Hadoop-入门部分知识点总结
目录
原文链接:Hadoop – 笔墨云烟
个人学习笔记,仅供参考
数据分析分类
数据分析在企业日常经营分析中主要有三个方向
- 现状分析(分析当下的数据):现阶段的整体情况,各个部分的结构占比、发展变动‘
- 原因分析(分析过去的数据):某一现状为什么发生,确定原因,做出调整优化;
- 预测分析(结合数据预测未来):结合已有数据预测未来发展趋势;
离线分析(原因分析):面向过去/历史,分析已有的数据。在时间维度明显成批次性变化。一周一分析(T+7),一天一分析(T+1),所以也叫做批处理。
实时分析(现状分析):面向当下,分析实时产生的数据。所谓的实时是指从数据产生到数据分析到数据应用的时间间隔很短,可细分秒级、毫秒级。
预测分析(机器学习):基于历史数据和当下产生的实时数据预测未来发生的事情;侧重于数学算法的运用,如分类、聚类、关联、预测。
概念
分布式与集群概念
分布式:多台机器;每台机器上部署不同组件
分布式由多个节点组成,节点之间互通,共同配合对外提供服务
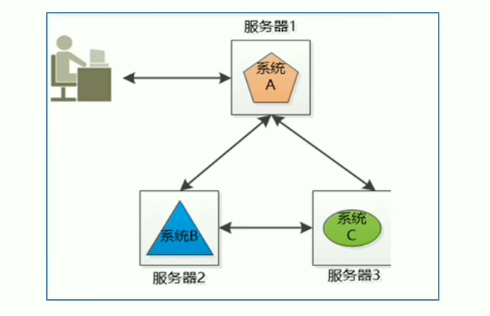
集群:多台机器;每台机器上部署相同组件
集群是指在几个服务器上部署相同的应用程序来分担客户端的请求
Hadoop组件
Hadoop是一个由Apache基金会开发的分布式系统基础架构,旨在处理大规模数据的存储和计算。它的核心组件包括HDFS、MapReduce和YARN,这些组件共同支撑起Hadoop的高效性、可靠性和可扩展性
HDFS
HDFS(分布式文件存储系统):是Hadoop生态系统中的数据存储管理基础。HDFS通过流式数据访问,提供高吞吐量的数据访问功能,适合处理大型数据集。数据以块的形式分布在集群的不同物理机器上,提供了一次写入多次读取的机制。
MapReduce
MapReduce(分布式计算框架):是一种分布式计算模型,用于进行大数据量的计算。它将计算抽象成map和reduce两部分,其中Map对数据集上的独立元素进行操作,生成键-值对形式的中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
YARN
YARN(集群资源管理和任务调度框架):是Hadoop的资源管理和任务调度框架。它将资源管理和作业调度/监视的功能拆分为单独的守护进程,包括ResourceManager和NodeManager。ResourceManager负责整个集群的资源管理和任务调度,而NodeManager负责管理和监控每个节点上的计算资源。YARN通过资源的统一管理和调度,提高了集群的利用率和数据共享能力。
集群的启动
1.启动HDFS服务
start-dfs.sh2.查询Jps、NameNode、DataNode与SecondaryNameNode共四个进程
jps 3.启动yarn服务、查询ResourceManager与NodeManager两个进程
start-yarn.sh
jps 4.集群web网页(hadoop-2.6.5)
主机IP地址:50070端口
主机IP地址:8088端口
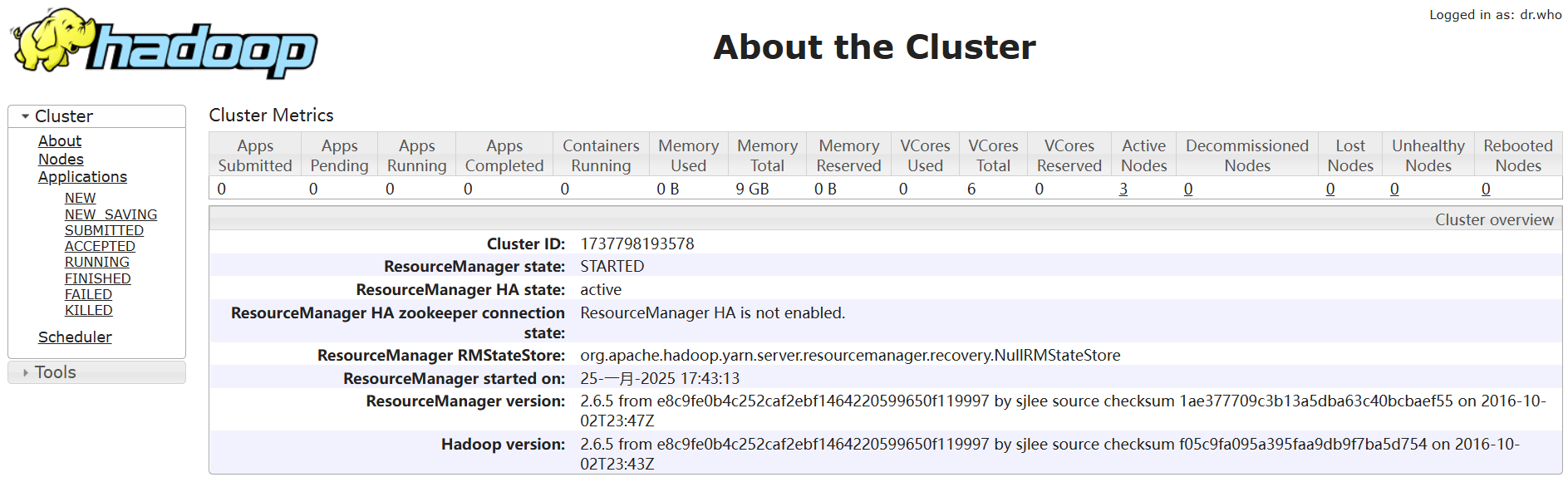
5.集群关闭
stop-all.shHadoop特性
