缓存在计算机的应用点。
前言
这篇文章主要记录平时了解到计算机缓存在程序中的一些应用。只是个人的总结。
1.Array和LinkedList,删除第N个数字,谁更快?
答案:链表增删方便,会更加块。
补充:数组查找快,查找第n个数组块。
原因:数组是一整块内存地址。链表是分散的地址。在数组查找的话,一整块的内容数组都会被转移到缓存里,它们内存地址连续,访问更快速。
2.再遍历数组的时候,为什么是从行开始,而不是列开始。
1. 下面实现是否效率可以更高,可以的话写出更高的版本,并说明why
int a[2048][2048];
for(int x=0;x<2048;x++)
{
for(int y=0; y<2048; y++)
{
a[ y ][ x ]++;
}
}
改成
int a[2048][2048];
for(int x=0;x<2048;x++)
{
for(int y=0; y<2048; y++)
{
a[x][ y]++;
}
}
一段是以一行行的形式访问二维数组,第二段是以一列列的形式访问二维数组。
简单介绍一下缓存
在Cache内部是按行存储的,其中每一行称为Cache行(缓存行)。Cache行是Cache与主内存进行数据交换的单位。缓存行的大小一般为2的幂次数字节。
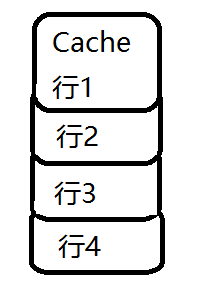
当CPU去访问某个变量时,首先会去看CPU Cache内是否有该变量,如果有则直接从中获取,否则就去主内存里面获取该变量,然后把该变量所在内存区域的一个Cache行大小的内存复制到Cache中。由于存放到Cache行的是内存块而不是单个变量,所以可能会把多个变量存放到一个Cache行中。
回到问题本身,先列后行”遍历发生的页面交换次数要比“先行后列”多,且cache命中率相对较低。例如对于int b[2048][2048];假设内存页大小为4096字节,该数组每行正好占据一个内存页的空间,若按先行后列遍历,外层循环每走一行,内层走过2048个元素正好一页,没发生页面调度,遍历完整个数组页面调度次数最多为2048次;若按先列后行,则每遍历一个元素,都发生一次页面调度,因为列上每个元素位于同行内(不同页), 遍历整个数组页面调度次数可能达到2048* 2048次;实际中由于物理内存足够,调度次数会减少很多。
二维数组在计算机里面怎么存储的
二维数组的存放地址是这样的:
比如定义一个3x3的int类型的二维数组,即每个元素占四个字节,那么就有如下示意图:
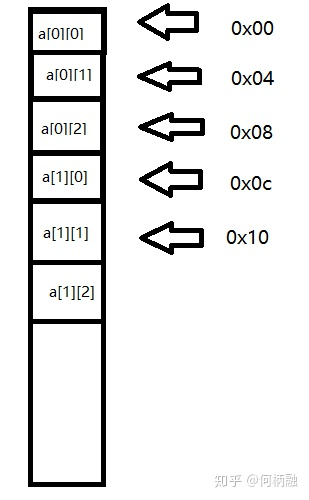
这里是用16进制表示地址0x0c表示12,我们都知道数组的存放地址是连续的,二维数组则是下一行的地址接着在这一行的尾地址上继续添加。所以也是地址也是连续的。
这样的话,当访问数组第一个元素时,会把第一个元素后的若干元素一块放入缓存行,这样顺序访问数组元素时就会在缓存中命中,因而就不会去主内存读取了,后续访问也是这样。也就是说,当顺序访问数组里面的元素时,如果当前元素在缓存没有命中,那么会从主内存一下子读取后续若干个元素到缓存,也就是一次内存访问可以让后面多次访问直接在缓存中命中。而第二段代码是跳跃式访问数组元素的,不是顺序的,这破坏了程序访问的局部性原则,并且缓存是有容量控制的,当缓存满了时会根据一定淘汰算法替换缓存行,这会导致从内存置换过来的缓存行的元素还没等到被读取就被替换掉了。
补充:缓存的大小
如果cache大小大于数组arr大小,cache此时相当于缓存了整个arr数组的内容。那么后续访问其他元素,确实是cache hit。似乎和片段1代码分析结果差不多。但是如果cache的大小很小,例如只有数组一半大小,那么cache命中率就很明显会降低。同样的cache大小,片段1的代码依然会获得很高的cache命中率。
局部性原理
时间局部性
时间局部:如果执行了程序中的某条指令,那么不久后这条指令很有可能再次被执行;如果某个数据被访问过,不就之后该数据很有可能再次被访问。(因为程序中存在大量的循环)
空间局部
空间局部性:一旦程序访问了某个存户单元,在不久之后,其附近的存储单元也很有可能被访问。(因为很多数据在内存中都是连续存放的)。
时间局部性和空间局部性统称为局部性原理。
参考资料:
双重for循环访问二维数组的不同方式 局部性原理 缓存行 cpu jdk解决方案
Cache对代码的影响
Cache的基本原理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号