爬虫入门笔记!
爬虫入门笔记!✨
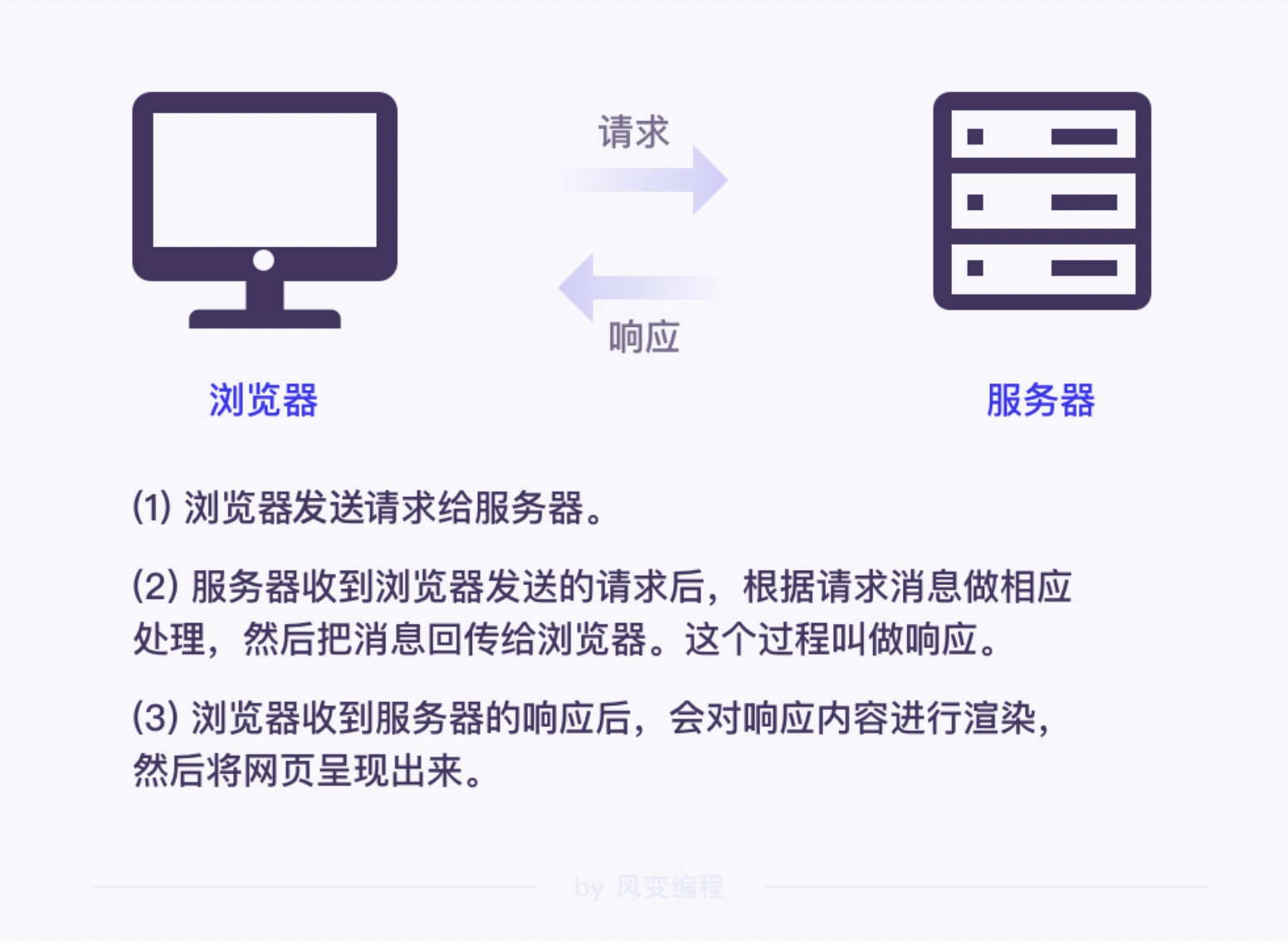
1.信息的请求与收集
网络爬虫指的是能够自动化访问网站的程序,其目的一般是提取和保存网页信息。
网络爬虫的一般流程:
-
获取网页
-
解析网页
-
存储数据
建议前置知识:python基础+html
2.获取网页
-
requests.get()函数
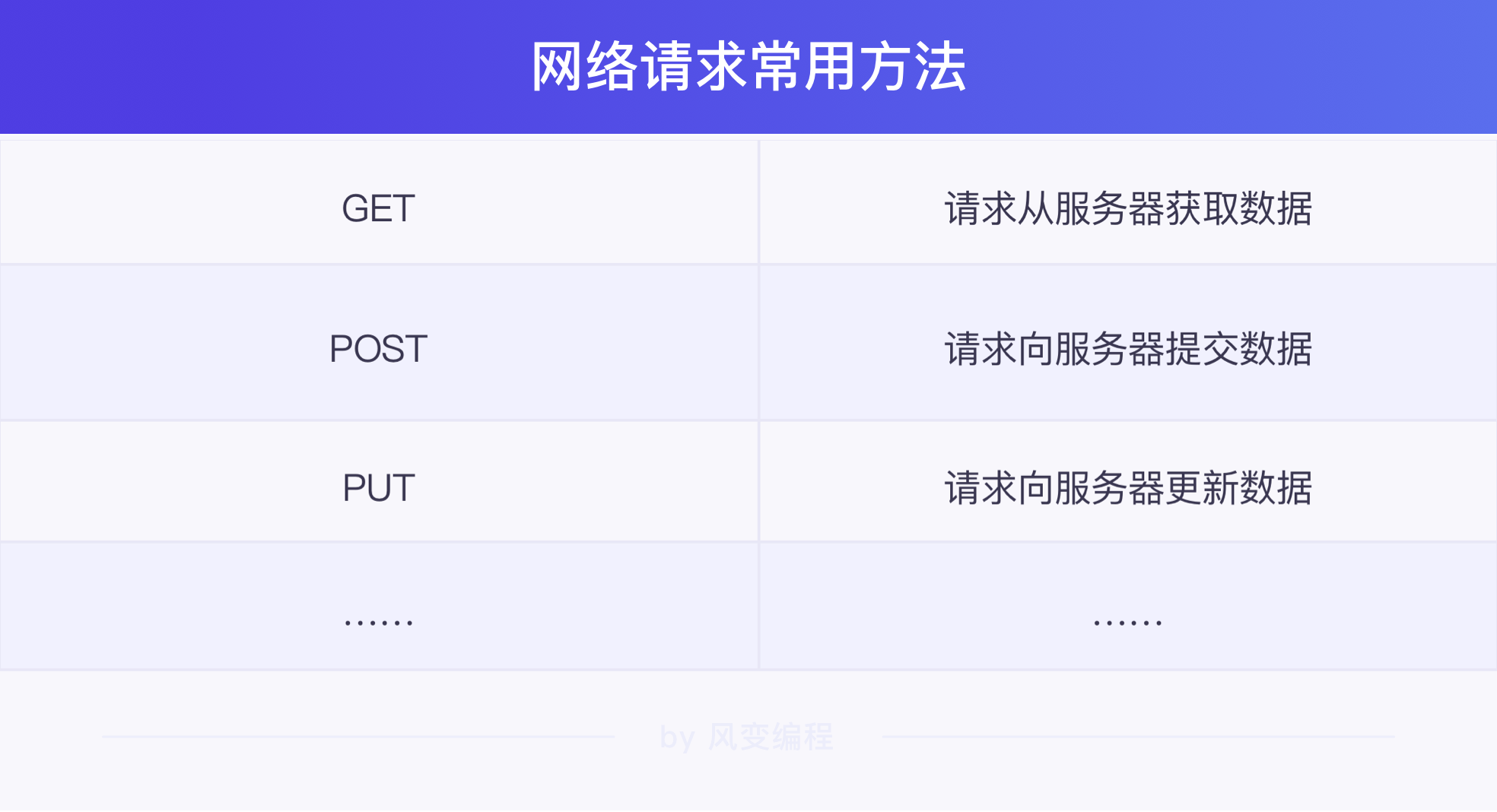
Requests 库内置了很多函数来帮我们实现各种方法的网络请求,像 requests.get()就是 Requests 库中用来发起 GET 请求的函数。
而get则是网络请求方法的一种。
-
URL(统一资源定位符)
包含协议、主机域名和路径

-
http与https的区别:
http 是一种从网络传输数据到本地浏览器的传送协议,我们一般也称它为 http 协议。一般来说网络请求可以被称作http请求。
而 https 协议会在 http 协议的基础上对数据进行加密处理,相对于 http 来说更加安全、可靠。
-
响应
requests.get() 函数返回结果是一个属于 requests.models.Response 类的对象。
Response 就是英文里响应的意思,Response 对象顾名思义,就是一个包含各种网络请求响应信息的对象。
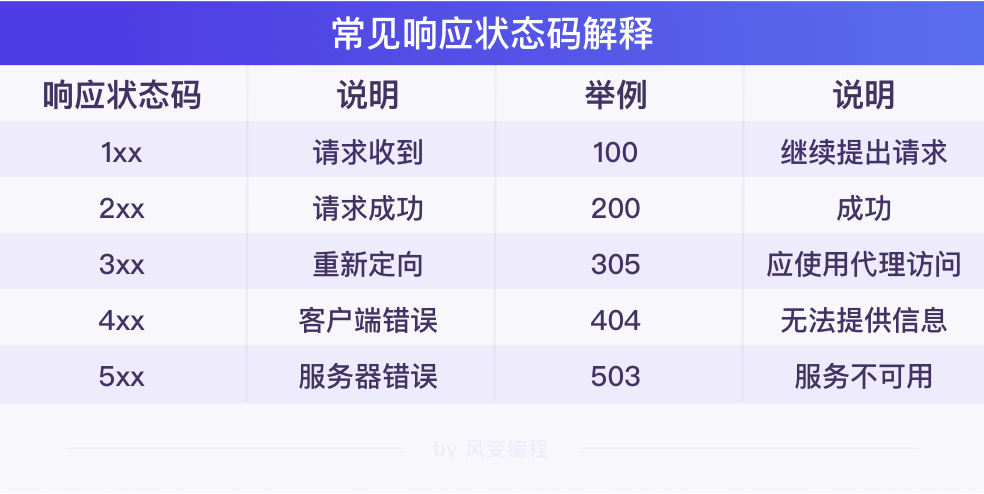
服务器返回给浏览器的内容,主要包含了响应状态码、响应头和响应体等信息。
-
response对象的status_code属性(状态码)
import requests # 发送请求,并把响应结果赋值在变量res上 res = requests.get('https://www.baidu.com/') # 打印Response对象的status_code属性,即状态码 print(res.status_code) #运行结果:200(请求成功) -
robots协议
想要查看某个网页的robots协议,只需要在网站的主机域名后加上/robots.txt即可
在 Robots 协议中,
User-agent代表的是爬虫身份。比如
User-agent: Baiduspider代表的就是百度的爬虫,User-agent: *代表的是未指定身份的所有爬虫,像我们就属于User-agent: *。Robots 协议对于不同的爬虫身份有着不一样的限制。
Disallow:声明了网站禁止百度爬虫爬取的内容。冒号后面代表限制爬虫的路径。Disallow:/表示禁止百度爬取https://wp.forchange.cn/下的所有内容。不过这些我们不用担心,禁止只是百度爬虫。我们只需要查看下面
User-agent: *的限制。首先我们看到一个跟百度爬虫一样的
Disallow: /,这里并不意味着我们对于网站的爬取受到了限制。因为往后看,我们还能看到一些
Allow的路径。例子:淘宝的robots协议的url为https://www.taobao.com/robots.txt
User-agent: Baiduspider Disallow: / User-agent: baiduspider Disallow: /虽然
