项目展示
团队简介
| 姓名 | 有图有真相 | 博客地址 | 分工 | —— | 姓名 | 有图有真相 | 博客地址 | 分工 |
|---|---|---|---|---|---|---|---|---|
| wyk |  |
链接 | PM | zyc |  |
链接 | 前端 | |
| ly |  |
链接 | 后端 | llj |  |
链接 | 前端 | |
| dxy |  |
链接 | 后端 | tzj |  |
链接 | 前端 |
工程介绍:
开发前
项目目标
在各类表单识别和OCR服务的机器学习模型中,训练数据占据很重要的地位。而真实表单中数据往往涉及用户隐私,不能直接使用,因此需要花费大量的资金和人力伪造一些与真实表单各个字段值相近的“虚假”表单作为训练数据。我们希望能够设计一个表单数据自动化生成工具,它能根据用户提供的空白表单和表单中各个字段的生成要求,自动随机生成多个满足用户要求的标注好的高质量表单,作为训练数据以供各个表单识别项目开发者使用,从而节省花费在训练数据上的人力物力。
预期的典型用户
| 用户信息 | 用户情况 |
|---|---|
| 姓名 | 卡罗尔·狗蛋·史密斯 |
| 用户身份 | 微软表单项目开发测试人员 |
| 用户情况 | 为了测试项目的bug,需要雇用大量的人力来填写表单 |
