博客网站流量日志分析系统
用于数据内容涉及用户隐私,因此不提供数据集内容,个人学习内容笔记,仅供参考。
项目链接:https://gitee.com/rongwu651/bokeshishi
原文链接:博客网站流量日志分析系统 – 笔墨云烟
前言:作为经营博客网站的一名大数据专业的大学生,个人博客不仅是展示技术见解、记录学习历程和分享生活感悟的重要窗口,更是连接志同道合者的数字桥梁。随着博客内容的丰富与访问量的逐步增长,理解“谁在访问”、“如何访问”以及“关注什么”变得至关重要。这些信息蕴含在服务器持续产生的访问日志中,是优化内容策略、提升用户体验、规划未来发展的核心数据资产。
因此,我将通过对网站访问者的请求访问进行数据收集,对实时流量趋势分析(如各国访问量、不同操作系统用户偏好、热门设备分布)的需求,设计并实现一套实时流量日志分析系统,通过技术手段实现数据采集、实时处理、多维度聚合及可视化展示,为运营决策提供数据支撑。
研究内容
本课题的核心目标是构建一个高效、实时的博客网站流量日志分析系统。该系统通过多维度数据采集、实时处理与聚合分析,实现对网站流量的深度洞察,帮助我快速掌握流量分布特征。课题的主要研究内容围绕如何利用大数据技术设计并实现高可靠、可扩展的实时分析系统,具体包括:
主要研究的内容如下:
- 针对大数据实时计算框架Kafka、zookeeper、storm,该如何设计系统架构,同时根据业务需求完成整套数据实时计算处理的实现。
- 系统的设计与实现。在对业务进行需求分析后,需要对系统进行整体的架构设计,应当考虑到如何用分层架构思想完成系统架构设计。之后,依据这些设计对系统进行落地实现。
- 核心功能实现细节与问题发现。针对各模块核心功能如何实现进行讲解,同时对开发过程中存在的问题进行简要概述问题与其解决方案。
系统架构设计
本课题的主要内容是采用 “数据采集→消息传输→实时处理→存储→查询” 的分层设计,核心组件包括 Kafka(消息队列)、Apache Storm(实时计算)、HBase(分布式存储)
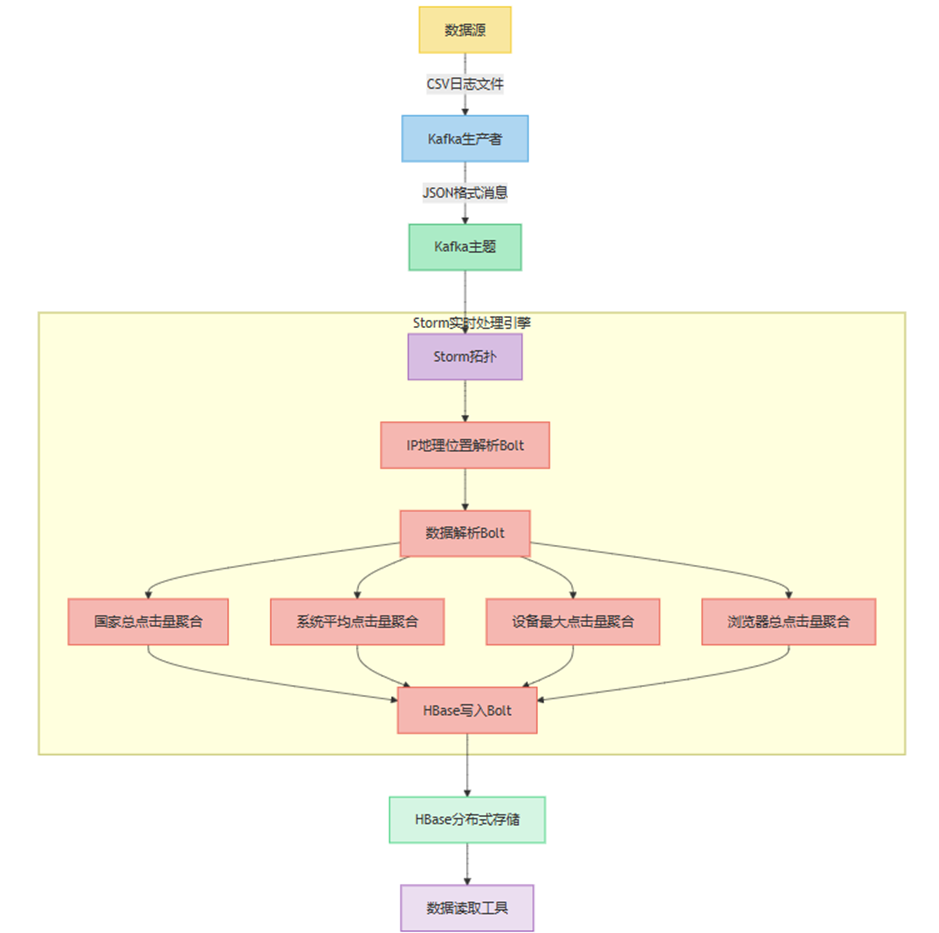
博客网站流量日志分析系统结构设计图
数据采集传输层
我们通过后台导出日志CSV文件并保存至项目中, 创建kafka生产者读取传输类CsvDataProducer,通过连接Kafka主题,读取并将CSV文件内容转为JSON格式,并按照日期作为分区依据写入到Kafka中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号