Robots协议只是一个道德规范,和爬虫相关的法律也还在建立和完善之中,但我们在爬取网络信息时,应该有意识地去遵守这个协议。网站的服务器被频繁访问,也会受到较大的压力,因此,各大网站也会做一些反爬虫的措施。不过呢,有反爬虫,也就有相应的反反爬虫。
3.解析网页
解析数据需要使用bs4库。
bs4 库是一个可以方便地从 HTML 文档中提取数据的 Python 第三方库,通常也称为“Beautiful Soup库”,bs4的4表示版本。
解析 HTML 文档的工具是解析器。就像建筑图纸有一本使用说明书,如果说 HTML 文档是搭建网页的建筑图纸,那解析器就是 HTML 文档的使用说明书,这份说明书是给程序用的。
解析 HTML 文档的过程就是实例化 BeautifulSoup 类,得到 BeautifulSoup 对象的过程。
这个过程很简单:先导入 bs4 库中的 BeautifulSoup 类,然后实例化 BeautifulSoup 类。
用from…import…语句可以导入 bs4 库中的 BeautifulSoup 类。
from bs4 import BeautifulSoup

第 1 个参数可以是字符串格式的 HTML 文档,指示要解析的内容;第 2 个参数可以是解析器的名字,用来标识怎样解析文档。
第一个参数要注意一下,数据类型是字符串。我们获取网页得到的是包含 HTML 文档的 Response 对象,需要调用 Response 对象的 text 属性(即Response 对象.text),得到 HTML 文档的字符串形式。
第二个参数,要传入解析器的名字,也是字符串类型,我们用到的解析器是'html.parser'。
BeautifulSoup 也支持其他类型的解析器,不同的解析器有不同优缺点

我们可以使用以下的代码解析网页:
# 导入 requests 库
import requests
# 从 bs4 中导入 BeautifulSoup 类
from bs4 import BeautifulSoup
# 百度网页的 URL
url = 'https://www.baidu.com'
# 请求网页,并将结果赋值给变量 res
res = requests.get(url)
# 打印响应状态码,查看是否请求成功
print(res.status_code)
# 设置响应内容的编码格式
res.encoding = 'utf-8'
# 用 BeautifulSoup 和解析器'html.parser'解析请求到的网页
bs = BeautifulSoup(res.text,'html.parser')
# 打印查看解析结果
print(bs)
解析完网页之后,可以试着用BeautifulSoup 对象.元素名取任意节点。
如要取的有很多节点,则会取到第一个节点。
.元素名操作还有一个拓展用法:.元素名.元素名.……,BeautifulSoup 对象和 Tag 对象都可以这样操作。

-
find_all() 和 find() 方法
find_all()方法:搜索所有满足条件的 Tag 对象。
返回的结果是一个类似列表的可迭代对象,里面包含了所有满足参数条件的 Tag 对象。
