MIT6.5840 2024 Spring Lab3
MIT6.5840 2024 Spring Lab3
前言
此lab是该课程的第三个实验,这个实验会让你实现Raft算法,最终实现一个容错的KV存储系统。该实验主要有四部分组成3A:leader选举,3B:日志,3C:持久化,3D:日志压缩。这四个部分我是单独完成的,也就是做完3A再做3B以此类推,很多人说3A和3B可以一起,不过为了后面自己看的时候不会懵逼我就分开来做了,代码也会分开展示,因为不同部分可能会用到同一段代码会有重复,所以下面的文章可能看起来全是代码。
前置知识
GO
1.select:
select时go里面的控制语句,很像switch的结构,内部也有很多case,每个case都是接收channel信息或者发送channel信息,select会选择一个可执行case执行,如果没有可执行的case就会阻塞,如果有default,就会执default。
select {
case <-channel1:
//channel1成功收到数据
code...
case channel2 <- i:
//channel2成功接受数据,channel2如果是无缓冲channel,如果没人执行 <-channel2,就会一直阻塞在这个位置
code...
default:
//默认执行
code...
}
2.Timer:
一次性的定时器,时间到达执行一次,之后需要Reset才能重新启动。
timer := time.NewTimer(1*time.MilliSecond) //返回值类型为 *time.Timer
t := <-timer.C //Time类型的channel,等定时器时间到了才会执行
code...
timer.Reset(1*time.MilliSecond) //重置时间
Raft算法Leader选举部分
其实这部分论文原文写的非常详细了,直接看论文就行,下面这部分,3B,3C,3D通用。
Raft中文版本
Raft英文原文
Raft可视化
3A Leader选举
Raft结构体部分
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
/*****moyoj-3A******/
statusAccessMutex sync.Mutex //其实可以直接用上面的mu,当时没注意到,就自己定义了一个
heartsbeatsTimer *time.Timer //leader心跳定时器
electionTimer *time.Timer //选举超时定时器
heartsbeatsTime int //发送一次心跳时间间隔
electionTimeout int //选举超时时间
state int //0:follower 1:leader 2:candidate
currentTerm int //当前任期
votedFor int //投票投给了谁,-1代表没有投票
leaderId int //当前leader的id,为了重定向
logs []logEntry //日志
}
RPC消息类型
这部分跟论文一致就行
type RequestVoteArgs struct {
// Your data here (3A, 3B).
/*****moyoj-3A******/
Term int
CandidateId int
}
// example RequestVote RPC reply structure.
// field names must start with capital letters!
type RequestVoteReply struct {
// Your data here (3A).
/*****moyoj-3A******/
Term int
VoteGranted bool
}
type AppendEntriesRequest struct {
/*****moyoj-3A******/
Term int
LeaderId int
Entries []logEntry
PreLogIndex int
PreLogTerm int
LeaderCommit int
}
type AppendEntriesResponse struct {
/*****moyoj-3A******/
Term int
Success bool
}
electStart
函数三个参数:启动leader选举时的term、启动leader选举的节点号、对端数量(为了防止data race),这部分我启动了多个go routine同时发送RequestVote消息,并设置了一个waitgroup等待收集到所有的结果,但是因为这个函数本身就是单独启动的routine所以整个程序并不会阻塞在这个函数,在进入该函数的同时,选举超时定时器一直启动着,如果一定时间内没有收到leader心跳或者本身选举失败(选票被瓜分)会再次启动选举。
func (rf *Raft) electStart(curterm int, me int, peerslen int) {
var sendWaitGroup sync.WaitGroup
voteCount := 1 //选票数,初始值为1,代表自己给自己投票
DPrintf("[%v],begin leader election,term:%v", me, curterm)
for i := 0; i < peerslen; i++ {
if i == me { //不用给自己发送投票请求
continue
}
sendWaitGroup.Add(1)
go func(serverid int) {
var request RequestVoteArgs
var response RequestVoteReply
request.CandidateId = me
request.Term = curterm
ok := rf.sendRequestVote(serverid, &request, &response)
if ok { //正常收到信息
rf.statusAccessMutex.Lock() //防止处理过程状态改变加锁
if rf.state==2 && rf.currentTerm==curterm{ //进入处理之前,先判断term是否改变,自身的状态是否还是候选者
if response.VoteGranted { //对端同意投票
voteCount += 1 //票数加1
if voteCount >= peerslen/2 +1{ //如果票数超过一半,
rf.state = 1 //变成leader
rf.votedFor = -1 //重置投票对象为空,为了当leader变成follower的时候能正常投票
go rf.sendHeartsbeats(curterm,me,peerslen) //立刻发送心跳给其他人
rf.heartsbeatsTimer.Reset(time.Duration(rf.heartsbeatsTime)*time.Millisecond) //重置心跳计时
}
} else { //对端拒绝投票
if response.Term > rf.currentTerm { //对端拒绝投票的原因:1:当前term过期 2:已经投给其他人,如果term过期就会进入次if语句
rf.currentTerm = response.Term //更新term
rf.state = 0 //变成follower
rf.votedFor = -1 //!!!!!选举失败,置成未投票状态
//重置选举超时计时
rf.electionTimer.Reset(time.Duration(rf.electionTimeout + rand.Intn(rf.electionTimeout))*time.Millisecond)
}
}
}
rf.statusAccessMutex.Unlock()
}
sendWaitGroup.Done()
}(i)
}
sendWaitGroup.Wait() //等待所有请求结果
/**进入一下代码之前,当前节点可能呢过分为多种状态 :
1.term没变,并且变成了leader
2.term没变,但是中途收到其他同term的leader发的心跳,变成了follower
3.term过期,变成follower,导致此情况的可能性
1.可能是回复消息给定的term更大
2.其他term更大候选者请求此节点投票
3.term更大的leader发送心跳给此节点
4.term没变,状态仍是candidate,说明没得到足够选票,选票被瓜分了
*/
rf.statusAccessMutex.Lock()
if rf.state==2 && rf.currentTerm == curterm{ //处于状态4的时候,进入这次if,状态1-3不用处理因为其他routine已经正常处理了
rf.state=0 //变成follower
rf.votedFor = -1 //投票对象重置以便能继续投票
rf.electionTimer.Reset(time.Duration(rf.electionTimeout + rand.Intn(rf.electionTimeout))*time.Millisecond)
}
rf.statusAccessMutex.Unlock()
}
sendHeartsbeats
leader发送的心跳也和投票选举一样启动多个线程一起发送,参数的含义也相同。
func (rf *Raft) sendHeartsbeats(curterm int, me int, peerslen int) {
for i := 0; i < peerslen; i++ {
if i == me { //跳过自己
continue
}
go func(serverid int) {
var request AppendEntriesRequest
var response AppendEntriesResponse
request.Entries = []logEntry{}
request.LeaderId = me
request.Term = curterm
ok := rf.peers[serverid].Call("Raft.AppendEntries", &request, &response)
if ok {
rf.statusAccessMutex.Lock()
if !response.Success && rf.currentTerm == curterm { //如果心跳发送回复失败,并且当前term和发送时相比没变
rf.currentTerm = response.Term //改为最新term
rf.state = 0 //变为follower
rf.votedFor = -1 //投票对象重置
//超时选举时间重置
rf.electionTimer.Reset(time.Duration(rf.electionTimeout + rand.Intn(rf.electionTimeout))*time.Millisecond)
}
rf.statusAccessMutex.Unlock()
}
}(i)
}
}
AppendEntries
func (rf *Raft) AppendEntries(request *AppendEntriesRequest, response *AppendEntriesResponse) {
/*****moyoj-3A******/
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
if request.Term < rf.currentTerm { //请求的term小于当前term,回复false
response.Success = false //失败标志
response.Term = rf.currentTerm //让旧leader更新自己term
return
}
/**这里不能重置voteFor = -1
假设一种情况:节点0(term=1),发起leader选举,并且该节点成功投票给节点0,节点0成功成为leader(term=1)
然后该节点收到节点0的心跳,并重置了voteFor,但是由于某个节点i因为网络不好没收到过节点0的任何消息,某一时刻
网络恢复,超时选举还正好触发,宣布开始leader选举(term=1),由于该节点voteFor重置了,那么仍然能投票给i,其他的节点
除了leader 0都能给节点i投票,成功收到半数以上的投票,i变成leader(term=1),此时就出现了两个leader,显然是不允许的!
