11-word2vec
当我们分析图片或者语音的时候,通常都是在密集高纬度数据。我们所需的全部信息都储存在原始数据中。

当我们做自然语言处理的时候,我们通常会分词,然后给每一个词一个编号,比如猫的编号是120,狗的编号是343。比如女生的编号是2329.这些编号没有规律,没有联系,我们从编号中不能得到词语词的相关性。
例如:How are you?
How : 234
Are : 7 you : 987
如果转化为one-hot:
000…1000000…
00000001000…
000…0000010
连续词袋模型(CBOW)
根据词的上下文词汇来预测目标词汇,例如上下文词汇是“今天早餐吃 ”,要预测的目标词汇可能 是“面包”
Skip-Gram模型
Skip-Gram模型刚好和CBOW相反,它是通过目标词汇来预测上下文词汇。例如目标词汇是“早餐”,上下文词汇可能是“今天”和“吃面包”。
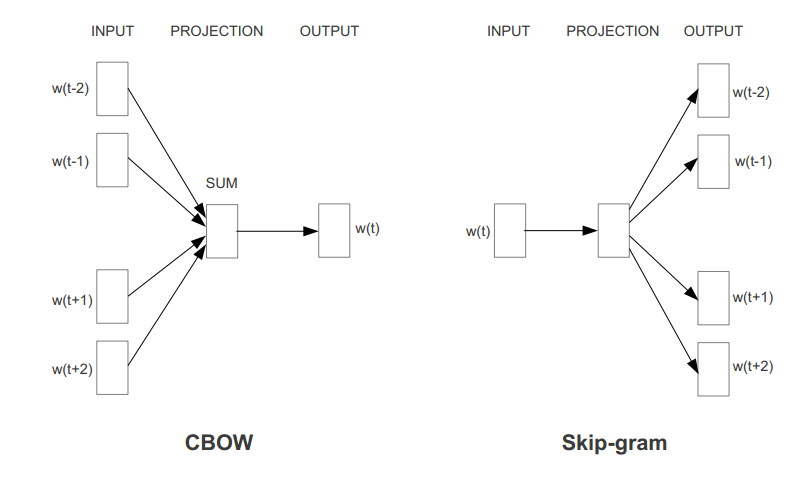
对于这两种模型的训练,我们可能容易想到,使用softmax作为输出层来训练网络。
这个方法是可 行的,只不过使用softmax作为输出层计算量将会是巨大的。
假如我们已知上下文,需要训练模型 预测目标词汇,假设总共有50000个词汇,
那么每一次训练都需要计算输出层的50000个概率值。