可以从 BeautifulSoup 对象中找,也可以从 Tag 对象中找。
-
如果从 BeautifulSoup 对象中搜索,语法是:
BeautifulSoup 对象.find_all(); -
从 Tag 对象中搜索,语法是:
Tag 对象.find_all()。
-
find_all() 方法的参数就是需要满足的条件。我们主要用到两种参数:HTML 元素名和 HTML 元素属性。
-
html元素名
传入
HTML 元素名作为 find_all() 方法的参数,即可搜索所有元素名匹配的 Tag 对象。用元素名查找对应的 Tag 对象时,每次只能传入一个元素名,而且要以字符串的形式传入。
例如:
BeautifulSoup 对象.find_all('div'),可以获取 BeautifulSoup 对象中所有的<div>元素。下面代码中的html可以替换为实例化对象.text。(需要转编码为utf-8)
# 解析 HTML 文档 bs = BeautifulSoup(html, 'html.parser') # 用find_all()获取所有<div>节点 div_all = bs.find_all('div') -
html元素属性
传入 HTML 元素属性时,要用
参数名 = 参数值的形式,一次可以传入 0 到多个属性。参数名通常是元素的属性名,参数值就是对应的属性值。这里需要注意的是:HTML 的 class 属性与 Python 的保留关键字 class 重复。因此,作为参数使用 class 属性时,要加一个
_,写作class_,避免混淆。例如:
BeautifulSoup 对象.find_all(class_='poems')用来搜索 BeautifulSoup 对象中,所有拥有属性class='poems'的元素对应的 Tag 对象。下面代码中的html可以替换为实例化对象.text。(需要转编码为utf-8)
bs = BeautifulSoup(html, 'html.parser') # 用find_all()获取所有含属性class="poems"的HTML元素对应的节点 poems_all = bs.find_all(class_='poems')
由于 find_all() 返回的都是满足所有参数条件的 Tag 对象,因此,可以结合使用上述两种参数,更准确定位到 Tag 对象。同时使用 HTML 元素名和 HTML 元素属性作为搜索条件时,要把 HTML 元素名作为第 1 个参数,后面接 0 到多个 HTML 元素属性。
例如,想在 BeautifulSoup 对象中搜索所有元素名为div,并且拥有属性class="poems"的元素对应的 Tag 对象,语法应该是:BeautifulSoup 对象.find_all('div', class_='poems')。
需要注意的是,find_all() 返回的结果并不是 Tag 对象,而是 Tag 对象组成的一个类似列表的可迭代对象。要拿到其中的 Tag 对象,通常需要for 循环来帮忙。
find()方法:大部分和find_all()一样。唯一不同的是,find() 方法返回的结果是一个 Tag 对象,搜索范围内,满足参数条件的第一个 Tag 对象。这一点和元素名操作有点儿像。