- 扩容能力:Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可方便灵活的方式扩展到数以千计的节点。
- 成本低:Hadoop集群允许通过部署普通廉价的机器组成集群来处理大数据,以至于成本很低看重的是集群整体能力。
- 效率高:通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
- 可靠性:能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。
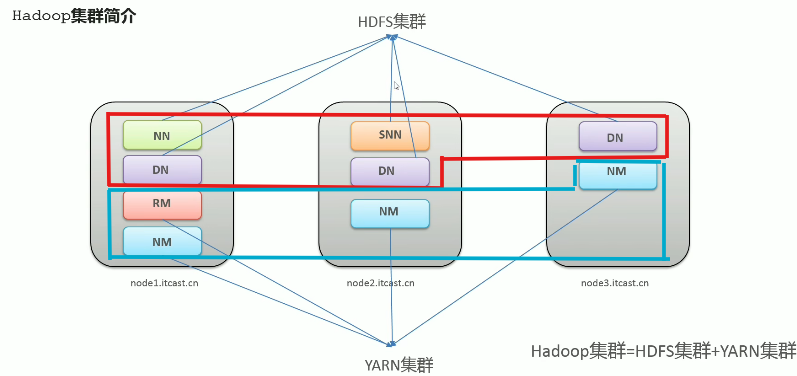
Hadoop集群概述
- Hadoop集群是由HDFS集群和YARN集群组成
- 两个集群逻辑上分离,通常物理上在一起
- 两个集群是标准的主从架构
- MapReduce是计算架构、代码层面的组件,无集群一说
HDFS集群内容:
- NameNode(名称节点):主角色
- DataNode(数据节点):从角色
- SecondaryNode(辅助节点):主角色辅助角色
YARN集群内容:
- ResourceManager(资源管理器):主角色
- NodeManager(节点管理器):从角色
HDFS
HDFS设计目标
故障检测和自动快速恢复:
- 硬件故障(Hardware Failure)是常态, HDFS可能有成百上千的服务器组成,每一个组件都有可能出现故障。因此故障检测和自动快速恢复是HDFS的核心架构目标。
高吞吐量:
- HDFS上的应用主要是以流式读取数据(Streaming Data Access)。HDFS被设计成用于批处理,而不是用户交互式的。相较于数据访问的反应时间,更注重数据访问的高吞吐量。
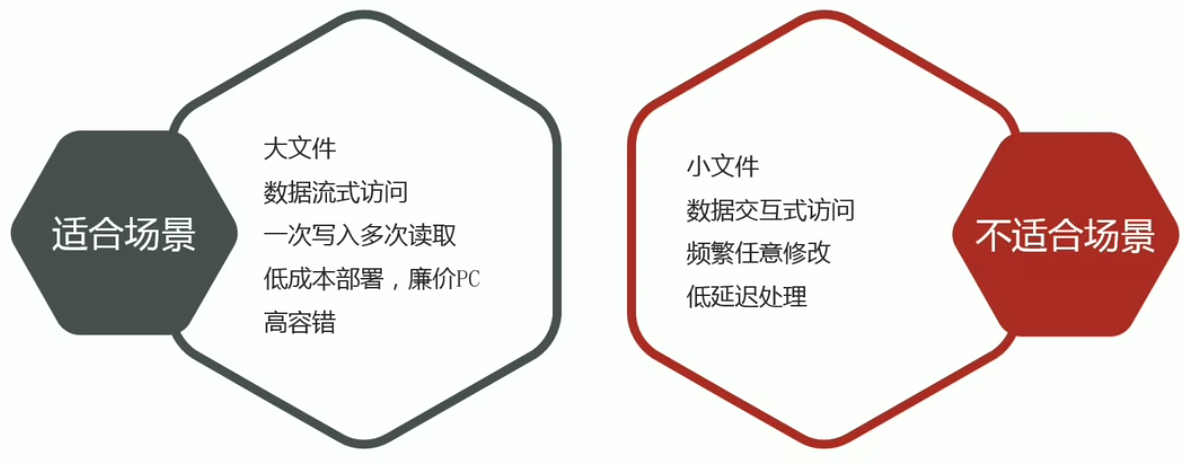
支持大文件:
- 典型的HDFS文件大小是GB到TB的级别。所以,HDFS被调整成支持大文件(Large Data Sets)。它应该提供很高的聚合数据带宽,一个集群中支持数百个节点,一个集群中还应该支持千万级别的文件。
无需修改:
- 大部分HDFS应用对文件要求的是一次写入,多次读取(write-one-read-many)访问模型。一个文件一旦创建、写入、关闭之后就不需要修改了。这一假设简化了数据一致性问题,使高吞吐量的数据访问成为可能。
移动计算代价:
- 移动计算的代价比之移动数据的代价低。一个应用请求的计算,离它操作的数据越近就越高效。将计算移动到数据附近,比之将数据移动到应用所在显然更好。
平台移植:
- HDFS被设计为可从一个平台轻松移植到另一个平台。这有助于将HDFS广泛用作大量应用程序的首选平台。
HDFS的分布式特性
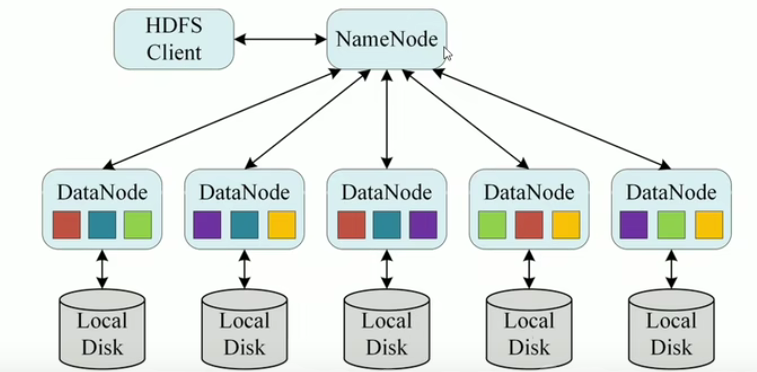
数据跨节点存储:
- HDFS的数据被分割成多个块(Block,默认128MB或256MB),并分散存储在不同机器的磁盘上。
- 单机文件系统只能操作单机上的文件,而HDFS需要协调多个节点(DataNode)的读写操作。
- 单机读写无法感知数据分布,可能导致数据不一致或丢失。
元数据集中管理:
- HDFS通过NameNode管理文件系统的元数据(如文件路径、块位置、副本信息等)。