我代码的逻辑是,“只有自己作为candidate并且参选失败时,或者作为leader时由于term落后变为follower时,这两种情况下才会重置
voteFor为-1”
*/
rf.state = 0 //变为follower
response.Success = true //回复成功
rf.currentTerm = request.Term //刷新term
rf.leaderId = request.LeaderId //切换leader
//重置超时选举时间
rf.electionTimer.Reset(time.Duration(rf.electionTimeout + rand.Intn(rf.electionTimeout))*time.Millisecond)
}
RequestVote
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (3A, 3B).
/*****moyoj-3A******/
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
if args.Term < rf.currentTerm { //请求的term小于当前节点,直接拒绝投票,回复最新的term
reply.VoteGranted = false
reply.Term = rf.currentTerm
return
}
if args.Term == rf.currentTerm { //如果term和当前节点相同
//如果当前节点已经是leader 或者 已经给别人投票,也回复拒绝投票,防止出现多个leader
if rf.state == 1 || rf.votedFor != -1{
reply.VoteGranted = false
reply.Term = rf.currentTerm
return
}
}
/**下面几种情况会选择投票
1.自己的term小,那肯定会选择投票并变成follower
2.自己的term和请求的term相同,此时肯定还没投票,自己也不是leader,这种情况极有可能是当前节点本来是
candidate但是选票不够一半以上,变成了follower(上文重置了voteFor就是为了这种情况),正好此时另一
个候选人投票请求到了,你就可以继续投票,你可能会说这种情况太难遇到了,但是面对复杂的网络就算很难发
生的情况,为了稳定也要考虑!
*/
rf.votedFor = args.CandidateId //投票候选人
rf.currentTerm = args.Term //更新当前term
rf.state = 0 //变为follower
reply.VoteGranted = true //同意投票
reply.Term = args.Term //这里设置不设置都行
//选举超时重置
rf.electionTimer.Reset(time.Duration(rf.electionTimeout + rand.Intn(rf.electionTimeout))*time.Millisecond)
}
tricker
func (rf *Raft) ticker() {
for rf.killed() == false {
select {
case <-rf.electionTimer.C: //选举超时事件发生
rf.statusAccessMutex.Lock()
if rf.state==0 || rf.state==2{ //当前状态为follower或者candidate
rf.state=2 //声明为candidate
rf.votedFor = rf.me //给自己投票,防止给其他candidate投票,导致多个leader
rf.currentTerm+=1 //term增加(逻辑时钟肯定要往前)
go rf.electStart(rf.currentTerm,rf.me,len(rf.peers)) //启动选举
//重设选举超时计时
rf.electionTimer.Reset(time.Duration(rf.electionTimeout + rand.Intn(rf.electionTimeout))*time.Millisecond)
}
rf.statusAccessMutex.Unlock()
case <-rf.heartsbeatsTimer.C: //定期发送心跳事件
rf.statusAccessMutex.Lock()
if rf.state==1{ //如果当前还是leader
go rf.sendHeartsbeats(rf.currentTerm,rf.me,len(rf.peers)) //启动发送心跳routine
//重设心跳超时计时
rf.heartsbeatsTimer.Reset(time.Duration(rf.heartsbeatsTime)*time.Millisecond)
}
rf.statusAccessMutex.Unlock()
}
}
}
Make
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me //可以作为唯一标识符
// Your initialization code here (3A, 3B, 3C).
/*****moyoj-3A******/
rf.currentTerm = 0 //初始term为0
rf.votedFor = -1 //初始未投票
rf.state = 0 //初始都为follower
rf.logs = []logEntry{}
rf.heartsbeatsTime = 110 //心跳时间间隔(ms)
rf.electionTimeout = 1000 //选举超时时间[1000,2000]之间,随机产生
//随机选举超时时间,防止瓜分选票迟迟选不出leader
rf.electionTimer = time.NewTimer(time.Duration(rf.electionTimeout + rand.Intn(rf.electionTimeout))*time.Millisecond)
rf.heartsbeatsTimer = time.NewTimer(time.Duration(rf.heartsbeatsTime)*time.Millisecond)
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
// start ticker goroutine to start elections
go rf.ticker()
return rf
}
压测结果

3B日志
修改部分
该部分只给出原本的函数或者结构体修改的部分,可能会看到原本就有的代码是为了给出修改代码的相对位置。
Raft结构体部分
/*****moyoj-3B******/
//to test
applyChan chan ApplyMsg //将已经commit的日志发送到该通道,用于通过测试
commitIndex int //当前节点已知的已经commit的最后一条日志的index
lastApplied int //当前节点已经应用到状态机的最后一条日志的index
//leader
nextIndex []int //记录每个节点的需要发送到该节点的下一条日志index
matchIndex []int //记录每个节点的已经和leader匹配上的最后一条日志的index
RPC消息类型
1.RequestVoteArgs
/*****moyoj-3B******/
LastLogIndex int //candidate最后一条日志的index
LastLogTerm int //candidate最后一条日志的term
2.AppendEntriesResponse
/*****moyoj-3B******/
FastBack int //为了让leader快速更新follower的nextIndex
Maske
/*****moyoj-3B******/
rf.commitIndex = -1
rf.lastApplied = -1
rf.nextIndex = make([]int, len(rf.peers))
rf.matchIndex = make([]int, len(rf.peers))
rf.applyChan = applyCh
go rf.applyEntries(20) //20ms apply一次日志到状态机
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
// start ticker goroutine to start elections
go rf.ticker()
return rf
ticker
case <-rf.electionTimer.C:
rf.statusAccessMutex.Lock()
if rf.state == 0 || rf.state == 2 {
rf.state = 2
rf.votedFor = rf.me
rf.currentTerm += 1
/*****moyoj-3B******/
lastLogIndex := -1 //进行leader选举为了确保安全性,candidate需要发送自己的最后一条日志的index和term
lastLogTerm := -1
if len(rf.logs) != 0 { //没有日志就默认-1
lastLogIndex = len(rf.logs) - 1 //最后一条日志的index
lastLogTerm = rf.logs[len(rf.logs)-1].Term //最后一条日志的term
}
go rf.electStart(rf.currentTerm, lastLogIndex, lastLogTerm, rf.me, len(rf.peers))
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
}
rf.statusAccessMutex.Unlock()
RequestVote(函数末尾)
新增的部分主要是为了确保日志复制的安全,确保新的领导人日志最新,候选人日志记录必须不旧于(大于或者等于)大部分节点的日志记录,何为较新?最后一条日志term更大的日志记录更新 或者 最后一条日志term相等但是日志记录数目多的更新。
以上两点共同确保了安全性
reply.VoteGranted = true //默认为true:投票给该请求candidate
if len(rf.logs) != 0 && rf.logs[len(rf.logs)-1].Term > args.LastLogTerm { //请求者最后一条日志term落后
reply.VoteGranted = false
}
//请求者最后一条日志term与当前节点相同,但是日志数目较少
if len(rf.logs) != 0 && rf.logs[len(rf.logs)-1].Term == args.LastLogTerm && args.LastLogIndex < len(rf.logs)-1 {
reply.VoteGranted = false
}
//如果投票成功则更新voteFor,重置选举超时时间
if reply.VoteGranted{
//更新leaderid和term
rf.votedFor = args.CandidateId //投票候选人
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
}
rf.currentTerm = args.Term
rf.state = 0
reply.Term = args.Term
AppendEntries
增加了检测leader发送的新日志前面的日志放入term是否与follower匹配,如果不匹配则追加日志失败,leader的nextIndex应该后移到与follower对应位置日志匹配的地方,匹配指的是该位置日志的index相同,term也相同。如果发送的新日志前面没有日志,也视作匹配成功,就直接把follower的日志全都替换成leader发送的日志。
/*****moyoj-3B******/
response.Success = true //默认追加日志(或者心跳)成功
if rf.matchNewEntries(request.Entries, request.PreLogIndex, request.PreLogTerm,response) {
//只有成功匹配上leader的日志,才能更新commitIndex,如果没有成功匹配上日志说明当前节点日志与leader不同步,日志可能落后,如果更新commitIndex可能会导致旧的日志提交到状态机
if request.LeaderCommit > rf.commitIndex {
if len(rf.logs)-1 < request.LeaderCommit { //选择当前节点最后一个新日志的index和leader的commitIndex更小的那个
rf.commitIndex = len(rf.logs) - 1
} else {
rf.commitIndex = request.LeaderCommit
}
}
}
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
rf.currentTerm = request.Term
rf.state = 0
rf.leaderId = request.LeaderId
response.Term = request.Term
sendHeartsbeats