- 我们还可以使用属性名脱去<>的外壳
h2_text = poem1_tag.find('h2').text
- 提取对应元素的元素属性
接下来看,提取对应元素的元素属性:
提取 Tag 对象对应元素的属性,和用字典的键获取值的方式很像,用方括号。
语法是:Tag 对象['属性名'],可用来提取对应元素的属性值。
import requests
from bs4 import BeautifulSoup
# 获取网页
# 《乌合之众》网页的 URL
url = 'https://wp.forchange.cn/psychology/11069/'
# 请求网页
res = requests.get(url)
# 打印响应的状态码
print(res.status_code)
# 将响应内容的编码格式设置为utf-8
res.encoding = 'utf-8'
# 解析网页
# 解析请求到的网页,得到 BeautifulSoup 对象
bs = BeautifulSoup(res.text, 'html.parser')
# 搜索书籍信息的父节点<div>
info_tag = bs.find('div', class_='res-attrs')
# 搜索每条信息的节点<dl>
info_list = info_tag.find_all('dl')
# 遍历搜索结果,在<dl>节点中继续提取
for info in info_list:
# 用.text提取信息提示项<dt>的元素内容
dt = info.find('dt').text
print(dt)
# 用.text提取书籍信息<dd>的元素内容
dd = info.find('dd').text
print(dd)
梳理一下从获取网页到提取数据的流程:


易错点:(二者不一样)
- 获取 Tag 对象对应的 HTML 元素的属性值的语句为
Tag 对象['属性名'] - 通过点号
.即BeautifulSoup对象.元素名语句来获取 Tag 对象
from bs4 import BeautifulSoup
html = '''
<h1>
<span property="v:itemreviewed">复仇者联盟4:终局之战 Avengers: Endgame</span>
<span class="year">(2019)</span>
</h1>
<span><span class="pl">导演</span>
':'
<span class="attrs">
<a href="/celebrity/1321812/" rel="v:directedBy">安东尼·罗素</a>
/
<a href="/celebrity/1320870/" rel="v:directedBy">乔·罗素</a>
</span>
</span>
<span><span class="pl">编剧</span>
':'
<span class="attrs">
<a href="/celebrity/1276125/">克里斯托弗·马库斯</a>
/
