python爬虫教程
2.1第一个爬虫
python有两种导入模块的方法,分别如下
import urllib.request在程序中就要使用urllib.request.urlopen(url)来调用模块中的函数from urllib import request在程序中使用request.urlopen(url)(和上面的对比没有urllib)
代码解释
request.urlopen(url):获取网页中的数据,输出内容为<http.client.HTTPResponse object at 0x00000209C849B8E0>read():读取网页中的数据,他们是网页html代码。
#import urllib.request
from urllib import request
url = r"http://www.baidu.com/"
# 发送请示,获取响应信息
## read() 读写信息
#reponse = urllib.request.urlopen(url).read()
reponse = request.urlopen(url).read()
print(reponse)
2.2中文处理
decode()解码:会把获取的数据转换成中文encode()编码:str转bytes,字符串转字节
from urllib import request
url = r"http://www.baidu.com/"
reponse = request.urlopen(url).read()
print(type(reponse))
reponse = request.urlopen(url).read().decode()
print(type(reponse))
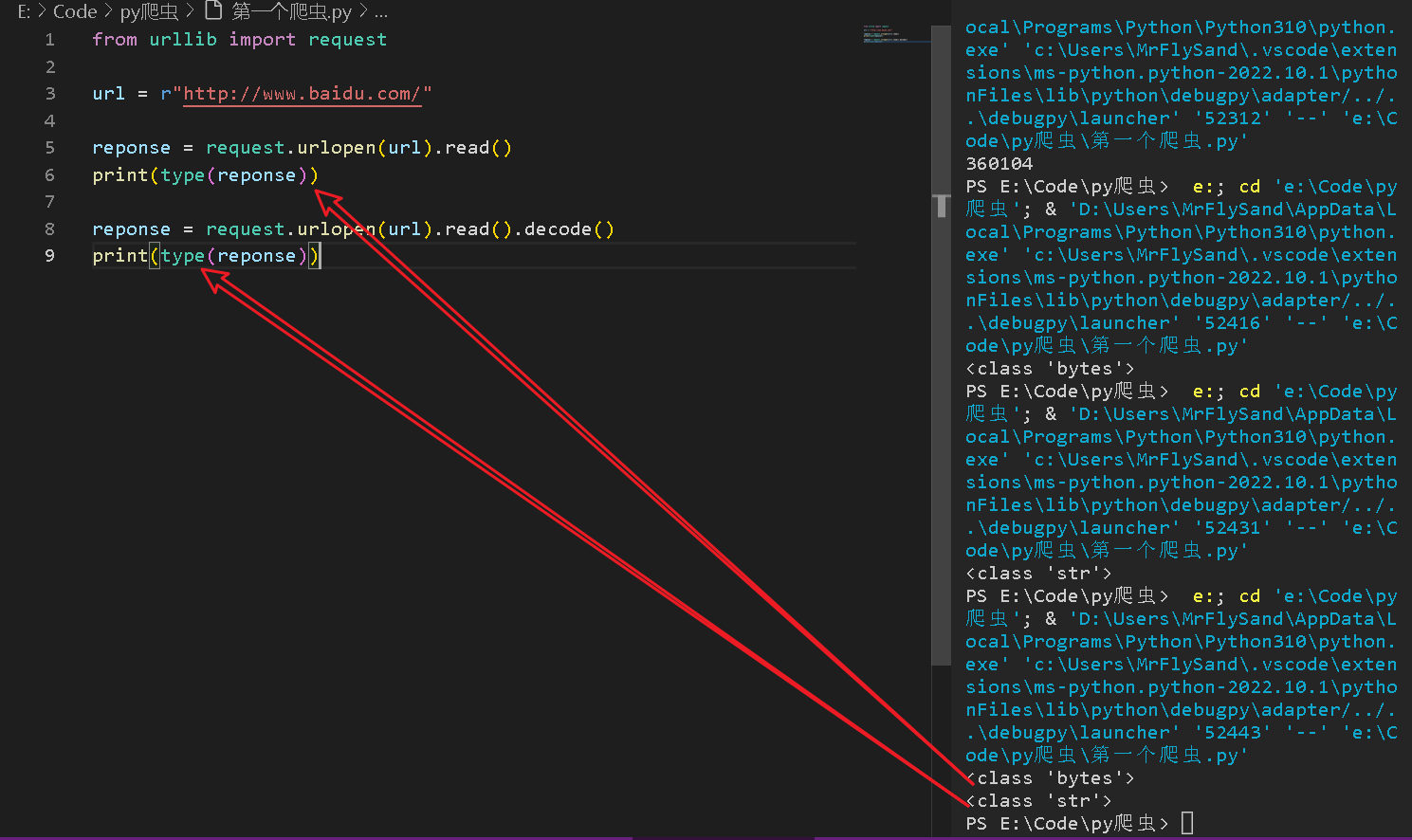
2.2.1输出获取的html代码
from urllib import request
url = r"http://www.baidu.com/"
reponse = request.urlopen(url).read()
print((reponse))
reponse = request.urlopen(url).read().decode()
print((reponse))
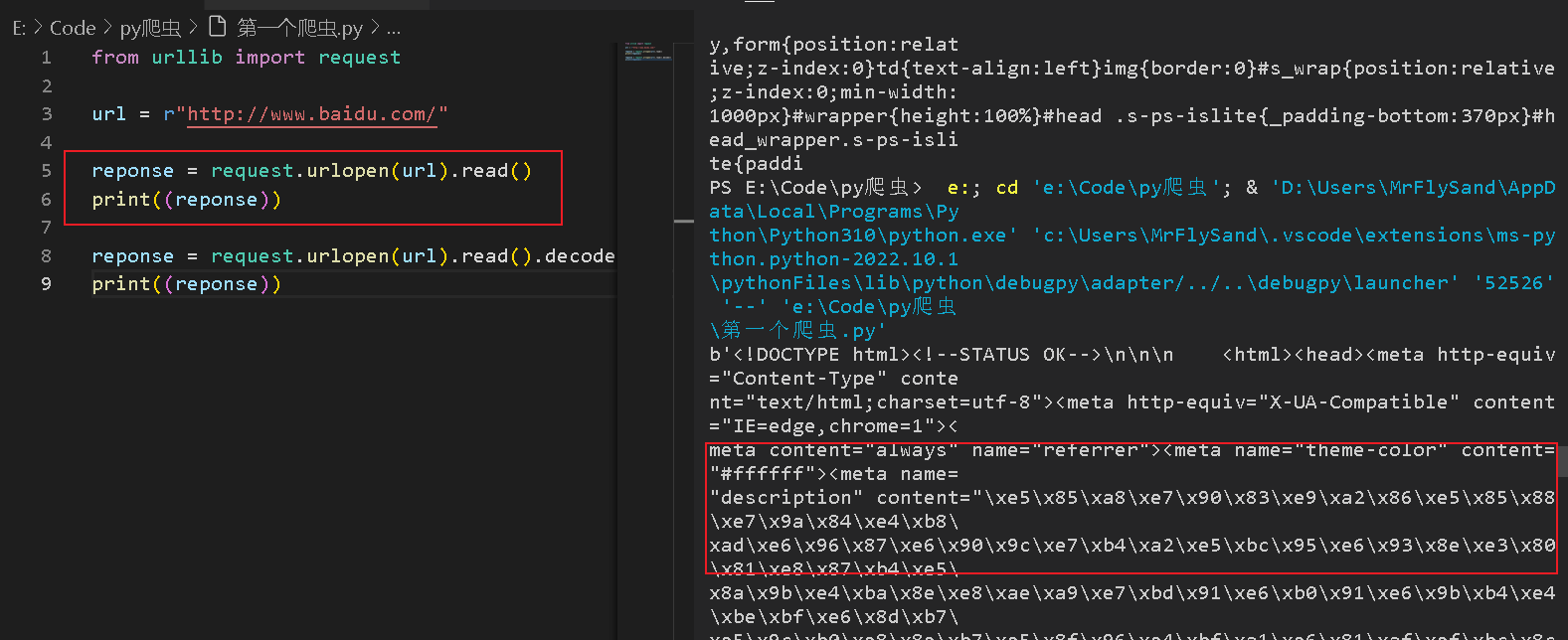
如下图,代码中会出现中文
2.2.2数据清洗
通过正则表达式进行数据清洗re.findall("需要清晰的数据", 获取到的网页html代码),在使用前在代码开头调用import re模块
"<title>(.*?)</title>"括号中的内容会被保留下来,其余的内容会被去掉
from urllib import request
import re #进行数据清洗要导入此模块
url = r"http://www.baidu.com/"
reponse = request.urlopen(url).read().decode()
# 通过正则表达式进行数据清洗
data = re.findall("<title>(.*?)</title>", reponse)
print((data))
输出内容如下:
['百度一下,你就知道']
2.3自定义请求
-
通过
request.Request()创建自定义请求对象,输出内容为<urllib.request.Request object at0x0000024194337C40> -
注意:data是一个列表对象
from urllib import request
import re
url = r"http://www.baidu.com/"
# 创建自定义请求对象
req = request.Request(url)
reponse = request.urlopen(req).read().decode()
pat = r"<title>(.*?)</title>"
# 通过正则表达式进行数据清洗
data = re.findall(pat, reponse)
print((data))
# data是一个列表对象
print(type(data))
print((data[0]))
代码输出:
['百度一下,你就知道']
<class 'list'>
百度一下,你就知道
2.4伪装浏览器原理
反爬虫机制:
- 判断用户是否是浏览器访问
- 可能通过伪装浏览器进行访问
2.5伪装浏览器的爬虫
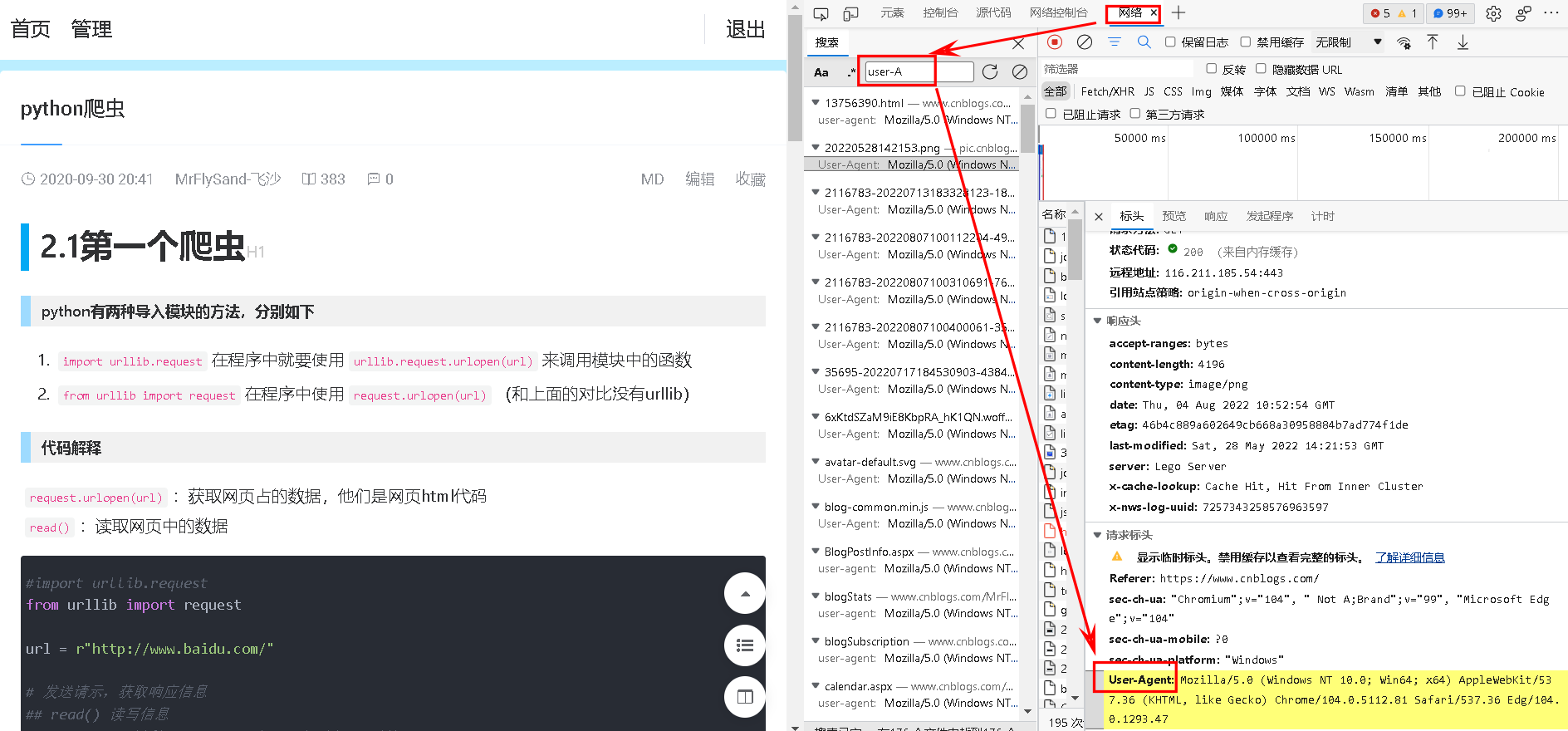
如图,点击【网络】-搜索【user-Agent】获取电脑端的网络头
from urllib import request
import re
url = r"http://www.baidu.com/"
# 创建自定义请求对象,反爬虫机制
req = request.Request(url)
# 构造请求头信息
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47"}
reponse = request.urlopen(req).read().decode()
pat = r"<title>(.*?)</title>"
# 通过正则表达式进行数据清洗
data = re.findall(pat, reponse)
print((data))
# data是一个列表对象
print(type(data))
print((data[0]))
以上代码运行效果如下:
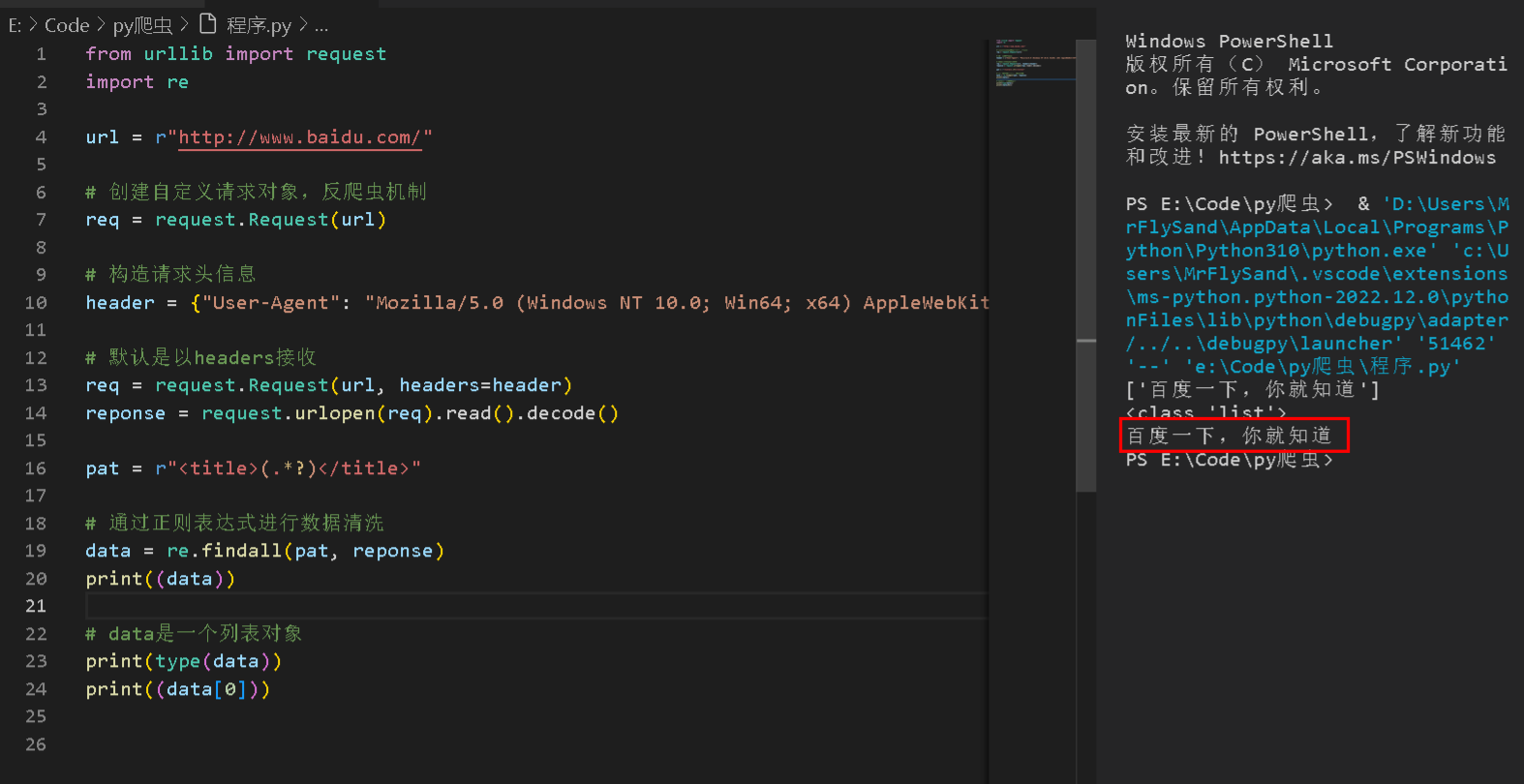
当把上面的代码改为手机版的User-Agent:
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47"}
运行效果就会改变,如下图:
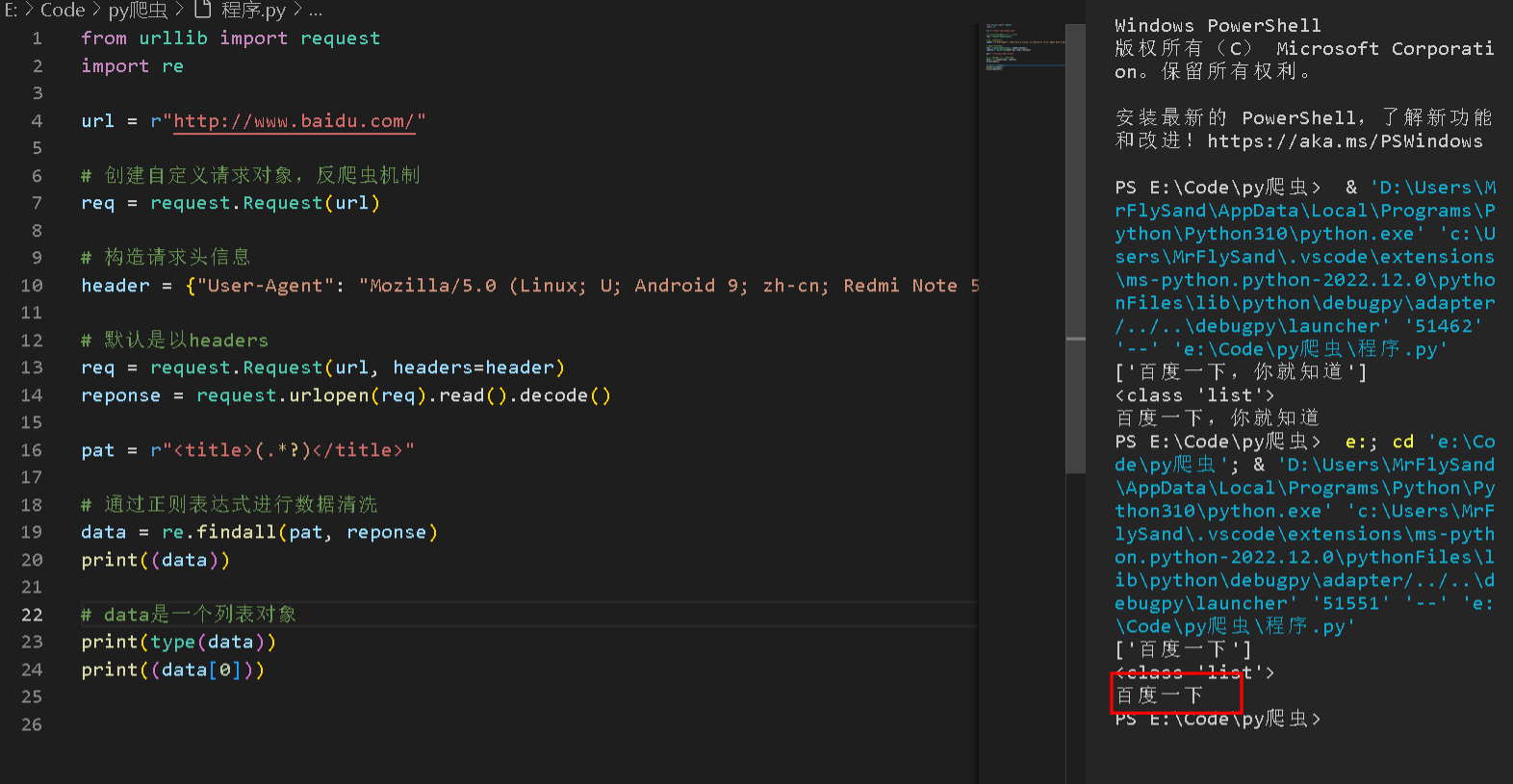
2.6添加多个UserAgent
在短时间内对一个网站多次发送请求,对方的网站会怀疑这是一个爬虫程序。所以要在程序中多设置几个UserAgent(请求头)
import imp
from urllib import request
import re
import random
url = r"http://www.baidu.com/"
# 创建自定义请求对象,反爬虫机制
req = request.Request(url)
