

[Hadoop]-HDFS-架构篇
1. 概论
2.核心概念
1.1 Namenode(NN)
官网的解释是就是这个文件系统的命名空间.
通俗点说,就是既然数据文件是分块存储在多个数据节点上,那必然有一个综合管理文件访问的地方.比如数据文件的路径,权限,以及存储在哪些数据数据节点上以及如何聚合还原等等.
按官网的说明,NN存储了以下东西(内存存储)
整个文件系统的目录树
文件的权限
文件的副本数量,块拆分情况以及文件块存储的数据节点集
1.2 Datanode(DN)
真正存储数据块的地方.以及数据块的校验码(校验文件是可用还是损坏的,文件校验非常必要,比如网络突然中断,或者其它非预知的文件变化等等)
需要注意的是,在HDFS的设计架构里,是 从->主 的.
所以NM启动时是没有东西的,也不会由NN负责嗅探DN,而是在DN启动后以类似注册通知的形式主动告知NN在自己这里的Blockreport.并在之后的时间里以心跳的形式持续告知NN自己的Blockreport
所以在启动是NN会进入Safemode模式,不会出现数据复制,等待DN发送Blockreport,当NN完成自检(确定每个块都有最小数量的副本),才会退出Safemode
默认情况 每隔3秒NN发送一次Alive心跳,每10次心跳,发送一次自己的Blockreport. NN指定时间(默认10分钟)未收到,将彻底放弃该DN
1.3 Secondary Namenode(SNN)
第二名称节点.勉强算HDFS自己早期的容灾方案(只是容灾,还远远谈不上高可用).
HDFS,虽然有文件副本的来保证文件块存储本身的高可用,但HDFS本身并不是高可用的,依然有单点问题.这个单点问题就是NN
试想在HDFS运行过程中,NN突然Down掉了,虽然数据文件不会丢失,HDFS还是不可用了.
SNN工作就是每隔一小时,将NN上的事务日志(editlog)追加到磁盘存储的 fsimage 上(CheckPoint). 这样一但NN发生了问题,可以将NN恢复到最迟一小时内的情况.呵呵
到今天来看SNN已经是一个相当鸡肋的做法,现在的HDFS,基本采用是直接在NN上做高可用,两个甚至多个DN同时写,一个Active 其余的StandBy,发生问题时立即在Standby中切换
1.4 数据文件块
数据文件在真正存储进HDFS时,会按照策略拆分成N个块,默认是128M,每一个块就是数据文件块,
数据节点真正存储时,将是以数据文件块为单位进行存储的.
数据文件分割时,将严格按照分割策略进行不平均分割.
举个例子 一个130M的文件,最终将被拆分为 128+2 而不会是 65+65
1.5 副本
一个文件块,最终会按照策略,同时存储多个副本,这样当某一个文件块出现问题,可以由其它的副本补上.
所以一个130M的文件,块拆分128M,副本数3时, 130M的文件最终将 (128+2)*3, 分割为6块,共需占用390M空间
副本存储遵循以下原则
如果存储要求发生地本身是一个数据节点,将会在自身节点A存一,与A不同的机架的随机节点B一,与B相同的机架的随机节点C一,其余副本随机挑选节点存储
如果存储要求地本身不是数据节点,比如来自集群外,则会由NN随机挑选一个CPU不忙,存储压力不大的节点A存一,后同上......
NN不会允许一个DM拥有同一个块的多个副本.