| 用户痛点 | 大量人力意味着大量的薪水,另外耗时较多 |
| 典型场景 | 新的模型开发出来了,又到了紧张刺激的训练和测试环节,但是真实表单数据,公司有要求不让用,只能花钱请人伪造表单来训练测试了,又费时又费钱。发现有一个自动生成表单数据的项目,可以把数据生成到Azure里,还能下载下来,真是非常方便呀! |
| 用户比例 | 10% |
| 重要性 | *****非常重要,开发测试者的时间非常宝贵,节省下来的时间与财力可以用于更多有意义的事 |
注:此为alpha阶段典型用户,目前剩余的90%用户(即FOTT项目的使用者)使用我们的软件还并不是很方便。在beta阶段完成时,剩余预期用户将能够进一步减少操作步骤,可以流畅的使用我们的软件
预期的用户数量在哪里
预期用户是一些表单数据的使用者(即需要使用人力物力来进行表单填写的人、相关软件的开发者等)和微软表单识别项目的使用者(借助我们的工具会方便很多)。
预期功能描述
| 页面 | 功能描述 | 原型设计 |
|---|---|---|
| Home | 点击New Project,填写相关信息,在Azure上上传好空白表单 |  |
| Tag Editor | 在标签编辑页面下选定已经自动识别好的文字作为tag,并手动划出该Tag下,用户想要采集/生成的数据位置,设置用户想要生成的数据的属性(如生成数量、数据各类型比例,数字大小范围、语言、字体等等) |  |
