OO第一单元总结
回顾第一单元的作业,我将总结自己代码成为”垃圾“并挣扎改出(并没有完全改出)的过程,尤其从第一次作业的面向过程到第二次彻底重构的过程。并感悟:同样通过测试的代码,其架构也可能是一个天上,一个地下。另外前排提示:觉得思路菜请勿嘲笑.....QAQ
如果有时光机,我绝对不会在寒假摆烂,没做pre
作业一:毫无头绪
1.1思路及架构
由于缺乏面向对象编程的思想,甚至java语法都没学利索,也没看懂递归下降,我采用了彻底地正则表达式+面向过程式编程
UML类图如下:
大体思路为:利用没有嵌套括号的特性,在底层直接实现三种因子的正则表达式,读入字符串进行暴力预处理后,直接将各个项拆开,装入ArrayList容器中,再分别解析各项的因子,套入正则表达式中计算其值,最后录入顶层的Result容器中。计算后存入Out类中输出。
以上思路着实不重要,因为纯纯面向过程,就是“垃圾”,另外.......当时我的最底层代码长这样(不许笑QAQ):
private Pattern costant = Pattern.compile("[+-]?(\\d+)");
private Pattern powerFuction = Pattern.compile("([+-]?)x(\\^\\d+)?");
private Pattern expressionFactor = Pattern.compile("[+-]?[(](([+-]?\\d+)|" +
"([+-]?x(\\^\\d+)?))([*](([+-]?\\d+)|x([+-]?\\^\\d+)?))*" +
"([+-](([+-]?\\d+)|([+-]?x(\\^\\d+)?))" +
"([*](([+-]?\\d+)|([+-]?x(\\^\\d+)?)))*)*[)](\\^\\d+)?");
private Pattern expressionPower = Pattern.compile("^[+-]?[(].*?[)]\\^\\d+$");
看看这糟糕光秃秃的、只有几个类的类图,吓人且极丑的代码,我颤抖着打开了复杂度分析........
果不其然一片红海,取几个核心方法如下:
| 方法 | 基本复杂度ev(G) | 模块设计复杂度iv(G) | 模块判定结构复杂度v(G) |
|---|---|---|---|
| Factors.multExpressionFactor | 9 | 14 | 17 |
| Factors.calculate | 9 | 10 | 11 |
| Factors.multOnceExpression | 5 | 14 | 15 |
| Parser.analyzeterm | 6 | 18 | 18 |
| Parser.calterm | 6 | 12 | 12 |
| 所有方法平均值 | 4.57 | 9.07 | 10.14 |
类似地,两个类的复杂度也是直接飘红......
分析如此之高的复杂度原因及扩展性为零的原因如下:
- 类的名字虽然是Parser,Factor,实际承担的工作是解析项并计算和解析因子并计算,没有采取任何面向对象的例如抽象因子为类、表达式项为类的思路。直接采取了解析表达式->算数乘起来的面向过程思路。
- 代码能力严重不足,多个方法间经常存在copy自己代码的怪事,导致维护困难度、复杂度极高。
- 底层竟然直接使用正则表达式描述匹配表达式因子,并且复用了大量match方法等等,导致完全无法处理多层括号,无法支持任何新因子的加入。
- 方法内部行数过长,不考虑怎样写出简洁的代码,只考虑怎样实现功能。且思维过于暴力只喜欢嵌套if_else语句。
1.2 测试
-
对拍思路
利用同班同学使用python语言写的数据生成器,将同学的程序的输出逻辑换为与自己一样则可以进行对拍,也就是靠着这个对拍器我才能在周五凌晨de掉了十几个Bug -
中测bugs
老实说,记不清最初的版本有多少bug了,都是瞎写代码惹的锅。由于模块间功能分配极不清晰、底层的笨拙、顶层对题目理解的偏差等等,我出现了预处理处理顶层输入字符串错误、乘法逻辑错误、输出逻辑错误......最终靠着对拍器和评测机de一整个夜晚苟过了第一次作业。
-
强测与互测
可能是运气好,也可能是代码过于恶心以至于没人愿意读我程序,本次作业强测与互测居然没出问题。
可能屎山到一定程度也会物极必反。互测时靠着评测机的随机数据输出hack成功两次
1.3 沉重的反思
