

[Spark]-编译(2.3.1)&部署(YARN-Cluster)
1.基础环境准备
Spark 2.3.1 编译需要 Maven 3.3.9 和 Java 8+ (从官网我们得知Java7已经在Spark2.2.0开始就已经不支持了),这里已提前准备,跳过.
另
Maven需要将内存使用调高(防止编译过程内存超标报错)
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"Spark编译时最好把Git装上.(方便后面做部署包)
2.Scala准备
Spark本身使用Scala写的,也需要Scala语言的支持.Spark 2.3.1需要的Scala版本是 2.11+,这里我选择的是2.11.8
官网下载: https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz
解压 # tar -xzvf ~/software/scala-2.11.8.tgz -C ~/app
写入环境变量:
export SCALA_HOME=/home/hadoop/app/scala-2.11.8
export PATH=$SCALA_HOME/bin:$PATH
3.编译
3.1 下载Spark源码
这里选择的当前最新版 spark-2.3.1.tgz
解压 # tar -xzvf ~/source/spark-2.3.1.tgz -C ~/source/
3.2 修改Spark pom.xml
因为Hadoop我使用的CDH版,所以必须在pom.xml中加入该配置节才能正确下载Hadoop.CDH Jar包
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
3.3 调制版本参数
Spark本身使用Maven进行编译的,所以必然有一个pom.xml,详细描述了项目的组织过程
从Spark的pom.xml上看,它本身是与Hadoop2.6.5一起的.这里我需要修改下,因为我正在使用的Hadoop版本是 hadoop-2.6.0-cdh5.7.0
这里就可以看出自己编译的好处了.紧密贴合自己需要的版本.
我自己的实际情况如下:
hadoop.version=hadoop-2.6.0-cdh5.7.0 (我的YARN与Hadoop版本相同)
hive.version=hive-1.1.0-cdh5.7.0
所以设置Maven编译命令应该如下:
./build/mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.7.0 -Phive -Phive-thriftserver -DskipTests clean package
但更好是使用这个,Spark提供的打包Shell,这个Shell可以编译打包成彷如官网下载的部署包一样
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Pyarn -Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.7.0 -Phive -Phive-thriftserver
开始编译打包吧,第一次编译耗时比较久,建议****,最后的结果如下:
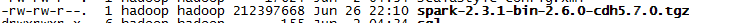
4.部署
Spark有三种部署模式,这里Spark选择为YARN-cluster模式
部署包拷贝到software,这里是我统一放安装的包的地方 # cp ./spark-2.3.1-bin-2.6.0-cdh5.7.0.tgz ~/software/
解压: # tar -xzvf ~/software/spark-2.3.1-bin-2.6.0-cdh5.7.0.tgz -C ~/app
配置环境变量
export HADOOP_CONF_DIR=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
export SPARK_HOME=/home/hadoop/app/spark-2.3.1-bin-2.6.0-cdh5.7.0
export PATH=$SPARK_HOME/bin:$PATH
拷贝Spark配置模板: # cp ~/app/spark-2.3.1-bin-2.6.0-cdh5.7.0/conf/spark-env.sh.template ~/app/spark-2.3.1-bin-2.6.0-cdh5.7.0/conf/spark-env.sh
编辑配置文件如下: vi ~/app/spark-2.3.1-bin-2.6.0-cdh5.7.0/conf/spark-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.8.0_45
export HADOOP_CONF_DIR=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
export YARN_CONF_DIR=/home/hadoop/app/hadoop-2.6.0-cdh5.7.0/etc/hadoop
export SPARK_EXECUTOR_CORES=1
export SPARK_EXECUTOR_MEMORY=1G
export SPARK_DRIVER_MEMORY=1G
拷贝Slayer配置: # cp ~/app/spark-2.3.1-bin-2.6.0-cdh5.7.0/conf/slaves.template ~/app/spark-2.3.1-bin-2.6.0-cdh5.7.0/conf/slaves
编辑如下: # vi ~/app/spark-2.3.1-bin-2.6.0-cdh5.7.0/conf/slaves
hadoop000
5. 启动
启动Spark-Shell:
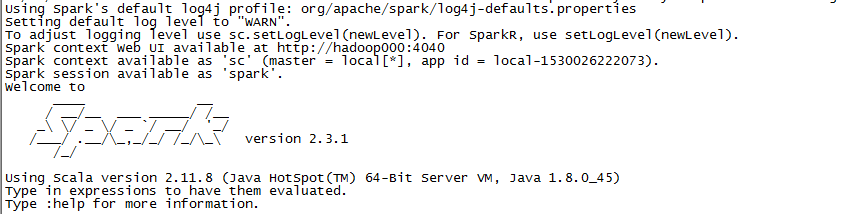

启动服务
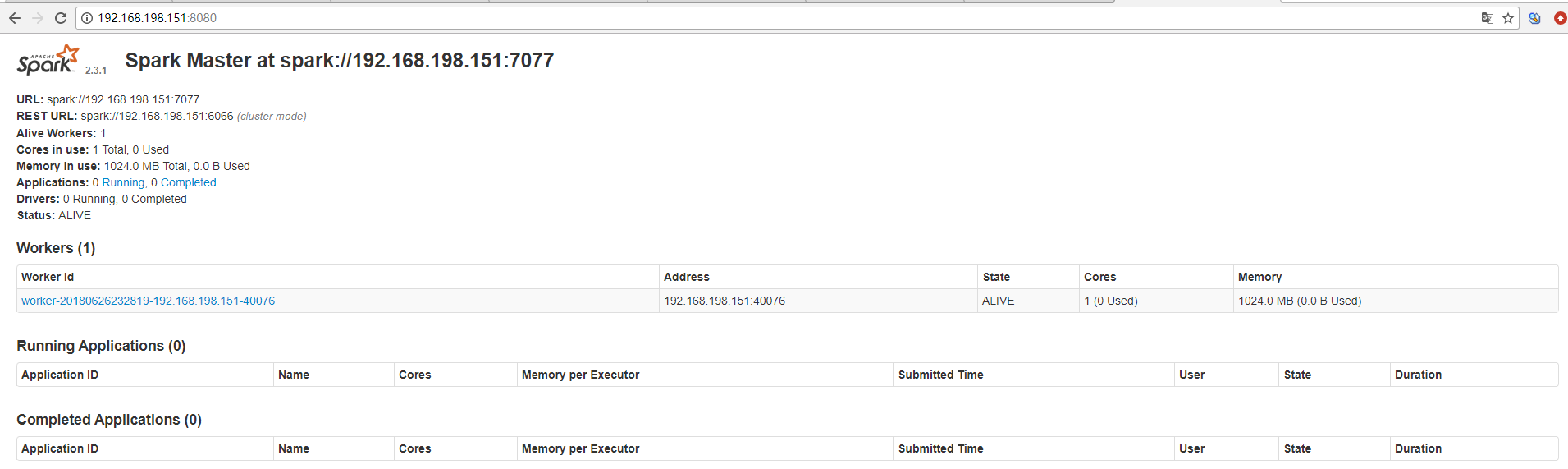
跑一个测试
./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
--queue thequeue \
examples/jars/spark-examples*.jar \
10
成功在YARN上执行


 浙公网安备 33010602011771号
浙公网安备 33010602011771号