| Data | 在数据页面下,输入一个整数表示想要生成的数据的数量,点击Generate按钮即可根据用户设置好的表单要求生成一系列训练数据。若用户需要下载生成得到的表单文件(pdf形式)以及相应的标注数据(json格式)自行使用,点击Download即可将数据下载到本地 |  |
| model | 数据生成完成之后,点击Train即可利用生成的数据进行训练,并得到训练中准确率、训练时长、训练模型保存ID等反馈信息 | 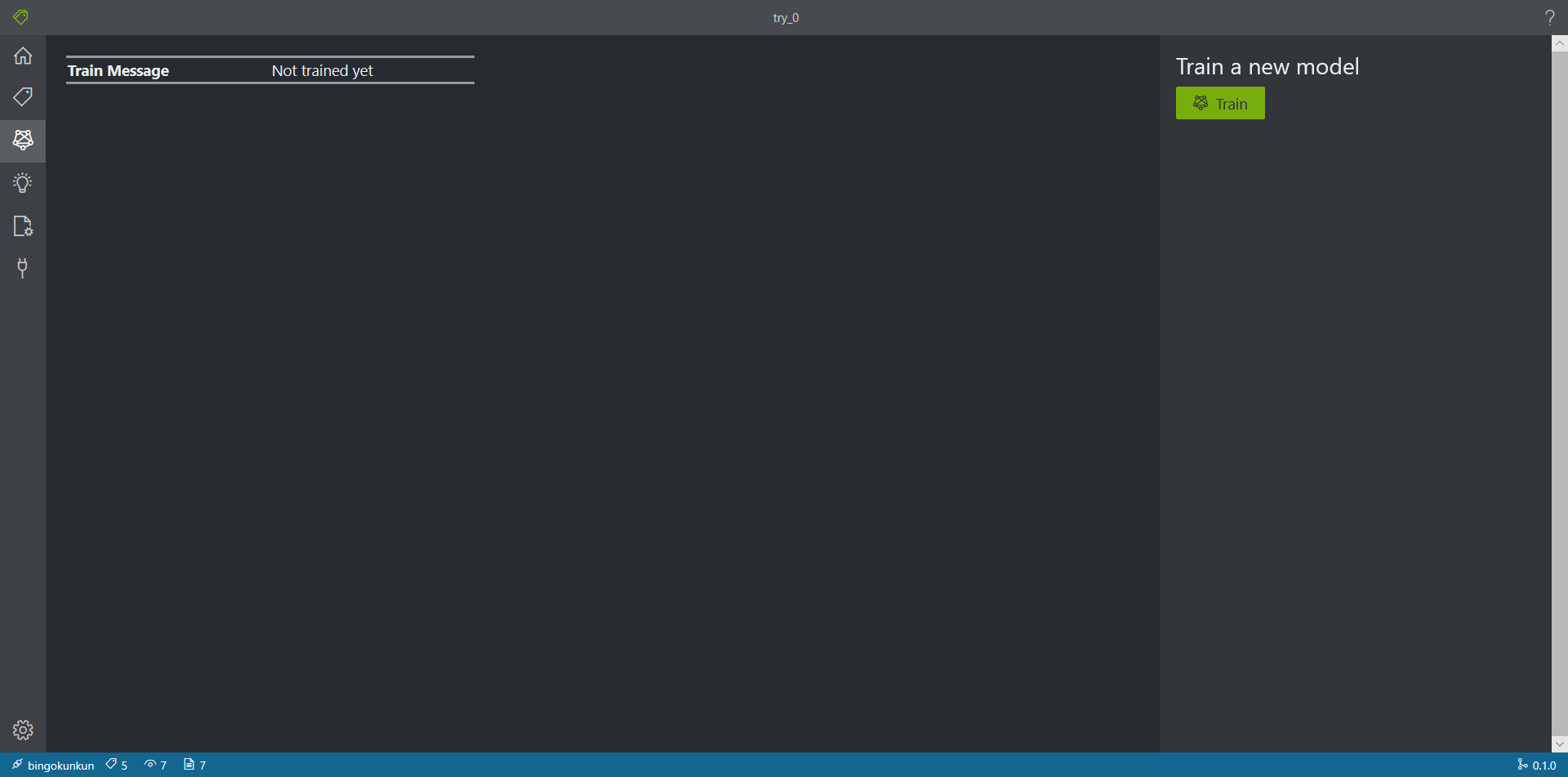 |
注:此为alpha阶段最初的预期页面和功能,在实际开发时有所修改,下文中有提及
开发中
项目管理
使用github进行项目管理,项目地址
实际功能描述
| 页面 | 功能描述 | 页面设计 | 与原计划的对比 |
|---|---|---|---|
| home | 支持新建项目,查看历史项目 |  |
基本功能不变 |
| update | 支持上传任意的空白表单 |  |
在项目最初阶段,对该页面功能并没有进行好的估计,后期出现了上传空白表单的需求后,才增添了该页面 |
| tag | 支持对标签的创建与属性修改,画出数据生成范围 | 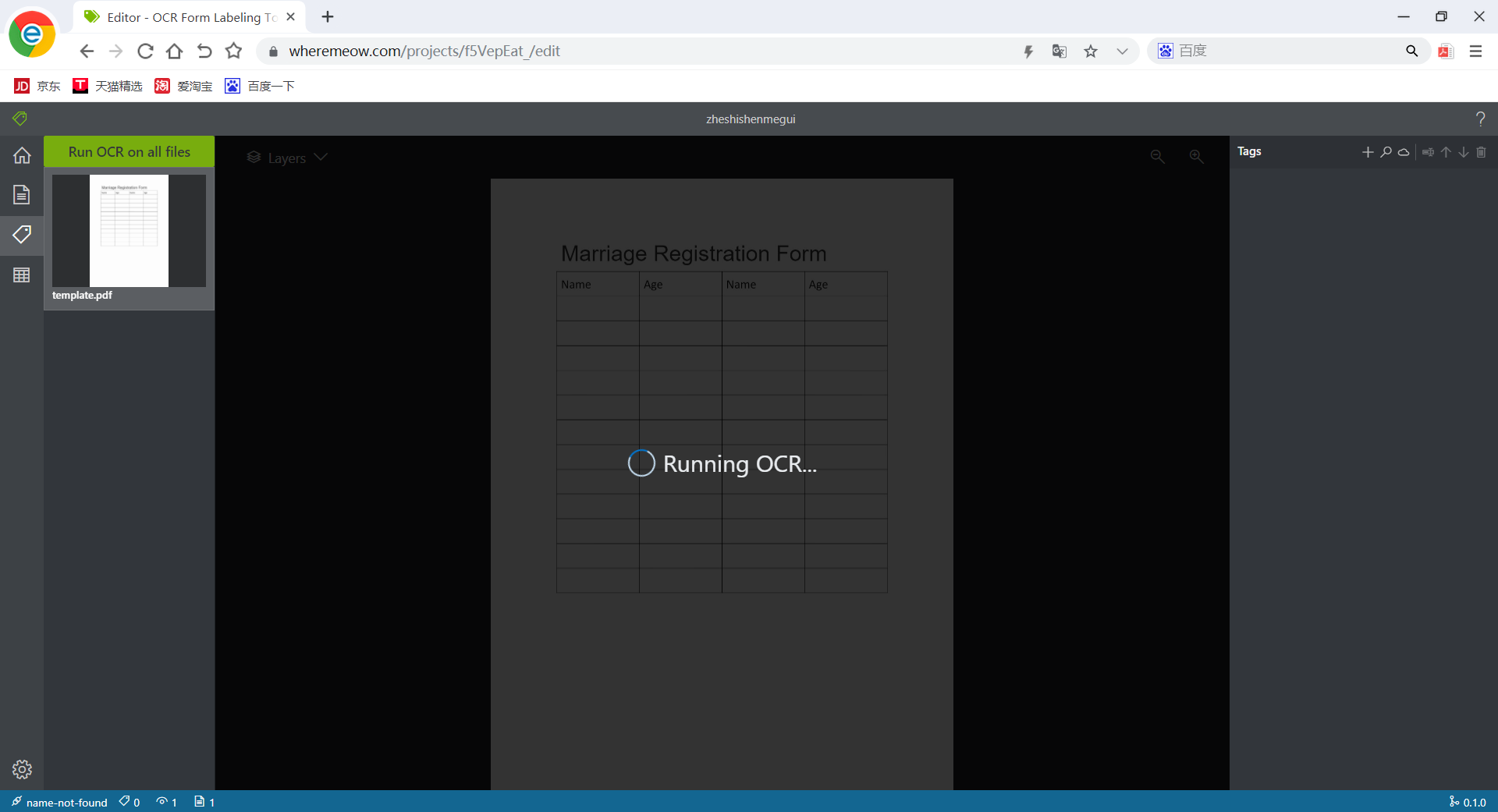 |