所以训练Word2vec模型我们通常可以选择使用噪声对比估计(Noise Contrastive Estimation)
。NCE使用的方法是把上下文h对应地正确的目标词汇标记为正样本(D=1),然后再抽取一些错
误的词汇作为负样本(D=0)。然后最大化目标函数的值。

当真实的目标单词被分配到较高的概率,同时噪声单词的概率很低时,目标函数也就达到最大值了。
计算这个函数时,只需要计算挑选出来的k个噪声单词,而不是整个语料库。所以训练速度会很快。
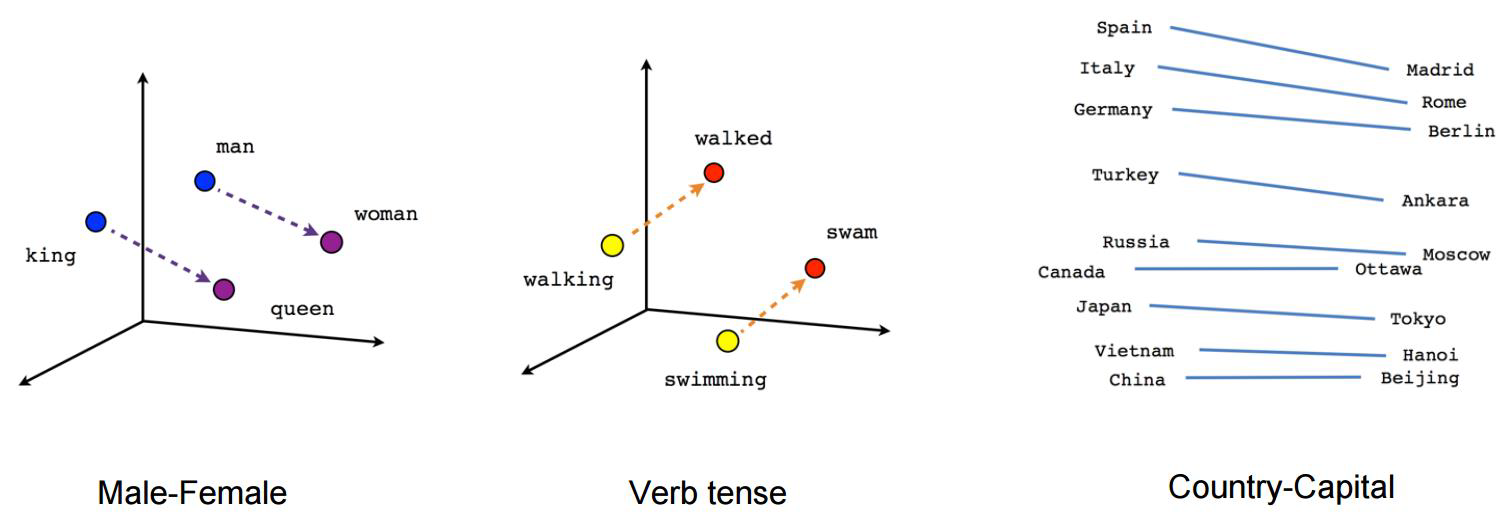
训练完成后,可以看到词性比较相近的词,在空间中内积应该很大
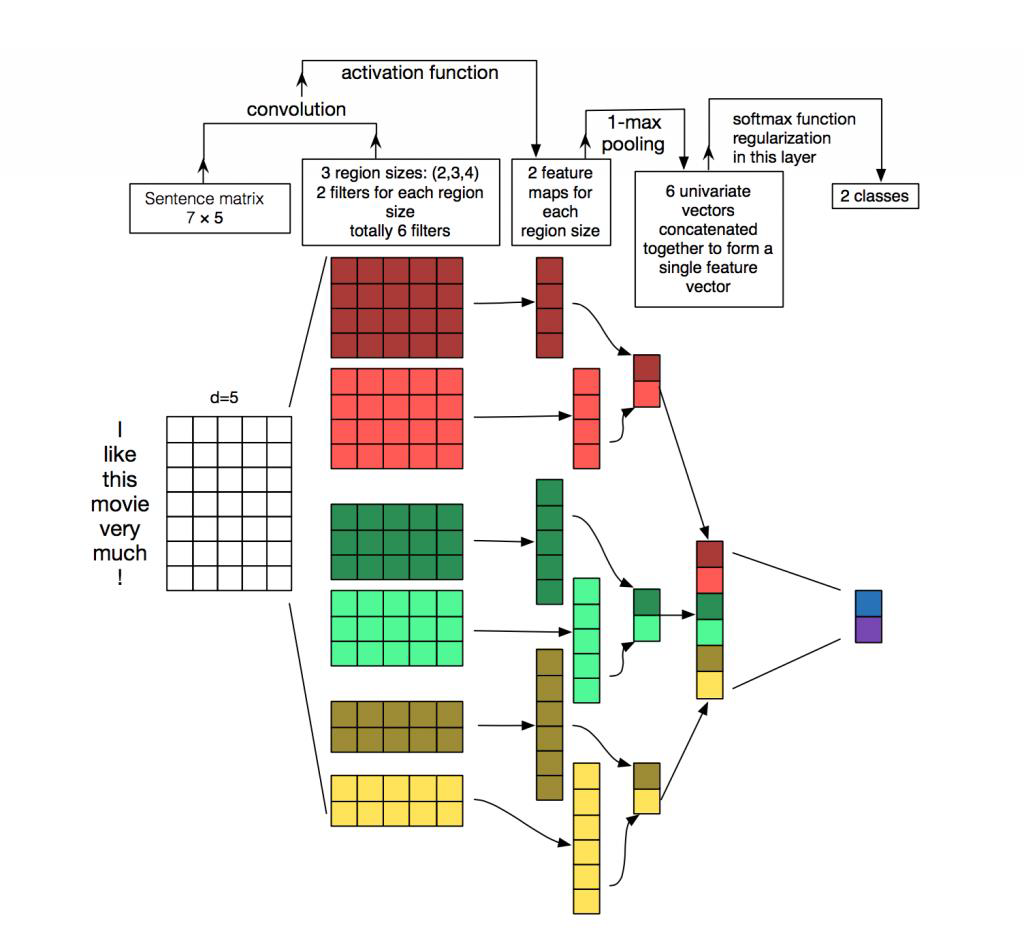
CNN在自然语言处理的应用
CNN应用于NLP的任务,处理的往往是以矩阵形式表达的句子或文本。
矩阵中的每一行对应于一 个分词元素,一般是一个单词,也可以是一个字符。
也就是说每一行都是一个词或者字符的向量(比如前面说到的word2vec)。
假设我们一共有10个词,每个词都用128维的向量来表示,那么我们就可以得到一个10×128维的矩阵。
这个矩阵就相当于是一副“图像”。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号