参数增加一个(leaderCommit int)传入当前leader的commitIndex(leader已知的已经提交日志的最大index),该函数主要增加了发送心跳的同时携带日志发送到follower,并对commitIndex、nextIdex和matchIndex进行更新。
go func(serverid int) {
var request AppendEntriesRequest
var response AppendEntriesResponse
request.Entries = []logEntry{}
request.LeaderId = me
request.Term = curterm
request.LeaderCommit = leaderCommit
/*****moyoj-3B******/
request.PreLogIndex = -1 //最前面要追加日志的前一条日志index默认为-1
request.PreLogTerm = -1
rf.statusAccessMutex.Lock()
if rf.currentTerm != curterm {
rf.statusAccessMutex.Unlock()
return
}
nextIndex := rf.nextIndex[serverid]
//一次性发送没发送的日志
request.Entries = rf.logs[nextIndex:len(rf.logs)] //获取要追加的日志
request.PreLogIndex = nextIndex - 1
if (nextIndex - 1) >= 0 { //存在前一条日志
request.PreLogTerm = rf.logs[nextIndex-1].Term
}
rf.statusAccessMutex.Unlock()
ok := rf.peers[serverid].Call("Raft.AppendEntries", &request, &response)
if ok {
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
if rf.currentTerm == curterm {
if !response.Success {
if rf.currentTerm < response.Term {
rf.currentTerm = response.Term
rf.state = 0
rf.votedFor = -1
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
} else { //term并没落后,说明是日志不匹配导致的失败
/*****moyoj-3B******/
//nextIndex后移,定位到与该follower日志匹配的地方
rf.nextIndex[serverid] = response.FastBack
}
}
if len(request.Entries)==0 || !response.Success{ //如果追加日志为空说明是心跳就不需要更新了,如果追加失败也不需要更新
return
}
//成功发送日志追加
/*****moyoj-3B******/
rf.nextIndex[serverid] = rf.nextIndex[serverid] + len(request.Entries) //下一条要发送到该follower的日志index更新
rf.matchIndex[serverid] = rf.nextIndex[serverid] - 1
//这里更新一下commitIndex
for maxMatchIndex := rf.commitIndex; maxMatchIndex < len(rf.logs); maxMatchIndex++ {
// 领导人只能对自己任期内的日志commit,不会对旧term的日志进行提交(如果提交旧的日志就会碰到论文5.4.2的情况),新领导人对自己任期内新日志提交会顺带把旧的提交。这里所谓的提交其实就是领导人更新commitIndex!只有当前term有新的日志产生才会更新commitIndex,非常重要!!
if maxMatchIndex == -1 || rf.logs[maxMatchIndex].Term != rf.currentTerm {
continue
}
//统计该该位置日志在对端的复制情况
count := 1 //算上自己
for peersIndex := 0; peersIndex < len(rf.peers); peersIndex++ {
if peersIndex == me {
continue
}
//当前这个follower的最后一个匹配日志的index大于等于当前验证的matchIndex
if maxMatchIndex <= rf.matchIndex[peersIndex] {
count++
}
}
//对于当前Index的日志的复制情况,自身加上follower超过了一半则更新commitIndex
if count >= len(rf.peers)/2+1 {
rf.commitIndex = maxMatchIndex
}
}
}
}
}
electStart
主要增加了(lastLogIndex int, lastLogTerm int)两个参数,leader选举之前传入最后一条日志的term和index为了保证选举安全,不会选出日志比较落后的leader,成为leader时更新nextIndex和matchIndex。
go func(serverid int) {
var request RequestVoteArgs
var response RequestVoteReply
request.CandidateId = me
request.Term = curterm
/*****moyoj-3B******/
request.LastLogIndex = lastLogIndex
request.LastLogTerm = lastLogTerm
ok := rf.sendRequestVote(serverid, &request, &response)
if ok {
rf.statusAccessMutex.Lock()
if rf.state == 2 && rf.currentTerm == curterm {
if response.VoteGranted {
voteCount += 1
if voteCount >= peerslen/2+1 {
rf.state = 1
rf.votedFor = -1
/*****moyoj-3B******/
//重置next和match数组
for index := 0; index < len(rf.peers); index++ {
rf.nextIndex[index] = len(rf.logs) //每个follower下一条要发送日志的index更新成自身日志的总数
rf.matchIndex[index] = -1 //每个follower已经和leader匹配的最后一条日志index
}
go rf.sendHeartsbeats(curterm, rf.commitIndex, me, peerslen)
rf.heartsbeatsTimer.Reset(time.Duration(rf.heartsbeatsTime) * time.Millisecond)
}
} else if response.Term > rf.currentTerm{ //是因为term落后导致的投票失败,把自身变成follower,日志落后不需要变成follower,因为可能只是和当前发送的follower相比日志落后,但和其他的比未必落后。
rf.currentTerm = response.Term
rf.state = 0
rf.votedFor = -1 //!!!!!选举失败,置成未投票状态
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
}
}
rf.statusAccessMutex.Unlock()
}
sendWaitGroup.Done()
}(i)
新增函数
Start
追加一条新的command到leader节点,返回值:
- command如果提交成功对应日志的Index
- 追加命令时leader的term
- 该节点是否为leader
func (rf *Raft) Start(command interface{}) (int, int, bool) {
index := -1
term := -1
isLeader := true
// Your code here (3B).
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
if rf.state != 1 {
isLeader = false
} else {
rf.logs = append(rf.logs, logEntry{command, rf.currentTerm})
index = len(rf.logs) //返回追加命令对应日志的Index,测试默认初始index为1,所以返回日志个数就是新增命令对应日志的index
term = rf.currentTerm //返回当前term
}
return index, term, isLeader
}
applyEntries
向服务层提交达到共识的操作。
func (rf *Raft) applyEntries(sleep int) {
for !rf.killed(){ //当前进程没被杀死
time.Sleep(time.Duration(sleep)*time.Millisecond)
rf.statusAccessMutex.Lock()
for ; rf.lastApplied < rf.commitIndex; rf.lastApplied++ {
var sendApply ApplyMsg
sendApply.Command = rf.logs[rf.lastApplied+1].Command //待apply的command
sendApply.CommandIndex = rf.lastApplied + 2 //待apply的command的index(因为论文默认index初始为1,所以这里+2)
sendApply.CommandValid = true
rf.applyChan <- sendApply
}
rf.statusAccessMutex.Unlock()
}
}
matchNewEntries
判断日志是否匹配指的是,当leader发送新的日志是否和当前存在的日志同index下term也相同。
func (rf *Raft) matchNewEntries(Entries []logEntry, preLogIndex int, preLogTerm int,response *AppendEntriesResponse) bool {
if preLogIndex != -1 && len(rf.logs) <= preLogIndex { //该节点的所有日志中没有下标为preLogIndex的项,也就是当前节点日志没这么多
response.Success = false
response.FastBack = len(rf.logs) //让leader快速定位应该发送的下一个日志的位置
return false
}
if preLogIndex != -1 && rf.logs[preLogIndex].Term != preLogTerm { //同下标的日志项的term与新日志的term不匹配
response.FastBack = rf.commitIndex+1 //让leader的nextIndex直接跳到当前节点的commitIndex+1处,因为commitIndex处的日志肯定和leader匹配,0-commitIndex的所有日志都是已经复制到大多数节点的日志,如果想成为leader,至少包含这些日志,否则不可能成为leader
response.Success = false
return false
}
//匹配成功,preLogIndex=-1说明当前节点没有日志或者包含的日志全都与leader不匹配(直接全删掉就行,leader的日志最优先)
response.Success = true
rf.logs = rf.logs[0 : preLogIndex+1] //follower匹配的日志后面的所有日志删除掉
rf.logs = append(rf.logs, Entries...) //追加leader发来的日志
return true
}
压测结果
1000次稳定运行

3C 持久化
3C实现是实现日志持久化,课程给出了对应的函数,只需要稍作修改,然后在原来的代码合适的位置调用就能完成3C,难不难全看3A,3B实现的如何,如果3A,3B稳定运行1000次以上不出错,3C就很少会遇到bug,至少在我实现3C的时候只遇到一个bug需要修改之前的代码。
修改部分
只要需要持久化的数据改变,就应该调用一下persist保存该数据。
electStart
if response.VoteGranted {
voteCount += 1
if voteCount >= peerslen/2+1 {
rf.state = 1
rf.votedFor = -1
/*****moyoj-3C******/
rf.persist()
/*****moyoj-3B******/
code....