<a href="/celebrity/1276126/">斯蒂芬·麦克菲利</a>
/
<a href="/celebrity/1013888/">斯坦·李</a>
/
<a href="/celebrity/1050183/">杰克·科比</a>
/
<a href="/celebrity/1360715/">吉姆·斯特林</a>
</span>
</span>
<span class="actor">
<span class="pl">主演</span>
':'
<span class="attrs">
<span><a href="/celebrity/1016681/" rel="v:starring">小罗伯特·唐尼</a> / </span>
<span><a href="/celebrity/1017885/" rel="v:starring">克里斯·埃文斯</a> / </span>
<span><a href="/celebrity/1040505/" rel="v:starring">马克·鲁弗洛</a> / </span>
<span><a href="/celebrity/1021959/" rel="v:starring">克里斯·海姆斯沃斯</a> / </span>
<span><a href="/celebrity/1004568/" rel="v:starring">乔什·布洛林</a> / </span>
</span>
</span>
'''
bs = BeautifulSoup(html, 'html.parser')
movie_name = bs.find('span', property="v:itemreviewed").text
director = []
director_list = bs.find_all('a', rel="v:directedBy")
for i in director_list:
director.append(i.text)
actor = []
actor_list = bs.find_all('a', rel="v:starring")
for i in actor_list:
actor.append(i.text)
movie_dict = {'电影名':movie_name,'导演':director,'主演':actor}
print(movie_dict)
4. 存储数据
先来爬取书名:
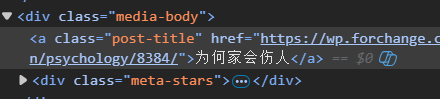
通过上图,我们发现通过<a>可以找到书名相关的连接,类名。
使用
bookname_list = bs.find_all('a', class_='post-title')
可以定位到
# 导入库 requests 以及类 BeautifulSoup
import requests
from bs4 import BeautifulSoup
# 设置网站书籍列表页第 1 页的链接
url = 'https://wp.forchange.cn/resources/page/1/'
# 请求网页
res = requests.get(url)
