文献阅读_低分识别_2016CVPR_Studying Very Low Resolution Recognition Using Deep Networks
Studying Very Low Resolution Recognition Using Deep Networks
自用
之前让看低分识别,不知道还要不要看了,也好久没看文献了,读几篇准备一下开学。基本上就是文献复述写着玩的,顺道熟悉下博客园。
论文结构
论文复述
论文总结
文章结构
Introduction
Problem Definition
Model I: Basic Single Network
Motivation
Technical Approach
Simulation
(下同)
Model II: Single Network with Super-Resolution Pre-training
...
Model III: Single Network with Pre-training and LR-HR Transfer
...
Model IV: partially Coupled Networks
...
Model V: Robust Partially Coupled Networks
...
Solving Real VLRR Problems
VLRR Face Identification
VLRR Digit Recognition
VLRR Font Recognition
Conclusion
Abstract
问题: ROI区域小(或<16x16)
技术L: super resolution, domain adaption,robust regression
结果:
1.鲁棒性部分偶尔网络同时实现特征增强和识别
2. 可以处理低分-高分不匹配并对异常具有鲁棒性
3.在人脸识别,字体识别,数字识别做了验证
Conclusion
基本是概要再现,讲了下行文.
批:行文规整,逻辑清晰(仅看标题)
Introduction
1.指出问题,ROI大区域假设现实中不成立
2.指出问题,传统人脸识别要求bigger than 32x32 or 64x64 (rather than 16x16 for typicall VLRR); 信息确实看似不能从LR直接恢复(看着像伏笔的样子
3.给出方法, 从基础CNN出发,不断提升,并给出理由,分析和仿真.
4.给出结论,三个问题验证,效果好.
1.1 问题定义
1. 重要定义一: VLRR直接从LR识别,没有HR. 训练时包括HR和LR.
2.根据29 39 两篇文献,定义了LR<16x16, HR>32x32
Model I 基础
想法
打个底子(baseline)
实现
参考了这篇文章的网络
Imagenet classification with deep convolutional neural networks.
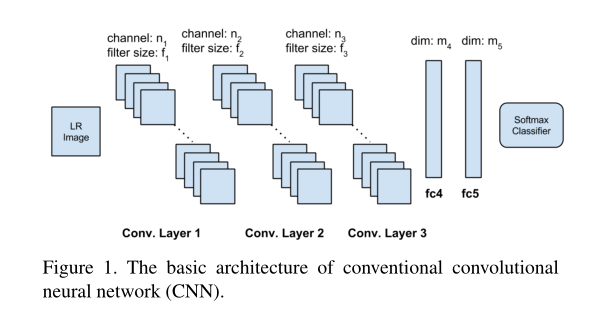
网络结构为三个卷积层两个FC层。指出了LR小故filter size不取大,为端到端训练。
仿真
预处理:卷积 s=4 下采样至8x8, 再插值回32x32作为LR图。归一化处理,并添加σ=0.05的高斯噪音。
para:
activation:ReLU
batch_size:128
lr:0.1 & /10 per plateau
Dropout:True
m4: 1024
m5: 10 for CIFAR-10 and 100 for CIFAR-100
#default: n1=64, f1= 5; n2= 64, f2= 3; n3= 32, f3= 1; m4= 1024.
Result:Top1 Error Table
| layer | kernerl_size | output_channel | stride | dimention |