........
}
} else if response.Term > rf.currentTerm {
code....
......
/*****moyoj-3C******/
rf.persist()
}
code...
......
if rf.state == 2 && rf.currentTerm == curterm {
code....
.......
/*****moyoj-3C******/
rf.persist()
}
sendHeartsbeats
在我遇到的唯一一个bug里,就是发生在这个函数中更新nextIndex的地方,该bug会导致下一次往这个follower发送日志时导致切片越界。假设可能的一种情况如图:
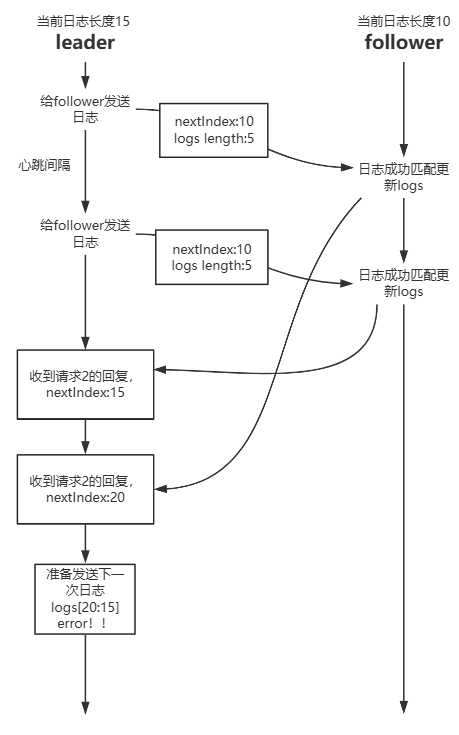
这只是一种可能,由于不太了解go的rpc调用具体细节,我无法给出这种情况发生的具体原因,我只能给出猜测。这个实验的调用都是模拟出,宕机也是模拟出的,如果让我写一个rpc远程调用框架,那我肯定会用TCP连接服务端,这样客户端发起的请求和返回的结果按理说都是有序的(先发的请求,回复的结果先收到),不会出现这种先发的请求,请求结果后到的情况。我本以为是这原因,但实际上就算有序到达也有可能会导致切片越界的情况,但仔细考虑之后发现主要原因可能是:允许leader对同一个follower追击日志的routine可以有多个并行导致的,如果同一时间只允许对一个follower启动一个routine进行日志追加就绝对不会出现:多个日志追加请求对同一个follower追加同一段日志的情况。
因为追加日志的routine都是并发运行,可能在某个请求返回结果更新当前节点的nextIndex前,另一个请求就发送出去了,然后对方处理完之后很快就返回了请求结果,导致两个请求结果几乎同时返回,然后抢夺rf.statusAccessMutex这把锁,先进入的先更新nextIndex,后面进入的在此基础上更新nextIndex,这就会导致错误,因为两个请求可能是对同一段日志进行的追加请求,返回的结果应该只应用到nextIndex上一次而不是两次。最理想的请求情况应该如下:
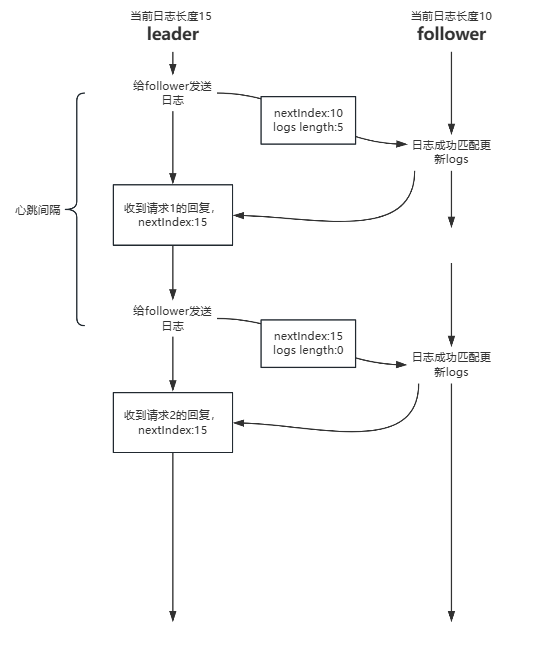
上图实现其实也好实现,只需要对每个follower设一把锁,当针对某个follower发送的请求得到回复并运用到对应的nextIndex时才释放锁,才允许开始处理并发送下一个针对该follower的请求。
以上都是我的猜测,真正的原因我不确定,如果有佬看到愿意给出解答我将十分感激!
if ok {
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
if rf.currentTerm == curterm {
if !response.Success {
if rf.currentTerm < response.Term {
code...
......
/*****moyoj-3C******/
rf.persist()
} else {
/*****moyoj-3B******/
//nextIndex后移
rf.nextIndex[serverid] = response.FastBack
}
}
if len(request.Entries) == 0 || !response.Success {
return
}
//成功发送日志追加
/*****moyoj-3B 3C******/
//3C Figure8(unreliable)bug1:更新rf.nextIndex前检查一下当前rf.nextIndex[serverid]是否还和发送日志时一样,如果不一样说明,在等待Call返回期间改变了(已经成功追加日志到follower),因为调用Call的时候并没有加锁,对同一个follower可能会多次调用,这次调用的返回结果就是过期的。
if nextIndex == rf.nextIndex[serverid]{ //rf.nextIndex[serverid]没有变更,还是和当时发送消息时一样
rf.nextIndex[serverid] = nextIndex + len(request.Entries)
}
rf.matchIndex[serverid] = rf.nextIndex[serverid] - 1
//这里更新一下commitIndex
code...
.......
}
}
AppendEntries
unc (rf *Raft) AppendEntries(request *AppendEntriesRequest, response *AppendEntriesResponse) {
/*****moyoj-3A******/
code...
.....
/*****moyoj-3B******/
code....
......
/*****moyoj-3C******/
rf.persist()
}
RequestVote
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
/*****moyoj-3A******/
code...
.......
/*****moyoj-3B******/
code...
......
/*****moyoj-3C******/
rf.persist()
}
Start
func (rf *Raft) Start(command interface{}) (int, int, bool) {
code....
........
if rf.state != 1 {
isLeader = false
} else {
code...
......
/*****moyoj-3C******/
rf.persist()
}
return index, term, isLeader
}
ticker
case <-rf.electionTimer.C:
rf.statusAccessMutex.Lock()
if rf.state == 0 || rf.state == 2 {
code...
......
/*****moyoj-3C******/
rf.persist()
/*****moyoj-3B******/
code...
......
