
用户与 VLM 的交互方式就像使用 LLM(如 ChatGPT)一样,可以提供图文混合的提示,让模型生成回答、总结或解释内容,还能进行多轮对话,并在对话中不断添加新图像。VLM 也能被集成到视觉智能体中,实现复杂视觉任务。
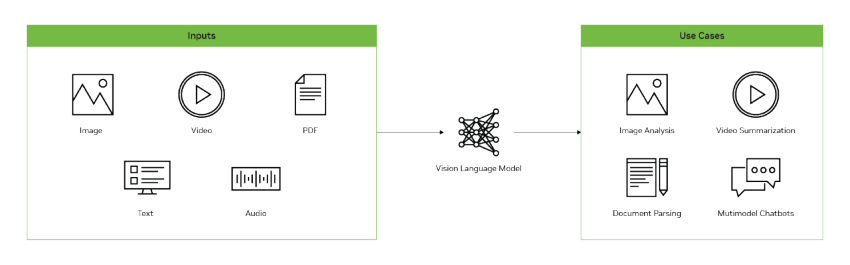
VLM 架构
大多数视觉语言模型(VLM)由三部分组成:
- 视觉编码器:通常是一个基于 transformer 架构的 CLIP(Contrastive Language–Image Pre-training) 模型,该模型已在数百万个图像-文本对进行了训练,具有图像与文本的关联能力。
- 投影器(Projector):由一组网络层构成,将视觉编码器的输出转换为 LLM 可以理解的方式,一般解读为图像标记 (tokens)。。
- 大语言模型(LLM):用来理解和生成自然语言,几乎所有已有的 LLM 都可以用于构建 VLM。

视觉语言模型应用场景
VLM 可用于一系列视觉语言任务:
● 视觉问答
●目标检测

●OCR
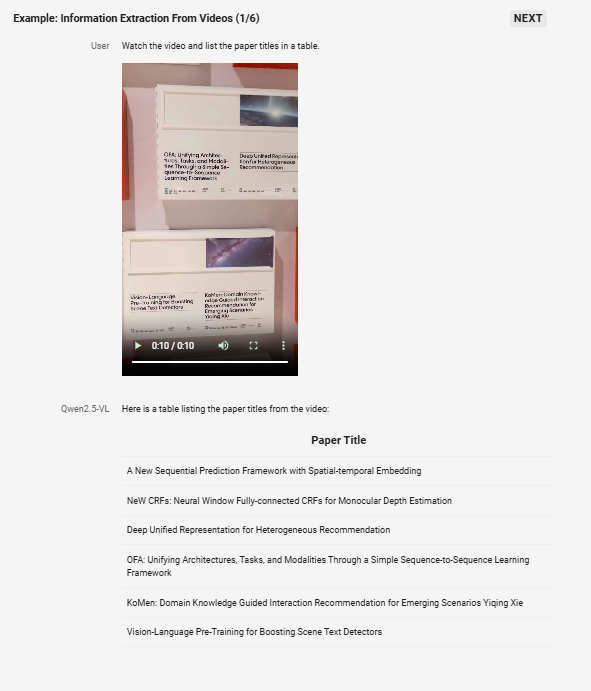
●视频分析

VLM 示例
以下是一些热门开源的VLM 的示例:
● Qwen2.5-VL: 3B、7B ,32B, 72B
● Qwen2-VL:2B,7B,72B
● Meta LLama3.2:11B, 90B
● Microsoft Phi-3.5 Vision 4B
...
下一步计划
●.在jetson 平台上部署个VLM 进行本地测试,验证两个场景
1)对视频中的机器是否工作做出判断
2) 对物体检测中出错的检测做出识别
3) 在相同的输入下,看哪个VLM模型准确率更高,输出更好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号