互测读了房间里别人的代码,感觉自己需要钻到地缝里;周一听了老师对于第一次作业的分析,我做出了如下的反思:
- 关于架构:写这次作业之前,可能我连什么是架构都说不清楚,更别说什么是“好的架构”。而具体写代码的时候也是想到哪就写到哪,完全没有整体观念。以致于先从底层的正则写起写了一大半,感觉再向上写有点难,于是又切到了顶层开始由顶向下写。于是最后......顶层和底层对不上号,错位了。
- 关于解析方法:第一周一边补着pre一边写着hw1,没能下决心学习递归下降算法,事实证明采取可拓展性极差且几乎无法解决多层括号匹配问题的正则表达式抓取方法无异于慢性自杀,在hw2中逼迫我硬着头皮切换了算法。
- 关于读懂题目: 开学前一天我还在感叹pre(2)题目好长好麻烦,周一晚看到作业题的长度便直接凌乱了。花了整整一个下午才将将明白题目的各种数据限制。事实上快速了解题目的要求//他人的需求的能力是很重要的,梳理清楚复杂(其实也没多复杂)的要求是很重要的。另外,虽然第一次作业代码我的后续利用率是0,但顶层的处理思想和大致的注意事项及坑点(譬如0不输出,幂次的坑点等等)的的确确沿用了一点下去。
- 关于迭代开发: 我们需要思考我们计算的逻辑中有什么是不可变或者什么是“稳定”的:打开括号的过程中,我们要考虑不带括号的最小单位,那便是“因子”的概念;再考虑到我们要输出的表达式,应该是根据我们运算的结果处理而来的,于是在输出逻辑前便需要有储存运算结果的逻辑,所以我们只需要建立储存结果的类即可。这样的架构理应才能在后续的作业的“拓展要求”中生存能力更强。于是这便是我后来的真-底层:建立表示因子的类、建立储存运算的类。加上输出逻辑后,我们只差预处理逻辑和解析逻辑了,这便是我后来的真-顶层:预处理后递归下降解析表达式,并在解析中不断调用底层,在储存结果的容器一级不断地做各种运算,得到结果,最后输出。虽然这个思路听起来与dl们的还是有些”愚蠢“,但好在也没hw1的这么寒碜甚至有点儿好笑了。
作业二:彻底重构
2.1 思路及架构
看到题目,反复读两遍,眼前一黑......
周四晚开始重写,万幸的是,有一些顶层思路可以沿用(事实上若像往年一样加入语法正确性分析,会寄),结合hw1中的反思,先放一张看起来会稍显愚笨的思路图:

UML类图如下:
嗯,起码这个架构看起来像个架构了......
预处理: 在赌博后续作业没有输入合法性检查的情况下,毅然决然决定在顶层进行去除制表符、空格、平方后正号、连续正负号等等
并在不考虑之后可能的互相调用的情况下直接在最顶层字符串层面展开所有自定义函数和求和函数(我承认,我当时因为时间不够 还是只想活过hw2,所以这个可延展性也不很强.......)
另外,在自定义函数和sum函数展开时,预处理需要补充大量括号,其理应在递归下降过程中解析。
解析器:递归下降开始处理输入字符串,一边读入一边进行计算(parseExpr返回的结果类),计算过程中我只抽象了因子类Factors,并 通过其总接口与结果类的getFactorResult()相连,以读入最底层的表达式因子结果。
存储结构:本次作业相比于hw1,最大的难度提升点在于选择怎样的合适的容器来保存三角函数乘积式,经过向同学请教及自己的思考,我采取了如下策略:
- 第一次作业中,所有表达式最终形式均为:\(\sum{a_i}*{x_i}^{b_i}\) 所以我只采用了一个HashMap来保存x的幂次及其所对应的常系数。
- 第二次作业中,由于三角函数这个怪胎,x幂次相同的各项很难合并,于是我考虑将三角函数因子的乘积和常系数合并作为复合系数类、并在顶层仍采用HashMap保存x的幂次所对应的各个复合系数。核心代码如下:
//复合系数类属性
private BigInteger coefficient;
private ArrayList<Trigonometric> trigonometrics = new ArrayList<>()
//结果类属性
private HashMap<BigInteger, ArrayList<CompoundCoefficient>> proresult = new HashMap<>();
即:本次作业的最终表达式可以化为 \(\sum{a_i}*\prod{sin(b_j)}^{c_j}\prod{cos(d_k)}^{e_k}*x_i^{k_i}\) 的形式,而我们将所有三角函数的连乘存储在一个ArrayList中,与常系数组成复合系数类,每个\(x\)的幂次对应一个复合系数的ArrayList。