# 创建多个请求头到列表中
list1 = ["Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47","Mozilla/5.0 (Linux; Android 9; MI 6 Build/PKQ1.190118.001; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/76.0.3809.89 Mobile Safari/537.36 T7/11.20 SP-engine/2.16.0 baiduboxapp/11.20.2.3 (Baidu; P1 9)","Mozilla/5.0 (Linux; Android 10; EVR-AL00 Build/HUAWEIEVR-AL00; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/74.0.3729.186 Mobile Safari/537.36 baiduboxapp/11.0.5.12 (Baidu; P1 10)","Mozilla/5.0 (Linux; Android 8.1.0; PBAM00 Build/OPM1.171019.026; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/76.0.3809.89 Mobile Safari/537.36 T7/11.20 SP-engine/2.16.0 baiduboxapp/11.20.0.14 (Baidu; P1 8.1.0) NABar/2.0","Mozilla/5.0 (Linux; Android 10; HMA-AL00 Build/HUAWEIHMA-AL00; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/66.0.3359.126 MQQBrowser/6.2 TBS/045130 Mobile Safari/537.36 MMWEBID/6002 MicroMessenger/7.0.12.1620(0x27000C36) Process/tools NetType/WIFI Language/zh_CN ABI/arm64"]
# 构造请求头信息,通过随机函数使用UserAgent
header = {"User-Agent": random.choice(list1)}
# 默认是以headers
req = request.Request(url, headers=header)
reponse = request.urlopen(req).read().decode()
pat = r"<title>(.*?)</title>"
# 通过正则表达式进行数据清洗
data = re.findall(pat, reponse)
print((data))
# data是一个列表对象
print(type(data))
print((data[0]))
2.7自定义opener
from urllib import request
# 构建处理器对象(专门处理http请求的对象)
http_hander = request.HTTPHandler()
# 创建自定义opener
opener = request.build_opener(http_hander)
# 创建自定义请求对象
req = request.Request("http://baidu.com")
# 发送请求,获取响应
opener.open(req)
print(open)
2.8设置opener为全局
from urllib import request
# 构建处理器对象(专门处理http请求的对象)
http_hander = request.HTTPHandler()
# 创建自定义opener
opener = request.build_opener(http_hander)
# 创建自定义请求对象
req = request.Request("http://baidu.com")
# 发送请求,获取响应
#reponse = opener.open(req).read()
# 把自定义opener设置为全局,这样用urlopen发送的请求也会被自定义的opener
request.install_opener(opener)
reponse = request.urlopen(req).read()
print(reponse)
2.9使用代理ip
- 反爬虫机制2:判断请求来源的ip地址是否一直重复请求,如果一直是同一ip请求就是爬虫
- 措施:使用代理ip,可以百度搜索“代理ip”,将不同的ip放入列表中
proxylist = [{"http","223.82.60.202:8060"}],有些代理ip可能不能使用,所以代理ip越多越好。
import imp
from urllib import request
import random
from weakref import proxy
proxylist = [
{"http","223.82.60.202:8060"},
{"http","223.82.60.202:8060"},
{"http","223.82.60.202:8060"},
{"http","223.82.60.202:8060"},
{"http","223.82.60.202:8060"},
]
proxylist = random.choice(proxylist)
# 构建代理处理器对象
proxyHandler = request.ProxyHandler(proxy)
# 创建自定义opener
opener = request.build_opener(proxyHandler)
# 创建请求对象
req = request.Request("http://www.baidu.com")
opener.open(req)
res = opener.open(req)
print(res.read())
2.11处理get请求
urllib.parse.urlencode(text)text是英文网址原样不变,如果text是中文就会转换成英文的。
from urllib import request
import urllib
url = "https://cn.bing.com/search?"
