

一.任务描述
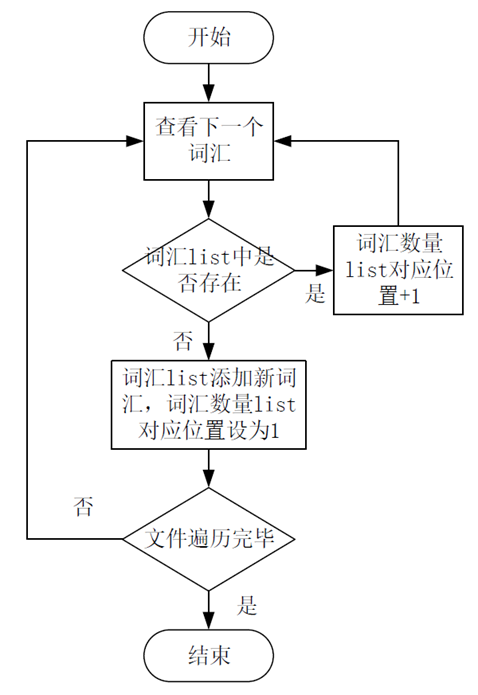
最近尝试自行构建skip-gram模型训练word2vec词向量表。其中有一步需要统计各词汇的出现频率,截取出现频率最高的10000个词汇进行保留,形成常用词词典。对于这个问题,我建立了两个list,词汇list 和 词汇数量list,分别记录新出现的词汇和该词汇出现的次数。遍历整个语料文件,收集各个词汇并计算其出现次数。最后,对词汇数量list进行降序排序,留下出现频率最高的10000个词汇。流程大致如下图:
二.问题描述
在程序实际运行的过程中,发现程序运行的速度实在是太慢。对于一个4000行的示例语料文件,分词+统计词频一共花费384秒。而此次目标的语料文件一共有上百万行,随着语料的扩充,词汇量也势必增大,每次对词汇list的检索开销也会有所上升。那么如何提高程序的运行速度呢?
三.问题解决思路
在未优化的程序运行过程中,我们发现电脑的CPU利用率一直处于20%左右,远未达到其最大负载功率,因此便想到使用多线程、多进程来并行的对文本进行处理,以提高处理效率。
思路如下:
由于我的电脑是八核CPU,因此我将语料文件平均分成八份,开启8个线程/进程来对这些语料数据进行处理。待八个进程/线程的工作结束后,再对结果进行拼接。
四.使用多线程程序处理语料文件。
python中多线程可以使用threading模块进行调用
具体调用语句为threading.Thread(target=函数名,args=(参数列tuple)),因此,首先的工作就是编写线程工作函数。
1.预设如下全局变量用于存储每个线程的输出结果。
1 # TODO 全局变量 TODO 2 pured_file = '../dataset/news_sohusite_xml_pure_200M_lines_content.txt' # 未切分语料地址 3 corp_list_all = [] # jieba分词过后的语料文件 4 for i in range(8): 5 corp_list_all.append([]) 6 dict_list_all = [] # 用于每个进程的词汇列表 7 for i in range(8): 8 dict_list_all.append([]) 9 dict_list_index_all = [] #用于每个进程的 词汇列表对于的出现次数。 10 for i in range(8): 11 dict_list_index_all.append([]) 12 finish_tag = [0,0,0,0,0,0,0,0] 13 # TODO 全局变量 TODO
线程工作函数如下
1 def cut_content_to_dict(c_lines,thread_index): 2 print("thread %s, length %s"%(str(thread_index),str(len(c_lines)))) 3 splited_list = [] 4 for sentences in c_lines: 5 words = jieba.cut(sentences,cut_all=False) 6 words = ' '.join(words) # 使用 空格 将每一个词汇隔开 此时是str类型变量。 7 splited_list.append(words[:-1]) # 去除句末的 '\n' 8 corp_list_all[thread_index] = splited_list # 将分词结果存入全局变量 9 word_index_list = [] #临时存储词汇列表 10 word_num_list = [] #临时存储词汇出现次数 11 count = 0 12 for item in splited_list: 13 words = item.split(' ') 14 for wd in words: 15 if wd in word_index_list: 16 word_num_list[word_index_list.index(wd)] += 1 # 有这个单词,则对应计数加1 17 else: 18 word_index_list.append(wd) 19 word_num_list.append(1) 20 if count%250==0: 21 print("thread %s, finished %s"%(str(thread_index),str(count))) 22 count+=1 23 dict_list_all[thread_index] = word_index_list #将词汇表存入全局变量对应位置 24 dict_list_index_all[thread_index] = word_num_list #将词汇频率存入全局变量对应位置 25 finish_tag[thread_index] = 1 26 if 0 not in finish_tag: # finish_tag 全为1 时,启用拼接函数 27 put_together()
其中,finish_tag全局变量用于检测是否所有线程都已工作完毕,其初始化为[0,0,0,0,0,0,0,0],待所有线程工作完毕后会成为全1向量,此时调用拼接函数put_together()对dict_list_all中的词汇进行拼接。
在main函数中,将语料数据分成8块,分别分配给各个线程,再对线程轮流进行启动:
1 with open(pured_file,'r',encoding='utf-8') as content_file: 2 lines = content_file.readlines() 3 lines = lines[:4000] 4 block_size = int(len(lines)/8) 5 tasks_8 = [] 6 for i in range(7): 7 tasks_8.append(lines[i*block_size:(i+1)*block_size]) 8 tasks_8.append(lines[7*block_size:]) 9 thread_list = [] 10 for i in range(8): 11 thread_list.append(threading.Thread(target=cut_content_to_dict, args=(tasks_8[i],i))) 12 for i in range(8): 13 thread_list[i].start()