}
rf.statusAccessMutex.Unlock()
新增函数
persiste
持久化信息。
func (rf *Raft) persist() {
/*****moyoj-3C******/
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.logs)
raftstate := w.Bytes()
rf.persister.Save(raftstate, nil)
}
readPersist
读取持久化信息。
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
/*****moyoj-3C******/
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var currentTerm int
var votrFor int
var logs []logEntry
if d.Decode(¤tTerm) != nil || d.Decode(&votrFor) != nil || d.Decode(&logs) != nil {
DPrintf("持久化数据解析失败")
} else {
rf.currentTerm = currentTerm
rf.votedFor = votrFor
rf.logs = logs
}
}
压测结果
因为运行时间比较长,我就测试了500次。

3D 日志压缩
这部分修改了非常多的代码,只要涉及了日志index几乎都修改了,因为多了快照这一部分,logs切片的下标和实际日志的index就没有固定的对应关系,实际上我的代码logs切片的下标就对应了日志的下标(index从0开始),不过我在往channel发送数据的时候日志index都加了1,代表日志index是从1开始的,但是加了快照之后就不行了,假设快照已经存储最后一条日志index为10,原本logs切片中index=15的日志在新的logs切片中index就是15-10-1=4,这是造成代码大量修的的原因之一,还有一部分原因是新增快照功能,不管是定时往channel上传日志还是发送日志的rpc请求都需要修改。所以我在单独给出新增函数的代码后,我会把整个raft.go文件的代码一次贴出来。
可能会遇到的死锁问题
在实验中你可能会需要定期的向applyCh chan ApplyMsg中发送日志,也就是applyEntries函数,可以看出我在3B和3D中applyEntries代码不一样,最大的区别就是,3B中往channel发送日志的时候,是一直获取着锁,但是3D中我在往channel发送数据的时候先释放了锁,也就是用各个变量的副本传输的数据,等发送完成再获取锁更改变量。当然这样可以提高性能,但主要的原因是如果不释放锁,会导致测试文件与raft.go文件互相等待从而导致死锁。
在config.go的applierSnap函数中,有这样一段代码:
for m := range applyCh {
err_msg := ""
if m.SnapshotValid {
cfg.mu.Lock()
err_msg = cfg.ingestSnap(i, m.Snapshot, m.SnapshotIndex)
cfg.mu.Unlock()
} else if m.CommandValid {
if m.CommandIndex != cfg.lastApplied[i]+1 {
err_msg = fmt.Sprintf("server %v apply out of order, expected index %v, got %v", i, cfg.lastApplied[i]+1, m.CommandIndex)
}
if err_msg == "" {
cfg.mu.Lock()
var prevok bool
err_msg, prevok = cfg.checkLogs(i, m)
cfg.mu.Unlock()
if m.CommandIndex > 1 && prevok == false {
err_msg = fmt.Sprintf("server %v apply out of order %v", i, m.CommandIndex)
}
}
cfg.mu.Lock()
cfg.lastApplied[i] = m.CommandIndex
cfg.mu.Unlock()
if (m.CommandIndex+1)%SnapShotInterval == 0 {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(m.CommandIndex)
var xlog []interface{}
for j := 0; j <= m.CommandIndex; j++ {
xlog = append(xlog, cfg.logs[i][j])
}
e.Encode(xlog)
rf.Snapshot(m.CommandIndex, w.Bytes())
}
} else {
// Ignore other types of ApplyMsg.
}
if err_msg != "" {
log.Fatalf("apply error: %v", err_msg)
cfg.applyErr[i] = err_msg
// keep reading after error so that Raft doesn't block
// holding locks...
}
}
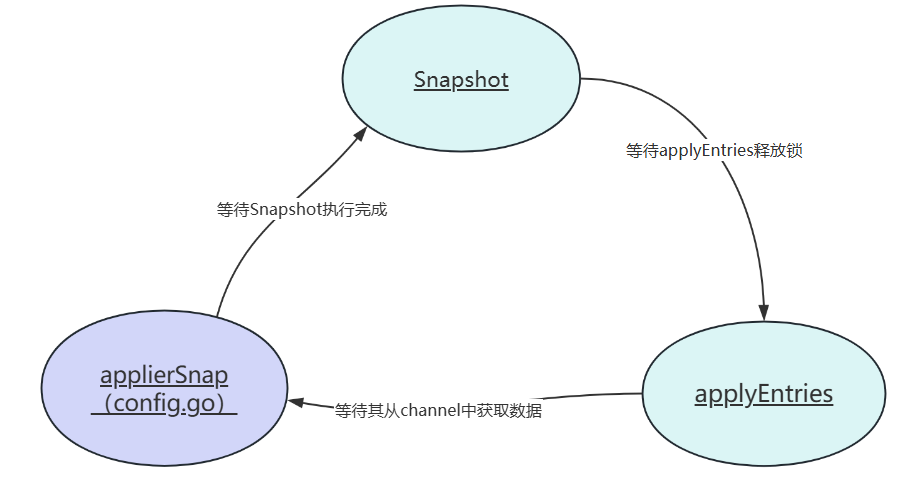
可以看到这个函数是一直从channel中等待日志,也就是等待我们实现的applyEntries函数中发送给channel的日志,如果没有日志发送到channel,for循环就会阻塞,在循环体内,调用了rf.Snapshot也就是我们需要实现的那部分代码,而在Snapshot代码中我们又上锁了临界区,假设一种情况:某个时刻applyEntries正在上传日志到channel,之后上面的代码 if (m.CommandIndex+1)%SnapShotInterval == 0 这个条件满足后会调用Snapshot,但是因为锁现在在applyEntries手上,他在发送日志呢,所以Snapshot会阻塞在这,上述代码的for循环也会停到这个位置,这又导致了没有人从channel中获取数据,这是个无缓冲的channel,没人从channel取数据,发送数据到channel的那一端就会阻塞,也就是applyEntries会阻塞在rf.applyChan <- sendApply,导致它持有锁迟迟没法释放,这就导致了死锁(关系如下),所以往channel发送数据的时候需要先释放锁,等发送完成再获得锁进行后续操作。
新增RPC消息类型
type InstallSnapshotRequest struct {
/*****moyoj-3D******/
Term int
LeaderId int
LastIncludeIndex int //快照最后一个日志的index
LastIncludeTerm int //快照最后一个日志的term
// Offset int
// Data []byte
// Done bool
}
type InstallSnapshotResponse struct {
/*****moyoj-3D******/
Term int
}
新增函数
InstallSnapshot
follower落后,给follower传送leader的snapshot。
func (rf *Raft) InstallSnapshot(request *InstallSnapshotRequest, response *InstallSnapshotResponse) {
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
if request.Term < rf.currentTerm { //请求term落后
response.Term = rf.currentTerm
return
}
curindex := request.LastIncludeIndex - rf.lastSnapshotIndex - 1 //快照中最后一条日志的index在当前节点的logs切片中对应的index
//造成这种情况的原因就是因为模拟网络延迟,同一部分快照发送了多次,同时到达follower,一个请求完成后lastSnapshotIndex会更新,第二个同样的请求计算出的curindex就会成负数,正常情况下curindex>=0
if curindex < 0 {
response.Term = rf.currentTerm
return
}
if curindex < len(rf.logs) { //比当前节点logs长度小,说明当前logs切片最后日志的index比请求中的index更大(或者相等)
//如果请求的index在当前切片对应位置的日志term与请求的term一致,则保留后续日志,否则全部删除,同样的index但是term却和leader的不一样说明这条日志以及后面的日志全都过期了
if rf.logs[curindex].Term != request.Term {
rf.logs = make([]logEntry, 0)
} else {
logs := rf.logs[curindex+1:]
rf.logs = make([]logEntry, len(rf.logs)-curindex-1)
copy(rf.logs, logs)
}
} else { //比当前节点logs长度大,说明当前节点的所有日志在leader中已经全都形成快照,所以直接把logs清空,快照直接用leader的快照
rf.logs = make([]logEntry, 0)
}
//更新状态
rf.lastSnapshotIndex = request.LastIncludeIndex
