数据分析-numpy


import numpy as np ls2 = np.arange(10) list(ls2) type(ls2) #numpy.ndarray
简单的方法:
np.ones([3,4]) #返回元素全为1的3×4二维数组 np.zeros([2,3])#返回元素全为0的2×3二维数组
array([[ 1., 1., 1., 1.], [ 1., 1., 1., 1.], [ 1., 1., 1., 1.]])
np.empty(3) #返回一维空数组
有关数组的属性和函数
属性:
arr3 = np.array(((1,1,2,3),(5,8,13,21),(34,55,89,144)))
arr3.shape #shape方法返回数组的行数和列数 (3, 4)
arr3.dtype #dtype方法返回数组的数据类型 dtype('int32')
a = arr3.ravel() #通过ravel的方法将数组拉直(多维数组降为一维数组) array([ 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144])
b = arr3.flatten() #通过flatten的方法将数组拉直 array([ 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144])
两者的区别在于ravel方法生成的是原数组的视图,无需占有内存空间,但视图的改变会影响到原数组的变化。而flatten方法返回的是真实值,其值的改变并不会影响原数组的更改。
arr4.ndim #返回数组的维数
arr4.size #返回数组元素的个数
arr4.T #返回数组的转置结果
如果数组的数据类型为复数的话,real方法可以返回复数的实部,imag方法返回复数的虚部。
函数:
len(arr4) #返回数组有多少行
np.hstack((arr3,arr4))两个行数相同的数组横向拼接。np.column_stack((arr3,arr4)) #与hstack函数具有一样的效果
np.vstack((arr3,arr4)) 两个行数相同的数组纵向拼接。np.row_stack((arr3,arr4)) #与vstack函数具有一样的效果
reshape()函数和resize()函数可以重新设置数组的行数和列数:
arr5 = np.array(np.arange(24))
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,17, 18, 19, 20, 21, 22, 23])
a = arr5.reshape(4,6) 通过reshape函数将一维数组设置为二维数组,且为4行6列的数组。

a.resize(6,4) 通过resize函数会直接改变原数组的形状。

数组转换:tolist将数组转换为列表,astype()强制转换数组的数据类型,下面是两个函数的例子:
b = a.tolist() c = a.astype(float)
数组元素的获取
通过索引和切片的方式获取数组元素,一维数组元素的获取与列表、元组的获取方式一样:
arr7=np.arange(10) array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
arr7[3] #获取index=3元素 3
arr7[:3] #获取index=3前面的元素 array([0, 1, 2])
arr7[3:] #获取index=3元素以及之后的所有元素 array([3, 4, 5, 6, 7, 8, 9])
arr7[-2:] #获取末尾的2个元素 array([8, 9])
arr7[::2] #从index=0开始,获取步长为2的所有元素 array([0, 2, 4, 6, 8])
二维数组元素的获取
arr8 = np.array(np.arange(12)).reshape(3,4)

arr8[1] #返回数组的index=1的行 array([4, 5, 6, 7])
arr8[:2] #返回数组的index=2以前的行 array([[0, 1, 2, 3],[4, 5, 6, 7]])
arr8[[0,2]] #返回指定的index=0和index=2行
arr8[[0,2]] #返回指定的index=0行和index=2行
arr8[:,0] #返回数组的index=0列
arr8[:,-2:] #返回数组的后2列
arr8[:,[0,2]] #返回数组的index=0列和index=2列
arr8[1,2] #返回数组中index=1行index=2列对应的元素
布尔索引,即索引值为True和False,需要注意的是布尔索引必须输数组对象。
log = np.array([True,False,False,True,True,False])
arr9 = np.array(np.arange(24)).reshape(6,4)
arr9[log] #返回所有为True的对应行 #0,3,4行
array([[ 0, 1, 2, 3],[12, 13, 14, 15],[16, 17, 18, 19]])
arr9[-log] #通过负号筛选出所有为False的对应行
举一个场景,一维数组表示区域,二维数组表示观测值,如何选取目标区域的观测?
area = np.array(['A','B','A','C','A','B','D'])

