

埋点服务设计与开发(一)调研阶段
1,概述
操作日志分析服务(OperationLogAnalysis)主要功能是:
- 记录用户操作日志;
- 对用户操作日志进行分析并保存到持久化数据库;
- 将分析结果输出,为产品的设计与优化提供数据支撑;
功能描述:
-
用户操作日志:鼠标点击、文件上传耗时、请求成功与失败等
-
分析结果:各个按钮点击频次、当前用户在线人数、用户活跃时长等
两个业务:
- 日志收集(LogCollector)
- 日志处理(LogProcessing)
2,设计
2.1,系统架构
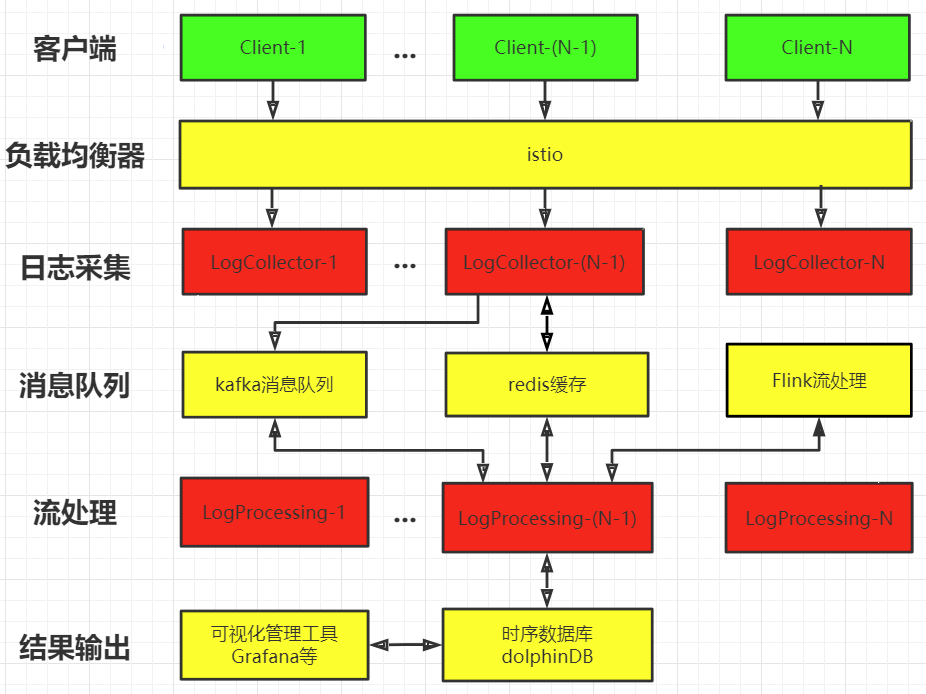
图示中,黄色模块为客户端、红色模块为业务服务端、黄色模块为基础设施服务
2.2,关键节点
客户端
这里的客户端可以是web、IOS、Android或者其他各种形式的client
在进行操作日志记录上报时,先检查是否存在活跃状态连接
- 如果没有,就直接请求创建,创建时需要带上消息里面带上token值进行连接校验
- 如果已经存在,就直接发送记录数据(使用Google ProtoBuf序列化二进制流)即可
负载均衡器
因为操作日志记录是一个很高频的过程,每一个当前活跃账户都需要建立长连接,每一个操作事件都需要进行记录上报,所以【长连接服务】需要进行集群部署满足大量连接、大量数据传输的高性能、高可用要求。因而引出了,需要一个负载均衡器来平衡各个节点的消息处理情况。
日志采集
主要用于操作日志记录数据的透传转发,将前端传输过来的序列化数据直接转发push给kafka消息队列。
消息队列
本项目中用于流量削峰,接受多个【长连接服务】的数据推送push,并等待【流处理服务】进行消费pull。
流处理
操作日志记录是一种无边界、实时产生的数据流,其数据特性比较适合使用Flink流引擎处理。
结果输出
数据处理的结果怎么输出?
- 直接对接前端编写前端 UI 交互页面
- 直接以生成文档然后下载的形式获取
- 其他成熟的数据可视化工具
3,实现细节
3.1,负载均衡器
直接使用istio中的ingress-gateway进行负载均衡,便于集群管理。
3.2,日志采集
首先尝试使用C语言中的NIO或者AIO框架实现,之后在考虑使用Golong或者Rust语言实现,
最后将Java实现作为保底(因为使用Java+Netty实现过相似的功能)。
难点:
-
传输数据格式、规范定义;
-
长连接主动关闭策略;
-
在客户端创建长连接请求时,进行连接许可校验(token校验);
- 校验成功后,才能允许正常连接;
- 否则,直接拒绝。
3.3,流处理
使用Flink流处理框架+dolphinDB时序数据库
难点:
- 如何实现无状态?如果单节点就直接进行数据分析即可,但是多节点进行MQ轮询消费,那么如何解决节点的数据统一?
- 直接使用Flink的多节点功能
- 使用中心redis缓存进行状态存储?将状态由节点转移至redis缓存,从而变成无状态
- 分析的结果需要什么样的?
- 点击频次、日活、月活、事件
- 结果输出形式
- 直接提供接口查询目标数据结构
- 直接使用管理工具显示相关数据
- 开发专门的数据显示页面
- 数据处理是否需要严格按照时序排列?