| Conv1 | f1 | n1 | 1 | - |
| Conv2 | f2 | n2 | 1 | - |
| Conv3 | f3 | n3 | 1 | - |
| FC1 | - | - | - | m4 |
| FC2 | - | - | - | m5 |
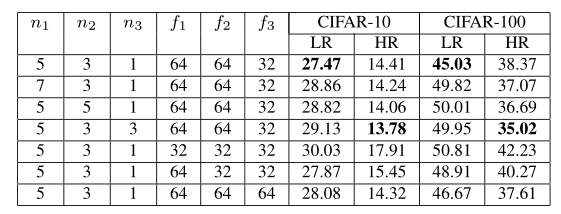
insights:
1.LR不如HR
2.大的fiter size 并没有显著提升
3.filter channels的提高在HR有帮助而LR无帮助。考虑到overfit。
其他:
1.提高m4能提高表现,但牺牲简洁性
2.更深的网络无用
结论:
LR与普通HR提升方法不同。
Model II 引入高分预训练的基础网络
想法
既然直接LR的信息太少,且实际预测中无法获得HR图。那么在训练的时候引入HR。
传统做法:进行超分重建并基于此进行分类(two stage)
问题: 过平滑,细节确实,重建痕迹
改进:[39]引入了'判别约束'( discriminative constraints)[12]在超分重建中引入了‘基于类的特征’(class-specific facial features)
实现
将Model1解耦为超分重建和人脸识别两个子网络。超分重建网络如下,采用无监督的方法首先训练,训练后丢弃Conv4层,并同人脸识别网络一同以监督方式联合训练。
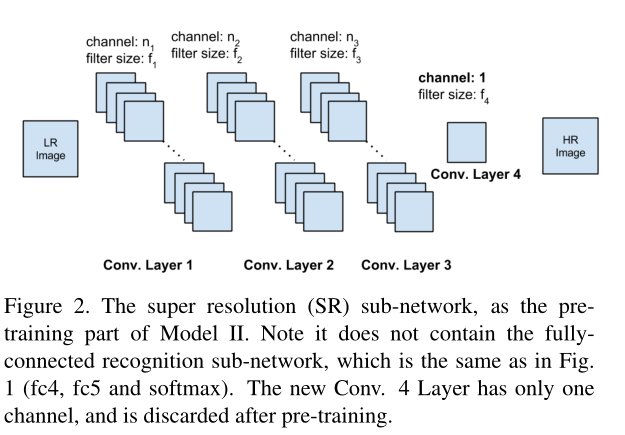
注:仅为超分重建网络,识别网络同ModelI
网络参考了Auto-Encoder,Denoising Auto-Encoder等的思想,但更关注无监督部分(而不是重建)
仿真
两个数据集上表现都变好了,但LR HR差距仍大
Remark:从只管来讲 超分重建一对多不是很稳定,超分重建对识别的贡献在于发现了更多的细节(较LR)但可信度一般。
MODEL III基本网络+SR预训练+LR-HR特征迁移
想法
对Model II 的结果可以看到分别将LR和HR作为输入,表现差距很大(10%)——SR没有为识别提供足够的特征——将HR图像混合在训练集中
域适应(domain adaption)观点
HR 源域(source domain),LR目标域(target domain)。先前工作[10]对来自所有域的未标记数据学习得到跨域特征提取器。分类器对来自源域的转换后的标记数据进行训练,并在目标域上进行测试。
数据增强观点
Q:Model II 已经引入了HR,why again。 A:problem-specific data augmentation approach for SR pre-training. 这里的意思应该是把'高清'作为一种数据增强的手段(like flip,rotate)
实现
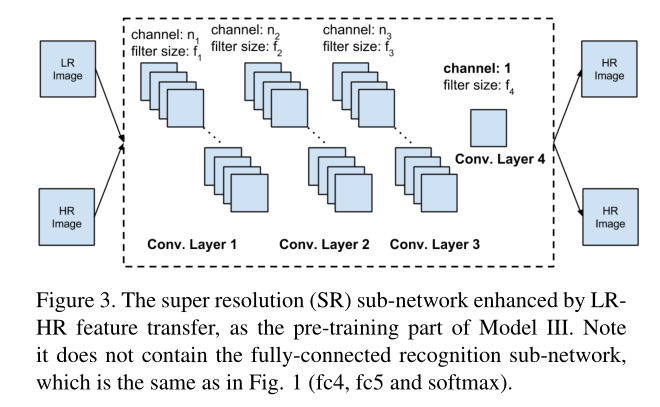
注:不含识别网络
域适应简介:
https://www.cnblogs.com/Terrypython/p/10645520.html
http://www.360doc.com/content/20/1107/09/7673502_944551402.shtml
我也不熟悉啊,按照文本的意思是这里有两个pipeline但共享hidden layer,一个是LR2HR,另一个是HR2HR
仿真
还是预训练再联合训练,if not better: why write
MODEL IV 部分耦合网络
想法
1.在LR和HR特征之间(同一副图)存在一个'部分共享'的隐藏空间(there exists a hidden space that are approximately shared by LR and HR features)