与原计划基本相同,数据种类方面增加了几个,并舍弃了原计划中对字体描述等不必要的字段 |
| data | 支持生成任意数量的表单数据 | 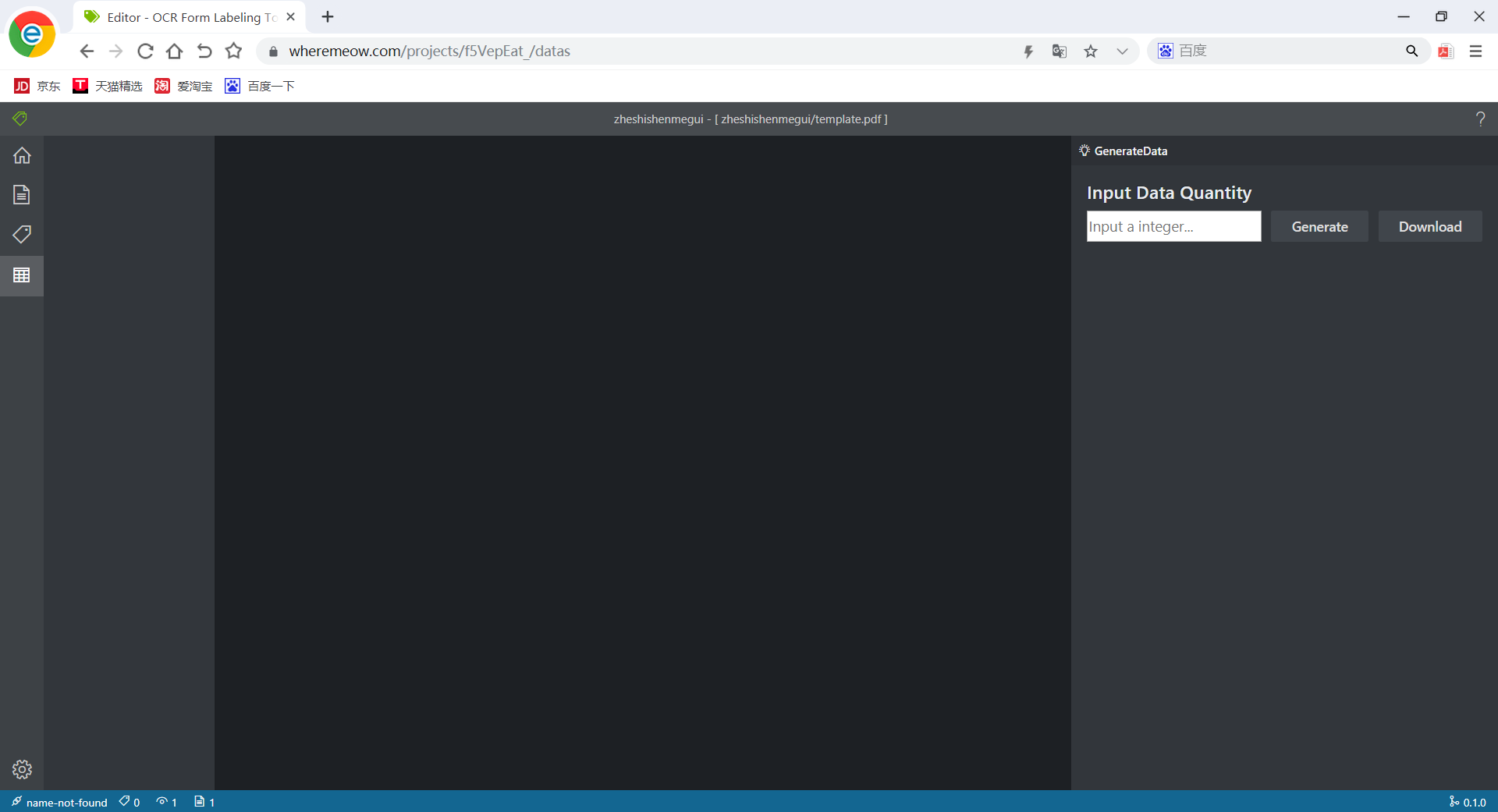 |
与原计划基本相同 |
另外,对于原计划中的model页面,由于涉及了beta阶段的任务,我们在开发过程中对其进行了推延。
代码规范
后端使用Python开发,故采用pylint来进行代码规范,除了部分情况为了满足Azure Functions的特性而忽略了警告和问题提醒。
另外对于后端的每个请求逻辑都用注释说明。
前端使用tslint进行代码规范检查,并且继续沿用了微软原项目中已经配置好的tslint.json的规范,要求tslint不产生任何error信息。以下是前端完成的主要代码部分的tslint检查结果,通过检查没有error。

相关文档
功能规格说明书
技术规格说明书
github README
项目使用说明书
项目使用说明书(英文)
代码的软件工程质量如何?如何用数据来证明?
为了检验我们工程的质量,我们进行了压力测试,当多个用户同时访问时,生成数据的速度和之前相比稍慢一点,但影响不大。
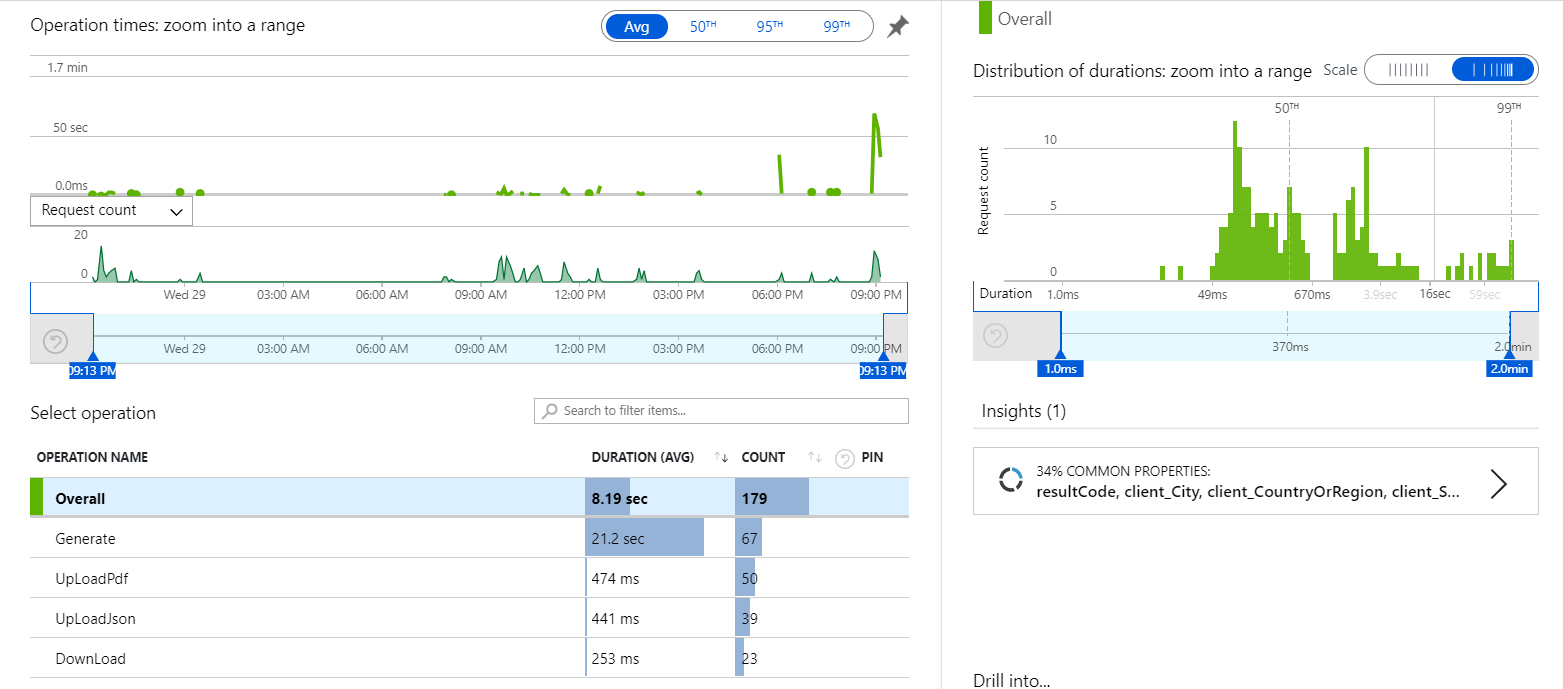
团队如何平衡 时间/质量/资源 争取如期完成任务的?