输出优化:除了第一次的正号提前、平方项优化之外,我做了一些不太智能的三角函数的化简:
-
\(cos(0)\) -> \(1\)
-
\(cos(-x)\) -> \(cos(x)\)
\(sin(-x)+sin(x)\) -> \(0\) (
哈哈 这里出大锅了 谁让我周六下午开始写优化) -
\(sin(x)^2+cos(x)^2\) -> \(1\) (
一样地由于时间关系只有平方项为2且常系数完全相等时才能合并)
而有关二倍角公式甚至更“黑科技”的化简,受限于时间和个人水平及正确性,我没有再做出尝试QAQ。
复杂度分析:
简而言之,比第一次好,复杂度整体还是偏高,另外代码能力的弱一周内实在是无能为力
具体而言,预处理类和输出逻辑类的方法复杂度有许多飘红,这与我部分模块还在面向过程的思维密不可分,另外还是存在一单元的各种问题。不过,底层及其它模块的复杂度稍有好转(只是稍有)。取部分糟糕的方法复杂度如下,列举外另有少量ev(G)飘红:
| 方法 | 基本复杂度ev(G) | 模块设计复杂度iv(G) | 模块判定结构复杂度v(G) |
|---|---|---|---|
| Out.singleOut | 10.0 | 17.0 | 17.0 |
| Out.judgeSum | 8.0 | 5.0 | 12.0 |
| Out.simplifyTrisum | 9.0 | 12.0 | 18.0 |
| Out.finalOut | 5.0 | 8.0 | 9.0 |
| Preprocess.handleRedundantBrackets | 5.0 | 9.0 | 9.0 |
| Preprocess.preprocess | 9.0 | 14.0 | 18.0 |
| CompoundCoefficient.simplify | 7.0 | 14.0 | 14.0 |
| Lexer.getNextPosition | 6.0 | 6.0 | 12.0 |
| 所有方法平均值 | 2.31 | 3.56 | 4.07 |
平均值上,也比hw1整体的复杂度低了很多,但和已有的博客一比还是惨不忍睹。(上表我偷懒揉在一起的那几个方法提升了不少平均值)。整体上我将方法的分布做了一个简单的统计图如下:
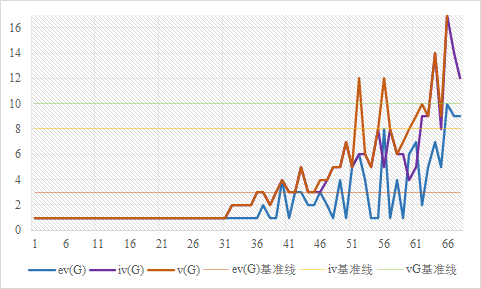
评价:改进空间极大(笑)
类复杂度上,数据不多直接放表:
| 类名称 | 平均圈复杂度 | 最大圈复杂度 | 总圈复杂度 |
|---|---|---|---|
| CompoundCoefficient | 3.00 | 7.00 | 30.00 |
| Proresult | 2.82 | 6.00 | 31.00 |
| Constant | 1.00 | 1.00 | 3.00 |
| Customfunction | 2.00 | 3.00 | 6.00 |
| Power | 1.33 | 2.00 | 4.00 |
| Sumfunction | 2.50 | 3.00 | 5.00 |
| Trigonometric | 2.83 | 7.00 | 34.00 |
| Lexer | 3.00 | 6.00 | 18.00 |
| Main | 2.00 | 2.00 | 2.00 |
| Out | 8.29 | 17.00 | 58.00 |
| Parser | 4.25 | 8.00 | 17.00 |
| Preprocess | 4.83 | 15.00 | 29.00 |
| 平均值 | 3.50 | 6.42 | 19.75 |
其中,输出类Out和预处理类PreProcess不出所料的红了,这两个直接承接输入输出的类里面写的方法不仅多且长。尤其是Out类,同样是因为其内部在面向过程,且套了极其多的if-else语句以判断怎样进行输出和进行化简、一大堆for循环用于遍历底层存储的各种因子,所以圈复杂度达到了惊人的8.3,这个模块在hw2中我独立的,hw3则(因为懒)合在了结果类中,然后让结果类更更更更复杂了。这样的处理确实会在化简出锅时很难对付,不过万幸的是这几个模块也相对解析、计算逻辑独立。
而总解析器Paser也略微超标,与某几个方法判断lexer当前读取的是什么类型字符套了太多if-else有关。(以我的水平只能略超一点儿了)
2.2测试
时间关系压根没有和同学进行对拍(找死.jpg)
强测中没有发现bug(感谢强测不强),性能分由于优化不彻底扣掉了约2.5分。但互测中就被锤爆了...