wd = {"q":"飞沙"}
# 构造url编码
wdd = urllib.parse.urlencode(wd)
url = url + wdd
print(url+"\n")
req = request.Request(url)
request = request.urlopen(req).read().decode()
print(request)


2.12实战-贴吧爬虫
- 观察页面的链接
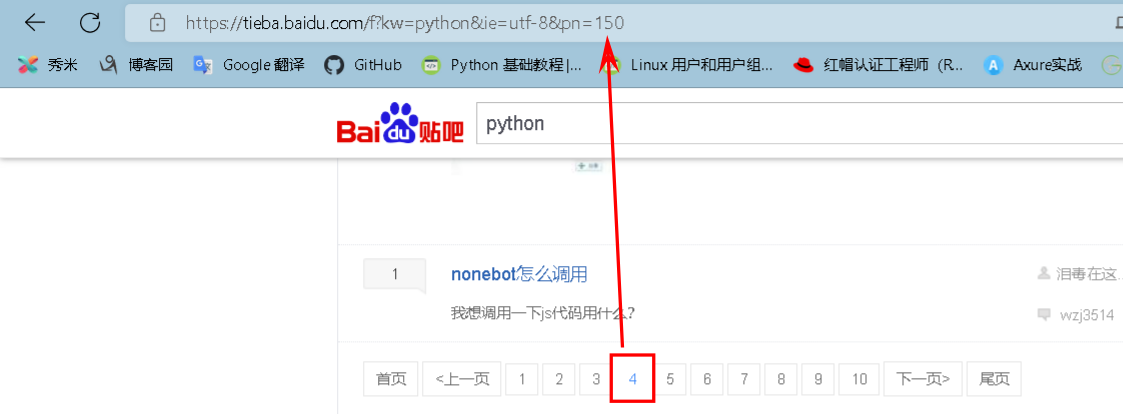
第一页:https://tieba.baidu.com/f?ie=utf-8&kw=python&fr=search
第二页:https://tieba.baidu.com/f?kw=python&ie=utf-8&pn=50
第三页:https://tieba.baidu.com/f?kw=python&ie=utf-8&pn=100
第四页:https://tieba.baidu.com/f?kw=python&ie=utf-8&pn=150
from urllib import request
import urllib
import time
# 构造请求头信息
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47"}
# 下载html代码
def loadpage(fullurl, filename):
print("\n正在下载:", filename)
# 请求网页html代码
req = request.Request(fullurl, headers = header)
resp = request.urlopen(req).read()
return resp
# 写入文件
## html:获取的html网页代码
## filename:创建的文件名称
def writepage(html,filename):
print("正在保存", filename)
#wb表示二进制文件格式写入filename文件中
with open(filename, "wb") as f:
f.write(html)
def tiebaSpaider(url, begin, end):
# 获取第1~5页
for page in range(begin, end+1):
# 每次请求的完整url
fullurl =url+str((page-1)*50)
filename = "C:/Users/MrFlySand/Desktop/testPy/"+str(page)+"页.html"
html = loadpage(fullurl, filename)# 调用爬虫爬取网页
writepage(html,filename)# 把获取的网页信息写入本地
if __name__ == "__main__":
kw = input("请输入贴吧名称:")
begin = int(input("请输入起始页:"))
end = int(input("请输入结束页:"))
url = "https://tieba.baidu.com/f?"
# 构造url编码
key = urllib.parse.urlencode({"kw":kw})
tiebaSpaider(url+key, begin, end)
2.16实战-有道翻译
- 功能介绍:输出“飞沙”进行翻译,输出“flysand”

urllib.parse.urlencode()构造formdata编码
from urllib import request
import urllib
import re
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47"}
url = "https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
key = "飞沙"
# input("请输入内容:")
# post请求需要提交的数据
formdata = {
"i":key,
"from":"AUTO",
"to":"AUTO",
"smartresult":"dict",
"client":"fanyideskweb",
"salt":"16606084281166",
"sign":"097c19675ab94536be3851055d802544",
"lts":"1660608428116",
"bv":"08c34ed4d2214384c56440d4bcb8a187",
"doctype":"json",
"version":"2.1",
"keyfrom":"fanyi.web",
"action":"FY_BY_REALTlME",
}
# 将需要翻译formdata的数据进行编码
data = urllib.parse.urlencode(formdata).encode(encoding='utf-8')
'''注释
data = b'i=%E9%A3%9E%E6%B2%99&from=AUTO&
to=AUTO&smartresult=dict&client=f
anyideskweb&salt=16606084281166&s
ign=097c19675ab94536be3851055d802
544<s=1660608428116&bv=08c34ed4
d2214384c56440d4bcb8a187&doctype=
json&version=2.1&keyfrom=fanyi.we
b&action=FY_BY_REALTlME'
'''
'''
url:请求的网站
data:需要获取的的内容
headers:爬虫的网络头
'''
req = request.Request(url, data, headers=header)
# req = <urllib.request.Request object at0x000001FCA794BC10>
# request.urlopen()获取网页中的数据
resp = request.urlopen(req).read().decode()
'''注释
resp = {
"type":"ZH_CN2EN",
"errorCode":0,
"elapsedTime":1,
"translateResult":[
[{
"src":"飞沙",
"tgt":"Fly sand"
}]
]
}
'''
# 正则表达式,提取
pat = r'"tgt":"(.*?)"}]]'
result = re.findall(pat,resp)
print(result[0])
2.19异常处理
from urllib import request
list = [
"http://baidu.com",
"http://baidu.com",
"http://mrflysand",
"http://baidu.com",
"http://baidu.com",
]
i = 1
for url in list:
data = request.urlopen(url)
print("第",i,"请求:",data)
i =i + 1
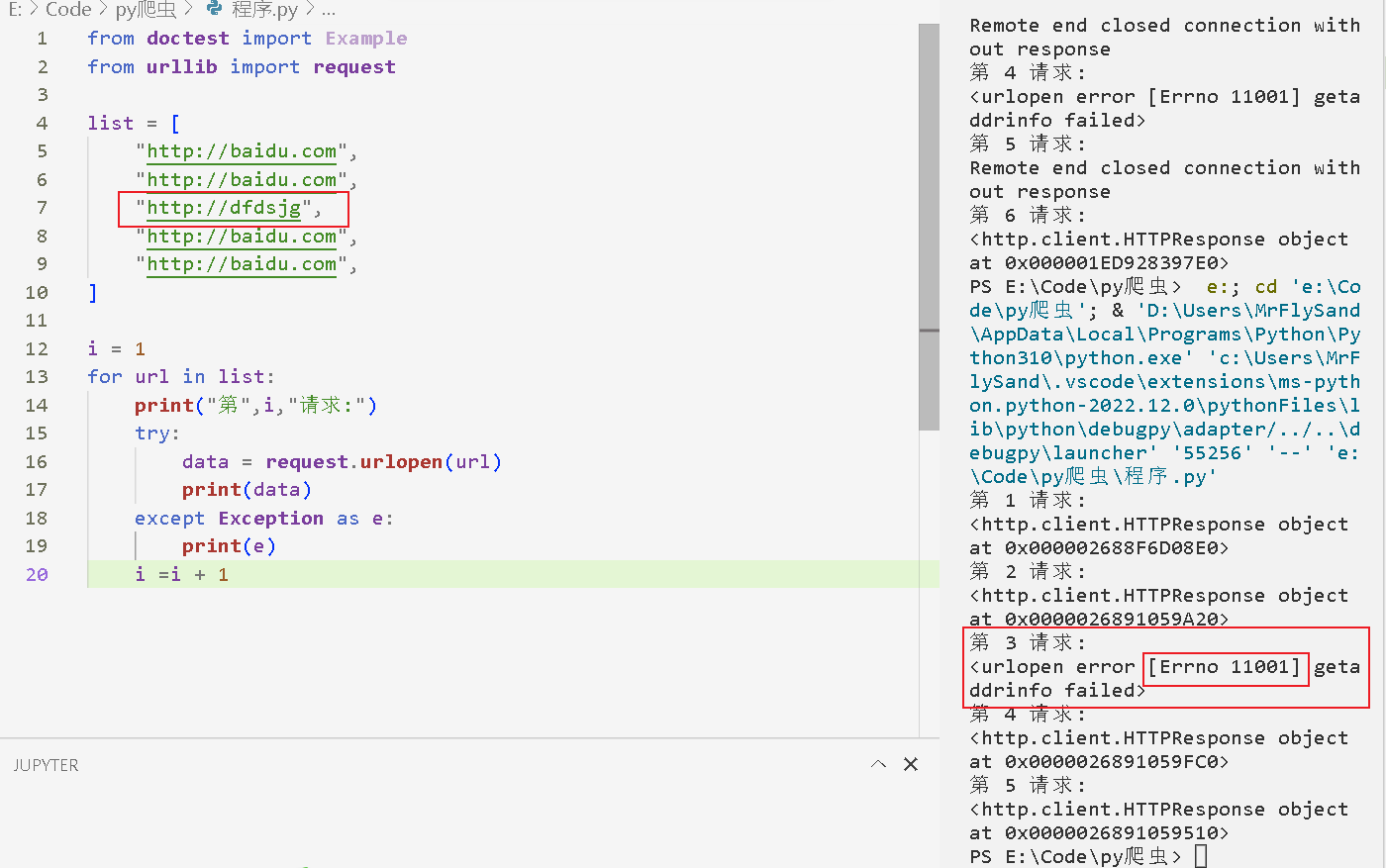
运行上面代码就会出错,如下图
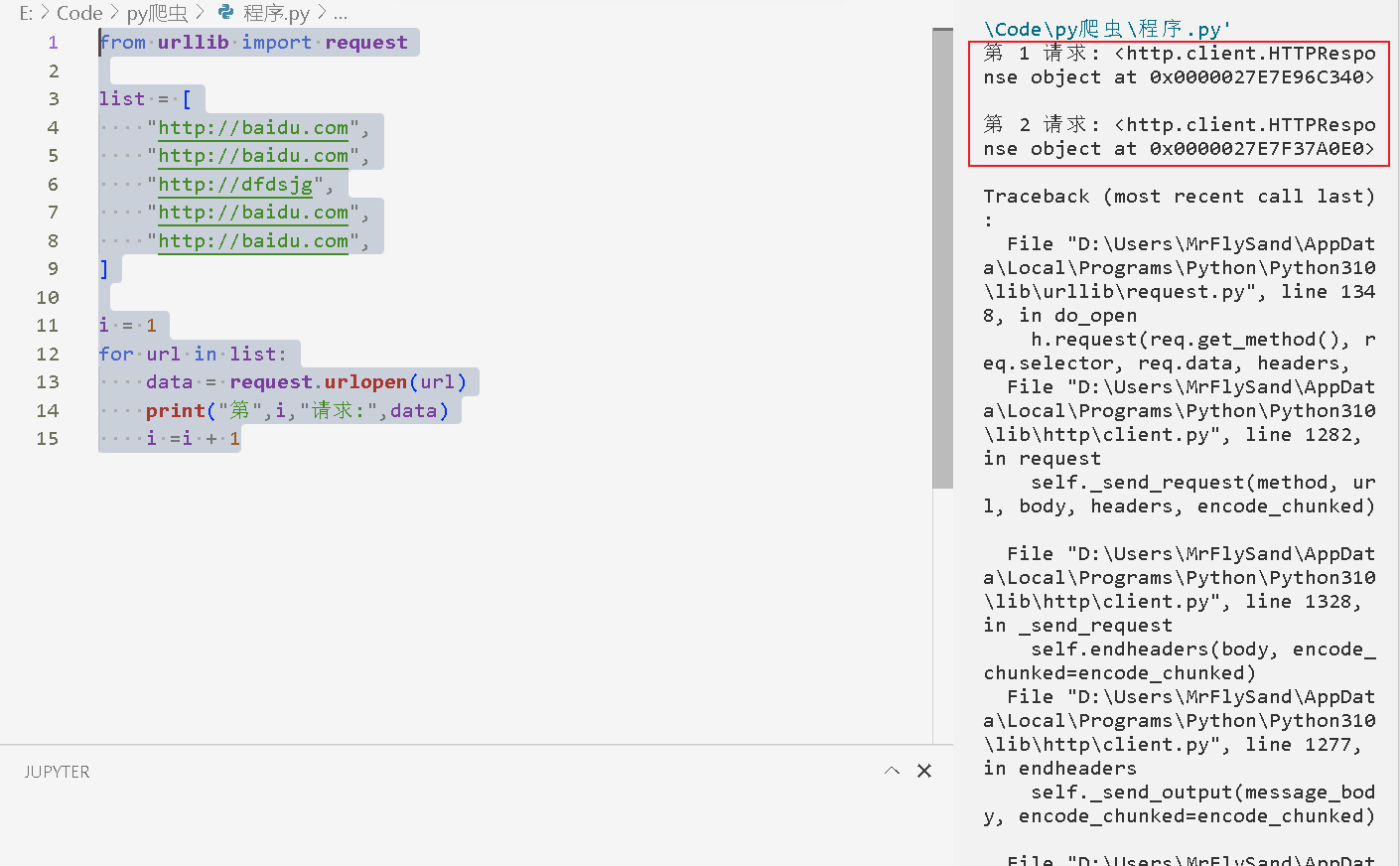
通过try进行异常处理
from doctest import Example
from urllib import request
list = [
"http://baidu.com",
"http://baidu.com",
"http://dfdsjg",
"http://baidu.com",
"http://baidu.com",
]
i = 1
for url in list:
print("第",i,"请求:")
try:
data = request.urlopen(url)
print(data)
except Exception as e:
print(e)
i =i + 1
2.20cookie模拟登录
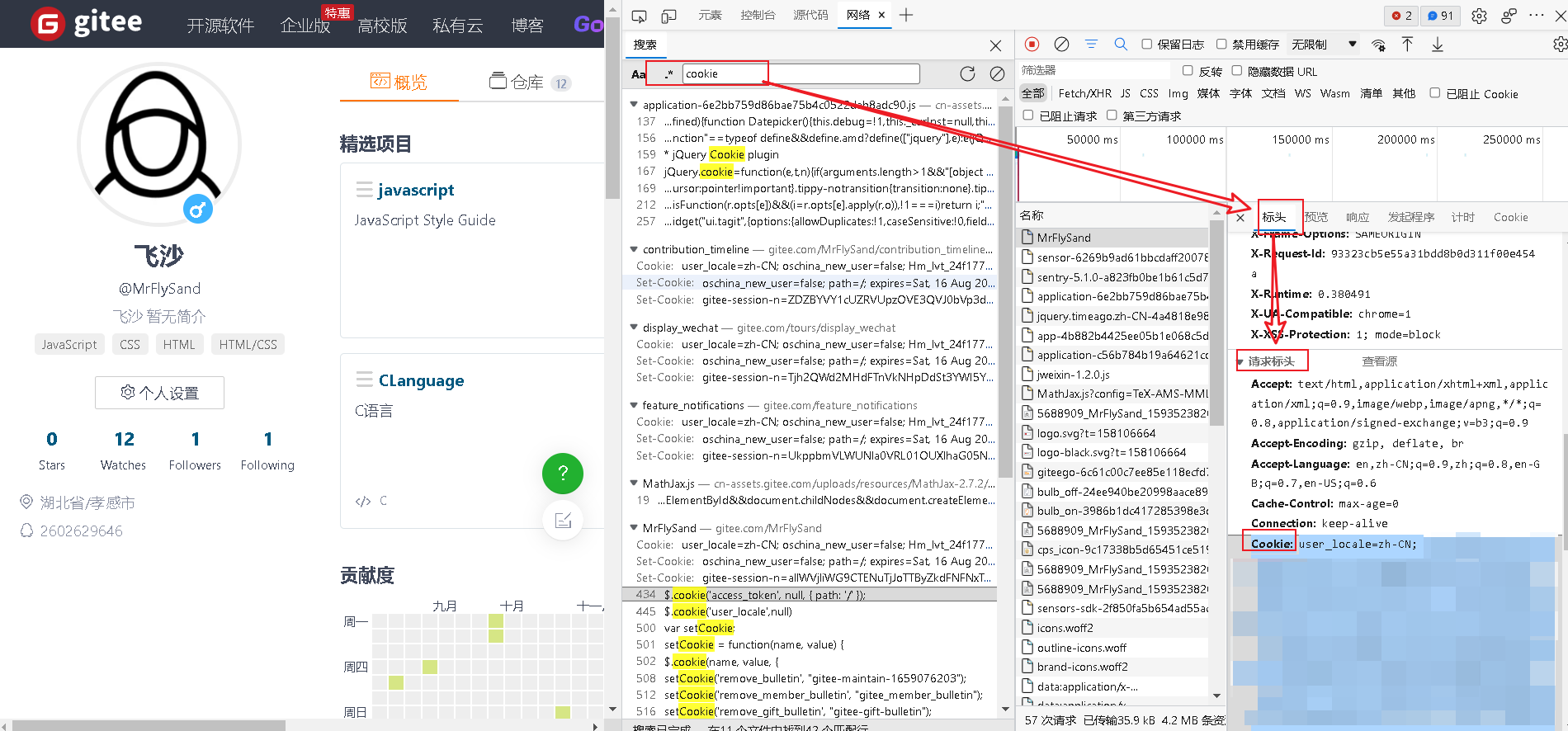
在没有Cookie时分别执行代码,两次获取到的html不同。当有cookie时,用户不需要登录。
from urllib import request, response
url = r"https://gitee.com/MrFlySand"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47",