在资源方面,我们所使用的服务器、开发环境等均能够满足在alpha阶段的需求,因此暂时不纳入考虑。
时间和质量方面,我们是在完成了最小可用版本的前提下,尽可能地去平衡时间因素,完成了最小功能集后,再逐步稳定地提升质量。
项目实际进展
这是第十次例会中的燃尽图。
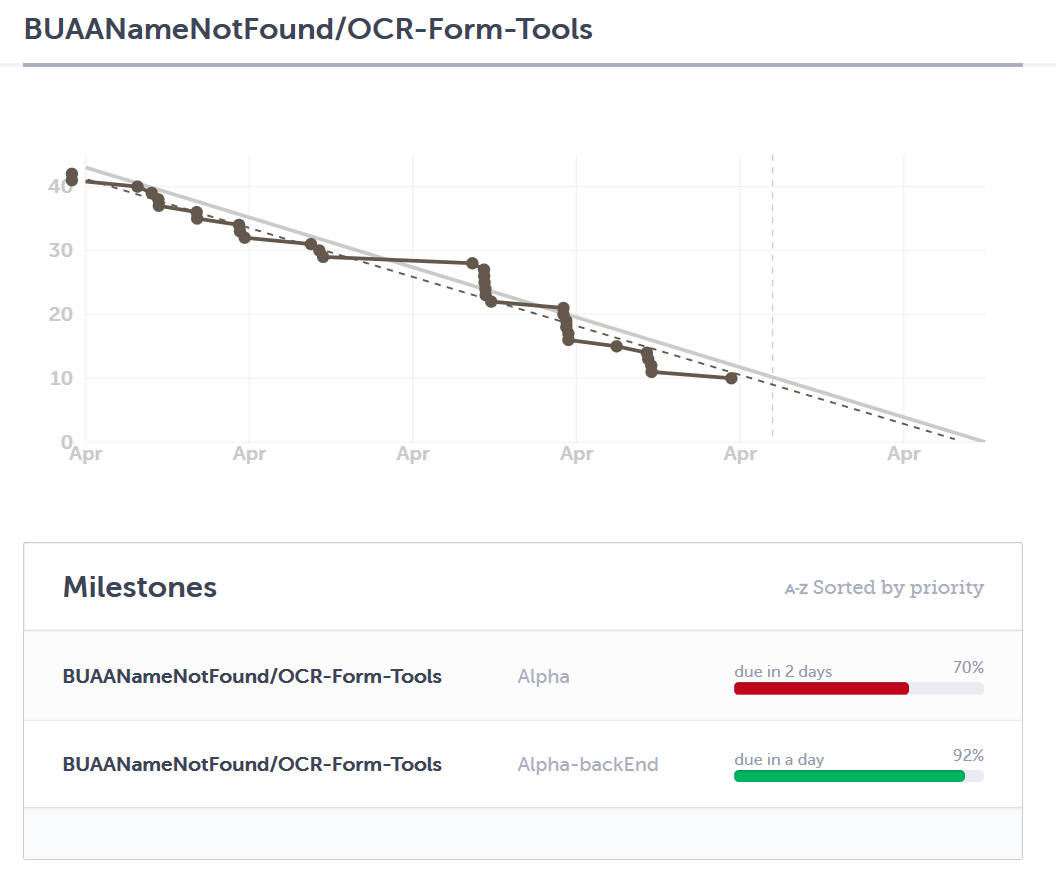
前端完成度较低的原因是前端开了比较多的测试issue,实际上在第十次例会时,我们冲刺阶段的所有任务都已经基本完成。
测试环节
测试用例数目
在alpha阶段,前端会向后端发送4种请求:上传JSON文件(POST)、上传PDF模板(POST)、请求生成(GET)、请求下载(GET)。针对四种情况进行单元测试。
-
上传JSON文件(POST)
请求类别 参数或者数据 是否成功 反馈信息 GET —— 否 Well, please use POST to upload the json file! POST 没有path参数 否 Wrong in path parameter! You should give the path! POST —— 出现异常 Upload failed, please try again! POST —— 是 We have get the data: [上传的JSON数据] -
上传PDF模板(POST)
请求类别 参数或者数据 是否成功 反馈信息 GET —— 否 Well, you should use POST to upload pdf template! POST 没有path参数 否 Wrong in path parameter! You should give the path! POST —— 出现异常 Upload failed, please try again! POST —— 是 We have get the data! -
请求生成(GET)
请求类别 参数或者数据 是否成功 反馈信息 GET|POST 没有path参数 否 Wrong in path parameter! You should give the path! GET|POST —— 异常 readjson and getlabel wrong! GET|POST —— 异常 genData wrong! GET|POST —— 异常 open mark fail! GET|POST —— 成功 We have generated * files! You can just download them! -
请求下载(GET)
请求类别 参数或者数据 是否成功 反馈信息 GET|POST 没有path参数 否 Well, you should give the 'path' parameter! GET|POST —— 出现异常 DownLoad wrong, please try again! GET|POST —— 是 pdf和对应的JSON文件zip包
代码覆盖率数目
后端因为采用了Azure Functions的开发环境,Azure没有提供相应的覆盖率测试方案,暂时没有找到替代方案。不过因为开发过程是采用Postman面向测试驱动,且后端流程单一(详情请看测试报告的后端测试方案),几乎不存在分支,在开发过程基本覆盖了所有代码!
