作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
splash是容器安装的,从docker官网上下载windows下的docker进行安装。
下载完成之后直接点击安装,安装成功后,桌边会出现三个图标:

点击 Docker QuickStart 图标来启动 Docker Toolbox 终端。
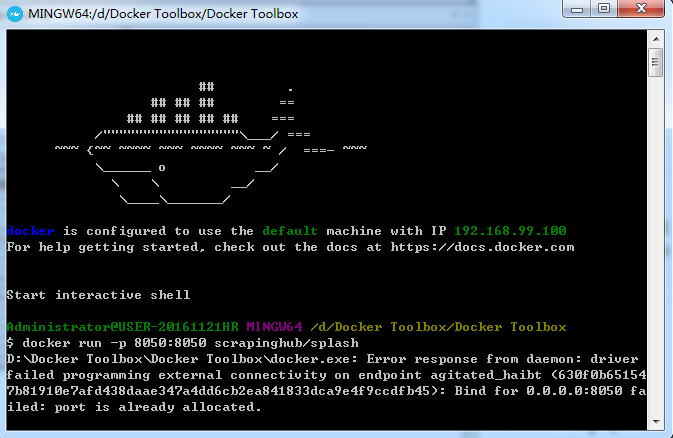
使用docker启动服务命令启动Splash服务
docker run -p 8050:8050 scrapinghub/splash
这里我已经开启服务了打开cmd,在当前目录下开始scrapy爬虫:
scrapy startproject scrapy_examples
在spider文件夹中新建python文件jd_book.py用于编写爬虫
在项目下新建pybook.py用于对数据文件csv处理
京东上的商品是动态加载的,爬取python书籍的前20页,获取每个商品的评论数、书名、简介。
SplashRequest(url,endpoint='execute',args={'lua_source':lua_script},cache_args=['lua_source'])请求页面并执行JS函数渲染页面
endpoint='execute':在页面中执行一些用户自定义的JavaScript代码
args={'lua_source':lua_script}:用户自定义的lua脚本
cache_args=['lua_source']:让Splash服务器缓存该函数
用户自定义的lua脚本中必须包含一个main函数作为程序入口,main函数被调用时会传入一个splash对象(lua中的对象),用户可以调用该对象上的方法操纵Splash。
splash.args属性:用户传入参数的表,通过该属性可以访问用户传入的参数
splash:go方法:类似于在浏览器中打开某url地址的页面,页面所需资源会被加载,并进行JavaScript渲染
splash:wait方法:等待页面渲染,time参数为等待的秒数
splash:runjs方法:在当前页面下,执行一段JavaScript代码
splash:html方法:splash:html()获取当前页面的HTML文本。
middlewares.py随机产生User-Agent添加到每个请求头中
pipelines.py处理爬取的数据并存入数据库
settings.py配置splash服务信息、设置请求延迟反爬虫、添加数据库信息