"Cookie": "user_locale=zh-CN; oschina_new_user=false; Hm_lvt_24f17767262929947cc3631f99bfd274=1646402371; sensorsdata2015jssdkchannel=%7B%22prop%22%3A%7B%22_sa_channel_landing_url%22%3A%22%22%7D%7D; remote_way=http; tz=Etc%2FGMT-8; gitee_user=true; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%225688909%22%2C%22first_id%22%3A%22182a5a05182b3e-0618d85178732ec-45647f52-1327104-182a5a0518315c7%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E5%BC%95%E8%8D%90%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC%22%2C%22%24latest_referrer%22%3A%22https%3A%2F%2Fwww.cnblogs.com%2F%22%7D%2C%22%24device_id%22%3A%2217f553a7ead157e-0381ee7113506ac-7e697a64-1327104-17f553a7eae119e%22%7D; gitee-session-n=bTI3cGhZM2F5UkgrcUNYRnBCSmVicEl3TXpqaG1KTGtnYjhGZHJ5T29pY0pvczF1TncvVnc1THd0M1BEcXRDSUpLaVlIY3h5SlFlckMrYlZ2QmpRZE1mNWp2VXF4cTBXQVAvbXljUTE3ZVVUSXNMWVdOMm1rRkg4U3VUYjlqVTIzNlJFOTFNYm02TlVoNHFibzkvVTczem5XMnBIWUI2bUJxY1YvWUUyVVFaUEdZYjVleStIRFk4dnJ1ZFlvRGM2aXVVZWRWMVJabGw1L3Q1YlAzWTY5bitINW8xdnR6WDlTSGxRY3ByUk4vbDUwVWdaa1craWxmNGJiNTRrbTdiVEZzWW5YaGR6d2tZVmlQWnpnWW1jUklkNWJidnI0bStaL0NmZUlOeisvYlhzNkZONDZ4Kzl6dmI0Y0RmTnY0d1BNSFhvT29ZSHVCeXRlM0ZWM1NFNU83cUZRQTN4R2hMb0Y1Q210eTI4TGw1Y3d0ZnhVKzgwOG9JM0tGVVhQRGlaWGo2WDBUV01ydk1lL0RtYzVQQTZIWnV1V21RYStFd1V5aDA4bURkZ25uZWtaczRXN1NOeHlaemlKNkNjcDRjMi0tWVdyWDdHanhzaVp5andGSU82TFhKZz09--0faf867ee5455b30ccf7e326f93d45bc3a4b85d6"
}
req = request.Request(url,headers = header)
response = request.urlopen(req)
print((response.read().decode()))
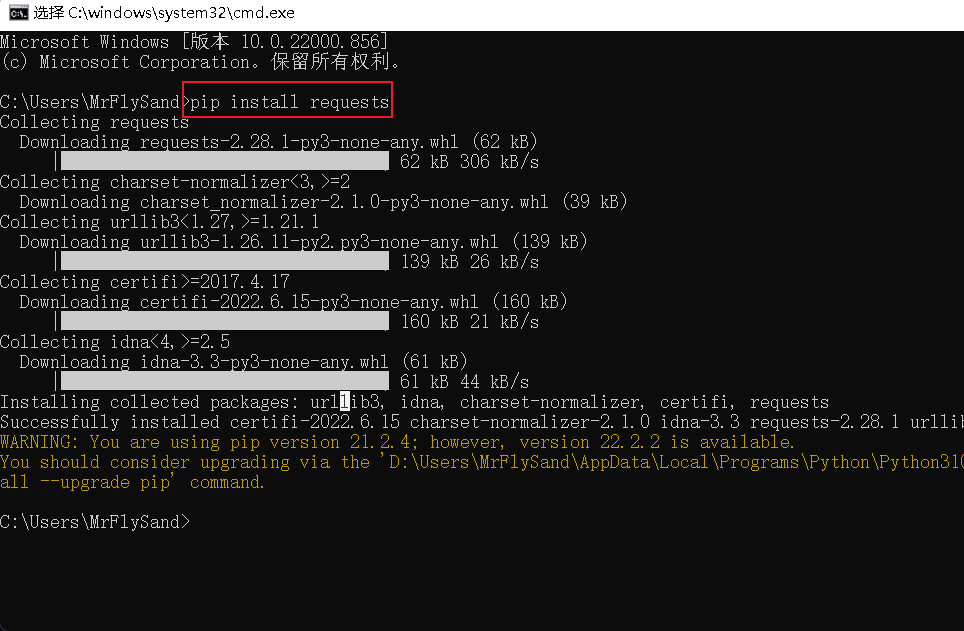
3.1requests安装与使用
【Win+R】-输入cmd-在cmd窗口中输入pip install requests进行安装
from urllib import request
import requests
data = requests.get("http://baidu.com")
# text以字符串的形式获取内容
response = requests.request("get","http://baidu.com").text
'''
<html>
<meta http-equiv="refresh" content="0;url=http://www.baidu.com/">
</html>
'''
# content以二进制的形式获取内容
response = requests.request("get","http://baidu.com").content
'''
b'<html>\n<meta http-equiv="refresh" content="0;url=http://www.baidu.com/">\n</html>\n'
'''
# decode()转换成中文
response = requests.request("get","http://baidu.com").content.decode()
'''
<html>
<meta http-equiv="refresh" content="0;url=http://www.baidu.com/"></html>
'''
# 用get方式获取数据
response = requests.get("http://baidu.com").content.decode()
3.2添加请求头和参数
requests.get("网址", params="请求的数据", headers=header)
import requests
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47"
}
wd = {"wd":"中国"}
'''
params:自动将wd转换成url编码
'''
response = requests.get("https://www.cnblogs.com/MrFlySand/p/13756390.html", params=wd, headers=header)
'''
response的结果:<Response [200]>
'''
# response.text返回一个字符串形式的html网页代码
data1 = response.text
# 返回一个二进制形式的html数据
data2 = response.content
print(data2)
# 返回一个二进制形式的html网页代码,用decode转换成中文
data3 = response.content.decode()
print(data3)
3.3处理post请求
import requests
import re
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47"}
url = "https://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule"
key = "飞沙"
# post请求需要提交的数据
formdata = {
"i":key,
"from":"AUTO",
"to":"AUTO",
"smartresult":"dict",
"client":"fanyideskweb",
"salt":"16606084281166",
"sign":"097c19675ab94536be3851055d802544",
"lts":"1660608428116",
"bv":"08c34ed4d2214384c56440d4bcb8a187",
"doctype":"json",
"version":"2.1",
"keyfrom":"fanyi.web",
"action":"FY_BY_REALTlME",
}
response = requests.post(url, headers=header, data=formdata)
pat = r'"tgt":"(.*?)"}]]'
result = re.findall(pat, response.text)
print(result)
输出内容如下:
['Fly sand']
3.4代理ip
proxy = {"http":"http://代理的ip地址:端口号"}。proxy里面也可以是https,但要注意键值中要保持一致。
点击查找新的代理ip
如下代码会输出请求到的html代码,有时会出现错误这是正常的,可以多运行几次代码。
import requests
# 设置代理ip地址
proxy = {
"http":"http://47.106.105.236:80",
"https":"https://47.106.105.236:80"
}
response = requests.get("http://www.baidu.com", proxies=proxy)
print(response.content.decode())
3.5获取响应的cookie
import requests
response = requests.get("http://www.baidu.com")
#1. 获取返回的cookiejar对象
cookiejar = response.cookies
print(cookiejar)
#2. 将cookiejar转换成字典
cookiedict = requests.utils.dict_from_cookiejar(cookiejar)
print(cookiedict)
输出内容如下:
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
{'BDORZ': '27315'}
3.6session实现登录
import requests
response = requests.get("http://www.baidu.com")
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47"}
# 创建session对象
ses = requests.session()
# 构造登录需要的参数
data = {
"email":"2602629646@qq.com",
"password":""
}
# 通过传递用户名密码得到cookie信息
ses.post("https://passport.baidu.com/v2/?login", data=data)
# 请求需要的页面
response = ses.get("https://passport.baidu.com/v6/ucenter")