原因很简单: \(sin(-x)^2\) -> -\(sin(x)^2\) 写化简的时候完全忘了三角函数因子外面有幂次啊喂
教训也很简单:优化易出锅,需要考虑到各种边界情况,随机数据或自己想的数据之外,一定要按照优化函数逐个对优化逻辑进行覆盖性 大的检查,不然优化就是自杀。
互测采取了“乱扔数据”的战略(我有罪,我认错,呜呜呜):通过边界压力测试hack成功一次
2.3感悟:在重构中看“面向对象”
本次作业我的时间极其紧张,好在之前反思给出的架构没有太大问题,才能在bug不多的基础下通过中测强测。
整个推导自己作业重来的过程,将第二次的写作业流程与第一次的写作业对比,我深切体会到了pre中抽象不同类型为“对象”的重要性。第一次作业中,我往往是想到哪里写哪里,基本是按照“我要先开解析项——我要把项算出来——把结果乘起来”的过程型逻辑编程;第二次作业中,则为“什么在运算中是“反复出现”的、可以被抽象为对象的东西——应该怎样解析表达式+应该怎样选取底层容器——怎样更加合理地安排整个工程的架构”这样一个“面向对象”但又没完全面向对象的过程。道阻且长,从过程到对象的思维不可能一蹴而就,还需要我慢慢练习。
作业三: 如何进行(糟糕的)迭代开发
3.1 迭代思路
看了第三次的作业,首先庆幸我的顶层直接暴力展开所有自定义函数求和函数的迷惑思路还可以用,接着便开始思考如何实现在三角函数内部存储表达式——答案显而易见,递归。
于是我稍微修改了顶层的展开逻辑和三角函数逻辑后(以及因为递归的各种比较、转化字符串重写了许多CompareTo、toString方法),UML类如下:(红圈为主要改动)

架构的类完全没有改变,但为了支持三角嵌套,我选择在三角函数解析时直接重复调用递归下降,使得层次感稍微有些乱,底层的接口有factors和compareTo两种,同样为了递归的结果类的比较,我们为复合系数类新增了compareTo方法。另外递归的化简我选择放在了结果类中(事实证明这样做很糟糕),输出类只负责调用这些方法并添加必要的括号(这其实是个补丁)
这样做的后果就是复杂度比第二次还高......
| 方法 | 基本复杂度ev(G) | 模块设计复杂度iv(G) | 模块判定结构复杂度v(G) |
|---|---|---|---|
| 所有方法平均值 | 2.81 | 3.90 | 4.82 |
如果对着IDEA里的表格分析一番,会发现这次除了预处理和输出类(特指复杂度爆表的添加括号逻辑)之外,融合到结果类里的化简逻辑和一些toString方法还是红的,这一现象的原因与上次基本一致。不过,方法之外,将化简放在结果类里的害处大抵就是类复杂度会爆炸,如下表:
| 类名称 | 平均圈复杂度 | 最大圈复杂度 | 总圈复杂度 |
|---|---|---|---|
| CompoundCoefficient | 5.67 | 18.00 | 85.00 |
| Proresult | 5.30 | 16.00 | 106.00 |
| Constant | 1.00 | 1.00 | 3.00 |
| Customfunction | 2.67 | 4.00 | 8.00 |
| Power | 1.33 | 2.00 | 4.00 |
| Sumfunction | 2.50 | 3.00 | 5.00 |
| Trigonometric | 2.33 | 5.00 | 28.00 |
| Lexer | 3.33 | 6.00 | 20.00 |
| Parser | 4.25 | 8.00 | 17.00 |
| Main | 3.00 | 3.00 | 3.00 |
| Out | 7.00 | 19.00 | 21.00 |
| Preprocess | 4.50 | 15.00 | 27.00 |
| 平均值 | 4.79 | 8.33 | 27.25 |
所以,看着右上角的85和106的复杂度,感慨为什么要偷懒,真的应当再建一个专门用来化简的类啊。放在一起不仅程序巨长(结果类有400行、复合系数类有近300行)难以调试,模块内的“高内聚”也完全没有一点体现。(其实就是懒得再建类了 我认罪)试想,本单元若有第四次作业,可能我还需要对本次的代码进行一些改动,以减轻迭代工作的压力。
另外值得一提深浅拷贝的问题,这回的优化逻辑中我也测出了深浅拷贝的问题,看来使用不可变对象、或者弄明白指针及自己程序何时、怎样需要进行深拷贝都还需要加强学习啊。
3.2 优化与测试
