深入理解intern()
首先来看JDK1.6
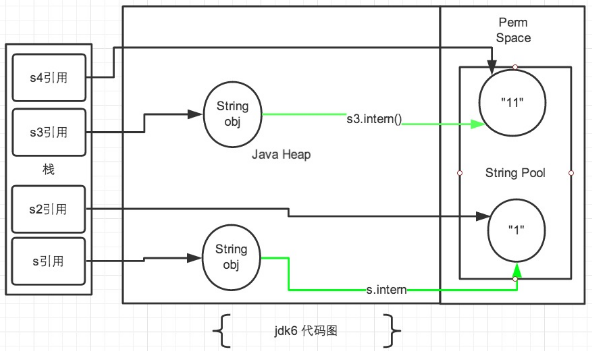
显然JDK1.6及其以前版本常量池是放在 Perm 区(属于方法区)中的,熟悉JVM的话应该知道这是和堆区完全分开的。
1.6中intern方法的作用:
比如String s = new String("SEU_Calvin"),再调用s.intern(),此时返回值还是字符串"SEU_Calvin",表面上看起来好像这个方法没什么用处。但实际上,在JDK1.6中它做了个小动作:检查字符串池里是否存在"SEU_Calvin"这么一个字符串,如果存在,就返回池里的字符串;如果不存在,该方法会把"SEU_Calvin"添加到字符串池中,然后再返回它的引用。
String s = new String("1"); s.intern(); String s2 = "1"; System.out.println(s == s2); String s3 = new String("1") + new String("1"); s3.intern(); String s4 = "11"; System.out.println(s3 == s4);
那么来看这段代码
使用引号声明的字符串都是会直接在字符串常量池中生成的,而 new 出来的 String 对象是放在堆空间中的。所以两者的内存地址肯定是不相同的,即使调用了intern()方法也是不影响的。
所以两个都是false
然后JDK1.7及其以后版本
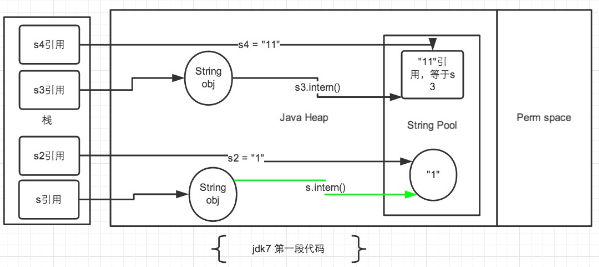
还是刚才的代码
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
结果是在JDK1.7以及以后版本中答案却是false true
第一到四行代码运行过程:
第一行:new String(“1”) 中的“1”,那么首先检查常量池是否有“1”,如果没有则在堆上创建“1”,并将堆上“1”的引用添加到常量池,如果有,则堆上新建“1”存储常量池“1”的引用
然后new String 则在堆上创建另一个不同于第一个在堆上“1”的“1”,并将栈上的s指向该1
第二行:检查常量池中是否有“1”,如果没有就将s指向堆中的“1”的引用存入常量池,如果有返回常量池“1”的引用
String s2=“1”引用赋值,则直接检查常量池中是否有1,如果有则s2指向常量池中的1(即堆中的第一个“1”) 若没有则在堆上创建“1”,并将常量池存入该“1”的引用
显然s2指向的是之前new String(“1”)中的1(堆中的第一个“1”)
第四步 s指向的是堆中第二个“1” s2指向堆中第一个“1” 固为false
第四行到第8行代码分析:
第一行:堆上先建一个“1” ,其引用至常量池 s3指向堆中“11” 此时常量池只有“1”,无“11”
s3.intern()将s3的“11”引用加入到常量池中
s4=“11”检查常量池是否有11 如果有(常量池中的“11”)为s3的引用
则将s4指向常量池中的“11”(就是s3) 所以s3=s4
但需要注意以下
String s1 = new String("1") + new String("1") (变量+...)和String s2 = "1"+"1"(常量加常量)不同
s1在赋值阶段 调用StringBuilder在堆上创建对象。 而s2是检查常量池,从而决定在堆上创建还是直接引用常量池中的变量
final修饰的串,final修饰的串在编译时就会被替换成常量(即 final s1就看成“11”常量)
图文部分来自:
https://blog.csdn.net/seu_calvin/article/details/52291082

 浙公网安备 33010602011771号
浙公网安备 33010602011771号