print(response.content.decode())
3.7B站数据爬取
import requests
import re
import time
# 写入本地
def writePage(html,fileName):
print("正在保存", fileName)
#wb表示二进制文件格式写入fileName文件中
with open(fileName, "wb") as f:
f.write(html)
# 基础数据
response = requests.get("https://www.bilibili.com")
header = {"User-Agent": "请自己填写相应的代码"}
# 数据清洗
title = r'<p title="(.*?)" class="title">'
readCount = r'<p class="play">(.*?)</p>'
html = response.content.decode()
title = re.findall(title, html)
readCount = re.findall(readCount, html)
# html数据保存到本地
## 保存的数据
html = response.content
## 保存路径
fileName = "C:/Users/MrFlySand/Desktop/testPy/1页.html"
writePage(html,fileName)
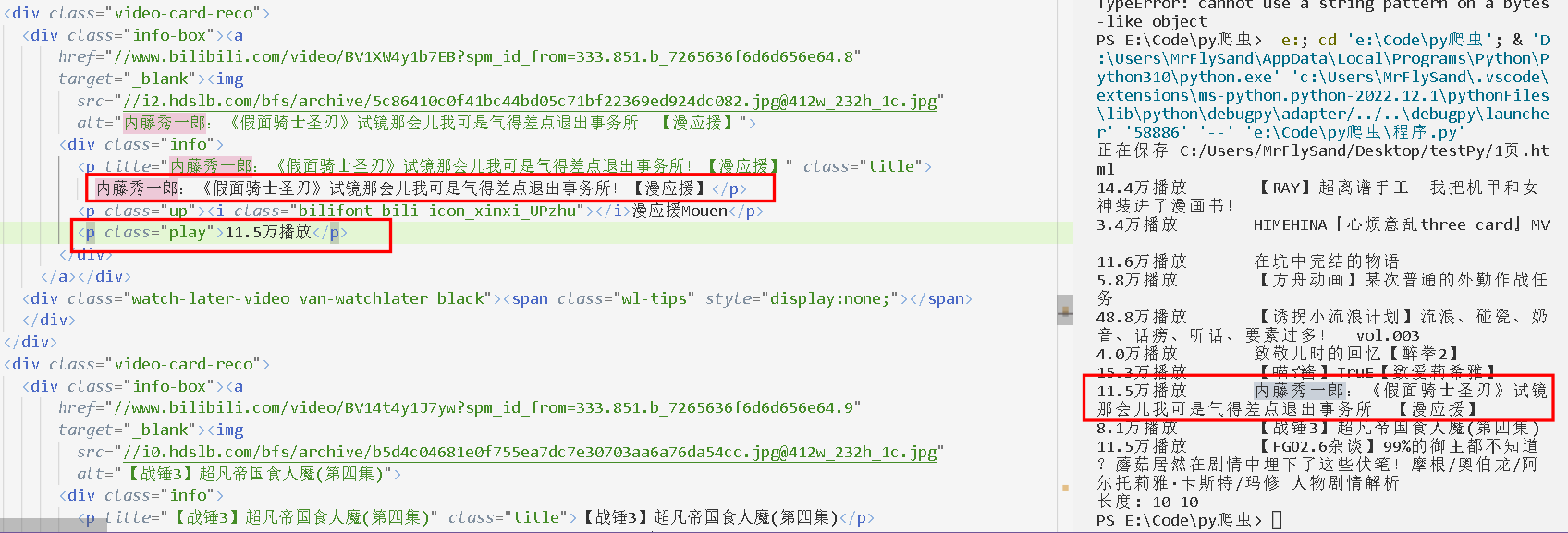
# 输出爬取的数据
for i in range(0, len(readCount)):
print(readCount[i],"\t",title[i])
## 长度相同,说明数据正确
print("长度:",len(readCount),len(title))
输出内容如下:
4.1正则表达式
re.search("查找的字符串","原数据")
import re
str = "MrFlySand飞沙FlySand-Q:2602629646"
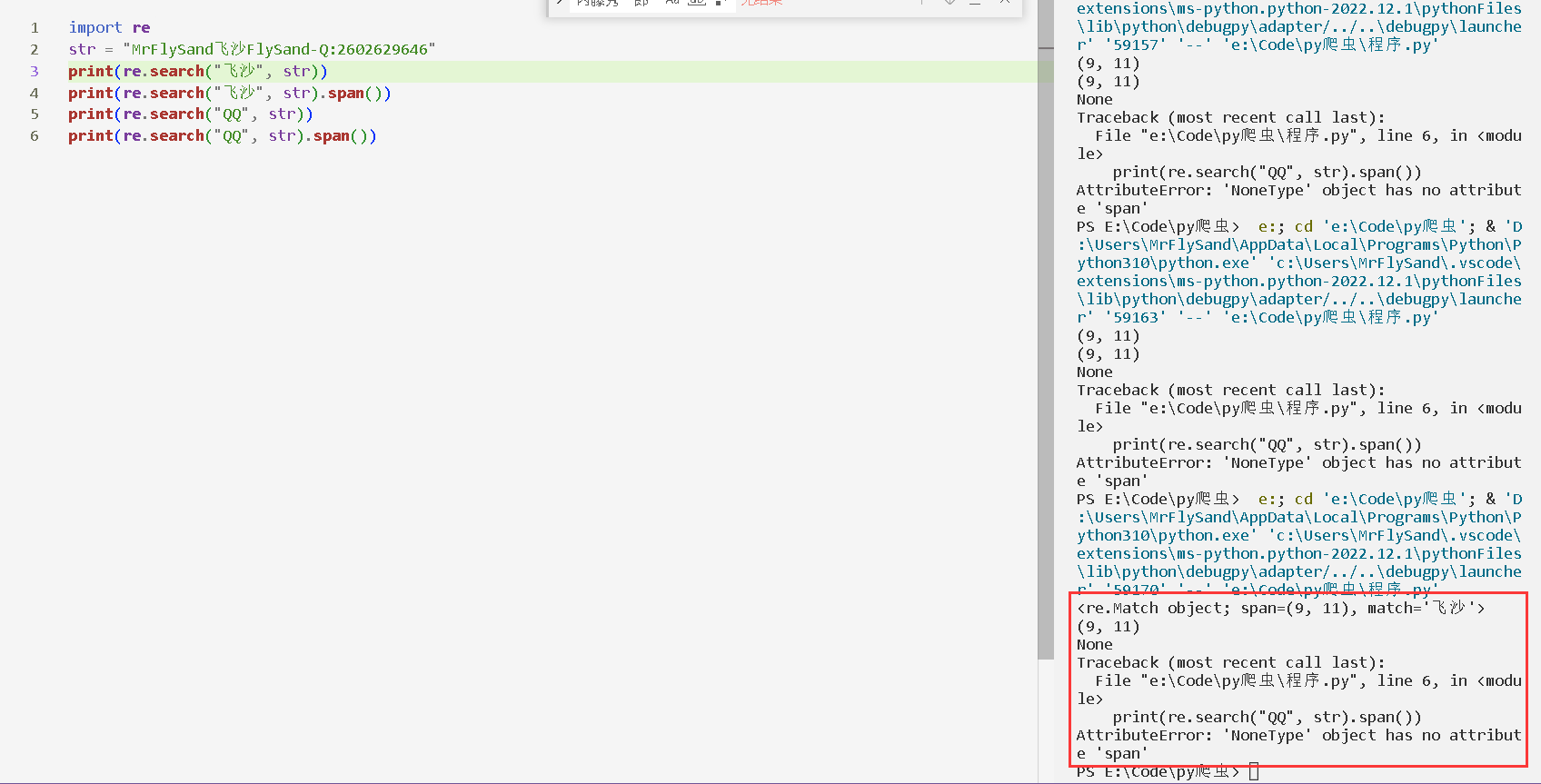
print(re.search("飞沙", str))
print(re.search("飞沙", str).span())
print(re.search("QQ", str))
print(re.search("QQ", str).span())
输出内容如下:
4.2分析单词出现的次数
re.findall("查找的字符串","原数据")返回的是一个列表
import re
with open(r"C:/Users/MrFlySand/Desktop/testPy/英语.txt","rb") as f:
data = f.read().decode()
#print((data))
n1 = len(re.findall("homework", data))
n2 = len(re.findall("pros", data))
n3 = len(re.findall("cons", data))
print("homework:",n1,"\n","pros:",n2,"\n","cons:",n3)
printf(re.findall("cons", data))
输出内容如下:
homework: 45
pros: 3
cons: 5
['cons', 'cons', 'cons', 'cons', 'cons']
4.3 匹配通配字符
原子:正则表达式中实现匹配的基本单位
元字符:正则表达式中具有特殊合义的字符
| 匹配通用字符 |
|---|
\w任意字母/数字/下划线 |
\W和小写\w相反 |
\d十进制数字 |
\D除了十进制数以外的值 |
\s空白字符 |
\S非空白字符 |
[0-9]数字 |
[a-z][A-Z]英文 |
[\u4e00-\u9fa5]中文 |
import re
str = "qq:2602629646,./飞沙MrFlySand"
pat = r"qq"
print(re.search(pat, str))
pat = r"26\w"
print(re.search(pat, str))
pat = r"[A-Z][a-z]"
print(re.search(pat, str))
pat = r"[0-9][0-9][0-9]"
print(re.search(pat, str))
输出内容如下:
<re.Match object; span=(0, 2), match='qq'>
<re.Match object; span=(3, 6), match='260'>
<re.Match object; span=(18, 20), match='Mr'>
<re.Match object; span=(3, 4), match='2'>
4.7 元字符
元字符:正则表达式中具有特殊合义的字符
| 元字符 |
|---|
.匹配任意字符\n除外 |
^匹配字符串开始的位置 |
$匹配字符串中结束的位置 |
*重复0次1次多次前面的原子 |
?重复一次或者0次前面的原子 |
+重复一次或多次前面的原子 |
import re
str = "2602629646,./FlySand飞沙MrFlySand112233"
# 从前面匹配任意2个字符
pat = ".."
print(re.search(pat, str))
# 从开头匹配,以26开头+任意数字
pat = "^26\d"
print(re.search(pat, str))
# 从末尾匹配,任意符号结尾
pat = ".$"
print(re.search(pat, str))
# 从末尾匹配,任意2个字符+Fly结尾
pat = "..Fly$"
print(re.search(pat, str))
# 任意个字符
pat = ".*"
print(re.search(pat, str))
## M开头,d结尾,中间任意个字符
pat = "M.*d"
print(re.search(pat, str))
## 从字符串前面往后匹配,str开头就是2。匹配的结果是:0~n个2+3
pat = "2*3"
print(re.search(pat, str))
## 从字符串前面往后匹配,str开头就是2。匹配的结果是:0~n个1+2
pat = "1*2"
print(re.search(pat, str))
# ?重复0次或者1次前面的原子。匹配的结果是:0~1个2+6
pat = "2?6"
print(re.search(pat, str))
# +重复0次或者1次前面的原子。匹配的结果是:1~n个2+3
pat = "2+3"
print(re.search(pat, str))
输出结果如下:
<re.Match object; span=(0, 2), match='26'>
<re.Match object; span=(0, 3), match='260'>
<re.Match object; span=(36, 37), match='3'>
None
<re.Match object; span=(0, 37), match='2602629646,./FlySand飞沙MrFlySand112233'>
<re.Match object; span=(22, 31), match='MrFlySand'>
<re.Match object; span=(33, 36), match='223'>
<re.Match object; span=(0, 1), match='2'>
<re.Match object; span=(0, 2), match='26'>
<re.Match object; span=(33, 36), match='223'>
4.8匹配固定次数
{n}前面的原子出现了n次
{n,}至少出现n次
{n,m}出现次数介于n-m之间,注意n,m之间不能有空格
import re
str = "2602629646"
pat = r"\d{6}" #匹配6个数字
print(re.search(pat, str))
str = "2602629646"
pat = r"\d{11}" # 匹配11个数字
print(re.search(pat, str))
str = "2602629646"
pat = r"\d{6,8}" # 匹配6~8个数字
print(re.search(pat, str))
str = "2602629646"
pat = r"\d{6, 8}" # ","和"8"之间有空格,无法正常匹配
print(re.search(pat, str))
输出内容如下:
<re.Match object; span=(0, 6), match='260262'>
None
<re.Match object; span=(0, 8), match='26026296'>
None
4.9匹配多个正则表达式
|表示或,只要|的前面或者后面有一个满足条件就可以输出字符串
import re
str = "2602629646"
pat = r"2[126]0|9[6]"
print(re.search(pat, str))
pat = r"200|9[6]"
print(re.search(pat, str))
- 输出结果如下:
<re.Match object; span=(0, 3), match='260'>
<re.Match object; span=(6, 8), match='96'>