observes = np.array(np.arange(21)).reshape(7,3)
observes[area == 'A'] 返回所有A区域的观测。 array([[ 0, 1, 2],[ 6, 7, 8],[12, 13, 14]])
observes[(area == 'A') | (area == 'D')] #条件值需要在&(and),|(or)两端用圆括号括起来 返回所有A区域和D区域的观测。
当然,布尔索引也可以与普通索引或切片混合使用:
observes[area == 'A'][:,[0,2]] 返回A区域的所有行,且只获取index=0列与index=2列数据。
花式索引:实际上就是将数组作为索引将原数组的元素提取出来
arr10 = np.arange(1,29).reshape(7,4)

arr10[[4,1,3,5]] #按照指定顺序返回指定行
arr10[[4,1,5]][:,[0,2,3]] #返回指定的行与列 如果想使用比较简单的方式返回指定行以列的二维数组的话,可以使用ix_()函数
arr10[np.ix_([4,1,5],[0,2,3])]

arr10[[4,1,5],[0,2,3]] array([17, 7, 24])
请注意!这与上面的返回结果是截然不同的,上面返回的是二维数组,而这条命令返回的是一维数组。
统计函数与线性代数运算
统计运算中常见的聚合函数有:最小值、最大值、中位数、均值、方差、标准差等。首先来看看数组元素级别的计算:
arr11 = 5-np.arange(1,13).reshape(4,3)

arr12 = np.random.randint(1,10,size = 12).reshape(4,3)

arr11 ** 2 #计算每个元素的平方
np.sqrt(arr11) #计算每个元素的平方根 由于负值的平方根没有意义,故返回nan。
np.exp(arr11) #计算每个元素的指数值
np.log(arr12) #计算每个元素的自然对数值
np.abs(arr11) #计算每个元素的绝对值
相同形状数组间元素的操作:
arr11 + arr12 #加 arr11 - arr12 #减 arr11 * arr12 #乘 arr11 / arr12 #除 arr11 // arr12 #整除 arr11 % arr12 #取余
统计运算函数:
np.sum(arr11) #计算所有元素的和
np.sum(arr11,axis = 0) #对每一列求和
np.sum(arr11, axis = 1) #对每一行求和
np.cumsum(arr11) #对每一个元素求累积和,返回一维数组(从上到下,从左到右的元素顺序)#array([ 4, 7, 9, 10, 10, 9, 7, 4, 0, -5, -11, -18], dtype=int32)
np.cumsum(arr11, axis = 0) #计算每一列的累积和,并返回二维数组 #array([[ 4, 3, 2],[ 5, 3, 1],[ 3, 0, -3],[ -2, -6, -10]], dtype=int32)
np.cumprod(arr11, axis = 1) #计算每一行的累计积,并返回二维数组
np.min(arr11) #计算所有元素的最小值 np.max(arr11, axis = 0) #计算每一列的最大值 np.mean(arr11) #计算所有元素的均值
np.mean(arr11, axis = 1) #计算每一行的均值 np.median(arr11) #计算所有元素的中位数 np.median(arr11, axis = 0) #计算每一列的中位数
np.var(arr12) #计算所有元素的方差 np.std(arr12, axis = 1) #计算每一行的标准差
numpy中的统计函数运算是非常灵活的,既可以计算所有元素的统计值,也可以计算指定行或列的统计指标。还有其他常用的函数,如符号函数sign,ceil(>=x的最小整数),floor(<=x的最大整数),modf(将浮点数的整数部分与小数部分分别存入两个独立的数组),cos,arccos,sin,arcsin,tan,arctan等。
让我很兴奋的一个函数是where(),它类似于Excel中的if函数,可以进行灵活的变换:
np.where(arr11 < 0, 'negtive','positive')

