
数据库索引
索引可以考虑的数据结构
-
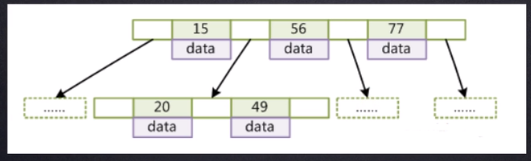
二叉树:会出现单边增长的问题,如果插入的数据是逐条递增的,按照二叉树小的数据在父节点的左边,大的数据在父节点的右边的规则,那么将要插入的数据会全部放在右边,这时查询起来跟没有建立索引之前并没有什么区别,如下面这张图
-
-
叶节点具有相同的深度
-
叶节点的指针为空
-
节点中的数据索引从左到右递增排列
-
-
-
-
-
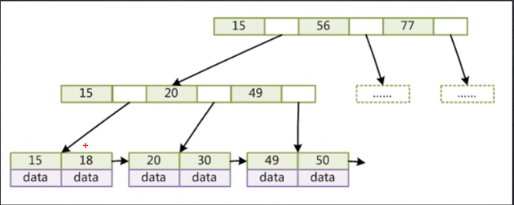
非叶子节点不存储data,只存储索,可以放更多的索引
-
-
非叶子节点上面的数字表示范围,空格处存一个指针,指向存储这个范围的数据页,譬如上面15到20之间的指针指向的就是存储15到20的数据页,假如现在查找索引是30的数据,先来到根节点发现30大于15小于56,那么去15到56的空白处查找,空白处指向最左边的节点,在最左边的节点中查询30在20到49之间,那继续在20到49之间的空格处查找,空格指向的数据页就存储着索引为30的数据
-
假设mysql使用bigint存储数据,那个一个数占8个字节,innodb引擎中一个指针大小为6个字节,加起来是14b,一个数据页16k,那么一个数据也可以存储1170个这样的数据跟指针,那么三层高度的B+树可以存储大概1170*1170*16个数据(假设一条数据占1k),大概是两千多万行数据
-
-
叶子节点不存储指针
-
-
数据库引擎使用的比较多的就是innodb跟MYISAM
MYISAM
MyISAM索引文件和数据文件是分离的(非聚集)
它表现为三个文件,即一张表对应三个文件
-
xxx.frm:这个文件是存储表的数据定义的相关信息的
-
xxx.MYD:这个文件是存储表中所有的数据行
-
xxx.MYI:这个文件存储表的索引
INNODB
INNODB引擎的索引文件跟数据文件是聚焦的
INNODB引擎存储表只有两个文件
-
xxx.frm:存储表的数据定义相关的信息
-
xxx.ibd:存储表的数据以及索引数据
-
该表文件本身就是按照B+Tree组织的一个索引结构文件
-
该文件中的索引叫做聚集索引,叶节点包涵了完整的记录
-
这也就是为什么innodb表中必须有主键的原因,没有主键就无法组织文件结构,并且一般推荐使用整型作为自增主键
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号