前端通过关键文件编写test.tsx文件,配合使用jest工具实现各种方法和事件的单元测试,结果如视频所示。
运行测试用例得到代码覆盖率的视频录像
其他方面的优化
| 出现的问题 | 进行的优化 |
|---|---|
| 生成数据的种类太少 | 在alpha阶段即将结束时,我们对生成数据的种类做了进一步的扩充 |
| 对原项目的bug进行了简单的处理 | 原项目在连续点击两次按键时会出现错误,我们增加了分布式锁,简单地处理了相关问题 |
| 由于服务器部署在美国,导致访问速度非常慢 | 为我们的第一个网址配置了CDN,实现了访问速度的大幅度提升;另外我们还新增了另一个网址,采用位于北京的服务器,和最开始相比,速度提升也是十分显著 |
发布环节
项目发布地址
项目使用过程
用户反馈


用户的简单反馈我们已经进行了处理,如访问速度慢的问题已经解决。剩下的一些问题我们将在beta阶段进行完善。
事先定义的软件下载量达到了么?为什么没有达到?
预计的用户数量是100左右,生成的表单数量约在400个左右。
由于我们的项目受众并不是学生群体,而我们目前在短期时间内只能向同学们推广,因此软件的预期下载量很可能并不能达到相应的标准。
但值得欣慰的是,截止5月5日21:15,我们的项目创建数量达到了94个,generate的次数达到了339,除去我们的测试数据,也比较可观,这说明我们基本上完成了预期。
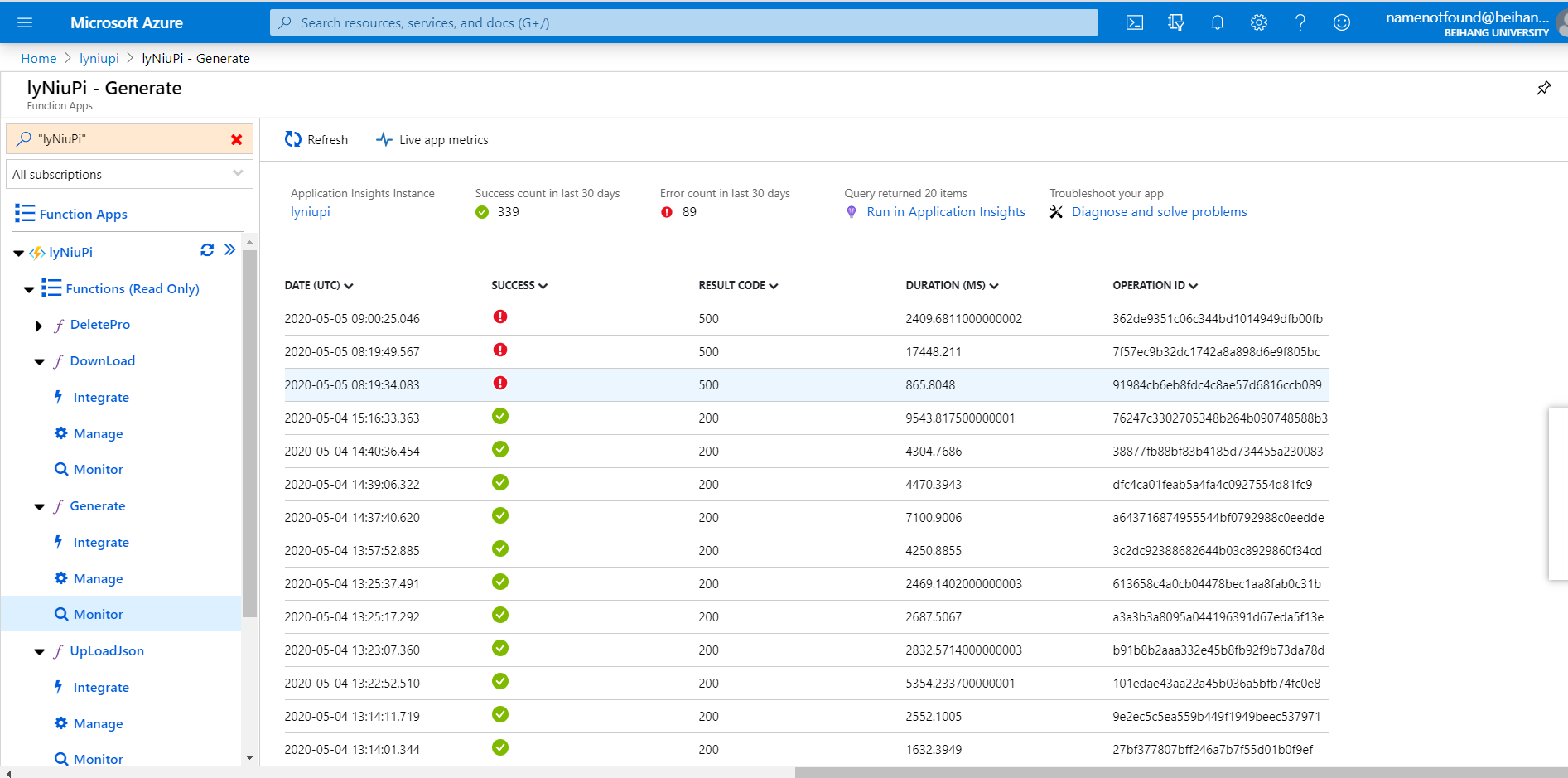
现阶段存在的bug
- 网络问题引起的bug
- 网络问题引起的bug较多,且无法复现,例如tag标记有时会莫名其妙的消失;新建项目时会简单的报错但等一会还是正常运行;点击某些按钮时由于等待时间较长会弹出一些奇怪的东西等。这一问题目前我们没有想到好的解决办法,希望在beta阶段能够得到改善。
- 微软原项目遗留bug
- 我们的前端开发在很多地方使用了微软原项目的代码,因此原项目在使用中遇到的bug,很大程度上会在我们的项目中出现。例如连续点击两次生成按钮时,网页会出现错误,我们利用分布式锁进行了修改,但并没有彻底解决。另外,这些bug很难复现,且部分也是由于网络问题引起的,后续我们会尽可能地继续研究原项目的代码,尝试着让我们的项目避开这些bug问题。