# 解析网页得到 BeautifulSoup 对象,赋给变量 pybs
bs = BeautifulSoup(res.text, 'html.parser')
# 搜索网页中所有包含书籍名和书籍链接的 Tag
bookname_list = bs.find_all('a', class_='post-title')
# 遍历搜索结果,提取并打印书籍名和书籍链接
for bookname in bookname_list:
# 使用 Tag.text 属性提取书籍名,并打印书籍名
print(bookname.text)
# 使用 Tag['属性名'] 提取书籍链接,并打印书籍链接
print(bookname['href'])
接下来进入存储环节。先复习一下csv。

在存储上会更倾向于使用 csv 模块的 DictWriter()。
调用 csv 模块中类 DictWriter 的语法为:csv.DictWriter(f, fieldnames),执行后会得到一个 DictWriter 对象。语法中的参数 f 是 open() 函数打开的文件对象;参数 fieldnames 用来设置文件的表头。
得到的 DictWriter 对象可以调用 writeheader() 方法,将 fieldnames 写入 csv 的第一行。
再调用 writerows() 方法将多个字典写进 csv 文件中。
5.带headers请求
headers即为请求头,目的是获得网页的访问许可。
eg:如果直接用requests来访问会返回418status_code的网站,比如豆瓣。
网络请求会将浏览器信息储存在请求头(Request Header)当中。
只要我们将浏览器信息复制下来,在爬虫程序只要在发起请求时,设置好与请求头对应的参数,即可成功伪装成浏览器。
我们打开豆瓣后台的网络界面,按Ctrl+R,会出现以下界面。

一定记住要勾选保存日志:
数据上面有状态栏(edge已经翻译为中文,下图为英文)


我们重点找的是最先出现的document格式的文件,这一般就是我们看到的网页界面。
当然,也可以通过筛选功能选择Doc格式的文件,这样在网页加载信息太多时,可以查找更加方便。
继续,点击这个document文件的name,再点击它的preview选项卡,查看是否含有我们想要爬取的信息。
通过观察可以判断我们找对了文件,再切换到Headers选项卡。
暂时先忽略其他信息,重点看Request Headers。
这代表着"请求头",也就是浏览器证明自己身份的信息。
在请求标头中找到最下方的User_Agent
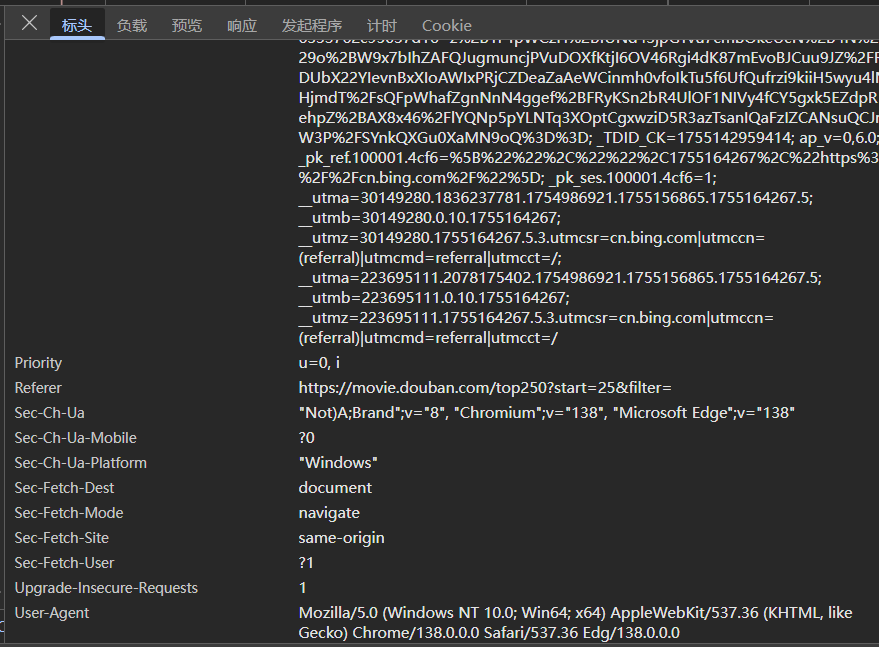
在Request Headers中,除了User-Agent,还有Accept、Host、Cookie 等信息。

将网页中Request Headers里的信息用一个字典保存起来,然后再将这个字典传递给 get() 函数里的headers参数,就可以让 get() 函数伪装成“小红帽”的样子去拜访“外婆”。
我们查询到headers的内容如下:

如下,使用headers再次请求访问。输出为200状态码,请求成功。
import requests