rf.lastSnapshotTerm = request.LastIncludeTerm
rf.lastApplied = request.LastIncludeIndex
rf.commitIndex = request.LastIncludeIndex
//当成一次心跳,所以需要重置选举超时时间
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
rf.currentTerm = request.Term
rf.state = 0
rf.leaderId = request.LeaderId
response.Term = request.Term
//持久化
rf.persist(request.Data)
//apply snapshot
go func() {
var sendApply ApplyMsg
sendApply.CommandValid = false
sendApply.Snapshot = request.Data
sendApply.SnapshotIndex = rf.lastSnapshotIndex + 1
sendApply.SnapshotTerm = rf.lastSnapshotTerm
sendApply.SnapshotValid = true
rf.applyChan <- sendApply
}()
}
updateNextMatch
更新nextIndex和matchIndex,防止发送心跳函数的代码过于冗余就把更新nextIndex和matchIndex的代码单独拿出来了,参数是leader的id。
/*****moyoj-3D******/
func (rf *Raft) updateNextMatch(me int) {
for maxMatchIndex := rf.commitIndex + 1; maxMatchIndex-rf.lastSnapshotIndex-1 < len(rf.logs); maxMatchIndex++ {
if rf.logs[maxMatchIndex-rf.lastSnapshotIndex-1].Term != rf.currentTerm { //不对旧term的日志进行提交,通过对当前term的日志提交顺便提交旧term的日志 continue
continue
}
//统计该该位置日志在对端的复制情况
count := 1
for peersIndex := 0; peersIndex < len(rf.peers); peersIndex++ {
if peersIndex == me {
continue
}
if maxMatchIndex <= rf.matchIndex[peersIndex] {
count++
}
}
//对于该下标日志的复制情况,自身加上对端超过了一半更新commit
if count >= len(rf.peers)/2+1 {
rf.commitIndex = maxMatchIndex
}
}
}
压测结果
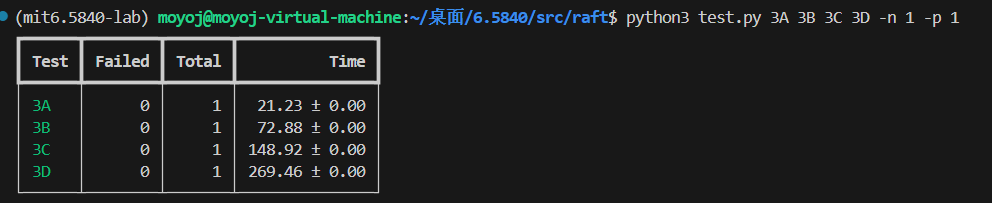
本以为速度有点慢,但是看mit官方的运行结果大差不差的我就没继续优化了。

下图是四个部分都运行一次的总时间。
所有代码
/*****moyoj-3A******/
type logEntry struct {
Command interface{}
Term int
}
// A Go object implementing a single Raft peer.
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (3A, 3B, 3C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
/*****moyoj-3A******/
statusAccessMutex sync.Mutex
//electionTimeout >> heartsbeatsTime
heartsbeatsTimer *time.Timer
electionTimer *time.Timer
heartsbeatsTime int //发送一次心跳时间间隔
electionTimeout int //选举超时时间(超过这个时间(实验要求大于100ms),该服务器就作为候选人开始选举)
leaderId int //当前leader的id
state int //0:follower 1:leader 2:candidater
/*****moyoj-3B******/
//to test
applyChan chan ApplyMsg
commitIndex int
lastApplied int
//leader
nextIndex []int
matchIndex []int
/*****moyoj-3D******/
lastSnapshotIndex int //快照中最后一个日志的下标
lastSnapshotTerm int //快照中最后一个日志的term
currentTerm int
votedFor int
logs []logEntry
}
func (rf *Raft) GetState() (int, bool) {
var term int
var isleader bool
// Your code here (3A).
/*****moyoj-3A******/
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
term = rf.currentTerm
isleader = rf.state == 1
return term, isleader
}
func (rf *Raft) persist(snapshot []byte) {
/*****moyoj-3C******/
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm)
e.Encode(rf.votedFor)
e.Encode(rf.logs)
/*****moyoj-3D******/
e.Encode(rf.lastSnapshotIndex)
e.Encode(rf.lastSnapshotTerm)
raftstate := w.Bytes()
rf.persister.Save(raftstate, snapshot)
}
// restore previously persisted state.
func (rf *Raft) readPersist(data []byte) {
if data == nil || len(data) < 1 { // bootstrap without any state?
return
}
/*****moyoj-3C******/
r := bytes.NewBuffer(data)
d := labgob.NewDecoder(r)
var currentTerm int
var votrFor int
var logs []logEntry
/*****moyoj-3D******/
var lastSnapshotIndex int
var lastSnapshotTerm int
if d.Decode(¤tTerm) != nil || d.Decode(&votrFor) != nil || d.Decode(&logs) != nil || d.Decode(&lastSnapshotIndex) != nil || d.Decode(&lastSnapshotTerm) != nil {
DPrintf("持久化数据解析失败")
} else {
rf.currentTerm = currentTerm
rf.votedFor = votrFor
rf.logs = logs
rf.lastSnapshotIndex = lastSnapshotIndex
rf.lastSnapshotTerm = lastSnapshotTerm
//初始化为snapshot最后一条日志的下标,否则crash重启applyEntries会越界
rf.lastApplied = lastSnapshotIndex
rf.commitIndex = lastSnapshotIndex
}
}
func (rf *Raft) Snapshot(index int, snapshot []byte) {
// Your code here (3D).
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
if index-1 <= rf.lastSnapshotIndex {
return
}
if index-1 > rf.commitIndex {
return
}
rf.lastSnapshotTerm = rf.logs[index-1-rf.lastSnapshotIndex-1].Term
temp := rf.logs[index-rf.lastSnapshotIndex-1:]
rf.lastSnapshotIndex = index - 1
rf.logs = make([]logEntry, len(temp))
copy(rf.logs, temp)
rf.persist(snapshot)
}
type RequestVoteArgs struct {
// Your data here (3A, 3B).
/*****moyoj-3A******/
Term int
CandidateId int
/*****moyoj-3B******/
LastLogIndex int
LastLogTerm int
}
type RequestVoteReply struct {
// Your data here (3A).
