
累加器和广播变量
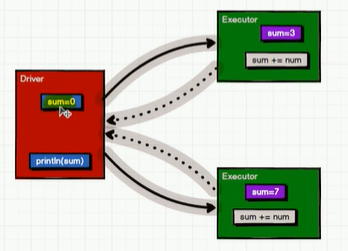
前言:由于Spark的闭包检查,Driver端的数据无法获取到Executor端的计算数据。
因此需要特殊类型——累加器(ACC)

累加器实现原理
累加器用来把Executor端变量信息聚合到Driver端。再Driver程序中定义的变量,在Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后, 传回 Driver 端进行 merge。
调用系统累加器
package com.pzb.acc
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Description TODO
* @author 海绵先生
* @date 2023/4/16-20:16
*/
object Spark02_Acc {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkAcc")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// 获取系统累加器
// Spark默认就提供了简单数据聚合的累加器
val sumAcc: LongAccumulator = sc.longAccumulator("sum")
rdd.foreach(
num => {
sumAcc.add(num)
}
)
println("sumAcc:" + sumAcc) // sumAcc:LongAccumulator(id: 0, name: Some(sum), value: 10)
sc.stop()
}
}
该累加器为long类型,会自动累加并返回结果
系统中还有double、collection类型(内部是List类型)
注意事项
package com.pzb.acc
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
/**
* @Description TODO
* @author 海绵先生
* @date 2023/4/16-20:16
*/
object Spark03_Acc {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkAcc")
val sc = new SparkContext(sparkConf)
val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4))
// TODO 累加器常遇到的问题
val sumAcc: LongAccumulator = sc.longAccumulator("sum")
// 在转换算子中调用
val mapRDD: RDD[Int] = rdd.map(
num => {
// 使用累加器
sumAcc.add(num)
num
}
)
// 少加:转换算子中调用累加器,如果没有行动算子的话,那么不会执行
println(sumAcc.value) // 0
// 多加:转换算子中调用累加器,如果作业被多次执行,那么就会被多次计算
mapRDD.collect()
mapRDD.collect()
println(sumAcc.value) // 20
// TODO 因此累加器一般情况下是放在行动算子中使用的
sc.stop()
}
}
自定义累加器
官方给的集合类型累加器内部是List类型,如果想换成Map获取其他类型就要自定义累加器。
自定义累加器步骤:
1.继承一个抽象类——AccumulatorV2[IN, OUT]
- IN:输入类型
- OUT:输出类型
2.注册累加器
package com.pzb.acc
import org.apache.spark.rdd.RDD
import org.apache.spark.util.{AccumulatorV2, LongAccumulator}
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
/**
* @Description TODO 自定义累加器
* @author 海绵先生
* @date 2023/4/16-20:16
*/
object Spark04_Acc {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkAcc")
val sc = new SparkContext(sparkConf)
val rdd: RDD[String] = sc.makeRDD(List("Hello","Spark","Hello","Word"))
// 创建累加器对象
val accumulator = new MyAccumulator()
// 注册累加器
sc.register(accumulator,"MyAcc")
rdd.foreach{
word => {
accumulator.add(word)
}
}
println(accumulator.value) // Map(Word -> 1, Hello -> 2, Spark -> 1)
sc.stop()
}
class MyAccumulator extends AccumulatorV2[String, mutable.Map[String, Long]]{
// 定义累加器value
private var wcMap = mutable.Map[String, Long]()
// 初始化累加器
override def isZero: Boolean = {
wcMap.isEmpty
}
// 复制累加器方法
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = {
new MyAccumulator()
}
// 重置累加器方法
override def reset(): Unit = {
wcMap.clear()
}
// 获取累加器需要计算的值
override def add(word: String): Unit = {
// 通过key获取value,如果没有key就为0
val newCnt = wcMap.getOrElse(word, 0L) + 1
// 更改Map的值
wcMap.update(word, newCnt)
}
//Driver端合并多个累加器
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
val map1: mutable.Map[String, Long] = this.wcMap
// 获取其他累加器的值
val map2: mutable.Map[String, Long] = other.value
map2.foreach{
case (word, count) => {
val newCnt: Long = map1.getOrElse(word, 0L) + count
map1.update(word,newCnt)
}
}
}
// 获取累加器结果
override def value: mutable.Map[String, Long] = {
wcMap
}
}
}
对一些简单的累加统计可以用累加器来完成,减少Shuffle的操作。
广播变量
闭包数据都是以Task为单位发送的,每个任务中包含闭包数据,这样可能会导致一个Executor中含有大量重复的数据,并且占用大量的内存(Executor其实就是一个JVM,在启动时就会自动分配好内存)。

Spark中的广播变量就可以将闭包的数据保存到Executor的内存中。
Spark中的广播变量是不能改的:分布式共享只读变量。

package com.pzb.acc
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
/**
* @Description TODO 自定义累加器
* @author 海绵先生
* @date 2023/4/16-20:16
*/
object Spark05_Bc {
def main(args: Array[String]): Unit = {
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkAcc")
val sc = new SparkContext(sparkConf)
val rdd: RDD[(String,Int)] = sc.makeRDD(List(("a",1),("b",2),("c",3)))
val map1 = mutable.Map(("a",4), ("b",5), ("c",6))
// 封装广播信息
val bc: Broadcast[mutable.Map[String, Int]] = sc.broadcast(map1)
rdd.map{
case (w, c) => {
val l: Int = bc.value.getOrElse(w,0)
(w,(c,l))
}
}.collect().foreach(println)
/*
(a,(1,4))
(b,(2,5))
(c,(3,6))
*/
sc.stop()
}
}
上面的案例通过广播变量很好的避免了笛卡尔集的发生

 浙公网安备 33010602011771号
浙公网安备 33010602011771号