4.10分组
import re
str = ";]\][/;$*(#(*%#$@A#MrFlySand$#($*#%@#@$Python^&&aa2602629646bb"
pat = r"MrFlySand.{0,}Python{0,}"
print(re.search(pat, str))
pat = r"(MrFlySand).{0,}(Python).s{0,}"
print(re.search(pat, str).group(1)) # 将第1个括号里面的内容输出
print(re.search(pat, str).group(2))
# 保留括号中间的内容
pat = r"aa(.*?)bb"
print(re.findall(pat,str))
- 输出结果如下:
<re.Match object; span=(19, 45), match='MrFlySand$#($*#%@#@$Python'>
MrFlySand
Python
['2602629646']
4.11贪婪模式和非贪婪模式
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配;
<div>MrFlySand飞沙1</div><div>MrFlySand飞沙2</div>123213中<div>MrFlySand飞沙1</div>和<div>MrFlySand飞沙1</div><div>MrFlySand飞沙2</div>都匹配,但后者更多,结果就是后者。 - 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配(?) ;
- Python里默认是贪婪的。
findall()得到的是数列。
import re
str = "<div>MrFlySand飞沙1</div><div>MrFlySand飞沙2</div>123213"
# 贪婪模式
pat = r"<div>.*</div>"
print(re.search(pat,str))
# 非贪婪模式
pat = r"<div>.*?</div>"
print(re.search(pat,str))
print(re.findall(pat,str))
- 输出内容:
<re.Match object; span=(0, 46), match='<div>MrFlySand飞沙1</div><div>MrFlySand飞沙2</div>'>
<re.Match object; span=(0, 23), match='<div>MrFlySand飞沙1</div>'>
['<div>MrFlySand飞沙1</div>', '<div>MrFlySand飞沙2</div>']
4.12 compile函数
- compile函数:将正则表达式换成内部格式,提高执行效率。
\d表示任意数字,\d+表示任意个数字。
import re
strr = "mrflysand666python"
pat = r"\d"
print(re.search(pat,strr))
pat = r"\d+"
print(re.search(pat,strr))
pat = re.compile(r"\d")
print(pat.search(strr))
pat = re.compile(r"\d+")
print(pat.search(strr))
pat = re.compile(r"python")
print(pat.search(strr))
# 区分大小写
pat = re.compile(r"Python")
print(pat.search(strr))
## 模式修正符:忽略大小写。注意re.I,I是大写。
pat = re.compile(r"Python",re.I)
print(pat.search(strr))
输出内容:
<re.Match object; span=(9, 10), match='6'>
<re.Match object; span=(9, 12), match='666'>
<re.Match object; span=(9, 10), match='6'>
<re.Match object; span=(9, 12), match='666'>
<re.Match object; span=(12, 18), match='python'>
None
<re.Match object; span=(12, 18), match='python'>
4.13 match函数和serch函数
- match函数和serch函数都是一次匹配,匹配到一次就不在往后匹配。
match函数匹配开头
import re
# match函数
strr = "mrflysand666python"
pat = re.compile(r"666")
print(pat.match(strr))
strr = "999mrflysand666python"
pat = re.compile(r"999")
print(pat.match(strr))
- 输出如下:
None # “666”不在strr字符串的开头
<re.Match object; span=(0, 3), match='999'>
serch函数匹配任意位置
import re
# search()
strr = "mrflysand666python"
pat = re.compile(r"666")
print(pat.search(strr))
strr = "999mrflysand666python"
pat = re.compile(r"999")
print(pat.search(strr))
- 输出如下:
<re.Match object; span=(9, 12), match='666'>
<re.Match object; span=(0, 3), match='999'>
group()中的数字是匹配字符串strr中括号的位置
import re
strr = "mrflysand666pythonmrflysand"
pat = re.compile(r"(m)rflysan(d)")
print(pat.search(strr).group())
print(pat.search(strr).group(1))
print(pat.search(strr).group(2))
- 输出如下:
mrflysand
m
d
4.14 findall()和finditer()
findall()查找所有匹配的内容,装到列表中fiditer()查找所有匹配的内容,装到迭代器中
import re
# findall函数
strr = "mrflysand——————mrflysand——————mrflysand——"
pat = re.compile(r"mrflysand")
print(pat.findall(strr))
# finditer函数
pat = re.compile(r"mrflysand")
print(pat.finditer(strr))
data = pat.finditer(strr)
for i in data:
print(i)
list = []
data = pat.finditer(strr)
for j in data:
print(j.group())
list.append(j.group())
print(list)
- 输出如下:
['mrflysand', 'mrflysand', 'mrflysand']
<callable_iterator object at 0x0000022CC8997C40>
<re.Match object; span=(0, 9), match='mrflysand'>
<re.Match object; span=(15, 24), match='mrflysand'>
<re.Match object; span=(30, 39), match='mrflysand'>
mrflysand
mrflysand
mrflysand
['mrflysand', 'mrflysand', 'mrflysand']
4.15 split()函数和sub()函数
split()按照能够匹配的子串分割后返回列表
import re
# split()
strr = "mrflysand1,,,,,mrflysand2,,,,,mrflysand3,,,,"
pat1 = re.compile(r",+")
result1 = pat1.split(strr)
print(result1)
strr = "mrflysand1,,,,,mrflysand2,,,,,mrflysand3"
pat1 = re.compile(r",+")
result1 = pat1.split(strr)
print(result1)
- 输出如下:
['mrflysand1', 'mrflysand2', 'mrflysand3', '']
['mrflysand1', 'mrflysand2', 'mrflysand3']
sub("替换后的内容",要处理的字符串)用于替换
# sub()
str2 = "mrflysand 123, mrflysand 456!"
pat2 = re.compile(r"\d+")
result2 = pat2.sub("666",str2)
print(result2)
- 输出如下:
mrflysand 666, mrflysand 666!