经过这番改造,使用多线程处理4000行的示例语料文件共花费197秒,比未优化的代码速度提高了几乎一倍。但是通过观察CPU使用率,发现CPU并未全功率运行,占用率仍在20%多徘徊。因此尝试使用多进程来完成语料分词、统计任务。
五.使用多进程处理语料文件
python中多进程可以使用multiprocessing模块进行调用,与多线程的不同之处在于,每个子进程会单独划分一份资源,因此不能使用全局变量的方式来对子进程输出结果进行存储。multiprocessing模块提供了特殊的变量类型multiprocessing.Manager().list(),multiprocessing.Value()来获取子进程的输出结果。
首先编写进程工作函数:
1 # array_c,array_di,array_dn 是三个multiprocessing.Manager().list 类型变量,可以用于返回输出结果 2 def cut_content_to_dict(c_lines,proc_index,array_c,array_di,array_dn): 3 print("process %s, length %s"%(str(proc_index),str(len(c_lines)))) 4 for sentences in c_lines: 5 words = jieba.cut(sentences,cut_all=False) 6 words = ' '.join(words) # 使用 空格 将每一个词汇隔开 此时是str类型变量。 7 array_c.append(words[:-1]) # 去除句末的 '\0' 8 count = 0 9 for item in array_c: 10 words = item.split(' ') 11 for wd in words: 12 if wd in array_di: 13 array_dn[array_di.index(wd)] += 1 # 有这个单词,则对应计数加1 14 else: 15 array_di.append(wd) 16 array_dn.append(1) 17 if count%250==0: 18 print("process %s, finished %s"%(str(proc_index),str(count))) 19 count+=1
与之前的线程函数相比,这个进程函数多了很多参数,其中,array_c代表传入的语料数据,array_di,array_dn对应多线程代码中dict_list_all和dict_list_index_all,分别表示词汇list和词汇数量list。这种传递返回值的方式类似C语音中的指针调用。另外,multiprocessing.Value()类型的变量proc_index用于对子进程进行标注,记录该进程的执行进度。
在main函数中,需要额外一步初始化multiprocessing.Manager().list()类型和multiprocessing.Value()变量。
1 proc_id = [] 2 corp_list_all = [] # jieba分词过后的语料文件 3 dict_list_all = [] # 用于每个进程的词汇列表 4 dict_list_index_all = [] #用于每个进程的 词汇列表对于的出现次数。 5 for i in range(8): 6 corp_list_all.append(multiprocessing.Manager().list([])) # 主进程与子进程的共享list 7 for i in range(8): 8 dict_list_all.append(multiprocessing.Manager().list([])) # 主进程与子进程的共享list 9 for i in range(8): 10 dict_list_index_all.append(multiprocessing.Manager().list([])) # 主进程与子进程的共享list 11 for i in range(8): 12 proc_id.append(multiprocessing.Value("i",i)) # "i" 表示int类型, 第二个i表示初始数值
在对每个进程进行调用时,分别传入这些参数。
1 p_list = [] # 用于存储8个进程 2 for i in range(8): 3 p = multiprocessing.Process(target=cut_content_to_dict,args=(tasks_8[i],proc_id[i],\ 4 corp_list_all[i],dict_list_all[i],dict_list_index_all[i])) 5 p_list.append(p) 6 for p in p_list: 7 p.start() 8 for p in p_list: 9 p.join() 10 # 所有进程结束后,调用拼接函数 11 put_together(corp_list_all,dict_list_all,dict_list_index_all)
经过测试,使用多进程运行的代码处理4000行语料数据共花费159秒的时间,比多线程代码的运行速度又有所提高,同时CPU利用率也提升到了100%。
以上代码可用在我的GitHub中找到(https://github.com/NosenLiu/DIY_Word2Vec)。后续还将根据此次预处理结果构建一个skip-gram以训练出一个word2vec词向量表,有兴趣的同学可以下载进行参考。
