哈夫曼树编码
对输入的英文大写字母进行统计概率 然后构建哈夫曼树,输出是按照概率降序排序输出Huffman编码
输入
大写字母个数 n 第一个字母 第二个字母 第三个字母 ... 第n个字母
输出
字母1 出现次数 Huffman编码
字母2 出现次数 Huffman编码
字母3 出现次数 Huffman编码
…
字母n 出现次数 Huffman编码
Sample In
10
I I U U U I U N U U
字母1 出现次数 Huffman编码
字母2 出现次数 Huffman编码
字母3 出现次数 Huffman编码
…
字母n 出现次数 Huffman编码
Sample In
10
I I U U U I U N U U
Sample Out
U 6 1
I 3 01
N 1 00
解决此题首先要明白HuffmanTree的构造原理
I 3 01
N 1 00
解决此题首先要明白HuffmanTree的构造原理
首先来看一个简单的例子:
把某个班同学百分制的成绩转换成5分制,规则如下,
90~100 5
80~90 4
70~80 3
60~70 2
<60 1
<60 1
看起来很容易实现
即 if (score<60)
grade=1;
else if(score<70)
grade=2;
else if(score<80)
grade=3;
else if(score<90)
grade=4;
else
grade=5;
但是如果这个班的同学大多数都取得了90分以上的好成绩,那么前面4步的判断是很没必要且费时的。
很明显,这种算法在面对大量数据的时候是比较不合理的。
那么如何优化算法呢?
假定我们目前已经知道了这个班成绩的分布律
|
成绩 |
<60 |
60~70 |
70~80 |
80~90 |
90~100 |
|
比例 |
0.05 |
0.15 |
0.33 |
0.27 |
0.20 |
如果用刚才的办法,则算法的效率是多少呢,用比例乘上判断的次数0.05*1+0.15*2+0.33*3+0.27*4+0.20*4=3.22
我们稍微修改一下算法,先判断比例最大的,
即 if(score<80)
{
if(score<70)
if(score<60)
grade=1;
else
grade=2;
else
grade=3;
}
else if(score<90)
grade=4;
else
grade=5;
{
if(score<70)
if(score<60)
grade=1;
else
grade=2;
else
grade=3;
}
else if(score<90)
grade=4;
else
grade=5;
改良后的算法效率为0.05*3+0.15*3+0.33*2+0.27*2+0.2*2=2.2
很明显,改良后的算法效率增加了很多。
由树的定义可以把刚才的程序抽象成下图所示的"树":
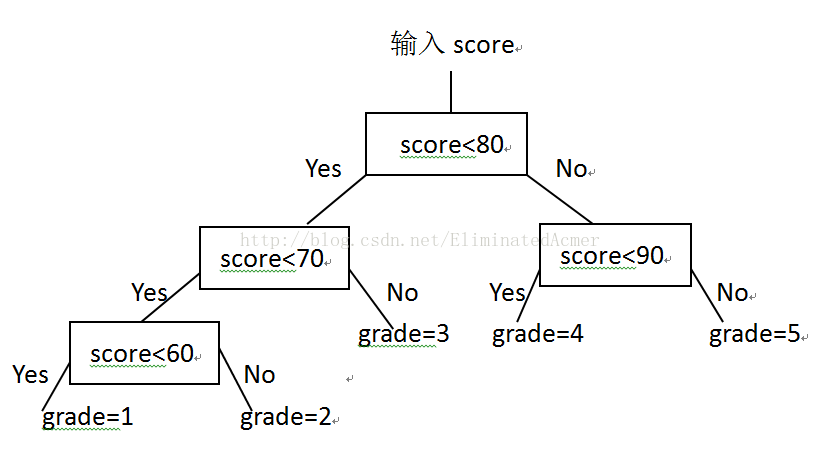
那么如何构造一个效率更好或者最好的搜索树呢,这就是哈夫曼树要解决的问题。
构造HuffmanTree思想:把权值(频率)从小到大排序,把权值最小的两颗二叉树合并
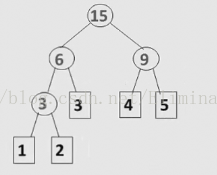
比如现有权值为1,2,3,4,5的节点(已经排好序)。
1.选择最小的两个,即1和2,合并,权值之和为3,
2.从刚才合并好的3和剩下的3,4,5里选择两个最小的,即3和3,合并,权值之和为6
3.从6,4,5里选择两个最小的,即4和5,合并,权值之和为9
4.将6和9合并,权值之和为15
下图为形成的哈夫曼树:
对于上面的问题,我们的思路之一应该是这样
1.统计相同字符出现的次数并记录之
2.根据统计好的结果构造哈夫曼树
3.获得哈夫曼编码
4.按题目要求格式打印
那么写出代码就是轻而易举的事情了:
#include <iostream> #include <cstring> #include <cstdio> using namespace std; template<class T> struct StaFrequency { T data; int times; StaFrequency(); StaFrequency(T data,int times) {this->data=data;this->times=times;} }; template<class T> struct TriNode { T data; int parent,left,right; }; template<class T> class HuffmanTree { private: int leafNum; TriNode<int> *huftree; char **hufcodes; void createHuffmanTree(T weight[],int n); void getHuffmanCode(); public: HuffmanTree(T