4.16实战-爬取网站电话号码
response爬取的网页的html数据,如下是html的一小段。通过观察href里面有电话号码,名称。
<tr>
<td>
<a href="/tel/110/">匪警</a>
</td>
<td>
110
</td>
</tr>
[\s\S]*?表示任意个字符;(\d+)表示任意个数字;(.*?)表示任意符号
from ast import pattern
import re
import requests
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.81 Safari/537.36 Edg/104.0.1293.47"}
response = requests.get("http://www.114best.com/tel",headers=header).text
pat1 = re.compile(r"<td>[\s\S]*?<a href=[\s\S]*?/tel/(\d+)[\s\S]*?>[\s\S]*?</a>[\s\S]*?</td>")
pat2 = re.compile(r"<td>[\s\S]*?<a href=[\s\S]*?/tel/[\s\S]*?/[\s\S]*?>(.*?)</a>[\s\S]*?</td>")
pattern1 = re.compile(pat1)
pattern2 = re.compile(pat2)
data1 = pattern1.findall(response)
data2 = pattern2.findall(response)
resultList = []
for i in range(0,len(data1)):
resultList.append(data2[i]+data1[i])
print(resultList[i])
4.17实战-爬虫电影排名列表
import urllib.request
import re
url = "https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&page_limit=50&page_start=0"
header = {"User-Agent":"用户自己输入"}
req = urllib.request.Request(url,headers=header)
data = urllib.request.urlopen(req).read().decode()
# print(data)
pat1 = re.compile(r'"rate":"(.*?)","cover_x":\d+,"title":"[\s\S]*?')
pat2 = re.compile(r'"rate":"[\s\S].*?","cover_x":\d+,"title":"(.*?)"')
data1 = pat1.findall(data)
data2 = pat2.findall(data)
for i in range(0,len(data1)):
print(data2[i],data1[i]+"分")
输出如下:
余命10年 6.9分
紫心之恋 6.6分
瞬息全宇宙 7.6分
祝你好运 6.8分
稍微想起一些 7.8分

data输出内容
5.1 xpath介绍和lxml安装
我们可以通过XPath,将HTML文件转换成XML文档,然后用XPath查找HTML节点或元素。通过这种方法会比正则表达式更加方便。
我们需要安装1xml模块来支持xpath的操作。
在cmd窗口中输入pip install lxml
5.2解析字符串形式html
from base64 import encode
from lxml import etree
text = '''
<h5 id="scroller-1" offset="2">python有两种导入模块的方法,分别如下
<button class="cnblogs-toc-button" title="显示目录导航" aria-expanded="false"></button>
<p>mrflysand
</h5>
'''
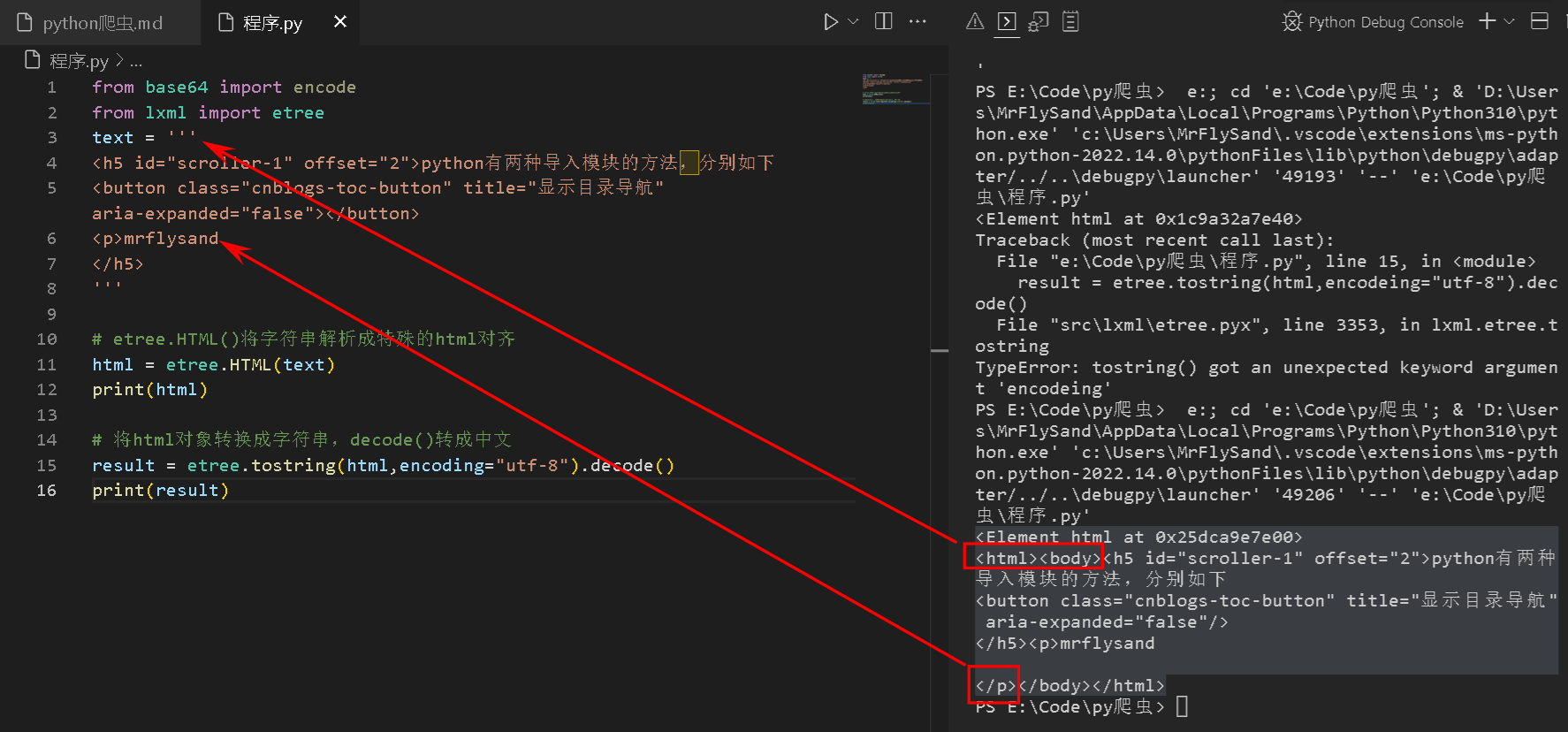
# etree.HTML()将字符串解析成特殊的html对齐
html = etree.HTML(text)
print(html)
# 将html对象转换成字符串,decode()转成中文
result = etree.tostring(html,encoding="utf-8").decode()
print(result)
输出如下:
<Element html at 0x25dca9e7e00>
<html><body><h5 id="scroller-1" offset="2">python有两种导入模块的方法,分别如下<button class="cnblogs-toc-button" title="显示目录导航" aria-expanded="false"/></h5><p>mrflysand
</p></body></html>
如下图,输出的内容会将原本少的代码自动补充上。
5.3 解析本地文件
5.3.1 解析本地txt文件
sorted()是排序,可参考【CSDN】python中的字典排序
txt中的文本
from base64 import encode
import urllib.request
import re
from lxml import etree
# 读取文档中所有的数据
def readAll(url):
str = open(url,encoding = "utf-8")
strs = ""
# 读取每一行
for line in str.readlines():
strs = line.strip() + strs
return strs
# 正则表达式匹配字符
strs = readAll("C:/Users/MrFlySand/Desktop/1.txt")
pat = re.compile(r'[a-z]+' or '[A-Z][a-z]+')
data = pat.findall(strs)
# 统计每个单词出现的次数并加入到dict字典中
dict = {}
for i in range(0,len(data)):
if data[i] in dict:
dictValue = dict[data[i]]+1
dict.update({data[i]:dictValue})
else:
dict.update({data[i]:1})
# 根据字典的value值进行排序
dict = sorted(dict.items(), key=lambda dict: dict[1], reverse=True)
for key in dict:
print(key)
输出结果:
('the', 9)
('of', 8)
('a', 7)
('and', 7)
('to', 4)
('in', 4)
5.3.2 解析本地html文件
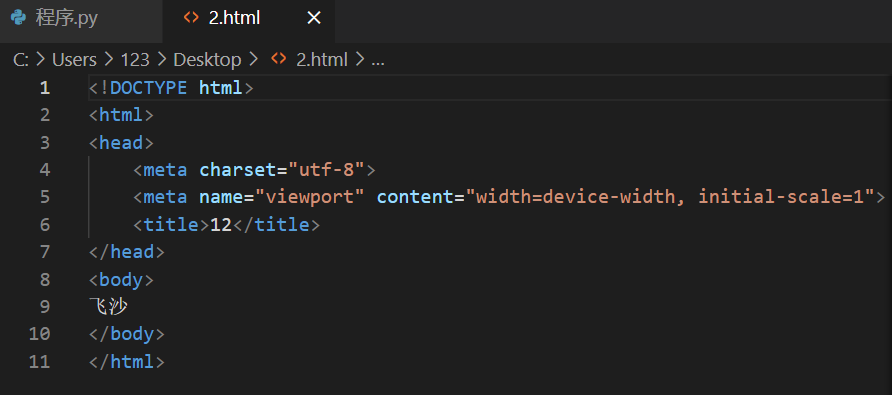
html文件中的内容
from lxml import etree
import re
parser = etree.HTMLParser(encoding='utf-8')
tree = etree.parse("C:/Users/123/Desktop/2.html", parser=parser)
result = etree.tostring(tree,encoding="utf-8").decode()
print(result)
输出内容:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8"/>
<meta name="viewport" content="width=device-width, initial-scale=1"/>
<title>12</title>
</head>
<body>
飞沙
</body>
</html>
5.3.2.1 lxml.etree.XMLSyntaxError: Opening and ending tag mismatch错误的解决办法
解决方法:创建html解析器,增加parser,指定编码格式
tree的结果是<lxml.etree._ElementTree object at 0x0000022E489279C0>
from lxml import etree
parser = etree.HTMLParser(encoding='utf-8')
tree = etree.parse(r'C:/mrflysand.html',parser=parser)
5.4 获取一类标签
result = tree.xpath("//")获取一类标签,result = tree.xpath("//p")获取所有的p标签
from lxml import etree
import re
parser = etree.HTMLParser(encoding='utf-8')
tree = etree.parse("C:/Users/123/Desktop/index.html", parser=parser)
html = etree.tostring(tree,encoding="utf-8").decode()
result = tree.xpath("//p")
for i in range(0,10):
print(result[i].text)
html代码如下:
<body>
<header class="header"></header>
<div id="container">
<!----------------------------------------可以修改的内容play------------------------------------>
<div id="main">
<section class="post" itemscope itemprop="blogPost">
<h1 style="color:#2ca6cb;" itemprop="name">个人博客</h1>
<p style="display:inline-flex;" itemprop="description">
<img style="width: 1em;height: 1em;display: inline-block;margin-right:0.5em;" src="http://q.qlogo.cn/headimg_dl?dst_uin=2602629646&spec=640">
<p style="display: contents;">飞沙QQ:<a href="mqqwpa://im/chat?chat_type=wpa&uin=2602629646">2602629646</a></p>
<p>博客园:<a href="https://www.cnblogs.com/MrFlySand">cnblogs.com/MrFlySand</a></p>
<p>CSDN:<a href="https://blog.csdn.net/MrFlySand">blog.csdn.net/MrFlySand</a></p>
<p>Bilibili:<a href="https://space.bilibili.com/403411216">https://space.bilibili.com/403411216</a></p>
<p>知乎:<a href="https://www.zhihu.com/people/MrFlySand/posts">zhihu.com/people/MrFlySand</a></p>
<p>Github:<a href="https://github.com/MrFlySand">github.com/MrFlySand</a></p>
</p>
花瓣网huaban.com/mrflysand 酷站MrFlySand.zcool.com.cn
</section>
<section class="post" itemscope itemprop="blogPost">
<a class="mainHref" href="Page/Algorithm/Sort" title="简单算法" itemprop="url">
<h1 itemprop="name">排序算法</h1>
<p itemprop="description">
<p>排序算法有很多:冒泡排序/选择排序/插入排序/归并排序/计数排序/基数排序/希尔排序/堆排序/桶排序/快速排序</p>
<p>排序算法是《数据结构与算法》中最基本的算法之一。</p>
<p>一个优秀的算法可以节省大量时间的空间。</p>
<p>排序算法是将一组或多组数据按照既定模式进行重新排序。</p>
</p>
</a>
</section>
<section class="post" itemscope itemprop="blogPost">
<a class="mainHref" target="_blank" href="https://www.cnblogs.com/MrFlySand/p/13461893.html" title="Git命令" itemprop="url">