总结
成员贡献
| 成员 | 代码行数 | 参与的博客/文档 | 测试用例数量 | 发现的bug数量(已经修复的数量) | 推广和调查次数 | 其他方面 | 互评后得分 |
|---|---|---|---|---|---|---|---|
| zyc | 533 | 1 | 3 | 1(1) | 1 | 前端服务器的部署 | 52 |
| tzj | 713 | 1 | 15 | 6(5) | 3 | 端到端测试 | 51 |
| llj | 220 | 1 | 5 | 2(2) | 2 | 视频教程的制作 | 48 |
| ly | 417 | 4 | 12 | 11(9) | 5 | 视频教程文字初稿 | 53 |
| dxy | 361 | 2 | 9 | 2(2) | 1 | 英文稿修改、数据库整理 | 49 |
| wyk | 0 | 20 | 1 | 3(1) | 8 | 开发后期的issue管理、组织例会 | 47 |
现阶段学到了什么
-
后端:
-
ly
首先,之前没有接触过Azure Functions,这是第一次使用VS Code和Azure开发相应的软件。过程中查阅了很多的文档说明,google了很多没有遇到的难题,还遇到了和数据生成模块的严重对接问题(因为Azure Functions无法创建和使用临时文件导致数据生成失效),经过多方尝试,最终解决了这一问题(采用Azure storage作为临时存储)二就是团队交流,我们的团队整体上合作意识很强,大家都愿意主动探讨问题,寻求解决方案或者代替方案。不过如何有效的交流是我学习到的一点,我们经常会遇到探讨问题不是同一个的情况,究其原因是线上有时不太容易表达真实意思。因此建议首先表明自己的观点,待其他人理解后继续沟通。
三是对于需求的明确,团队在开发初期对于数据生成的需求一直不是特别明确,造成开发和对接的问题,最终经过和zx老师的多番讨论交流,越来越明确数据生成的需求。同专业用户交流可以有效获得需求信息!