# 设置要请求的网页链接
url = 'https://movie.douban.com/top250?start=0&filter='
# 设置请求头
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0'
}
# 请求网页
res = requests.get(url, headers=headers)
# 打印网页状态码
print(res.status_code)
总结:
1)熟练地使用开发者工具的指针工具,可以很方便地帮助我们定位数据。
2)用指针工具定位到各个数据所在位置后,查看它们的规律。
3)想要提取的标签如果具有属性,可以使用 Tag.find(HTML元素名, HTML属性名='')来提取;没有属性的话,可以在这个标签附近找到一个有属性的标签,然后再进行 find() 提取。
通过上述步骤将信息爬取下来后,就走到我们爬虫的最后一步——存储数据。

6.模拟登录、爬取评论
之前的网络请求使用requests,现在我们使用post来完成。之所以不用get,是因为get会在网页链接中显示。

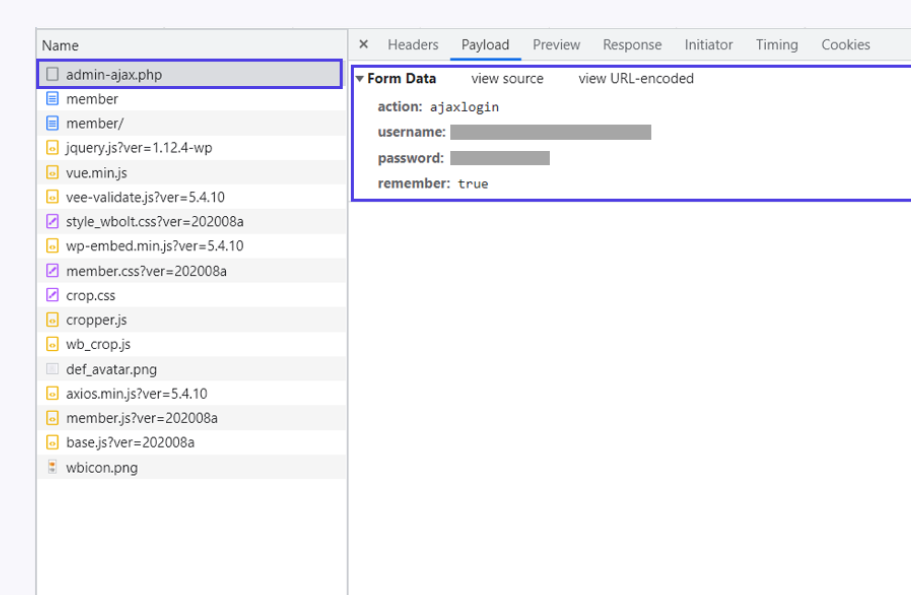
这里的登录请求我们看到是POST。
一般来说,请求可以分为四部分内容:请求网址、请求方法、请求头和请求体。
我们可以在负载中找到自己的登录信息。
POST()函数

url:传入的请求网址
data:传入的请求体,即我们上面在请求详情页的【Form Data】中看到的所有信息。这些信息在 Python 中可以以字典的形式来存储:
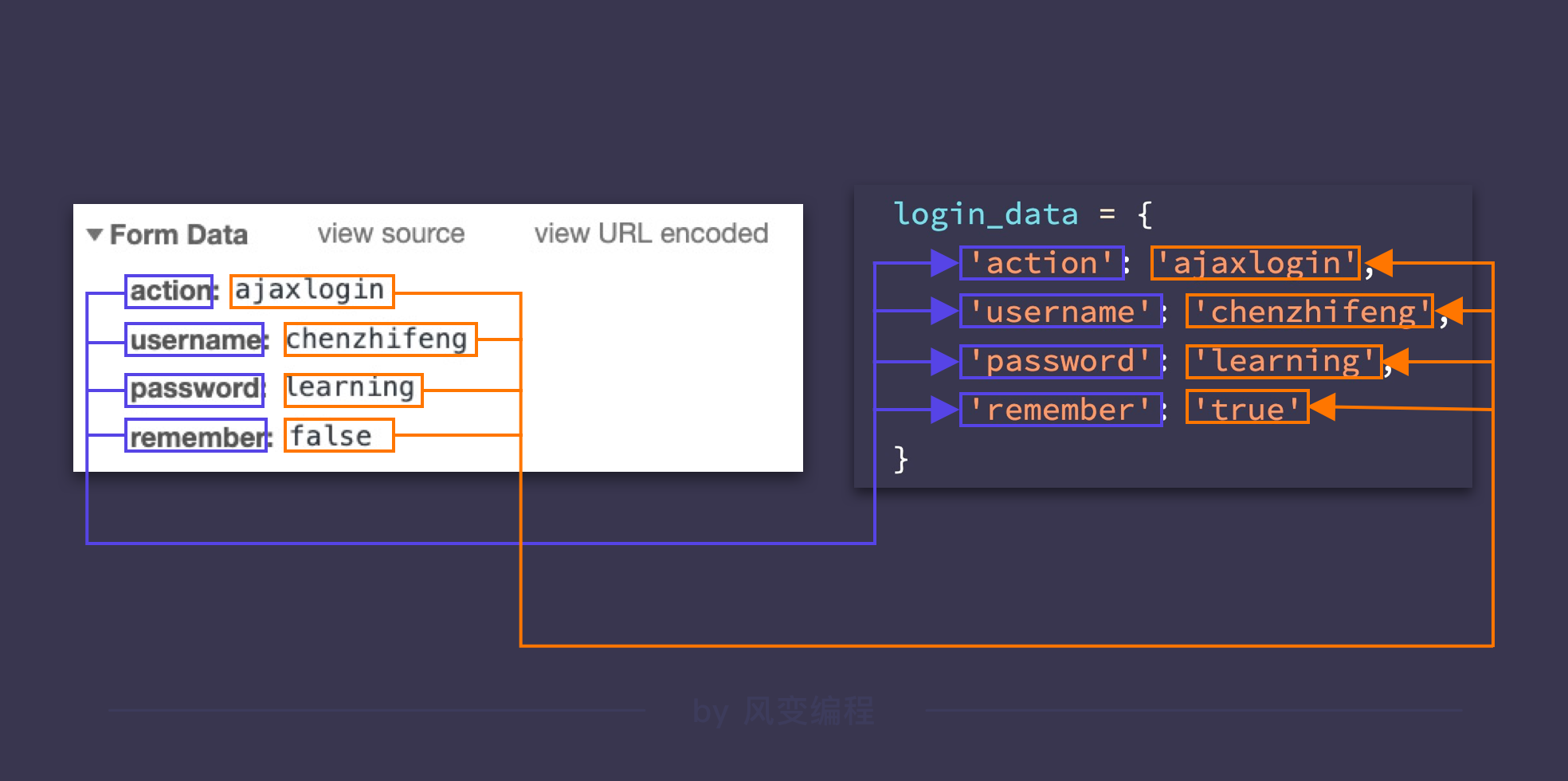
import requests
# 设置登录请求的请求网址
login_url = 'https://wp.forchange.cn/wp-admin/admin-ajax.php'
# 输入用户的账号密码
username = input('请输入用户名:')
password = input('请输入密码:')
# 设置登录请求的请求体数据
login_data = {
'action': 'ajaxlogin',
'username': username,
'password': password,
'remember': 'true'
}
# 请求登录网站
login_res = requests.post(login_url, data=login_data)
print(login_res.text)
cookies
Cookies 是网站为了辨别用户身份,进行会话跟踪而存储在用户本地的数据,由用户客户端计算机暂时或永久保存的信息。
首次登陆网站成功后,服务器会将 Cookies 信息返回给浏览器,浏览器将 Cookies 信息保存下来。
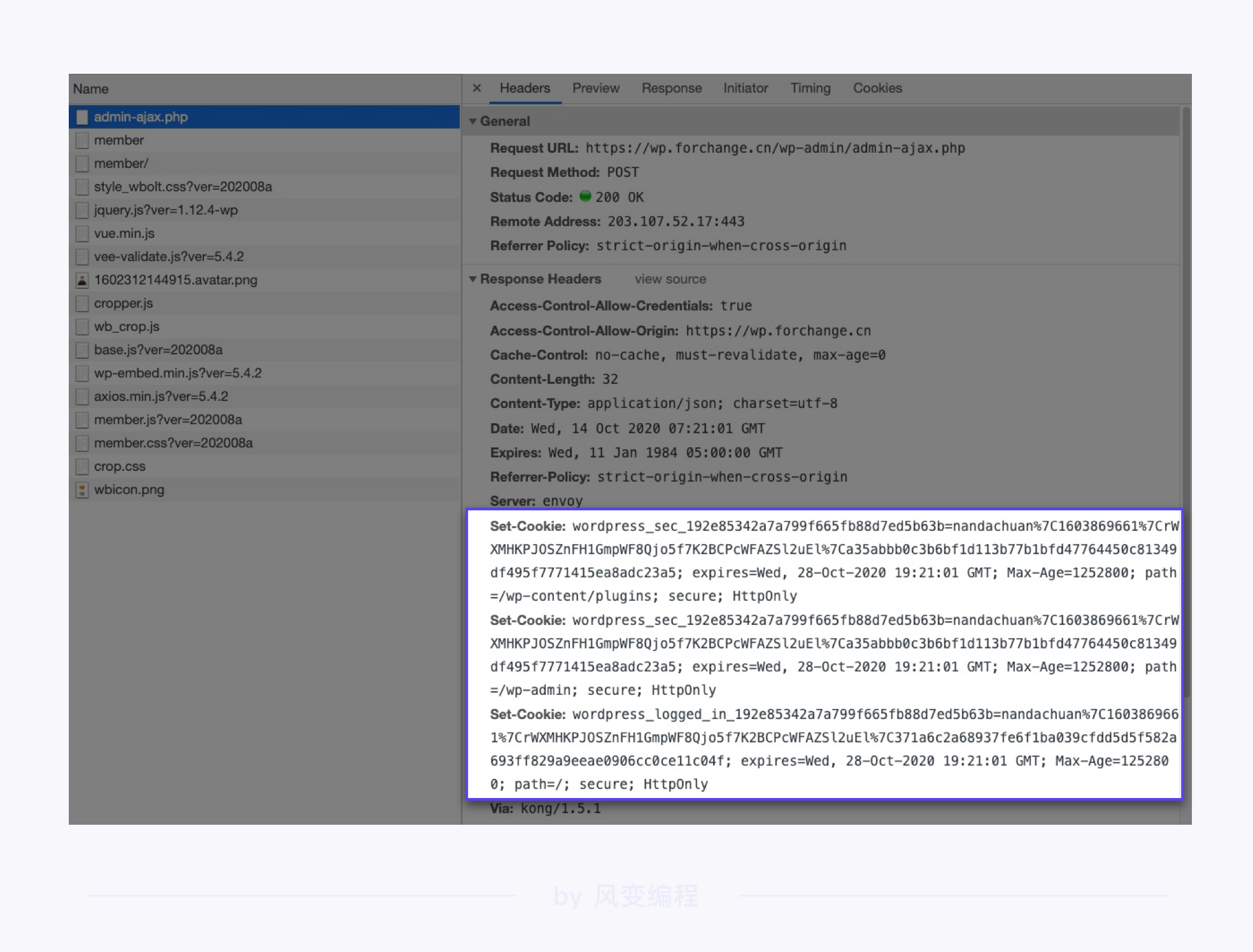
Cookies 里含有登录相关的信息,下次浏览器请求该网站的网页时,浏览器会将 Cookies 发送给服务器,服务器通过识别 Cookies 来判断发送请求的用户是否已登录。
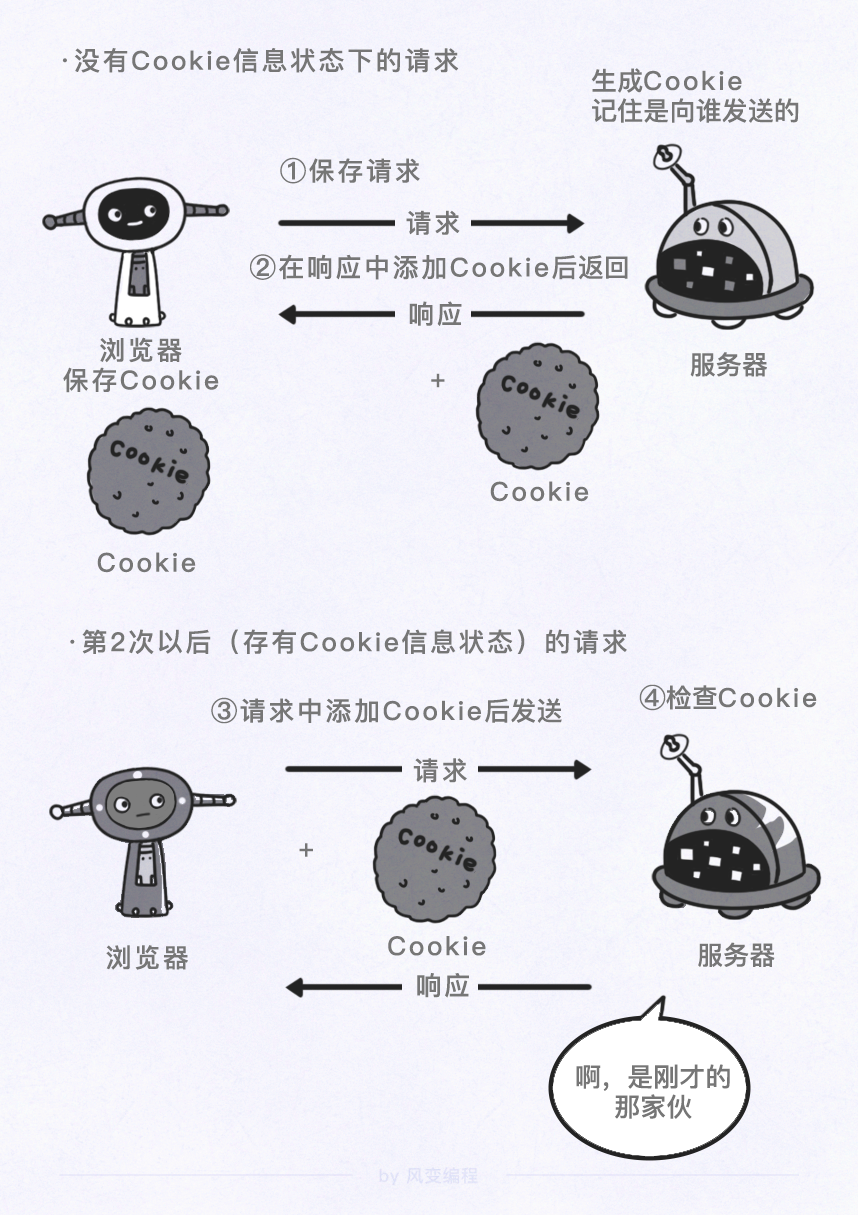
怎么才能拿到服务器返回的 Cookies 信息呢?