weight[],int n); ~HuffmanTree() {delete []huftree;delete []hufcodes;}; void print(int i); }; const int Max_Weight=9999; template <class T> HuffmanTree<T>::HuffmanTree(T weight[],int n) { createHuffmanTree(weight,n); getHuffmanCode(); } //构造哈夫曼树 template <class T> void HuffmanTree<T>::createHuffmanTree(T weight[],int n) { leafNum=n; huftree=new TriNode<int>[2*n-1]; int i; for(i=0;i<n;i++) { huftree[i].data=weight[i]; huftree[i].parent=huftree[i].left=huftree[i].right=-1; } for(i=0;i<n-1;i++) { int min1,min2,x1,x2; min1=min2=Max_Weight; x1=x2=-1; for(int j=0;j<n+i;j++) { if(huftree[j].data<min1&&huftree[j].parent==-1) { min2=min1; x2=x1; min1=huftree[j].data; x1=j; } else if(huftree[j].data<min2&&huftree[j].parent==-1) { min2=huftree[j].data; x2=j; } } huftree[x1].parent=n+i; huftree[x2].parent=n+i; huftree[n+i].data=huftree[x1].data+huftree[x2].data; huftree[n+i].parent=-1; huftree[n+i].left=x1; huftree[n+i].right=x2; } } //获得哈夫曼编码 template <class T> void HuffmanTree<T>::getHuffmanCode() { int n=leafNum; hufcodes=new char *[n]; for(int i=0;i<n;i++) { char * code=new char[n]; code[n-1]='\0'; int start=n-1; int child=i; int parent=huftree[child].parent; while(parent!=-1) { start--; if(huftree[parent].left==child) code[start]='0'; else code[start]='1'; child=parent; parent=huftree[child].parent; } hufcodes[i]=code+start; } } //打印哈夫曼编码 template <class T> void HuffmanTree<T>::print(int i) { cout<<hufcodes[i]<<endl; } int main() { int m; cin>>m; char weight[m]; for(int i=0;i<m;i++) cin>>weight[i]; int i=0,n=0,sum=0,num=0,x=0; int s[m]; char w[m]; bool flag; for(i=0;i<m;i++) { flag=true; sum=0; for(int j=i-1;j>=0;j--)//检测是否有已经算过的字母 { if(weight[j]==weight[i]) { flag=false; break; } } for(n=i;n<m&&flag;n++)//若上一步没有,则算相同的个数 { if(weight[i]==weight[n]) { sum++; } } if(flag) //存储相同字符及个数 { s[num++]=sum; w[x++]=weight[i]; } } //就写个最简单的冒泡排序吧 for(int k=0;k<num;k++) { for(int j=0; j<num-1-k; j++) { if(s[j]<s[j+1]) { swap(s[j],s[j+1]); swap(w[j],w[j+1]); } } } HuffmanTree<int> htree(s,num); for(int i=0;i<num;i++) { cout<<w[i]<<" "<<s[i]<<" "; htree.print(i); } return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号