- 本地命令(如cp、mv)无法与NameNode交互,无法获取文件的分布式元数据。
- HDFS Shell命令会通过NameNode的RPC接口完成元数据操作(如hdfs dfs -ls)。
HDFS的存储位置
每一个集群节点的数据存储地点可以在安装Hadoop时配置的hadoop-2.6.5/etc/hadoop/hdfs-site.xml中查询
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/software/hadoop-2.6.5/hdfs/data</value>
</property>
HDFS的Shell操作
hadoop fs 和 hdfs dfs 可以替换使用
基础操作
1..查看文件目录
hdfs dfs -ls /
hdfs dfs -ls -R / # 递归列出子目录2.查看文件内容
hdfs dfs -cat <HDFS文件路径>
hdfs dfs -tail <文件> # 查看文件末尾内容3.创建目录
hdfs dfs -mkdir <目录路径>
hdfs dfs -mkdir -p <多层目录路径>
hadoop fs -mkdir <目录路径> 4.上传文件到HDFS
hdfs dfs -put <本地文件> <HDFS目标路径>
hdfs dfs -copyFromLocal <本地文件> <HDFS路径> # 功能同put,生产环境更习惯用put
hdfs dfs -moveFromLocal <本地文件> <HDFS路径> # 从本地剪切粘贴到HDFS
hdfs dfs -appendToFile <本地文件> <HDFS路径> # 追加到文件末尾
hadoop fs [-put][-copyFromLocal][-moveFromLocal][-appendToFile] <本地文件> <HDFS路径> 5.下载文件到本地
hadoop fs -copyToLocal <HDFS目标路径> <本地文件>
hadoop fs -get <HDFS目标路径> <本地文件>6.删除文件和文件夹
hadoop fs -rm -r <路径>
hdfs dfs -rm <路径>
hdfs dfs -rm -skipTrash <文件> # 直接删除(绕过回收站)7.移动/重命名文件
hdfs dfs -mv <源路径> <目标路径>8.复制文件
hdfs dfs -cp <源路径> <目标路径>文件权限管理
1.修改文件/目录权限
hdfs dfs -chmod <权限模式> <路径> # 示例:-chmod 755 /data
hdfs dfs -chmod -R <权限模式> <目录> # 递归修改2.修改文件所有者
hdfs dfs -chown <用户:组> <路径> # 示例:-chown hadoop:users /data
hdfs dfs -chown -R <用户:组> <目录> # 递归修改3.修改文件所属组
hdfs dfs -chgrp <组名> <路径>系统管理与监控
1.查看HDFS磁盘使用情况
hdfs dfs -df -h # 显示可读的磁盘空间统计
 浙公网安备 33010602011771号
浙公网安备 33010602011771号