/*****moyoj-3A******/
Term int
VoteGranted bool
}
type AppendEntriesRequest struct {
/*****moyoj-3A******/
Term int
LeaderId int
Entries []logEntry
PreLogIndex int
PreLogTerm int
LeaderCommit int
}
type AppendEntriesResponse struct {
/*****moyoj-3A******/
Term int
Success bool
/*****moyoj-3B******/
FastBack int
}
type InstallSnapshotRequest struct {
/*****moyoj-3D******/
Term int
LeaderId int
LastIncludeIndex int
LastIncludeTerm int
Offset int
Data []byte
Done bool
}
type InstallSnapshotResponse struct {
/*****moyoj-3D******/
Term int
}
func (rf *Raft) electStart(curterm int, lastLogIndex int, lastLogTerm int, me int, peerslen int) {
var sendWaitGroup sync.WaitGroup
voteCount := 1 //选票数
for i := 0; i < peerslen; i++ {
if i == me {
continue
}
sendWaitGroup.Add(1)
go func(serverid int) {
var request RequestVoteArgs
var response RequestVoteReply
request.CandidateId = me
request.Term = curterm
/*****moyoj-3B******/
request.LastLogIndex = lastLogIndex
request.LastLogTerm = lastLogTerm
ok := rf.sendRequestVote(serverid, &request, &response)
if ok {
rf.statusAccessMutex.Lock()
if rf.state == 2 && rf.currentTerm == curterm {
if response.VoteGranted {
voteCount += 1
if voteCount >= peerslen/2+1 {
rf.state = 1
rf.votedFor = -1
/*****moyoj-3C******/
rf.persist(rf.persister.ReadSnapshot())
/*****moyoj-3B******/
//重置next和match数组
for index := 0; index < len(rf.peers); index++ {
rf.nextIndex[index] = len(rf.logs) + rf.lastSnapshotIndex + 1
rf.matchIndex[index] = -1
}
go rf.sendHeartsbeats(curterm, rf.commitIndex, me, peerslen)
rf.heartsbeatsTimer.Reset(time.Duration(rf.heartsbeatsTime) * time.Millisecond)
}
} else if response.Term > rf.currentTerm {
rf.currentTerm = response.Term
rf.state = 0
rf.votedFor = -1 //!!!!!选举失败,置成未投票状态
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
/*****moyoj-3C******/
rf.persist(rf.persister.ReadSnapshot())
}
}
rf.statusAccessMutex.Unlock()
}
sendWaitGroup.Done()
}(i)
}
sendWaitGroup.Wait()
rf.statusAccessMutex.Lock()
if rf.state == 2 && rf.currentTerm == curterm {
rf.state = 0
rf.votedFor = -1 //!!!选举失败变为-1
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
/*****moyoj-3C******/
rf.persist(rf.persister.ReadSnapshot())
}
rf.statusAccessMutex.Unlock()
}
func (rf *Raft) sendHeartsbeats(curterm int, leaderCommit int, me int, peerslen int) {
for i := 0; i < peerslen; i++ {
if i == me {
continue
}
go func(serverid int) {
rf.statusAccessMutex.Lock()
if rf.currentTerm != curterm {
rf.statusAccessMutex.Unlock()
return
}
nextIndex := rf.nextIndex[serverid]
//说明要发送的日志已经形成快照,follower远远落后,直接发送installsnapshotrpc了,这也是为什么论文指出installsnapshotrpc当成一次心跳的原因,就是在发送追加日志(心跳)的途中发现没法追加时才发送installSnapshot rpc
if nextIndex <= rf.lastSnapshotIndex {
//发送快照
var request InstallSnapshotRequest
var response InstallSnapshotResponse
curLastSnapshotIndex := rf.lastSnapshotIndex
request.Data = rf.persister.ReadSnapshot()
request.LastIncludeIndex = curLastSnapshotIndex
request.LeaderId = me
request.Term = curterm
rf.statusAccessMutex.Unlock()
ok := rf.peers[serverid].Call("Raft.InstallSnapshot", &request, &response)
if ok {
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
if rf.currentTerm == curterm {
if response.Term > rf.currentTerm {
rf.currentTerm = response.Term
rf.state = 0
rf.votedFor = -1
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
/*****moyoj-3C******/
rf.persist(rf.persister.ReadSnapshot())
return
}
if rf.nextIndex[serverid] == nextIndex {
rf.nextIndex[serverid] = curLastSnapshotIndex + 1
}
rf.matchIndex[serverid] = rf.nextIndex[serverid] - 1
//更新commitindex
rf.updateNextMatch(me)
}
}
} else {
var request AppendEntriesRequest
var response AppendEntriesResponse
request.Entries = []logEntry{}
request.LeaderId = me
request.Term = curterm
request.LeaderCommit = leaderCommit
/*****moyoj-3B******/
request.PreLogIndex = -1
request.PreLogTerm = -1
//一次性发送没发送的日志
request.Entries = rf.logs[nextIndex-rf.lastSnapshotIndex-1 : len(rf.logs)]
request.PreLogIndex = nextIndex - 1
if (nextIndex - rf.lastSnapshotIndex - 1 - 1) >= 0 {
request.PreLogTerm = rf.logs[nextIndex-rf.lastSnapshotIndex-1-1].Term
} else {
request.PreLogTerm = rf.lastSnapshotTerm
}
rf.statusAccessMutex.Unlock()
ok := rf.peers[serverid].Call("Raft.AppendEntries", &request, &response)
if ok {
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
if rf.currentTerm == curterm {
if !response.Success {
if rf.currentTerm < response.Term {
rf.currentTerm = response.Term
rf.state = 0
rf.votedFor = -1
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
/*****moyoj-3C******/
rf.persist(rf.persister.ReadSnapshot())
} else {
/*****moyoj-3B******/
//nextIndex后移
rf.nextIndex[serverid] = response.FastBack
}
}
if len(request.Entries) == 0 || !response.Success {
return
}
//成功发送日志追加
/*****moyoj-3B******/
if nextIndex == rf.nextIndex[serverid] { //nextIndex没有变更,还是和当时发送消息时一样
rf.nextIndex[serverid] = nextIndex + len(request.Entries)
}
rf.matchIndex[serverid] = rf.nextIndex[serverid] - 1
//这里更新一下commitIndex
rf.updateNextMatch(me)
}
}
}
}(i)
}
}
/*****moyoj-3B******/
//追加日志是否匹配
func (rf *Raft) matchNewEntries(Entries []logEntry, preLogIndex int, preLogTerm int, response *AppendEntriesResponse) bool {
if preLogIndex != -1 && len(rf.logs) <= preLogIndex-rf.lastSnapshotIndex-1 { //该节点的所有日志中没有下标为preLogIndex的项
response.Success = false
response.FastBack = len(rf.logs) + rf.lastSnapshotIndex + 1
return false
}
//preLogIndex >= rf.lastSnapshotIndex,如果是相等,则一定能把term匹配上,则不需要让leader回退nextIndex
if preLogIndex != -1 && preLogIndex != rf.lastSnapshotIndex && rf.logs[preLogIndex-rf.lastSnapshotIndex-1].Term != preLogTerm {
//同下标的日志项的term与新日志的term不匹配
response.FastBack = rf.commitIndex + 1 //让leader的nextIndex直接跳到当前节点的commitIndex+1处
response.Success = false
return false
}
response.Success = true
rf.logs = rf.logs[0 : preLogIndex-rf.lastSnapshotIndex-1+1]
rf.logs = append(rf.logs, Entries...)
return true
}
/*****moyoj-3B******/
func (rf *Raft) applyEntries(sleep int) {
for !rf.killed() {
time.Sleep(time.Duration(sleep) * time.Millisecond)
rf.statusAccessMutex.Lock()
appliedIndex := rf.lastApplied
commitIndex := rf.commitIndex
logs := make([]logEntry, len(rf.logs))
lastSnapshotIndex := rf.lastSnapshotIndex
copy(logs, rf.logs)
rf.statusAccessMutex.Unlock()
//向上层提交的过程可以先释放锁
for ; appliedIndex < commitIndex; appliedIndex++ {
var sendApply ApplyMsg
sendApply.Command = logs[appliedIndex-lastSnapshotIndex-1+1].Command
sendApply.CommandIndex = appliedIndex + 2
sendApply.CommandValid = true
rf.applyChan <- sendApply
}
rf.statusAccessMutex.Lock()
if rf.lastApplied < commitIndex { //有可能在apply的过程中,rf.lastApplied被installSnapshot函数改变的更大了,防止lastApplied回退
rf.lastApplied = commitIndex
}
rf.statusAccessMutex.Unlock()
}
}
/*****moyoj-3D******/
func (rf *Raft) updateNextMatch(me int) {
for maxMatchIndex := rf.commitIndex + 1; maxMatchIndex-rf.lastSnapshotIndex-1 < len(rf.logs); maxMatchIndex++ {
if rf.logs[maxMatchIndex-rf.lastSnapshotIndex-1].Term != rf.currentTerm { //不对旧term的日志进行提交,通过对当前term的日志提交顺便提交旧term的日志 continue
continue
}
//统计该该位置日志在对端的复制情况
count := 1
for peersIndex := 0; peersIndex < len(rf.peers); peersIndex++ {
if peersIndex == me {
continue
}
if maxMatchIndex <= rf.matchIndex[peersIndex] {
count++
}
}
//对于该下标日志的复制情况,自身加上对端超过了一半更新commit
if count >= len(rf.peers)/2+1 {
rf.commitIndex = maxMatchIndex
}
}
}
// 心跳或者追加日志条目的处理函数,由别的节点调用后,该函数处理(会有多个该函数同时执行)
func (rf *Raft) AppendEntries(request *AppendEntriesRequest, response *AppendEntriesResponse) {
/*****moyoj-3A******/
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
if request.Term < rf.currentTerm {
response.Success = false
response.Term = rf.currentTerm
return
}
/*****moyoj-3B******/
response.Success = true
if rf.matchNewEntries(request.Entries, request.PreLogIndex, request.PreLogTerm, response) {
//只有成功匹配上leader的日志,才能更新commitIndex
if request.LeaderCommit > rf.commitIndex {
if len(rf.logs)-1 < request.LeaderCommit-rf.lastSnapshotIndex-1 {
rf.commitIndex = len(rf.logs) + rf.lastSnapshotIndex + 1 - 1
} else {
rf.commitIndex = request.LeaderCommit
}
}
}
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
rf.currentTerm = request.Term
rf.state = 0
rf.leaderId = request.LeaderId
response.Term = request.Term
/*****moyoj-3C******/
rf.persist(rf.persister.ReadSnapshot())
}
// example RequestVote RPC handler.