1 # -*- coding:utf-8 -*-
2 import scrapy
3 from scrapy import Request
4 from scrapy_splash import SplashRequest
5 from splash_examples.items import PyBooksItem
6
7 lua_script ='''
8 function main(splash)
9 splash:go(splash.args.url)
10 splash:wait(2)
11 splash:runjs("document.getElementsByClassName('pn-next')[0].scrollIntoView(true)")
12 splash:wait(2)
13 return splash.html()
14 end
15 '''
16 class JDBookSpider(scrapy.Spider):
17 name = "jd_book"
18 allowed_domains = ['search.jd.com']
19 base_url = 'https://search.jd.com/Search?keyword=python&enc=utf-8&wq=python'
20 def start_requests(self):
21 yield Request(self.base_url,callback=self.parse_urls,dont_filter=True)
22 def parse_urls(self,response):
23 for i in range(20):
24 url = '%s&page=%s' % (self.base_url,2*i+1)
25 yield SplashRequest(url,
26 endpoint='execute',
27 args={'lua_source':lua_script},
28 cache_args=['lua_source'])
29 def parse(self, response):
30 for sel in response.css('ul.gl-warp.clearfix>li.gl-item'):
31 pyjdbooks = PyBooksItem()
32 pyjdbooks['name'] = sel.css('div.p-name').xpath('string(.//em)').extract_first()
33 pyjdbooks['comment']=sel.css('div.p-commit').xpath('string(.//a)').extract_first()
34 pyjdbooks['promo_words']=sel.css('div.p-name').xpath('string(.//i)').extract_first()
35 yield pyjdbooks
1 import scrapy
2
3 class PyBooksItem(scrapy.Item):
4 name=scrapy.Field()
5 comment=scrapy.Field()
6 promo_words=scrapy.Field()
1 from fake_useragent import UserAgent
2 # 随机的User-Agent
3 class RandomUserAgent(object):
4 def process_request(self, request, spider):
5 request.headers.setdefault("User-Agent", UserAgent().random)
1 class SplashExamplesPipeline(object):
2 def __init__(self):
3 self.book_set = set()
4
5 def process_item(self, item, spider):
6 if not(item['promo_words']):
7 item['promo_words'] = item['name']
8 comment = item['comment']
9 if comment[-2:] == "万+":
10 item['comment'] = str(int(float(comment[:-2])*10000))
11 elif comment[-1] == '+':
12 item['comment'] = comment[:-1]
13 return item
14
15
16 import pymysql
17
18 class MysqlPipeline(object):
19 def __init__(self, host, database, user, password, port):
20 self.host = host
21 self.database = database
22 self.user = user
23 self.password = password
24 self.port = port
25
26 @classmethod
27 def from_crawler(cls, crawler):
28 return cls(
29 host=crawler.settings.get('MYSQL_HOST'),
30 database=crawler.settings.get('MYSQL_DATABASE'),
31 user=crawler.settings.get('MYSQL_USER'),
32 password=crawler.settings.get('MYSQL_PASSWORD'),
33 port=crawler.settings.get('MYSQL_PORT'),
34 )
35
36 def open_spider(self, spider):
37 self.db = pymysql.connect(self.host, self.user, self.password, self.database, charset='utf8', port=self.port)
38 self.cursor = self.db.cursor()
39
40 def close_spider(self, spider):
41 self.db.close()
42
43 def process_item(self, item, spider):
44 data = dict(item)
45 keys = ', '.join(data.keys())
46 values = ', '.join(['%s'] * len(data))
47 sql = 'insert into books (%s) values (%s)' % (keys, values)
48 self.cursor.execute(sql, tuple(data.values()))
49 self.db.commit()
50 return item
1 BOT_NAME = 'splash_examples'
2
3 SPIDER_MODULES = ['splash_examples.spiders']
4 NEWSPIDER_MODULE = 'splash_examples.spiders'
5
6 #Splash服务器地址
7 SPLASH_URL = 'http://192.168.99.100:8050'
8
9 #开启Splash的两个下载中间件并调整HttpCompressionMiddleware的次序
10 DOWNLOADER_MIDDLEWARES = {
11 'splash_examples.middlewares.RandomUserAgent':345,
12 'scrapy_splash.SplashCookiesMiddleware': 723,
13 'scrapy_splash.SplashMiddleware': 725,
14 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
15 }
16 #设置去重过滤器
17 DUPEFILTER_CLASS='scrapy_splash.SplashAwareDupeFilter'
18
19 #用来支持cache_args
20 SPIDER_MIDDLEWARES ={
21 'scrapy_splash.SplashDeduplicateArgsMiddleware':100,
22 }
23 # 使用Splash的Http缓存
24 HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
25
26 # Obey robots.txt rules
27 ROBOTSTXT_OBEY = False
28
29 COOKIES_ENABLED = False
30 DOWNLOAD_DELAY = 3
31
32 ITEM_PIPELINES = {
33 'splash_examples.pipelines.SplashExamplesPipeline':400,
34 'splash_examples.pipelines.MysqlPipeline':543,
35 }
36
37 MYSQL_HOST = 'localhost'
38 MYSQL_DATABASE = 'pybooks'
39 MYSQL_PORT = 3306
40 MYSQL_USER = 'root'
41 MYSQL_PASSWORD = 'root'
在Terminal中执行爬虫:scrapy crawl jd_book -o pybooks.csv
将数据存储到数据库并生成csv文件用于分析可视化
![]()
在数据库中查看有1187条信息
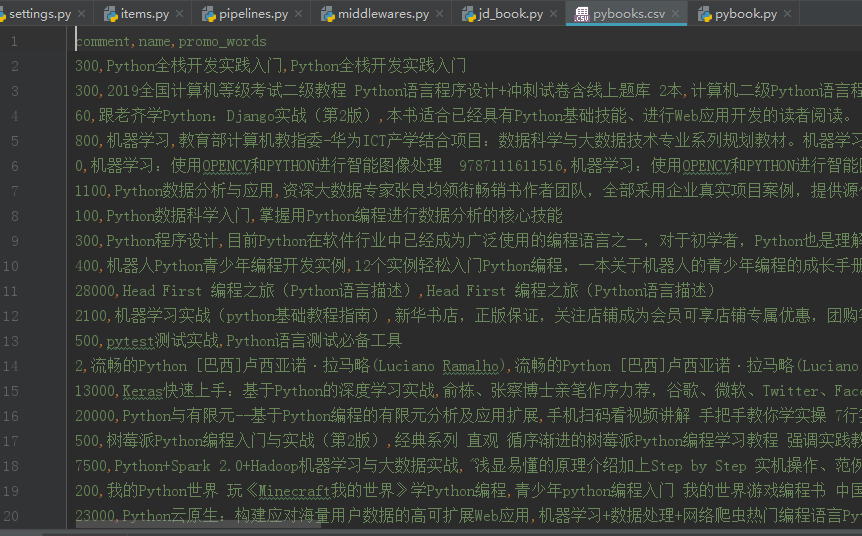

做数据分析可视化
1 import pandas as pd 2 import jieba 3 from wordcloud import WordCloud 4 import matplotlib.pyplot as plt 5 obj = pd.read_csv('pybooks.csv') 6 Books = obj.sort_values('comment',ascending=False)[:200] 7 promoWords = [] 8 for promo in Books['promo_words']: 9 promoWords.append(promo) 10 promoWordsStr = ''.join(promoWords) 11 bookTxt = jieba.lcut(promoWordsStr) 12 stopwords = ['学习','入门','掌握','教程','图书','使用','全面','推荐','读者','专家'] 13 bookTxt = [token for token in bookTxt if token not in stopwords] 14 bookTxtSet = set(bookTxt) 15 txtCount = {} 16 for i in bookTxtSet: 17 if len(i) == 1: 18 continue 19 txtCount[i] = bookTxt.count(i) 20 txtCount = sorted(txtCount.items(),key=lambda key:key[1],reverse=True) 21 TxtStr = ' '.join(bookTxt) 22 ciyun = WordCloud(background_color = '#122',width=400,height=300,margin = 1).generate(TxtStr) 23 plt.imshow(ciyun) 24 plt.axis("off") 25 plt.show() 26 print(txtCount)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号