
python:爬取博主的所有文章的链接、标题和内容
以爬取我自己的博客为例:https://www.cnblogs.com/Mr-choa/
1、获取所有的文章的链接:

博客文章总共占两页,比如打开第一页:https://www.cnblogs.com/Mr-choa/default.html?page=1的HTML源文件

每篇博客文章的链接都在a标签下,并且具有class属性为"postTitle2",其href属性就指向这篇博文的地址
<a class="postTitle2" href="https://www.cnblogs.com/Mr-choa/p/12615986.html">
简单爬取自己的一篇博客文章
</a>
这样我们可以通过正则表达式获取博文的地址,获取所有的文章的链接就要对博客的页数做一个遍历:
模块代码实现:
# 获取所有的链接
def get_Urls(url,pageNo):
"""
根据url,pageNo,能够返回该博主所有的文章url列表
:param url:
:param pageNo:
:return:
"""
# 创建一个list,用来装博客文章的地址
total_urls=[]
# 对页数做个遍历
for i in range(1,pageNo+1):
# 页数的地址
url_1=url+str(i)
# 获取这一页的全部源代码
html=get_html(url_1)
# 创建一个属性
title_pattern=r'<a.*class="postTitle2".*href="(.*)">'
# 通过正则表达式找到所有相关属性的数据,就是所有的博客文章的链接
urls=re.findall(title_pattern,html)
# 把链接放到list容器内
for url_ in urls:
total_urls.append(url_)
#print(total_urls.__len__())
# 返回所有博客文章的链接
return total_urls
2、获取全部源代码
代码实现:
# 获取网页源码
def get_html(url):
"""
返回对应url的网页源码,经过解码的内容
:param url:
:return:
"""
# 创建一个请求对象
req = urllib.request.Request(url)
# 发起请求,urlopen返回的是一个HTTPResponse对象
resp = urllib.request.urlopen(req)
# 获取HTTP源代码,编码格式为utf-8
html_page = resp.read().decode('utf-8')
# 返回网页源码
return html_page
或者用requests库实现:
def get_html(url):
# 创建一个响应对象
response=requests.get(url)
# 获取整个网页的HTML内容
html_page=response.text
# 返回网页的HTML内容
return html_page
3、获取博客文章的标题
代码实现:
# 获取博客文章的标题
def get_title(url):
'''
获取对应url下文章的标题
:param url:
:return:
'''
# 通过博文的地址获取到源代码
html_page = get_html(url)
# 创建str变量
title_pattern = r'(<a.*id="cb_post_title_url".*>)(.*)(</a>)'
# 匹配到相关的数据
title_match = re.search(title_pattern, html_page)
# 获取标题
title = title_match.group(2)
# 返回标题
return title
4、获取博客文章的所有文本
代码实现:
# 获取博客文章的文本
def get_Body(url):
"""
获取对应url的文章的正文内容
:param url:
:return:
"""
html_page = get_html(url)
soup = BeautifulSoup(html_page, 'html.parser')
div = soup.find(id="cnblogs_post_body")
return div.text
5、保存文章
代码实现:
# 保存文章
def save_file(url):
"""
根据url,将文章保存到本地
:param url:
:return:
"""
title=get_title(url)
body=get_Body(url)
filename="Mr_choa"+'-'+title+'.txt'
with open(filename, 'w', encoding='utf-8') as f:
f.write(title)
f.write(url)
f.write(body)
# 遍历所有的博客文章链接,保存博客的文章
def save_files(url,pageNo):
'''
根据url和pageNo,保存博主所有的文章
:param url:
:param pageNo:
:return:
'''
totol_urls=get_Urls(url,pageNo)
for url_ in totol_urls:
save_file(url_)
显示所有的代码:


import requests import urllib.request import re from bs4 import BeautifulSoup #该作者的博文一共有多少页 pageNo=2 #后面需要添加页码 url='https://www.cnblogs.com/Mr-choa/default.html?page=' # 获取网页源码 def get_html(url): """ 返回对应url的网页源码,经过解码的内容 :param url: :return: """ # 创建一个请求对象 req = urllib.request.Request(url) # 发起请求,urlopen返回的是一个HTTPResponse对象 resp = urllib.request.urlopen(req) # 获取HTTP源代码,编码格式为utf-8 html_page = resp.read().decode('utf-8') # 返回网页源码 return html_page '''# 获取网页源代码 def get_html(url): # 创建一个响应对象 response=requests.get(url) # 获取整个网页的HTML内容 html_page=response.text # 返回网页的HTML内容 return html_page ''' # 获取博客文章的标题 def get_title(url): ''' 获取对应url下文章的标题 :param url: :return: ''' # 通过博文的地址获取到源代码 html_page = get_html(url) # 创建str变量 title_pattern = r'(<a.*id="cb_post_title_url".*>)(.*)(</a>)' # 匹配到相关的数据 title_match = re.search(title_pattern, html_page) # 获取标题 title = title_match.group(2) # 返回标题 return title # 获取博客文章的文本 def get_Body(url): """ 获取对应url的文章的正文内容 :param url: :return: """ # 通过博客文章的链接,获取博客文章的源代码 html_page = get_html(url) # 创建对象,基于bs4库HTML的格式输出 soup = BeautifulSoup(html_page, 'html.parser') # 定义一个soup进行find()方法处理的标签 div = soup.find(id="cnblogs_post_body") # 返回博客文章内容 return div.text # 保存文章 def save_file(url): """ 根据url,将文章保存到本地 :param url: :return: """ title=get_title(url) body=get_Body(url) filename="Mr_choa"+'-'+title+'.txt' with open(filename, 'w', encoding='utf-8') as f: f.write(title) f.write(url) f.write(body) # 遍历所有的博客文章链接,保存博客的文章 def save_files(url,pageNo): ''' 根据url和pageNo,保存博主所有的文章 :param url: :param pageNo: :return: ''' totol_urls=get_Urls(url,pageNo) for url_ in totol_urls: save_file(url_) # 获取所有的链接 def get_Urls(url,pageNo): """ 根据url,pageNo,能够返回该博主所有的文章url列表 :param url: :param pageNo: :return: """ # 创建一个list,用来装博客文章的地址 total_urls=[] # 对页数做个遍历 for i in range(1,pageNo+1): # 页数的地址 url_1=url+str(i) # 获取这一页的全部源代码 html=get_html(url_1) # 创建一个属性 title_pattern=r'<a.*class="postTitle2".*href="(.*)">' # 通过正则表达式找到所有相关属性的数据,就是所有的博客文章的链接 urls=re.findall(title_pattern,html) # 把链接放到list容器内 for url_ in urls: total_urls.append(url_) #print(total_urls.__len__()) # 返回所有博客文章的链接 return total_urls save_files(url,pageNo)
效果:

打开.txt:
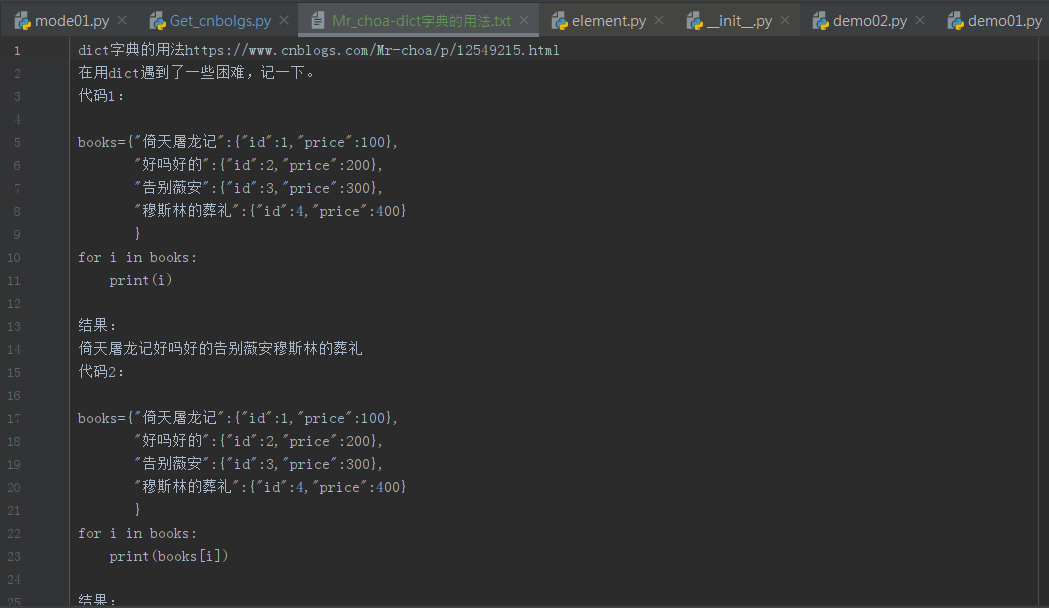
业精于勤而荒于嬉,勤劳一日,可得一日安眠;勤劳一生,可得幸福一生。因为,我们努力了;因为,天道酬勤。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号