本次的优化点与上次基本一致,这次我进一步优化了三角函数平方和公式的算法,使得系数不相等时也能进行化简(但幂次我仍然判断是否为2,还是不太机智的样子),二倍角由于担心正确性及负优化问题我还是没有做。不过这次的合并同类项方法行数会增长许多(然后我犯了和上次几乎一模一样的锅)。
强测没有测出bug,性能分同样没有做彻底的化简树逻辑扣掉了约3分多点,但是我合并同类项又没考虑外面的幂次,互测又G了(悲)。
即: \(cos(1-x)+cos(x-1)^2\) -> -\(2*cos(x-1)^2\)
看来自己本地的测试做的还是严重不足啊,今后也要向身边的dl们学习如何搭建评测机了。(在一个坑跌倒两次,屑)
3.3 不足和优点
我只想分析不足,感觉没什么优点:
-
写程序的时候断断续续,经常写一半不知道干啥去了,回来接着写导致有的东西能忘了写。
-
真的要把计算逻辑和优化逻辑拆开,不然长度复杂度调试难度全都会爆表。
-
顶层直接展开了字符串,效率真的不如在递归下降中遇到时进行解析
-
(这条其实原因还没那么清楚)程序运行很慢,诸如\(\sum_{i=-120}^{120}i+sin(i)+cos(sin(i))+x+cos(x)+cos(sin(x))\)这种式子有些同学的程序能秒出,而我的程序已经有了\(tle\)的风险了。
-
几乎没有进行输入合法性检验的可扩展性
-
方法名、变量名太——长——了,几乎没法给表格排版
Hack策略&Bug分析(结合复杂度)
由于时间分配的原因,我只在第一周尝试过认真的hack,大致策略为利用python生成大量随机数据,之后利用python的eval函数代入不同的x值,计算相对误差、绝对误差进行对拍。
但这么做非常蠢,无敌蠢
首先,数据生成器无法覆盖所有情况,导致房间里其他人测出的bug我根本没测出来。尤其进行边界压力测试时,随机数据往往不理想。
其次,此方法需要我更改房间里所有人的程序,使得一次可以读入、输出多行消息,但这也太肝了,不如写一个可以迭代开发的评测机。
最后,有的bug的特殊性在于只有读入极其特殊的输入时才能出现,面对这种bug,读代码是效率最高的。
另外,多蹲群,看看有没有什么最新的普遍bug(bushi)
至于具体的hack情况:
-
被hack:三次作业被捅了10刀,出了两个bug,原因竟然一模一样,均为未考虑到三角函数外可能的幂指数。
一方面是写程序时想当然,另一方面是做测试时覆盖的着实不够全面
-
hack他人: 效率属实低下,第一次成功了hack了2人,后两次各1人
(注:水群里有人说某异常不会在评测机报错,导致我直接放弃hack某程序,事后发现此异常是可以被触发的)
另外,是否是圈复杂度高的程序//代码行数多的程序容易出bug呢
对于我自己而言,两次出问题的都是优化逻辑函数,确实是都是复杂度比较高的方法和类,然而,hack到的同学有一些bug出现在相对复杂度没那么高的地方——预处理,暴力替换输入字符串虽然复杂度不高,但着实容易出错。
行数上,对于我自己而言,两次bug中第二次的优化方法是大约40行,第三次是约50行,确实都很长。
一个简易的总结:诚然不用多想,肯定是复杂度越低、行数越短(不压行)的情况下bug越少,这也是我们将复杂的表达式拆分成各个对象,一个个“逐个击破”的原因之一。
三次作业的收获与心得
- 跟上课程安排很重要,闭门造车绝不可取:让我预习我就应该老老实实预习,面对作业上的挑战要多与同学们沟通,不沟通有时候都反应不过来自己的一些想法有多蠢(bushi)。
- 先想好架构再动手写很重要,一顿乱写往往会导致最后写出来的东西架构混乱且bug极多,有时间调试不如早点想好可扩展性好的架构。另外对于迭代式的开发,一定要想好什么是需要抽象为对象的而什么不可以。
- 面向对象编程的思想处处都在,要多加观察,多加练习。回忆大二上的数据结构课,当时python语言的class就是一种类,回顾上学期的Tree大作业,原来里面已经包含了面向对象的思想,只是我完全没有学会而已。将自己写数据结构抽象为一种类加以复用,正好似这几次作业中写出的储存表达式结果的类。
- 道阻且长,阅读他人代码,与他人讨论的过程,深深地感到自己代码能力、知识体系的欠缺。阅读他人的博客,发现他人架构基本上都优于自己的架构,无论是可拓展性上还是复杂度上。另外,自己写代码时往往会出现写了一半拍脑袋,“我去,这个不对!”的情况或者“我去,这个没用!”的情况,这充分说明在今后的学习中还要多加练习,多加思考。
- 最后,随着这一单元的谢幕,希望能够顺利完成接下来几个单元的学习,少出些bug,有了第一单元的经验,也希望自己可以更快的进步~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号