我们只需要在“登录网站”的代码末尾,使用 post() 函数返回的 Response 对象,去调用它的 cookies 属性即可。(调用 cookies 属性时,注意开头的 c 为小写)
import requests
# 设置登录请求的请求网址
login_url = 'https://wp.forchange.cn/wp-admin/admin-ajax.php'
# 输入用户的账号密码
username = input('请输入用户名:')
password = input('请输入密码:')
# 设置登录请求的请求体数据
login_data = {
'action': 'ajaxlogin',
'username': username,
'password': password,
'remember': 'true'
}
# 请求登录网站
login_res = requests.post(login_url, data=login_data)
# 循环遍历获取到的 Cookies 信息
for cookie in login_res.cookies:
# 打印 Cookies 信息
print(cookie)
import requests
# 设置登录请求的请求网址
login_url = 'https://wp.forchange.cn/wp-admin/admin-ajax.php'
# 输入用户的账号密码
username = input('请输入用户名:')
password = input('请输入密码:')
# 设置登录请求的请求体数据
login_data = {
'action': 'ajaxlogin',
'username': username,
'password': password,
'remember': 'true'
}
# 请求登录网站
login_res = requests.post(login_url, data=login_data)
# 设置要请求的书籍评论页链接
comment_url = 'https://wp.forchange.cn/psychology/11069/comment-page-1/'
# 携带获取到的 Cookies 信息请求书籍评论页
comment_res = requests.get(comment_url, cookies=login_res.cookies)
# 打印获取到的网页内容
print(comment_res.text)
import requests
from bs4 import BeautifulSoup
# 设置登录请求的请求网址
login_url = 'https://wp.forchange.cn/wp-admin/admin-ajax.php'
# 输入用户的账号密码
username = input('请输入用户名:')
password = input('请输入密码:')
# 设置登录请求的请求体数据
login_data = {
'action': 'ajaxlogin',
'username': username,
'password': password,
'remember': 'true'
}
# 请求登录网站
login_res = requests.post(login_url, data=login_data)
# 设置要请求的书籍评论页链接
comment_url = 'https://wp.forchange.cn/psychology/11069/comment-page-1/'
# 携带获取到的 Cookies 信息请求书籍网页
comment_res = requests.get(comment_url, cookies=login_res.cookies)
# 解析请求到的书籍网页内容
soup = BeautifulSoup(comment_res.text, 'html.parser')
# 搜索网页中所有包含评论的 Tag
comments_list = soup.find_all('div', class_='comment-txt')
# 使用 for 循环遍历搜索结果
for comment in comments_list:
# 提取用户名
coment_name = comment.find('cite',class_='fn')
# 打印用户名
print(coment_name.text[:-2])
爬取评论的用户名:
import requests
from bs4 import BeautifulSoup
# 设置登录请求的请求网址
login_url = 'https://wp.forchange.cn/wp-admin/admin-ajax.php'
# 输入用户的账号密码
username = input('请输入用户名:')
password = input('请输入密码:')
# 设置登录请求的请求体数据
login_data = {
'action': 'ajaxlogin',
'username': username,
'password': password,
'remember': 'true'
}
# 请求登录网站
login_res = requests.post(login_url, data=login_data)
# 设置要请求的书籍评论页链接
comment_url = 'https://wp.forchange.cn/psychology/11069/comment-page-1/'
# 携带获取到的 Cookies 信息请求书籍网页
comment_res = requests.get(comment_url, cookies=login_res.cookies)
# 解析请求到的书籍网页内容
soup = BeautifulSoup(comment_res.text, 'html.parser')
# 搜索网页中所有包含评论的 Tag
comments_list = soup.find_all('div', class_='comment-txt')
# 使用 for 循环遍历搜索结果
for comment in comments_list:
# 提取用户名
coment_name = comment.find('cite',class_='fn')
# 打印用户名
print(coment_name.text[:-2])
7.刷评论
依旧是使用 post() 函数对网址发起请求。除了url与data外,发表评论是需要先登录的,所以我们还需要带上储存着登录信息的 Cookies 。
最终,我们发表评论中 post() 函数的语法格式应该是:requests.post(url, data, cookies)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号