-
dxy
首先是对于数据生成部分,这部分虽然逻辑较为简单,但对细节要求较高。出现的问题包括:与合作组员协商不够、与用户协商不够等导致反复修改数据格式。由于数据需要带有真实性,所以最初的生成名字是通过数据库检索,所以根据1940-2010年新生儿名字频率统计进行生成,实现较为繁琐,且效果并没有那么好,与用户需求有较大差距。后来使用打表的方式直接进行随机组合。
之后是对于pdf生成部分,这部分学习了pypdf2与reportlab两个库,同时还了解了itext的使用方法。出现的问题包括:生成数据的换行问题、数据的方向问题等。由于使用的部分数据较长,而一般情况下表格的空白部分较短,所以对于地址等信息需要分行输出,这里对于坐标的计算比较繁琐。并且,由于缺乏对数据位置的约定,在生成pdf时出现了倒转的现象。后来经过处理,将pdf生成做得较为完善。
最后是得到的收获,最为重要的一点就是团队之间的交流,只有在实现功能时,各个相关模块的接口是约定好的,才可以最大限度的减少重构等问题。还有,需要明确使用者的需求,对于数据的展示格式等要接受用户的反馈。
-
-
前端:
-
zyc
为了添加前端tag标注的功能,修复相关的bug,查阅了很多关于typescript,react的文档,学到了很多前端相关的知识,以及一些库和框架的使用。例如绘制boundingbox时,三种坐标(文档坐标,屏幕坐标,试图坐标)的相互转换,fetch的使用以及许多typescript代码编写时需要注意的规范。此外在做前端部署的时候也积累了一些经验。最开始尝试时直接部署http服务器,结果前端加密部分不能正常工作了,因为相关的库对安全要求很高,必须在https下使用。为了方便使用了netlify进行部署,它会自动使用Let's Encrypt申请SSL证书,部署https服务,但是netlify是在美国的服务器,许多同学表示访问很慢。后来意识到访问速度是一个十分重要的因素,于是将前端服务器部署在了国内,申请了SSL证书,同时也部署了CDN,这样全国的访问速度都很快。这里也吸取了教训,部署线上服务时和测试不一样,不能自己访问快就可以了,一定要验证各种环境下的访问情况。
-
tzj
技术方面,新学习到了许多前端知识如html、css、ts、react等,也接触了一些自动化测试的工具如jest、mockserver等等,代码能力和对复杂项目代码的阅读能力有了一些提高。
团队合作方面,整个团队从萌芽阶段走到了磨合、规范阶段,我也体会到了团队合作开发与一个人单干的区别。从一开始遇到问题自己埋头胡乱探索费时费力,到后来积极与团队其他伙伴交流高效的解决开发、测试中遇到的问题,深切体会到了团队共同开发相比于各自单干是一个1+1远大于2的收益。
软件开发方面,感受到了用户需求分析和最开始的设计文档的重要性。一份好的设计文档包括功能文档和技术文档,往往能让开发变得事半功倍;完善周到的用户需求分析,也是后期软件推广的重要指南。而且由于我们接手邹老师推荐的FOTT项目,邹老师除了老师这一身份也像是一个客户为我们提出开发建议和需求,因此我们也感受到了开发过程中与客户交流的重要性,要及时与客户沟通,明确自己的开发任务和验收标准,才能令客户满意。 -
llj
首先是技术方面,之前只是学习了简单的html和css,在这次开发中接触到的是react框架,并且是在开源代码的基础上进行功能增加,边学习边进行编程的过程让我更快的上手了代码;实现model界面功能的时候需要调用微软官方提供的接口,在这个过程中也感受到了react 的灵活易用;团队开发代码管理是在github平台,通过alpha阶段的开发,我了解到了之前不曾接触到的github操作,也在代码规范方面有了更强的意识。
其次是团队合作方面,这是我第一次比较规范的进行团队项目合作,每位队友都很积极,互相帮助,解决了很多意料之外的问题。在这个过程中我的感受是无论是队友之间还是跟用户,高效的沟通都很重要。跟队友及时的交流可以很快的解决技术难点,跟用户细致的沟通可以明确需求,减少后续修改重构的成本。跟小伙伴一起,可以走得又快又远~
最后是我比较遗憾的一点,由于一开始需求分析不准确,在alpha阶段model界面没有投入使用,希望在beta阶段可以拓展这一功能。
-
-
PM:
相对于之前做过的项目来说,这次的项目算是一个比较大的团队项目了。总的来说开发过程还是比较顺利,没有出现什么难以解决的开发问题和团队沟通问题。
作为一个合格的PM,具备全局性的视野。一个好的项目最重要的目标是按期保质的完成项目。通常情况下,只要是与该目标相违背的事情都需要进行协调。另外,PM要时刻关注项目的整体进度和质量,在保障第一条目标的情况下,可以降低系统部分功能的要求,一定要学会取舍。最后就是合理安排工作量,保证让开发人员既不会因任务过紧而不能完成,也不会由于任务过松而导致资源浪费。只有做到这点,才能带领团队有效推进项目。
beta阶段的计划
| 计划 | 具体内容 |
|---|---|
| model页面 | 在alpha阶段初期我们提出要完成一个model页面,在此页面下,能够显示所有的历史模型,但由于该功能的实现比较麻烦,且并不属于最小功能集的范围,因此在例会时,对其进行了推迟,在beta阶段我们将实现这一功能 |
| 生成数据种类的扩展 | 现阶段我们支持生成的随机数据的种类相对并不完整,后续将继续进行相应的增添 |
| 生成数据属性的详细描述 | 举个例子,我们目前的电话号码只支持美国的单一格式电话号码,后续我们会为用户提供选项:用户想要生成美国的电话号码还是中国的电话号码,手机号、座机号等等都可以供用户选择 |
| 细节完善 | 对alpha阶段的反馈进行完善 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号