- 严格要求:①kafka保证消息顺序;②多节点的日志采集,大概率也会有消息顺序紊乱问题;
- 非严格要求(倾向这个):①只要在分钟时间级别是有序即可,因为数据处理的时序紊乱没有特别大影响;②一整个操作事件流程,进行持续收集然后封装成一个消息包发送
4,其他
4.1,整体实现
部署:k8s、istio、helm部署
中间件:Quarkus云原生配置中心、dolphinDB时序数据库、redis缓存、kafka消息中间件、ingress-gateway(istio集成)
业务服务:LogCollector日志收集服务、LogProcessing日志处理服务
产出成果物:
- LogCollector日志收集、LogProcessing日志处理两个服务的docker镜像文件;
- helm整体的系统部署文件 OperationLogAnalysis.yaml (包含所有中间件、服务的部署配置,可平行迁移、扩缩容);
- 设计文档、自测票、使用文档;
4.2,持久化数据库选型
由于操作日志记录的数据量与高并发,因此使用MySQL、postgres等常见的数据库会有性能瓶颈(插入与查询),所以需要选用一款与需求相匹配的数据库。
首先分析一下我们的数据特点:
- 数据插入频次很高、数据修改基本没有、数据读取频次相对较少 ——>必须拥有高性能的插入特性
- 因为用户操作是一个有时间先后的过程 ——> 必须擅长处理时序数据
- 后续可能需要该数据库的性能扩展 ——> 最好支撑集群部署、动态扩缩容、容灾
- 为了方便数据管理、读取 ——> 最好有成熟的数据管理、可视化工具或者插件
- 基于经济的考量 ——> 最好是开源免费的,或者有免费的社区版
- 为了方便后续其他同事进行维护 ——> 最好是社区活跃度较高、使用流行度高
综合一下就是:插入性能、时序处理能力;集群、成熟工具、开源程度、流行度
数据库选型对比
| 数据库 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| MongoDB | 文档数据库 | 1,schema-less 2,扩展分片集群方便 3,网络文档相对较多 |
1,4.4版本前不支持事务 |
| Cassandra | 分布式数据库 | 1,集群扩展方便 2,去中心化(P2P、Gossip) 3,可调复制一致性级别 4,提供了类似于SQL语言的CQL查询语言 |
1,数据冗余度高 |
| influxDB | 时序数据库 | 1,高并发读写 2,拥有适配的管理、可视化工具 3,当前时序数据库流行度第一 |
1,集群功能收费 |
| Kdb+ | 时序数据库 | 1,处理速度相对较快 2,当前时序数据库流行度第二 |
1,32位免费版,有内置的性能限制 |
| dolphinDB | 时序数据库 | 1,开发快、处理速度相对较快、部署快和学习快 2,当前时序数据库流行度排名增长最快 3,支持集群部署 4,有专门的可视化管理样例 5,文档社区活跃 |
1,不开源,但是放开了社区版20年证书 集群2节点,每个节点限制2C8G |
| Prometheus | 时序数据库 | 1,k8s默认的监控与时序数据库 2,开源、云原生基金会项目 3,相对其他时序数据库较为成熟 |
1,专门针对监控数据进行定制 |
| timescaleDB | 时序数据库 | 1,基于PostgreSQL数据库打造 2,完全开源 |
1,本质上是一个 PostgreSQL 的插件, 数据库底层决定了其读强写弱的缺点 2,不支持水平扩展(集群) |
| ElasticSearch | 搜索引擎 | 1,擅长文本搜索 |
1,插入性能一般 |
| GaussDB | 关系型数据库 | 1,人工智能技术融入数据库调整 2,异构计算框架 3,源于PostgreSQL9.2 |
|
| Snowflake | 关系型数据库 | 1,存算分离 | 1,不开源,收费! |
当前综合比对各个NoSQL数据库的优缺点后,相对而言更加倾向于使用dolphinDB数据库,原因:
1,开发快、处理速度相较于其他时序数据库更快、部署快和学习快
2,当前时序数据库流行度排名增长最快
3,支持集群部署、扩缩容、容灾
4,有专门的可视化工具,并且工具中有多种数据处理函数与可视化策略,同样也可以集成Grafana可视化工具
5,文档社区活跃、更新迭代持续进行中、使用样例demo多
6,虽然该数据库不开源,免费版限定了集群、核心、内存的个数,但是这些在前期不需要担心
5,参考链接
- 什么是Flink?Flink能用来做什么?
- 介绍了批处理、流处理的区别与特性
- 介绍了Flink的特性与功能
- 什么场景应该用 MongoDB ?
- 哪些场景下使用MongoDB
- 使用 Kafka + Spark Streaming + Cassandra 构建数据实时处理引擎
- 什么是InfluxDB?跟其他数据库比有哪些优势?
- influxDB 适合做什么?
- 时序数据库timescaledb
- 深入理解什么是 Log Structured-Merge Tree
- DolphinDB高可用集群部署教程
- 时序数据库DolphinDB和TimescaleDB 性能对比测试报告
- 新一代大数据引擎Flink厉害在哪
- Apache Flink官网
- 基于 K8S 的 DolphinDB 部署教程
- DolphinDB GUI
- Prometheus - 时间序列数据库

 浙公网安备 33010602011771号
浙公网安备 33010602011771号