当然,np.where还可以嵌套使用,完成复杂的运算。
其它函数
unique(x):计算x的唯一元素,并返回有序结果
intersect(x,y):计算x和y的公共元素,即交集
union1d(x,y):计算x和y的并集
setdiff1d(x,y):计算x和y的差集,即元素在x中,不在y中
setxor1d(x,y):计算集合的对称差,即存在于一个数组中,但不同时存在于两个数组中
in1d(x,y):判断x的元素是否包含于y中
线性代数运算
同样numpu也跟R语言一样,可以非常方便的进行线性代数方面的计算,如行列式、逆、迹、特征根、特征向量等。但需要注意的是,有关线性代数的函数并不在numpy中,而是numpy的子例linalg中。
arr13 = np.array([[1,2,3,5],[2,4,1,6],[1,1,4,3],[2,5,4,1]])
np.linalg.det(arr13) #返回方阵的行列式 51.000000000000021
np.linalg.inv(arr13) #返回方阵的逆
np.trace(arr13) #返回方阵的迹(对角线元素之和),注意迹的求解不在linalg子例程中 10
np.linalg.eig(arr13) #返回由特征根和特征向量组成的元组
np.linalg.qr(arr13) #返回方阵的QR分解
np.linalg.svd(arr13) #返回方阵的奇异值分解
np.dot(arr13,arr13) #方阵的正真乘积运算
随机数生成
统计学中经常会讲到数据的分布特征,如正态分布、指数分布、卡方分布、二项分布、泊松分布等,下面就讲讲有关分布的随机数生成。
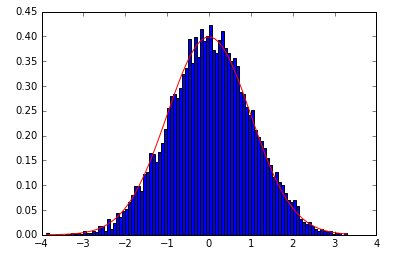
正态分布直方图
In [137]: import matplotlib #用于绘图的模块
In [138]: np.random.seed(1234) #设置随机种子
In [139]: N = 10000 #随机产生的样本量
In [140]: randnorm = np.random.normal(size = N) #生成正态随机数
In [141]: counts, bins, path = matplotlib.pylab.hist(randnorm, bins = np.sqrt(N), normed = True, color = 'blue') #绘制直方图
以上将直方图的频数和组距存放在counts和bins内。
In [142]: sigma = 1; mu = 0
In [143]: norm_dist = (1/np.sqrt(2*sigma*np.pi))*np.exp(-((bins-mu)**2)/2) #正态分布密度函数
In [144]: matplotlib.pylab.plot(bins,norm_dist,color = 'red') #绘制正态分布密度函数图
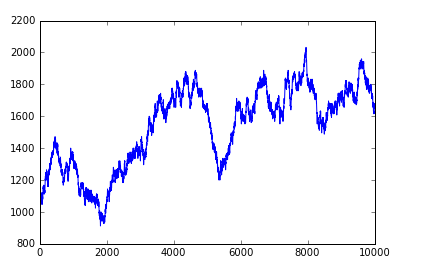
使用二项分布进行赌博
同时抛弃9枚硬币,如果正面朝上少于5枚,则输掉8元,否则就赢8元。如果手中有1000元作为赌资,请问赌博10000次后可能会是什么情况呢?
In [146]: np.random.seed(1234)
In [147]: binomial = np.random.binomial(9,0.5,10000) #生成二项分布随机数
In [148]: money = np.zeros(10000) #生成10000次赌资的列表
In [149]: money[0] = 1000 #首次赌资为1000元
In [150]: for i in range(1,10000):
...: if binomial[i] < 5:
...: money[i] = money[i-1] - 8
#如果少于5枚正面,则在上一次赌资的基础上输掉8元
...: else:
...: money[i] = money[i-1] + 8
#如果至少5枚正面,则在上一次赌资的基础上赢取8元
In [151]: matplotlib.pylab.plot(np.arange(10000), money)
一个醉汉在原始位置上行走10000步后将会在什么地方呢?如果他每走一步是随机的,即下一步可能是1也可能是-1。
In [152]: np.random.seed(1234) #设定随机种子
In [153]: position = 0 #设置初始位置
In [154]: walk = [] #创建空列表
In [155]: steps = 10000 #假设接下来行走10000步
In [156]: for i in np.arange(steps):
...: step = 1 if np.random.randint(0,2) else -1 #每一步都是随机的
...: position = position + step #对每一步进行累计求和
...: walk.append(position) #确定每一步所在的位置
In [157]: matplotlib.pylab.plot(np.arange(10000), walk) #绘制随机游走图

上面的代码还可以写成(结合前面所讲的where函数,cumsum函数):
In [158]: np.random.seed(1234)
In [159]: step = np.where(np.random.randint(0,2,10000)>0,1,-1)
In [160]: position = np.cumsum(step)
In [161]: matplotlib.pylab.plot(np.arange(10000), position)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号