聚类算法
参考资料:
https://www.cnblogs.com/liujinhong/p/6001997.html
https://blog.csdn.net/zaishuiyifangxym/article/details/89488420
https://blog.csdn.net/weixin_42056745/article/details/101287231
所谓聚类问题,就是给定一个元素集合 D,其中每个元素具有 n 个可观察属性,使用某种算 法将 D 划分成 k 个子集,要求每个子集内部的元素之间相异度尽可能低,而不同子集的元素相 异度尽可能高。其中每个子集叫做一个簇。 与分类不同,分类是示例式学习,要求分类前明确各个类别,并断言每个元素映射到一个类 别,而聚类是观察式学习,在聚类前可以不知道类别甚至不给定类别数量,是无监督学习的一 种。目前聚类广泛应用于统计学、生物学、数据库技术和市场营销等领域,相应的算法也非常的 多。
K-means k均值算法
相异度
根据需要,两个元素(通常是n维向量,或者n个参数的标量)的相异度通常定义如下:
1.对于标量:
用欧几里得距离,或者曼哈顿距离,闵可夫斯基距离

(此外,闵可夫斯基距离里面,p->∞,则这时候变成切比雪夫距离!!!)
但是这样取均值,会受到极端数据影响,可以对每一维先做归一化处理,把所有的数据放缩到[0,1]之中
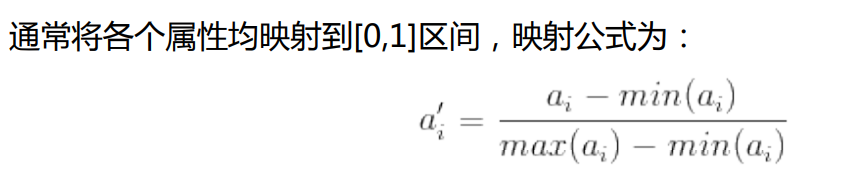
2.对于二元变量,

另外,有时候,同时取0的情况很多,这种情况并不代表二者更相近
则:

3.对于分类变量

没有什么同时取0之类的情况
4.对于序数变量

5.向量
向量有方向,不能直接做类似于标量的处理
用余弦度量这个相似度。注意,这里得到的是相似度,不是相异度(二者相加等于1)
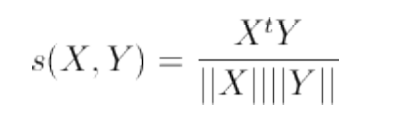
(存疑,那向量的长度不考虑加入相异性嘛)(这两种应该同时考量。。。应该是有个比重,或者看需求)
K-means聚类算法
k 均值算法的计算过程非常直观:
(1) 从 D 中随机取 k 个元素,作为 k 个簇的各自的中心。
(2) 分别计算剩下的元素到 k 个簇中心的相异度,将这些元素分别划归到相异度最低的 簇。
(3) 根据聚类结果,重新计算 k 个簇各自的中心,计算方法是取簇中所有元素各自维度的 算术平均数。
(4) 将 D 中全部元素按照新的中心重新聚类。
(5) 重复第 4 步,直到聚类结果不再变化。
(6) 将结果输出
期望复杂度的话,,,,,
算法的优势劣势
待补充。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号