再探快速排序
快速排序还是有细节值得扣一扣的
想写出一个时间O(nlogn)(极不容易被卡成O(n^2)的代码),并且空间O(logn)(栈空间)的代码并非易事。
关于快速排序还没有具体尝试过写法,于是现场进行了写法的学习。期间遇到的一个问题是:
起初,对于快排中指针移动位置的操作,只写了>x,

而这种写法,当存在相同元素的时候,如果只判断>x,那么可能会因为a[ptl]和a[ptr]的值同时等于x,而导致均无法移动,造成死循环。
所以,正确的写法是>=x
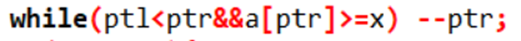
此外,经过在www.luogu.org洛谷网站上测试后,发现,传统的qsort代码(包括数据结构课本上的qsort代码的写法)存在优化的空间!
再看qsort的写法:

试想,如果全部元素均相等,那么蓝色部分的代码,ptr会直接减到ptl位置,然后while循环结束。这相当于每次取了最大值当中轴,区间规模只-1,复杂度退化为O(n^2).
快排算法本身并没有问题,只是写法有漏洞。
优化的要点在于,当相等元素很多的时候,如何让区间的划分仍然能够尽量平均分,也就是,不要直接取到最大值。
一个解决办法是,把数组的每个元素强行看成二元组<a[i],i>,强行赋予第二关键字i,按照a[i]升序排序,a[i]相同,那么i升序排序,这样,既可以保证排序的稳定性,而且把问题转化为各个元素不相同的情况,直接解决了这个问题。
当然,这个方案也存在问题,因为需要额外的O(n)的空间。如果不追求排序的稳定性,还想在相同元素很多的时候保证时间复杂度,该怎么办呢?
网上的解决办法的代码是这样的:
https://www.luogu.com.cn/blog/86005/solution-p1177

可以看到,a[i]<mid而不是a[i]<=mid,这样使得i不会直接一部跨过整个区间和j合并。事实上,全部元素都相同的时候,反而会直接把区间一分为二,得到最期待的结果。
而且,当a[i]和a[j]同时为mid的时候,会在if(i<=j)里面额外加上i++,j—的语句,使得i,j强行移动,避免死循环。这样,一举两得。至此,这个问题得到了解决。这个快排算法在luogu上的运行时间比上述快排算法快100倍。
(不过值得一提的是,这个版本的快排算法,没能实现把中轴放在应该在的位置,只实现了划分两段区间,左区间最大值小于等于右区间最小值。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号