2.先前研究指出LR和HR的映射是复杂,非线性且spatial-variant的
3.大胆假设:LR和HR的特征经历复杂变换也不会完全重叠
---->放宽模型3约束(解耦)以匹配想法3中的差异
实现
Model4 这个子网络起名叫做Partially Coupled SR Networks(PCSRN)大概是半解耦超分重建网络
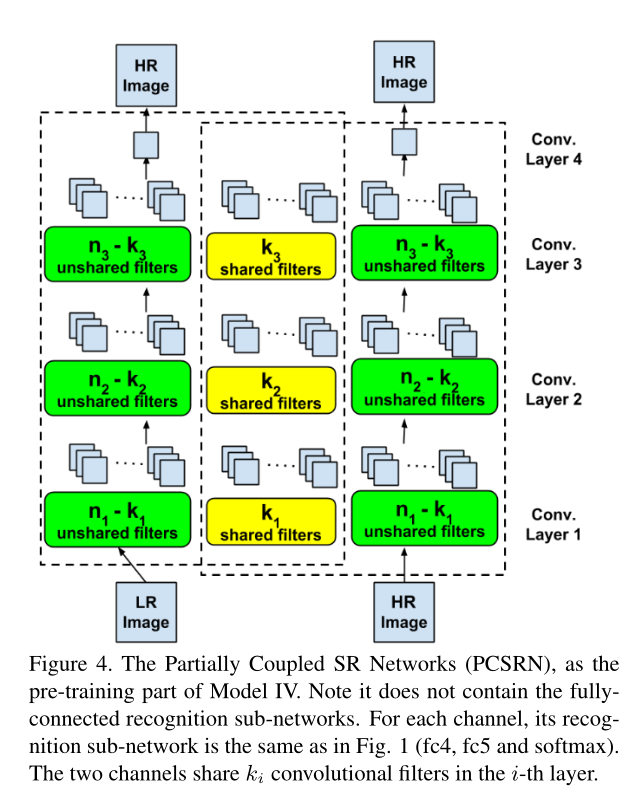
这里的主要改动,或者说唯一改动。就是把原来两个pipeline公用的hidden layer 分成两个部分重叠(k filters)的hidden layer。以对应“LR转换到HR后不匹配问题减少但存在”
仿真
default:c1= 0.50, c2= 0.75 and c3= 0.75
c_i这里定义为耦合比,c_i = k_i / n_i
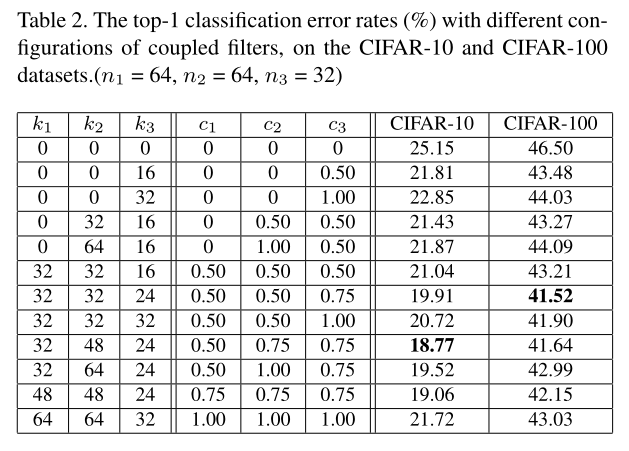
1.上述'非完全重叠'假设成立
2.深层网络容易过度拟合
3. 耦合比如何确定有待研究
MODEL V 鲁棒性+MODELIV
想法
1.针对实际场景的感受器(摄像头之类)噪音以及异常离群值( impulsive outliers)
2.在SR自网络预训练中使用的损失函数是MSE,对异常值敏感,后文给出的解释是LR给出的典型特征过少不足以给出数据流形(mainfold)。提到了一种针对异常值的损失函数, 指出了correntropy-induced loss function,用huber和MSE两种损失函数做了对比。
Reference:
https://en.wikipedia.org/wiki/Huber_loss
https://blog.csdn.net/forlogen/article/details/90264072
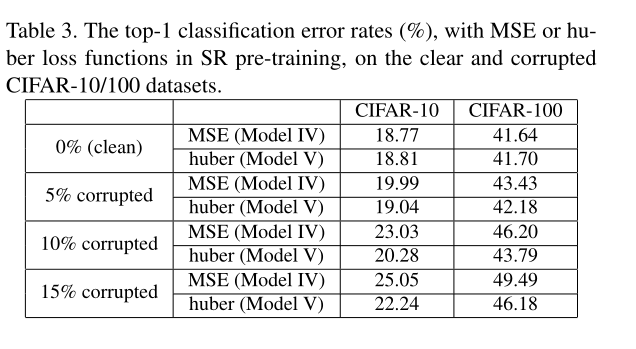
实现
最终确定使用的loss fun(和wiki差不多,等号位置而已):
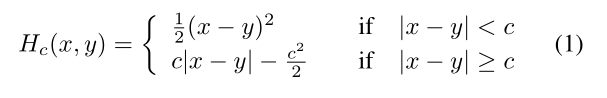
仿真
使用椒盐噪声污染不同比例的数据集,在两个模型上测试。干净的数据集huber略弱,噪声比例越强越好。(批:这里是不是应该多来几种噪声)
回顾对比
给了一个设计和发展模型方法论:关注具体方法(比如超分预训练而etc.)以及特定数据方面(特征转换,部分耦合,损失函数etc.)
懒得写了,简单记录一下

| 任务 | 数据集 | top1(V) | top5(V) | LR | HR |
类 |
| 人脸识别 | * | 40.97% | 22.35% | 16x16 | 80x80 | 180 |
| 数字识别 | SVHN | 43.02% | 29.18% | 8x8 | 32x32 | 10 |
| 字体识别 | VFR | 36.34% | 16.31% | h[7,21] | - |
2383train 93test |
| *:Large scale unconstrained open setface database | ||||||
读后批:
条例清晰,环环相扣,如作者所说根据具体问题和具体数据思考改进方法,并逐步实现优化。
大致的思路是:
| 想法 | 文献 | 实现 |
| LR信息少,引入SR | 基于类特征 | 建立一个拓扑与分类相同的超分重建网络 |
| 超分重建效果不良,输入引入HR | 域适应(及数据增强) |
完全共享隐藏层LR-HR特征迁移网络 |
| 提出LR-HR迁移后特征不完全重叠假设 | LR-HR 映射复杂,相似性判据不一 | 部分共享隐藏层LR-HR特征迁移网络 |
| 考虑实际场景中噪声和坏点 | 抗坏点损失函数 | 更改损失函数为huber* |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号