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (3A, 3B).
/*****moyoj-3A******/
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
if args.Term < rf.currentTerm {
reply.VoteGranted = false
reply.Term = rf.currentTerm
return
}
if args.Term == rf.currentTerm {
if rf.state == 1 || rf.votedFor != -1 {
reply.VoteGranted = false
reply.Term = rf.currentTerm
return
}
}
/*****moyoj-3B******/
/**主要是为了确保日志复制的安全,确保新的领导人不会用自己较为旧的日志覆盖掉已经提交的日志
1.领导人只能对自己任期内的日志commit,不会对旧任期的日志进行提交(如果提交旧的日志就会碰到论文5.4.2的情况),新
领导人对自己任期内新日志提交会顺带把旧的提交。这里所谓的提交其实就是领导人更新commitIndex!非常重要!!
2.候选人日志记录必须不旧于(大于或者等于)大部分节点的日志记录,何为较新?
最后一条日志term更大的日志记录更新 或者 最后一条日志term相等但是日志记录数目多的更新
以上两点共同确保了安全性
*/
reply.VoteGranted = true
if len(rf.logs) != 0 && rf.logs[len(rf.logs)-1].Term > args.LastLogTerm {
reply.VoteGranted = false
}
//请求的日志数目较少
if len(rf.logs) != 0 && rf.logs[len(rf.logs)-1].Term == args.LastLogTerm && args.LastLogIndex < len(rf.logs)+rf.lastSnapshotIndex+1-1 {
reply.VoteGranted = false
}
/*****moyoj-3D******/
if rf.lastSnapshotIndex != -1 && rf.lastSnapshotTerm > args.LastLogTerm {
reply.VoteGranted = false
}
if rf.lastSnapshotIndex != -1 && rf.lastSnapshotTerm == args.LastLogTerm && args.LastLogIndex < rf.lastSnapshotIndex {
reply.VoteGranted = false
}
if reply.VoteGranted {
//更新leaderid和term
rf.votedFor = args.CandidateId //投票候选人
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
}
rf.currentTerm = args.Term
rf.state = 0
reply.Term = args.Term
/*****moyoj-3C******/
rf.persist(rf.persister.ReadSnapshot())
}
func (rf *Raft) InstallSnapshot(request *InstallSnapshotRequest, response *InstallSnapshotResponse) {
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
if request.Term < rf.currentTerm {
response.Term = rf.currentTerm
return
}
curindex := request.LastIncludeIndex - rf.lastSnapshotIndex - 1
if curindex < 0 {
response.Term = rf.currentTerm
return
}
if curindex < len(rf.logs) {
if rf.logs[curindex].Term != request.Term {
rf.logs = make([]logEntry, 0)
} else {
logs := rf.logs[curindex+1:]
rf.logs = make([]logEntry, len(rf.logs)-curindex-1)
copy(rf.logs, logs)
}
} else {
rf.logs = make([]logEntry, 0)
}
rf.lastSnapshotIndex = request.LastIncludeIndex
rf.lastSnapshotTerm = request.LastIncludeTerm
rf.lastApplied = request.LastIncludeIndex
rf.commitIndex = request.LastIncludeIndex
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
rf.currentTerm = request.Term
rf.state = 0
rf.leaderId = request.LeaderId
response.Term = request.Term
rf.persist(request.Data)
go func() {
var sendApply ApplyMsg
sendApply.CommandValid = false
sendApply.Snapshot = request.Data
sendApply.SnapshotIndex = rf.lastSnapshotIndex + 1
sendApply.SnapshotTerm = rf.lastSnapshotTerm
sendApply.SnapshotValid = true
rf.applyChan <- sendApply
}()
}
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool {
ok := rf.peers[server].Call("Raft.RequestVote", args, reply)
return ok
}
func (rf *Raft) Start(command interface{}) (int, int, bool) {
index := -1
term := -1
isLeader := true
// Your code here (3B).
rf.statusAccessMutex.Lock()
defer rf.statusAccessMutex.Unlock()
if rf.state != 1 {
isLeader = false
} else {
rf.logs = append(rf.logs, logEntry{command, rf.currentTerm})
index = len(rf.logs) + rf.lastSnapshotIndex + 1
term = rf.currentTerm
/*****moyoj-3C******/
rf.persist(rf.persister.ReadSnapshot())
}
return index, term, isLeader
}
func (rf *Raft) Kill() {
atomic.StoreInt32(&rf.dead, 1)
// Your code here, if desired.
}
func (rf *Raft) killed() bool {
z := atomic.LoadInt32(&rf.dead)
return z == 1
}
func (rf *Raft) ticker() {
for rf.killed() == false {
select {
case <-rf.electionTimer.C:
rf.statusAccessMutex.Lock()
if rf.state == 0 || rf.state == 2 {
rf.state = 2
rf.votedFor = rf.me
rf.currentTerm += 1
/*****moyoj-3C******/
rf.persist(rf.persister.ReadSnapshot())
/*****moyoj-3B******/
lastLogIndex := -1
lastLogTerm := -1
if len(rf.logs) != 0 || rf.lastSnapshotIndex != -1 {
if len(rf.logs) != 0 {
lastLogIndex = len(rf.logs) + rf.lastSnapshotIndex + 1 - 1
lastLogTerm = rf.logs[len(rf.logs)-1].Term
} else {
lastLogIndex = rf.lastSnapshotIndex
lastLogTerm = rf.lastSnapshotTerm
}
}
go rf.electStart(rf.currentTerm, lastLogIndex, lastLogTerm, rf.me, len(rf.peers))
rf.electionTimer.Reset(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
}
rf.statusAccessMutex.Unlock()
case <-rf.heartsbeatsTimer.C:
rf.statusAccessMutex.Lock()
if rf.state == 1 {
go rf.sendHeartsbeats(rf.currentTerm, rf.commitIndex, rf.me, len(rf.peers))
rf.heartsbeatsTimer.Reset(time.Duration(rf.heartsbeatsTime) * time.Millisecond)
}
rf.statusAccessMutex.Unlock()
}
}
}
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{}
rf.peers = peers
rf.persister = persister
rf.me = me //可以作为唯一标识符
// Your initialization code here (3A, 3B, 3C).
/*****moyoj-3A******/
rf.currentTerm = 0
rf.votedFor = -1
rf.state = 0
rf.logs = []logEntry{}
rf.heartsbeatsTime = 110
rf.electionTimeout = 1000
rf.electionTimer = time.NewTimer(time.Duration(rf.electionTimeout+rand.Intn(rf.electionTimeout)) * time.Millisecond)
rf.heartsbeatsTimer = time.NewTimer(time.Duration(rf.heartsbeatsTime) * time.Millisecond)
/*****moyoj-3B******/
rf.commitIndex = -1
rf.lastApplied = -1
rf.nextIndex = make([]int, len(rf.peers))
rf.matchIndex = make([]int, len(rf.peers))
rf.applyChan = applyCh
go rf.applyEntries(10) //20msapply一次日志
/*****moyoj-3D******/
rf.lastSnapshotIndex = -1
rf.lastSnapshotTerm = -1
// initialize from state persisted before a crash
rf.readPersist(persister.ReadRaftState())
// start ticker goroutine to start elections
go rf.ticker()
return rf
}
其他
2025-4-16 :在做Lab4的时候发现了Lab3的代码一些没检测到的bug。
主要分为两个bug:1.日志在不同节点同步和commit的速度太慢。2.服务层丢失操作,也就是会丢失日志,没法达到线性一致性。
为了防止混乱,修改的代码放在Lab4。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号