不只是副本存储,读取是HDFS也遵循尽量读取贴近读取者的副本进行读取
在HDFS的设计认知中,HDFS通常分布在多个机架上的计算机集群上。不同机架间的两个节点之间的通信必须通过交换机。在大多数情况下,同一机架的机器之间的网络传输消耗小于不同机架之间的网络消耗,
所以才有这样依靠机架来设计,实际生产过程中很少严格遵循机架分布网络,甚至有同机架不同网络甚至不能访问的情况,所以了解了解就行了
3.架构图概览
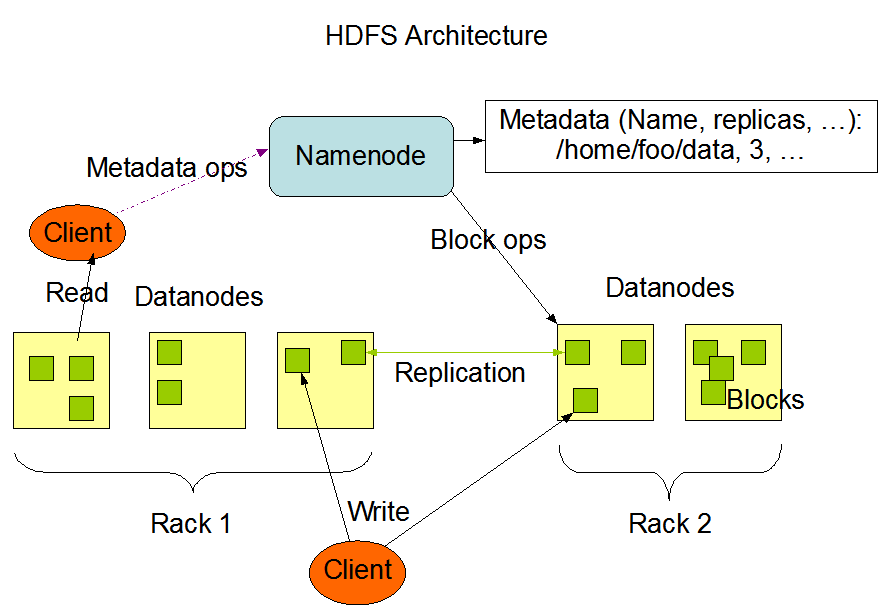
4.文件写
客户端打开DFS组件,调用文件写入
DFS接管整个文件写入过程
首先向NN发送RPC请求,NN收到请求判断如果允许写入,则创建一个空的(没有块关联)虚拟文件,并返回FSOutputStream(虚拟文件信息和文件块列表,以及文件块DN副本链路列表,副本数量等信息),否则拒绝并抛出异常
DFS拿到FSOutputStream后写入字节流,FSOutputStream将根据结果拆分出第一个文件块,并根据副本链路请求第一个DN写入文件块并向这个DM传递副本链路,这个DM在接受数据块的同时会根据传入的副本链路,联系第二个DM再同时再写入文件块,第二个再联系第三个,依次类推
FSOutputStream只会向NO.1DN写入,再通过NO.1DN同时写入NO2.依次类推直到最后一个,这样文件块将会迅速蔓延分布到所有的副DN中.
当最后一个DN完成写入时,将会通知成功前一个DN,依次类推当NO.1收到NO.2的成功通知后,NO.1将最终通知DFS的FSDataOutputStream,此时该文件块最终写入成功,继续写入下一个文件块
当文件块按照上述流程全部写入成功后,DFS判断最终写入成功,调用FileSystem.complete()通知NN已写入成功.此时整个文件写入工作完成,转回客户端
在整个文件写入过程中,所有与NN,DN等通讯,写入,确认等等都由DFS封装,对客户端来说完全透明
5.文件读
客户端打开DFS组件,FileSystem.open(filePath) 调用文件读取
DFS同样接管整个文件读取过程
首先向NN发送RPC请求,NN收到请求判断如果允许读取,则返回需要读取块列表,以及每个块的校验码,以及该文件块在DM的全部或部分副本链路表,否则拒绝并抛出异常
DFS拿到NN的返回结果后,调用FSDataInputStream对象的read()去尝试读取数据文件
读取第一个块的DM链路列表,挨个尝试去请求DM,如果DM成功响应并返回数据,则再比对该文件块的校验码,如果都成功则进行读取下一个文件块,否则联系下一个DM依旧读取本文件块
如果NM返回的块列表已经读取完毕但文件还没有结束,则会再次请求NM返回下一批次的块列表并继续重复
所有文件块读取完毕后,DFS整合所有文件块为一个统一的数据文件返回客户端
在整个文件读取过程中,依然对客户端完全透明

 浙公网安备 33010602011771号
浙公网安备 33010602011771号