<h1 itemprop="name">Git命令</h1>
<p>git本地文件上传到远程仓库</p>
<p>删除文件</p>
<p>版本控制/回退</p>
<p>路径问题</p>
<p>其它常用命令</p>
</a>
</section>
<section class="post" itemscope itemprop="blogPost">
<a class="mainHref" href="Page/Algorithm/MaximumDepthOfTheTree/" title="树的最大深度" itemprop="url">
<h1 itemprop="name">树的最大深度</h1>
<p itemprop="description">
<p>树的左子结点小于父结点</p>
<p>树的右子结点大于父结点</p>
<p>求二叉树的最大深度</p>
</p>
</a>
</section>
</div>
<!----------------------------------------可以修改的内容end------------------------------------>
<div id="asidepart"></div>
</div>
输出内容:
飞沙QQ:
博客园:
CSDN:
Bilibili:
知乎:
Github:
排序算法有很多:冒泡排序/选择排序/插入排序/归并排序/计数排序/基数排序/ 希尔排序/堆排序/桶排序/快速排序排序算法是《数据结构与算法》中最基本的算法之一。
5.5 获取指定属性的标签
5.5.1实例一:指定标签和属性
index.html中的代码看5.4中的html代码。
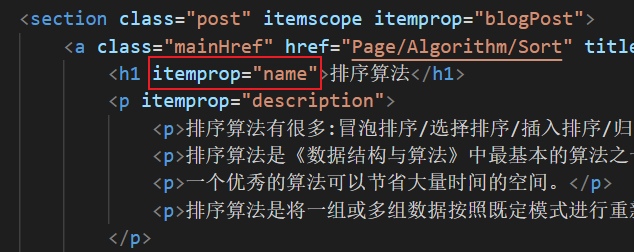
tree.xpath("//h1[@itemprop='name']")获取h1标签,itemprop的值为name。如下图:
from lxml import etree
import re
parser = etree.HTMLParser(encoding='utf-8')
tree = etree.parse("C:/Users/123/Desktop/index.html", parser=parser)
html = etree.tostring(tree,encoding="utf-8").decode()
result = tree.xpath("//h1[@itemprop='name']")
for i in range(0,len(result)):
print(result[i].text)
输出内容如下:
个人博客
排序算法
Git命令
树的最大深度
5.5.2实例二:指定标签和属性
tree.xpath("//p/a[@href='https://www.cnblogs.com/MrFlySand']")获取p标签下的a标签,其中href='https://www.cnblogs.com/MrFlySand'中的文本
/表示下一级标签
from lxml import etree
import re
parser = etree.HTMLParser(encoding='utf-8')
tree = etree.parse("C:/Users/123/Desktop/index.html", parser=parser)
html = etree.tostring(tree,encoding="utf-8").decode()
result = tree.xpath("//p/a[@href='https://www.cnblogs.com/MrFlySand']")
for i in range(0,len(result)):
print(result[i].text)
输出内容:
cnblogs.com/MrFlySand
5.6 获取标签属性
tree.xpath("//标签/@属性"),tree.xpath("//p/a/@href")获取p标签下的a标签中href属性。
注意:for循环中的i后面没有text,但5.5章节和5.7章节中有。
from lxml import etree
import re
parser = etree.HTMLParser(encoding='utf-8')
tree = etree.parse("C:/Users/123/Desktop/index.html", parser=parser)
html = etree.tostring(tree,encoding="utf-8").decode()
result = tree.xpath("//p/a/@href")
print(result)
for i in result:
print(i)
输出内容如下:
['mqqwpa://im/chat?chat_type=wpa&uin=2602629646', 'https://www.cnblogs.com/MrFlySand', 'https://blog.csdn.net/MrFlySand', 'https://space.bilibili.com/403411216', 'https://www.zhihu.com/people/MrFlySand/posts', 'https://github.com/MrFlySand']
mqqwpa://im/chat?chat_type=wpa&uin=2602629646
https://www.cnblogs.com/MrFlySand
https://blog.csdn.net/MrFlySand
https://space.bilibili.com/403411216
https://www.zhihu.com/people/MrFlySand/postshttps://github.com/MrFlySand
5.7 获取子标签
5.7.1实例一
\获取下一级标签
index.html中的代码看5.4中的html代码。
tree.xpath("//section/a/h1"),/表示下一级。
from lxml import etree
import re
parser = etree.HTMLParser(encoding='utf-8')
tree = etree.parse("C:/Users/123/Desktop/index.html", parser=parser)
html = etree.tostring(tree,encoding="utf-8").decode()
result = tree.xpath("//section/a/h1")
print(result)
for i in result:
print(i.text)
输出内容如下:
[<Element h1 at 0x25f86e1cd00>, <Element h1 at 0x25f86e1ccc0>, <Element h1 at 0x25f86e1cd80>]
排序算法
Git命令
树的最大深度
5.7.2实例二
\\获取所有符合条件的子标签
from lxml import etree
import re
parser = etree.HTMLParser(encoding='utf-8')
tree = etree.parse("C:/Users/123/Desktop/1.html", parser=parser)
html = etree.tostring(tree,encoding="utf-8").decode()
result = tree.xpath("//li//span")
for i in result:
print(i.text)
1.html中的代码内容:
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<li>
<a href="">
<span>mrflysand</span>
<span>mrflysand1</span>
</a>
<span>飞沙</span>
<span>飞沙1</span>
</li>
</body>
输出内容:
mrflysand
mrflysand1
飞沙
飞沙1
当py中的代码是result = tree.xpath("//li/span"),输出如下:
飞沙
飞沙1
5.7.3实例三
1.html代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<li>
<a href="">
<span class="abc">mrflysand</span>
<span>mrflysand1</span>
<span class="a1">mrflysand2</span>
</a>
<span>飞沙</span>
<span>飞沙1</span>
</li>
</body>
</html>
//li//span//@class任意li>span>有class属性的内容
from lxml import etree
import re
parser = etree.HTMLParser(encoding='utf-8')
tree = etree.parse("C:/Users/123/Desktop/1.html", parser=parser)
html = etree.tostring(tree,encoding="utf-8").decode()
result = tree.xpath("//li//span//@class")
for i in result:
print(i)
输出如下:
abc
a1
5.8获取标签内容和标签名
5.8.1 实例一:获取倒数第二个标签
html代码看5.7.3章节
//li/span[last()]选中li下的span标签最后一个元素
//li/span[last()-1]选中li下的span标签倒数第二个元素
parser = etree.HTMLParser(encoding='utf-8')
tree = etree.parse("C:/Users/123/Desktop/1.html", parser=parser)
html = etree.tostring(tree,encoding="utf-8").decode()
result = tree.xpath("//li/span[last()-1]")
print(result)
for i in result:
print(i.text)
输出内容:
[<Element span at 0x1f1d0238e80>]
飞沙
当代码成为result = tree.xpath("//li//span[last()-1]")时,选中的是所有li下的所有span标签,输出如下:
mrflysand1
飞沙
5.8.2实例二:获取倒数第二个标签
tree.xpath("//li/span")选中所有li标签下span标签,符合要求的有飞沙、飞沙1
from lxml import etree
import re
parser = etree.HTMLParser(encoding='utf-8')
tree = etree.parse("C:/Users/123/Desktop/1.html", parser=parser)
html = etree.tostring(tree,encoding="utf-8").decode()
result = tree.xpath("//li/span")
print(result[-2].text)
输出如下:
飞沙
5.8.3 实例三:获取指定的class标签中的文本
tree.xpath("//*[@class='abc']")获取所有标签下class值为abc的文本
from lxml import etree
import re
parser = etree.HTMLParser(encoding='utf-8')
tree = etree.parse("C:/Users/123/Desktop/1.html", parser=parser)
html = etree.tostring(tree,encoding="utf-8").decode()
result = tree.xpath("//*[@class='abc']")
print(result[0].text)
输出如下:
mrflysand
5.8.3 实例四:获取指定的class标签名
result[0].tag获取标签名,如下代码输出span
from lxml import etree
import re
parser = etree.HTMLParser(encoding='utf-8')
tree = etree.parse("C:/Users/123/Desktop/1.html", parser=parser)
html = etree.tostring(tree,encoding="utf-8").decode()
result = tree.xpath("//*[@class='abc']")
print(result[0].tag)
文章推荐:https://blog.csdn.net/qq_38403590/article/details/120352008

 浙公网安备 33010602011771号
浙公网安备 33010602011771号